







1。基本网络结构
1.1 多层感知器MLP
多层感知器也叫前向传播网络、深度前馈网络,由若干层组成,每一层包含若干个神经单元。激活函数采用径向基函数的多层感知器被称为径向基网络。

1.2 卷积神经网络CNN
卷积神经网络适合处理空间数据,在计算机视觉领域应用广泛,一维卷积神经网络也被称为时间延迟神经网络,可以用来处理一维数据。
CNN主要由卷积层和池化层组成。卷积层能够保持图像的空间连续性,能将图像的局部特征提取出来。池化层能降低中间隐藏层的维度,减少接下来各层的运算量,并提供了旋转不变性。
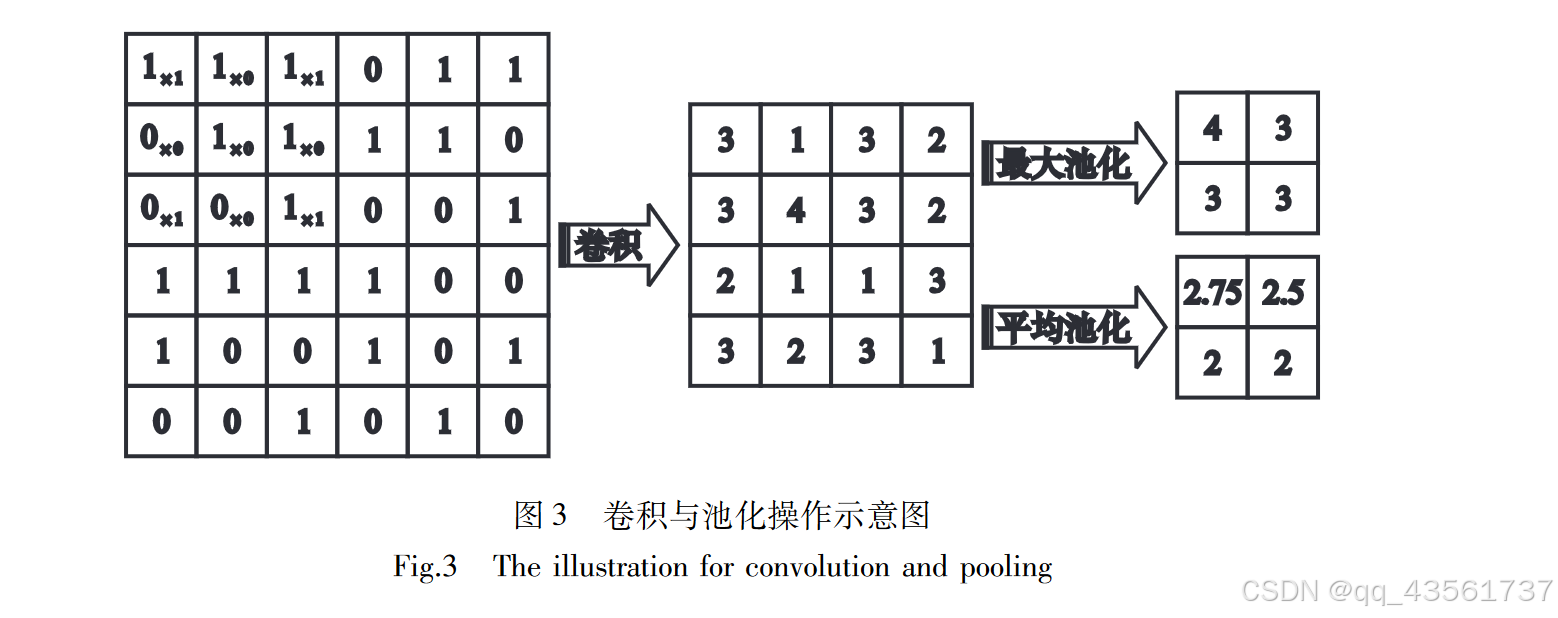
CNN提供了视觉数据的分层表示,CNN每层的权重实 际上学到了图像的某些成分,越高层,成分越具体.CNN将 原始信号经过逐层的处理,依次识别出部分到整体.可以对 CNN进行可视化来理解 CNN:CNN的第二层能识别出 拐角、边和颜色;第三层能识别出纹理、文字等更复杂的不 变性;第四层能识别出狗的脸、鸟的腿等具体部位;第五层 能识别出键盘、狗等具体物体.比如说人脸识别,CNN先是 识别出点、边、颜色、拐角,再是眼角、嘴唇、鼻子,再是整 张脸.CNN容 易 在 FPGA等 硬 件 上 实 现 并 获 得 加 速; CNN同一卷积层内权值共享,都为卷积核的权重.CNN的局 部连接、权值共享、池化操作等特性减少了模型参数,降 低了网络复杂性,也提供了平移、扭曲、旋转、缩放不变性
1.3循环神经网络RNN
循环神经网络适合处理时序数据,在语音处理、自然语言处理领域应用广泛。



RNN将上一时刻隐藏层的输出也作为这一时刻隐藏层的输入,能够利用过去时刻的信息,即RNN具有记忆性。RNN在各个时间上共享权重,大幅减少了模型参数。但RNN训练难度较大。
2.网络结构改进
2.1卷积神经网络改进
ImageNet[18]比赛(ImageNetlargescalevisualrecognition competition,ILSVRC)极大促进了卷积神经网络的发展,不 断有 新 发 明 的 卷 积 神 经 网 络 刷 新 了 ImageNet成 绩。
1)AlexNet。
Hinton为了验证深度学习的有效性,2012年 参加 ILSVRC并取得第一名,所用到的神经网络模型被称为 AlexNet.AlexNet网 络 包 含 5层 卷 积 层、maxpooling层 和 dropout层,接着连接 3层全连接层,最后输出层有 1000个 神经元,对应 1000个分类,经过 Softmax函数作用后得到 每一类的概率.AlexNet采用平移、翻转、截取图片一部分 等方式来增加训练数据,用 dropout来防止过拟合,用带有 动量和权重 衰 减 的 批 梯 度 下 降 方 法 来 训 练 模 型.AlexNet 用两块 GPU并行训练了 6天,而且采用 ReLU作为激活函 数比用 Tanh训练时间缩短了 6倍.AlexNet所采用的这一 系列技术现在仍然被广泛使用.
