







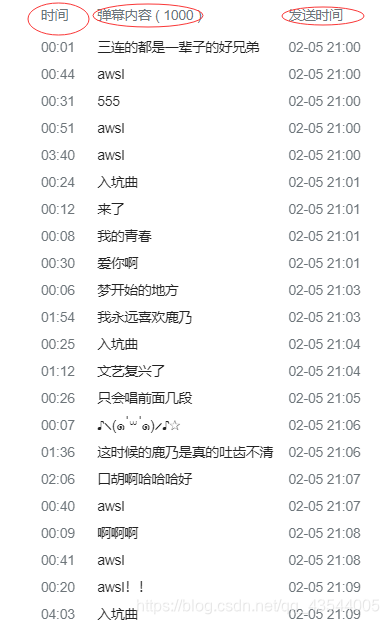
此次爬取的信息有:
1、视频名称
2、在线观看人数
3、弹幕内容
4、弹幕发送时间
5、弹幕在视频中的位置
6、点赞
7、收藏
8、投币数

由于b站的很多信息是动态加载的。所以部分信息,需要自己抓包,进入对应的网址抽取信息。例如在线观看视频人数,投币数,收藏数等等。
我的思路
首先拿到这个小项目时,分析出 要获取的数据如上。观察,不同信息对应的url。首先,我们应先在B站首页,获取出 要爬取视频的 名字,url地址。但此时存在一个问题:
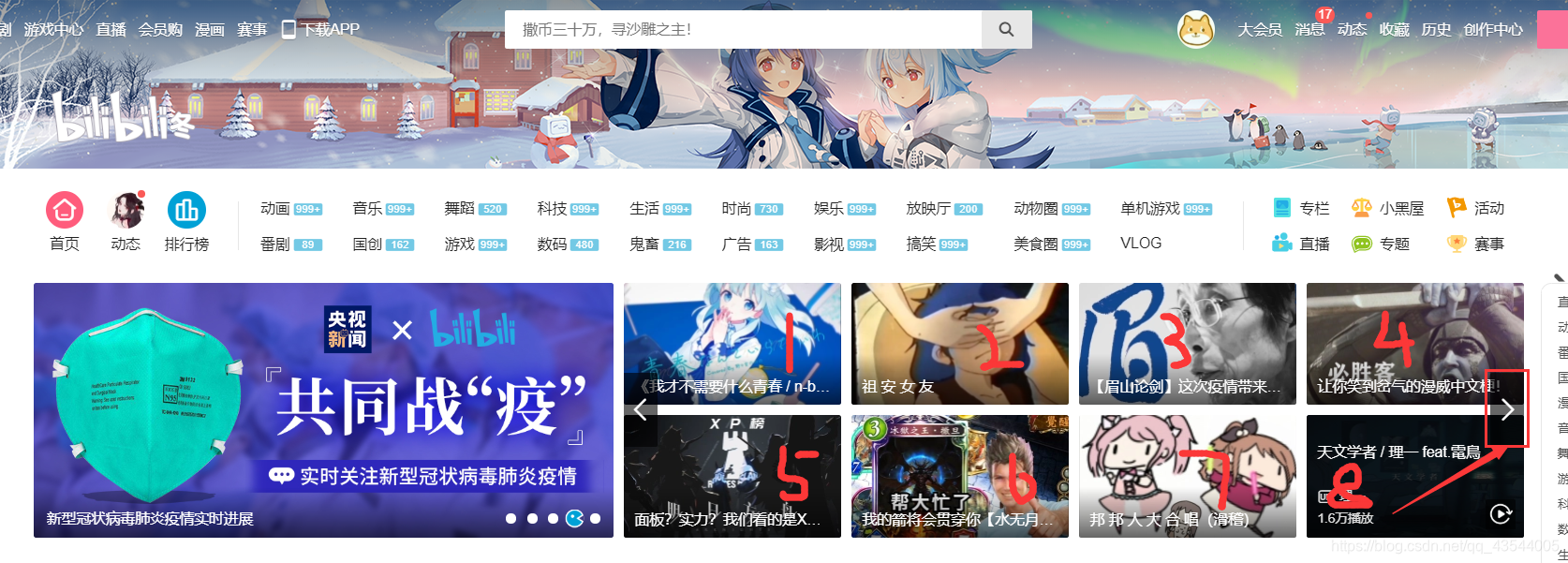
若直接发送请求获取响应,只能的到8个视频的url和名字,其实这一栏共有24个视频信息,但这个是轮播图,不能一次性得到。起先,我试图通过抓包,希望能够得到接口地址,得到所有信息。但事与愿违,经过使用开发者工具及分析页面源码,我发现这个网页 用的vue的响应式,就是监听左右翻,然后把对应页数里的数据改到html上的href的里面 不是xhr请求。翻页更新是通过js改的html的数据。与是乎,我想到了用selenium来进行 翻页操作。并用
webdriver.Chrome().page_source来获取当前网页源码,来获得翻页后的视频信息。
上代码:
#通过selenium 间隔0.1秒点击3次 右翻页 获取 视频的名称 地址
video_names = []
video_urls = []
chrome = webdriver.Chrome()
url = 'https://www.bilibili.com/'
chrome.get(url)
for i in range(3):
response = chrome.page_source
e = etree.HTML(response)
video_names += e.xpath('//div[@class="info"]/p[@class="title"]/text()')
video_urls += e.xpath('//div[@class="recommend-box"]//a/@href') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









