









在上一篇中我们采集了国家统计局2018年的全国地名数据。接下来,我们将会用这个数据进行匹配,提取相关的地级市与省份。

之前我们采集的全国地名数据分为了两种数据结构分别保存,在这里我们使用第一种结构的数据。

接下来我们要写一个进行提取的函数。输入是公司名称的字符串,公司所属省份,与省份对应相应的地名数据。
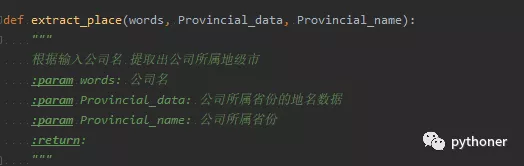
接下来就进入重点了,开始对前两个词的地名数据进行匹配。首先对第一个词进行匹配。
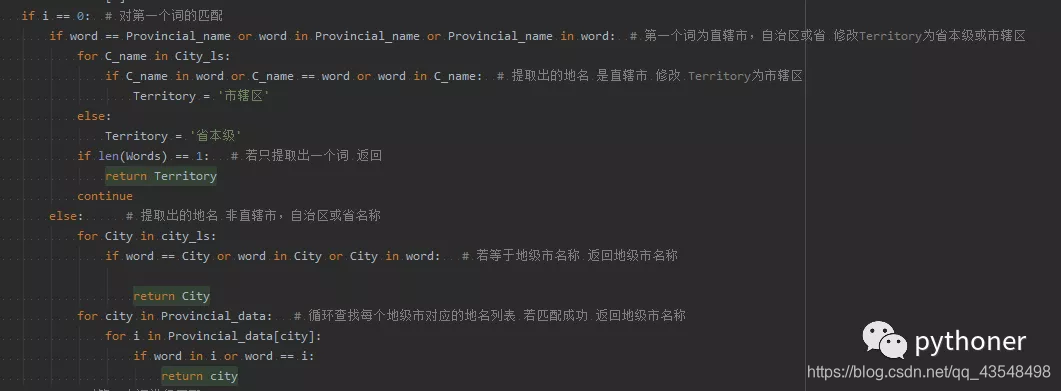
若第一个词未返回数据 对第二个词进行匹配
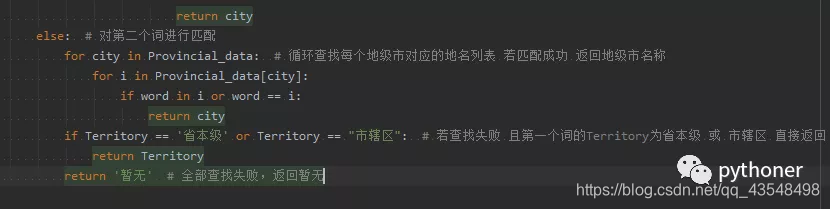
到此我们的地名提取基本上结束了。我们随便拿两个数据测试下
首先加载数据,这个就是我们之间采集的地名数据
province_data = open('./China_place_data.json', encoding="utf-8").read()
province_data = json.loads(procince_data)
然后提取所属地级市
place = extract_place('韩城市城市投资(集团)有限公司', procince_data['陕西省'], '陕西')
"维吾尔自治区", ""))
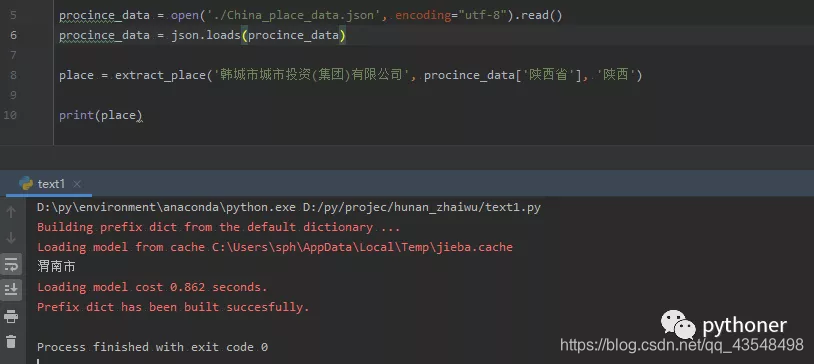
可以看到 最终提取到“韩城市城市投资(集团)有限公司”所属的地级市为渭南市。
github:https://github.com/sph116/Company_Place_name_extraction
基于国家统计局的地名提取项目就到此结束啦,后续我还会继续发布一些机器学习,爬虫相关的实战项目,欢迎交流哦!

欢迎扫码关注:















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