2)ZF Net
ZFNet.ZFNet是 ILSVRC2013冠军,错 误 率 为 11.2%,ZFNet可以认为是 AlexNet的微调,网络层数仍为 8.Zeiler和 Fergus利用反卷积网络对 CNN进行可视化来 理解 CNN每一层的作用,可视化帮助找到了比 AlexNet效 果更好的网络结构 ZFNet.ZFNet所需的训练数据更少, AlexNet用 1500万张图片来训练模型,而 ZFNet只用了 130万张图片.AlexNet第一层卷积核为 11×11,而 ZFNet 为 7×7,卷积核变小使得 ZFNet在第一层能保留更多的 相关信息.
3)VGGNet.
Simonyan等逐次在 AlexNet中增加卷积 层,比较 6种不同深度的网络,研究网络深度的影响.结 果表明神经网络越深,效果越好,当增加到 16、19层时, 效果提升明显,19层的网络被称为 VGG19.VGGNet严格 采用 3×3的卷积核,步长(stride)和填补(padding)都为 1; 采用 2×2的 maxpooling,步长为 2.相比于 ZFNet7×7的 卷积核,VGGNet卷积核大小只有 3×3,使得模型参数更少,而且连续两层的卷积层使其有 7×7卷积核的效果,之 后人们通常也使用 3×3的卷积核.VGGNet模型用 Caffe 来实现,利用图片抖动来增加训练数据,在图片分类和物 体定位任务方面都有很好的效果.
4)GoogLeNet
.GoogLeNet是 ILSVRC2014冠军,top5错 误率为 6.7%,其网络层数为 22层.GoogLeNet表明 CNN 不一定是 要 将 卷 积 层、池 化 层 依 次 堆 叠 起 来.GoogLeNet 采用 Inception模块,模块里的卷积层、池化层是并行的, 所以不用选择这一层是用卷积层还是池化层.在 Inception 模块的最后不直接将所有神经元“拉直”排成一排,而是采 用池化将 7×7×1024变成 1×1×1024,参数量减少到 1/49, GoogLeNet总的参数量只有 AlexNet的 1/12.使用训练好 的模型对图片进行分类时,对同一张图片的多张变形图片 输出 Softmax概率后求平均作为此图片的概率.
