






Python爬虫初步
1 相关概念
- 爬虫:用编写代码的方式去获取互联网上的资源(写程序去模拟浏览器用来抓取互联网上的内容)
- 具体操作:用程序去模拟浏览器,输入一个网址,去获取该网址的资源或者内容
1.1 web请求过程剖析
以百度为例:
- 在访问百度的时候, 浏览器会把这⼀次请求发送到百度的服务器(百度的⼀台电脑), 由服务器接收到这个请求, 然后加载⼀些数据. 返回给浏览器, 再由浏览器进行显示。
- 百度的服务器返回给浏览器的不直接是页面,而是页面源代码(由html, css, js组成)。由浏览器把页面源代码进行执行, 然后把执行之后的结果展示给用户。
- 图示:

页面渲染的两种方式:
- 服务器渲染 (相对比较容易就能抓取到页面内容)
在请求到服务器的时候, 服务器直接把数据全部写⼊到html中, 我们浏览器就能直接拿到带有数据的html内容。由于数据是直接写在html中的, 所以我们能看到的数据都在页面源代码中能找的到的。 - 前端js渲染 / 客户端渲染(好处是服务器那边能缓解压力,而且分工明确, 比较容易维护)
⼀般是第⼀次请求服务器返回⼀堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进行加载,如下图示:

1.2 HTTP协议
- 协议:两个计算机之间为了能够流畅的进行沟通而设置的⼀个君子协定. 常见的协议有TCP/IP. SOAP协议, HTTP协议,SMTP协议等等…
- HTTP协议(浏览器和服务器之间的协议), Hyper Text Transfer Protocol(超⽂本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
- HTTP协议把⼀条消息分为三大块内容. 无论是请求还是响应都是三块内容:
请求: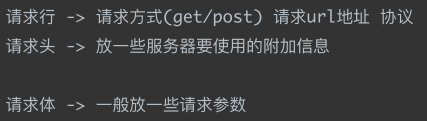
响应:
请求头中最常见的⼀些重要内容(爬虫需要):
1.User-Agent : 请求载体的身份标识(用啥发送的请求)
2.Referer: 防盗链(这次请求是从哪个页面来的? 反爬会用到)
3.cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
响应头中⼀些重要的内容:
1.cookie: 本地字符串数据信息(用户登录信息, 反爬的token)
2.各种神奇的莫名其妙的字符串(这个需要经验了, ⼀般都是token字样, 防止各种攻击和反爬)
请求方式:
GET: 显示提交
POST: 隐示提交
1.3 requests模块
用urllib来抓取页面源代码. 这个是python内置的⼀个模块。
但我们常用的爬虫工具,常用的抓取页面的模块通常使用⼀个第三方模块requests. 这个模块的优势就是比urllib还要简单, 并且处理各种请求都比较方便。
安装办法:
pip install requests
安装速度慢的话可以改用国内的源进行下载安装:
pip install -i
https://pypi.tuna.tsinghua.edu.cn/simple requests
案例——抓取搜狗搜索内容(仅供参考):

2 数据解析
主要学习了三种解析(可以混合使用)的方式:
- re解析
- bs4解析
- xpath解析
2.1 re解析(含正则表达式)
- 正则表达式(Regular Expression):⼀种使用表达式的方式对字符串进行匹配的语法规则。
- 正则的优点: 速度快, 效率高, 准确性高
- 正则的缺点: 上手难度有点儿高
- 正则的语法: 使用元字符进行排列组合用来匹配字符串
- 在线测试正则表达式:https://tool.oschina.net/regex/
元字符: 具有固定含义的特殊符号
常用元字符:


量词: 控制前面的元字符出现的次数

贪婪匹配和惰性匹配:
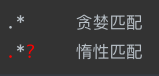
规律: .? 表示尽可能少的匹配 , . 表示尽可能多的匹配。
2.2 bs4解析
bs4模块安装:
pip install bs4
如果安装的速度慢, 建议更换国内源(推荐阿里源或者清华源)
pip install -i
https://pypi.tuna.tsinghua.edu.cn/simple bs4
bs4使用方法: 需要参照⼀些html的基本语法
案例分析:
尝试抓取北京新发地市场的农产品价格(仅供学习)http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml
1.先获取页面源代码. 并且确定数据就在页面源代码中
import requests
from bs4 import BeautifulSoup
url = "http://www.xinfadi.com.cn/marketanalysis/0/list/1.shtml"
resp = requests.get(url)
print(resp.text)
2.将页面源代码丢给BeautifulSoup, 然后我们就可以通过bs对象去检索页面源代码中的html标签
page = BeautifulSoup(resp.text)
3.BeautifulSoup对象获取html中的内容主要通过两个方法来完成。
不论是find还是find_all 参数几乎是⼀致的。
语法:
find(标签, 属性=值)
意思是在页面中查找 xxx标签, 并且标签的xxx属性必须是xxx值
find_all()的用法和find()几乎⼀致,find()查找1个,find_all()查找页面中所有的。
注意!!!
这种写法会有些问题, 比如html标签中的class属性。
<div class="honor">
page.find("div", class="honor")
注意, python中class是关键字,会报错的。怎么办呢? 可以在class后⾯加个下划线。
page.find("div", class_="honor")
可以使用第二种写法来避免这类问题出现:
page.find("div", attrs={"class": "honor"})
# 解析数据
# 1. 把页面源代码交给BeautifulSoup进行处理, 生成bs对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器
# 2. 从bs对象中查找数据
# find(标签, 属性=值)
# find_all(标签, 属性=值)
# table = page.find("table", class_="hq_table") # class是python的关键字
table = page.find("table", attrs={"class": "hq_table"}) # 和上一行是一个意思. 此时可以避免class
# 拿到所有数据行
trs = table.find_all("tr")[1:]
for tr in trs: # 每一行
tds = tr.find_all("td") # 拿到每行中的所有td
name = tds[0].text # .text 表示拿到被标签标记的内容
low = tds[1].text # .text 表示拿到被标签标记的内容
avg = tds[2].text # .text 表示拿到被标签标记的内容
high = tds[3].text # .text 表示拿到被标签标记的内容
gui = tds[4].text # .text 表示拿到被标签标记的内容
kind = tds[5].text # .text 表示拿到被标签标记的内容
date = tds[6].text # .text 表示拿到被标签标记的内容
csvwriter.writerow([name, low, avg, high, gui, kind, date])
2.3 xpath解析
xpath 是在XML文档中搜索内容的一门语言,html是xml的一个子集。
安装lxml模块:
pip install lxml -i xxxxxx
from lxml import etree
tree = etree.parse("1.html")
result = tree.xpath("/html/body/ul/li/a/@href")
print(result)
result = tree.xpath("/html/body/ul/li")
for li in result:
print(li.xpath("./a/@href")) # 局部解析
result = tree.xpath("//div[@class='job']/text()")
# [@class='xxx']属性选取 text()获取⽂本
print(result)
具体解析参考:
tree = etree.XML(xml)
# result = tree.xpath("/book") # /表示层级关系. 第一个/是根节点
# result = tree.xpath("/book/name")
# result = tree.xpath("/book/name/text()") # text() 拿文本
# result = tree.xpath("/book/author//nick/text()") # // 后代
# result = tree.xpath("/book/author/*/nick/text()") # * 任意的节点. 通配符(会儿)
result = tree.xpath("/book//nick/text()")
print(result)
















 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











