







Hi,朋友们,我们又见面了,这一次我给大家带来的是Hadoop集群搭建及Hive的安装。
说明一下,网上有很多的教程,为什么我还要水?
第一,大多数的安装都是很顺利的,没有疑难解答。
第二,版本问题,网上的搭建在3以前的比较多。
第三,我想给出一个更简洁的安装教程,把道理说明白,让读者就算在安装的过程中遇到问题也知道问题出在哪,应该朝哪个方向去要解决方案。
Hadoop-3.0.0的集群搭建
hadoop集群的安装,关键在主节点,主节点配置好以后,将主节点复制到其他做数据节点的服务器上就不用管了。
我有三台服务器,ip分别是192.168.12.71,192.168.12.200,192.168.12.201。
以12.71服务器作为主节点,我的hadoop路径是‘/opt/hadoop-3.0.0’首先要在这台服务器上安装一个jdk,我的jdk路径是‘/opt/jdk1.8’。
然后是设置hosts,vim /etc/hots
192.168.12.71 node1
192.168.12.200 node2
192.168.12.201 node3
配置
现在开始做Hadoop主节点的配置工作,我们先到hadoop的 ‘etc/hadoop/’目录下,所有的配置文件都在里面。
- hadoop-env.sh
在这个文件里,增加一行指定Jdk目录
export JAVA_HOME=/opt/jdk1.8 - core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
- hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--下面的是配置namenode和datanode的数据存储位置,若不配置会有默认位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/zhibei/Hadoop/hadoop-3.0.0/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/zhibei/Hadoop/hadoop-3.0.0/data/datanode</value>
</property>
- mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/hadoop-3.0.0/share/hadoop/mapreduce/*:/opt/hadoop-3.0.0/share/hadoop/mapreduce/lib/*</value>
</property>
报错
Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster Please check whether your etc/hadoop/mapred-site.xml contains the below configuration:
如果不配置,mapreduce.application.classpath,则会报以上错误,在你hive数据做插入时现象如下
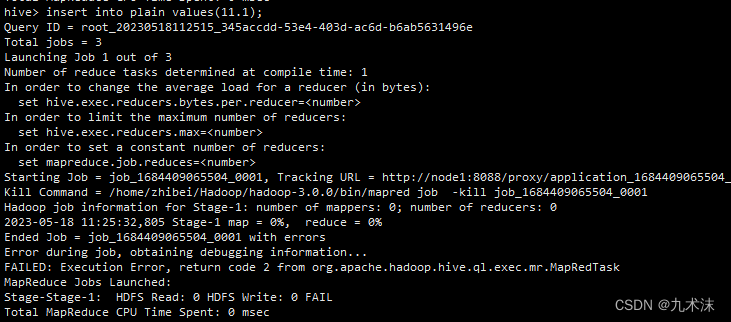
这个报错是在8088的端口上找到对应的插入日志,然后查看详情,就能看到。
5. yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
- workers
node1
node2
node3
总共配置就是这6项。
然后把hadoop3.0.0这个节点给另外的服务器复制过去。
格式化
主节点的格式化这一步,是非常重要的。执行命令
hadoop-3.0.0/bin/hadoop namenode -format
启动hadoop集群
在使用start-all.sh和stop-all.sh脚本启停脚本之前,先在两个脚本之前添加如下内容。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
启动 hadoop-3.0.0/sbin/start-all.sh
启动完成之后就是jps命令,jps来自jdk中,首先保证每个节点都有jdk.请把jdk配置出来
vim /etc/profile
#添加如下内容
export JAVA_HOME=/opt/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
完成之后执行
source /etc/profile
在jdk没有在环境中配置时,使用jps命令会报找不到的问题。在配置了jdk环境之后,jps执行出现permission的权限问题,那就需要给jps文件赋权,找到jdk/bin/jps文件,执行
chmod 775 jps
就ok.
接下来就是使用jps查看各服务器中启动的服务。
node1
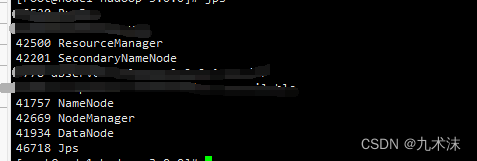
node2
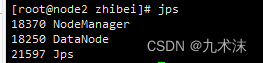
node3