5)深度残差网络 (ResNet)
ResNet是 ILSVRC2015 冠军,同一网络赢得图片分类、物体定位、物体检测三项 任务冠军,图像分类任务错误率为 3.57%,超过人类错误 率 5.1%.ResNet网络层数达到 152层,甚至 1000层.深 层网络有梯度消失的问题,ResNet在两层或多层之间直接 加上线性连通通路,即构成了残差模块,保证梯度能通过 线性通路传到底层,也使得输入层的信息能直接保留到后 面网络层.
6)R-CNN
Girshick等提出 RCNN用于完成计算机视 觉中的物体检测任务.物体检测目标是将图片中所有物体 用方框框出来,此任务可以分成两个子任务,首先是生成方 框将物体框出来,然后对框出来的物体进行分类判断是具 体哪个物体.R-CNN采用选择性搜索(selectivesearch)方法 生成大约 2000个方框,用已训练好的 CNN比如 AlexNet 对每一个方框内的图片提取出特征,再将特征放进 SVM 进 行 分 类 ,同 时 将 特 征 放 入 回 归 器 中 得 到 更 精 确 的 候 选 方框.
7)FastR-CNN
FastR-CNN将 R-CNN中 CNN提取特 征、SVM分类、回归这三个过程放在一起,形成端到端整 体的模型,速度和准确率都得到提升.FastR-CNN的输入 数据是整张图片和若干方框.首先用若干卷积层、池化层 处理整张图片得到特征图(featuremap);用兴趣区域池化 层(regionofinterestpoolinglayer)处理每个方框得到固定大 小的特征图.然后接若干全连接层,最后同时输出是某个 类别的概率、确定每个类的方框的 4个值
8)FasterR-CNN.
FasterR-CNN首先用卷积层、池化 层处理整张图片得到特征图,在此特征图上用 regionproposalnetwork来生成方框,其它操作跟 FastR-CNN一样. 即 FasterR-CNN将生成方框的方法也换成了深度学习模 型,并由原来 在 整 张 图 上 生 成 改 成 在 更 小 的 特 征 图 上 生 成,使得模型训练速度进一步加快.
9)MaskR-CNN.MaskR-CNN在 FasterR-CNN基础上 增加语义分割的并行分支,在原来生成方框、分类、回归 任务基础上增加分割任务,能同时实现物体检测和语义分 割.MaskR-CNN的基础网络使用 ResNeXt-101和 FPN(fea turepyramidnetwork).语义分割任务的误差由基于单像素 Softmax多项式交叉熵变成了基于单像素 Sigmoid二值交 叉熵.MaskR-CNN加入了 RoIAlign层,相当于对特征图 进行插值.
10)网中网结构(networkinnetwork,NIN).
网中网结 构用微型神经网络比如多层感知器,来代替 CNN中的卷 积核,形成了神经网络里嵌套着微型神经网络的结构.因 为已经用微型网络进行了复杂的局部建模,所以 CNN中 最后的全连接层可以由全局 mean-pooling来代替.这使得 模型参数大大 减 少,防 止 了 过 拟 合,也 增 加 了 可 解 释 性, NIN的参数有 2900万个,是 AlexNet的 1/10.
11)空间变换网络(spatialtransformernetworks,STNs).
空间变换网络通过变换输入的图片来提升准确率,而不是 通过改变网络结构.STNs里主要包含空间变换模块,其又 由本地化网络(localizationnetwork)、网格生成器(gridgenerator)、采样器(sampler)三部分组成.STNs对于输入的图 片,先用本地化网络来预测需要进行的变换,然后网格生 成器和采样 器 对 图 片 实 施 变 换,变 换 得 到 的 图 片 被 放 到 CNN中进行分类.STNs的鲁棒性很好,具有平移、伸缩、 旋转、扰动、弯曲等空间不变性.
12)其它卷积神经网络改进.此外,还有其它卷积神 经网络改进,包括 deconvolutionalnetworks、stackedcon volutionalautoencoders、SRCNN、OverFeat、FlowNet[49]、Mr-CNN[50]、FV-CNN[51]、DeepEdge[52]、DeepContour[53]、deep parsingnetwork[54]、 BoxSup[55]、 TCNN[56]、 3维 CNN[57]等.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









