









索引失效
常见情况模、型、数、空、运、算、最、快.
- like查询为满足最左匹配原则。


- where查询数据类型不一致。
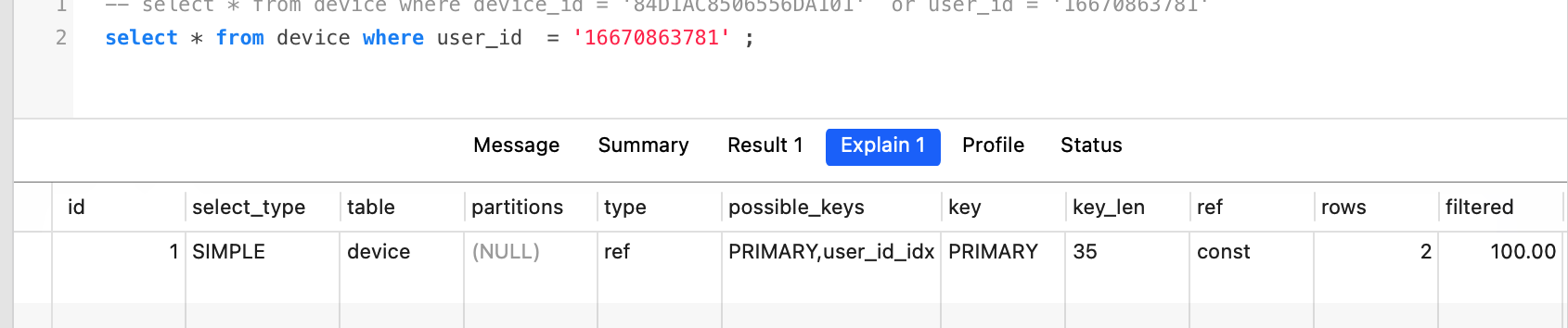
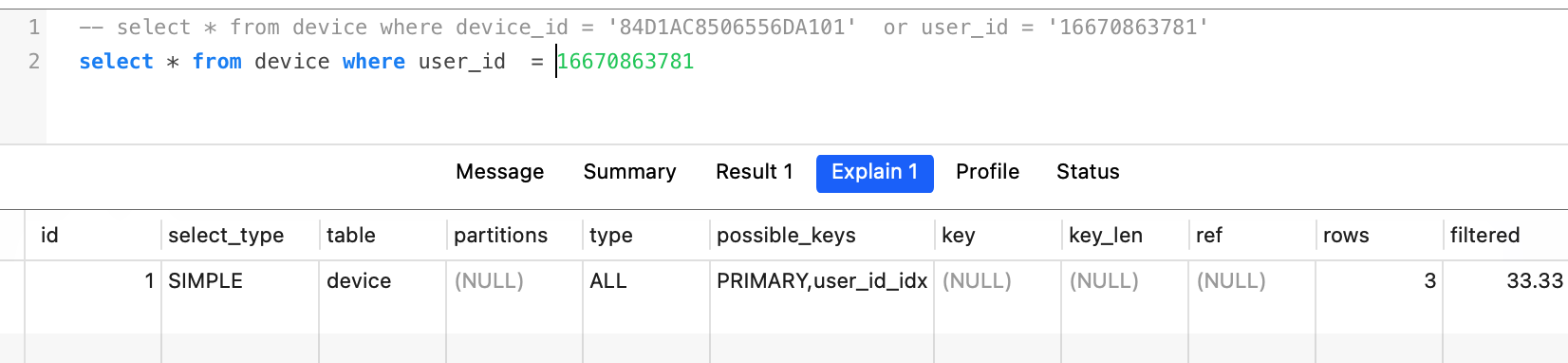
比如id设置为varchar数据类,但是在where比较的时候,1120省略掉了' ',mysql会默认将16670863781(int)转换为char类型的数据。这时查询也就索引失效了。
如,user_id是一个组合索引的最左前缀,按理说是走索引的,但是是Type = ALL 类型。
- 索引的字段上使用内部函数。

- 索引列上使用 is null、is not null、<>、!= 进行比较时候,索引失效。

- 索引列上使用数据运算可能导致索引失效?
正常情况下,intent建立的btree索引,= 比较能够查询出对应的数据,并且使用了intent_idx索引。


- 组合索引使用未满足最左匹配原则
主键(user_id,device_id),未满足最左A、AB匹配,直接使用B进行匹配。


-
全表扫描比索引查询速度更快的情况下,具体分一下几种情况。
- 不使用索引字段就能返回查询结果的查询,比如聚合函数中的count、max、min等。

- 查询结果的记录数量小于表中总记录一定比例的时候。对于大多数数据库来说,这个比例是10%(oracle,postgresql等,mysql可能是30%),即先对结果数量估算,如果小于这个比例用索引,大于的话即直接全表扫描。
如下:全表30条记录,大部分数据大于250,当intent>=250时候直接索引失效,而大于840范围查询将触发索引。