日志信息可以在hadoop-3.0.0/logs里面查看。等集群启动完成之后就可以访问,相关的网页了。
网页一 http://192.168.12.71:9870/

网页二 http://192.168.12.71:8088/
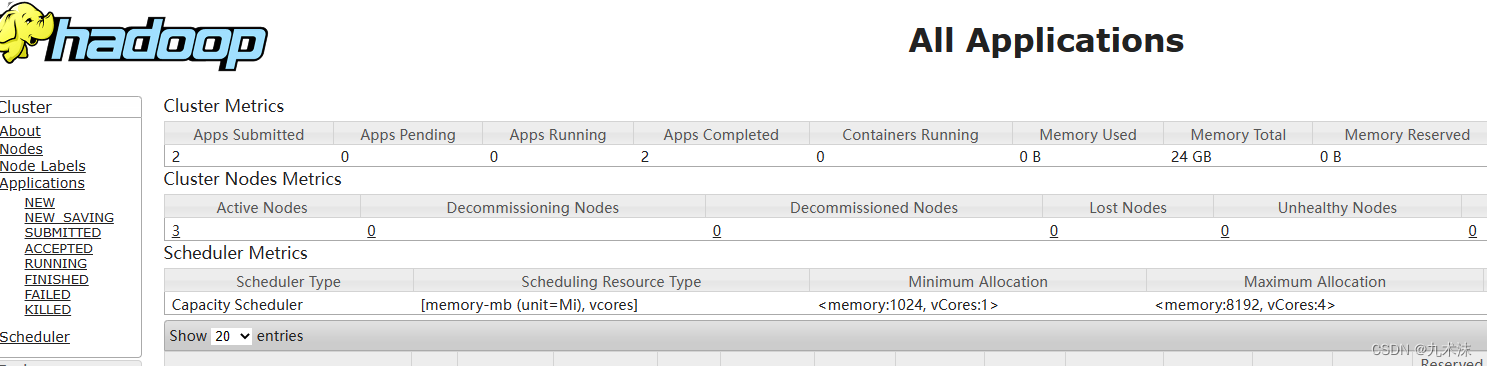
那么集群的搭建就到这样!
Hive-3.1.3的安装
我的hive路径是’/opt/hive-3.1.3/',和node1节点在同一个服务器。
准备工作
你首先需要有mysql,启动以后,需要创建一个数据库,我创建了一个hivedb供hive存储数据用。下面的配置中会体现。
配置
- hive-site.xml
这个配置文件需要先到hive-3.1.3/conf/目录下创建,然后添加如下内容
</configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hivedb?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
<!-- 如果 mysql 和 hive 在同一个服务器节点,那么请更改 hadoop02 为 localhost -->
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>hive default warehouse, if nessecory, change it</description>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>hive.in.test</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>Enforce metastore schema version consistency</description>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
</configuration>
- 添加一个mysql的驱动
mysql-connector-java-5.1.40.jar没有这个驱动,会连接不上数据库,导致meta数据无法存储。
没有驱动,你就会看到failed to load driver

- 初始化元数据
主要就是在对应的mysql数据库中创建一系列的表。命令如下
./bin/schematool -initSchema -dbType mysql -verbose
如果没有成功执行如上命令就直接启动Hive,在做查询操作的时候你就会看到
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
- 启动Hive
./bin/hive
到这里就结束了,纰漏肯定有,说不定你就有一些特殊情况。不妨留言给我!
番外
这里我想说一说的就是千万注意,如果你的系统上有旧的Hadoop,Hive存在的,现在要重新的部署,一定谨慎,因为这会导致数据的不可恢复。
如果只是测试数据,那就无所谓,删掉就的节点,重新配置,一定要重新格式化这一步,不然hadoop是不能成功的。
Hive也是同样,一旦之前Hadoop被覆盖或者架构发生改变,Hive之前的数据也会有损坏的风险。















 9673
9673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