最左匹配索引失效原理
-
单列索引,在mysql中的一种索引数据结构实现就是b+树,在B+树种,非叶子结点存储索引,叶子结点才是存储元素data的的节点,并且通过链表的形式将叶子结点串联起来,可以很方便的实现范围查询。
其中索引构建过程,根据元素大小选择插入
叶子节点位置,当叶子结点元素的数量大于指定阈值Y那就将叶子结点向上分裂,选择叶子结点中合适元素复制插入其父亲节点中,当前节点分裂(一般平分),插入后可能父亲节点也可能需要向上分裂,不同的是选择合适节点插入父节点中,没有父节点生成父节点,当前节点分裂。

- 在组合索引中,索引列有严格的先后循序,比如(A,B,C)三列,会先根据A大小建立索引,当A相等的时候采取根据B列大小建立索引,同字典序的比较。下图来源于 Mysql - 组合索引的B+树存储结构(最左前缀原理)

-
所以在进行where比较的时候,where A=? and B=? 使用该组合索引就应该先根据A索引,进行比较快速定位到A列值的具体位置,然后再对B进行比较定位。若是只是用B,C两列比较,不清楚A具体的值,那么只能走全表扫描查找B,C,也就索引失效了。
-
同理
在组合索引中,范围查询后都失效,在范围查询中,若 where A>=? and B = ? ,先根据A索引找到A边界值的具体位置,然后因为是一个范围查询,A是有序的,但是B不是有序的,就导致B列索引失效。如:

- 但是是前后两个不同索引的话还是可以的。

- like也需要满足最左匹配,也是因为在建立B+树索引的时候使用相同原理。
另外,常见组合索引失效的场景导致的问题:
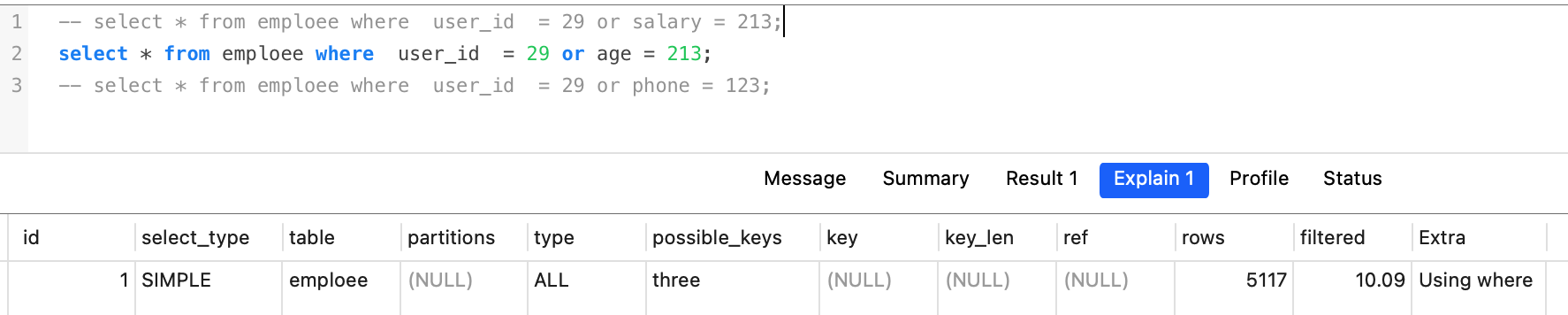
如下表emploee,组合索引 three (user_id,phone,insurance_id) , one(salary)。
and 拼接索引列需要满足最左匹配原则
or 拼接的前后两个字段都需要使用索引,且必须分别都满足最左前缀匹配原则。
select * from emploee where user_id = 29 or salary = 213; //满足上面两个条件 索引
select * from emploee where user_id = 29 or age = 213; // 不满足第一个条件 失效
select * from emploee where user_id = 29 or phone = 123;// 不满足第二个 失效


orderby索引失效导致外部排序,using filesort.
如下虽然user_id触发了索引,但是order by后的Insurance_id直接跳过了phone导致不能走联合索引,所以只能对满足条件的的数据再一次进行外部排序。

当我们修改一下 order by phone,就能直接走索引排序了。

同时orderby的字段也需要满足组合索引的严格顺序。正确的应该是 phone、Insurance_id。


总结: orderby走索引排序,需要满足组合索引的最左前缀匹配,且字段循序需要满足最左前缀匹配原则,或者orderby使用在单独索引列上。
总的来说,Using filesort 是Mysql里一种速度比较慢的外部排序,如果能避免是最好的了,很多时候,我们可以通过优化索引来尽量避免出现Using filesort,从而提高速度。
重要的工具sql语句分析工具explain
type
需要了解的是type字段的作用,展示sql语句是否走索引。
分 all、index、range、const、system
-
ALL:Full Table Scan, MySQL将遍历全表以找到匹配的行。
-
index:Full Index Scan,index与ALL区别为index类型只遍历索引树。
-
range: 索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<, >查询。
-
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。
-
ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
-
eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件。
key
key展示的是sql语句中使用到的索引字段,但不一定在查询中使用。
ref
描述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。















 721
721











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









