






Set接口学习小结
Set接口概述
(1)Set接口是Collection接口的子接口,集合中的元素是无序且不可重复的
(2)可以存放null值
(3)Set接口的常用实现类有:HashSet、LinkedHashSet、TreeSet
一、HashSet
遗留问题:为什么hashset每次添加成功后,table里面的值都会实时改变,在哪里赋的值呢???有没有大佬帮忙解答一下
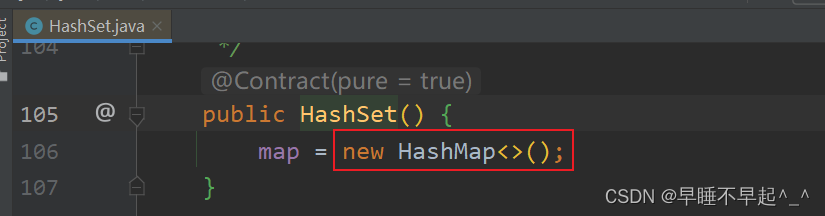
HashSet是基于哈希表的实现(内部实际就是一个HashMap)
HashSet特点:
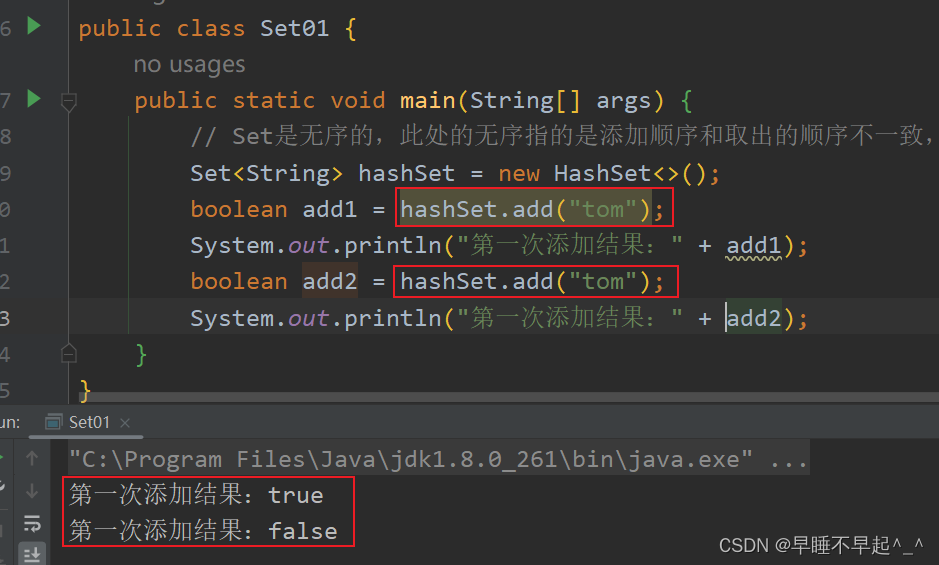
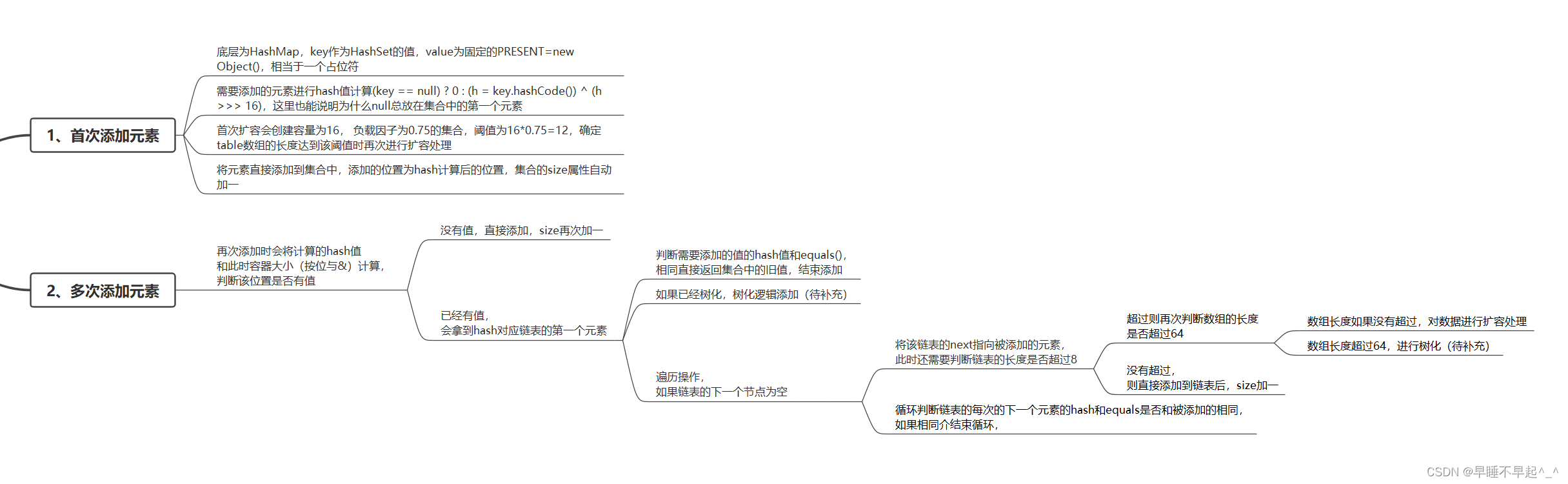
1、hashSet是无序的,无序指的是数据取出的顺序和添加进去的顺序无关,但是在内部按照自己的规则存放
2、hashSet不会有重复的元素,可以添加null值,重复添加数据会返回false
hashSet底层是数组+链表(单向)+ 红黑树
1、构造方法
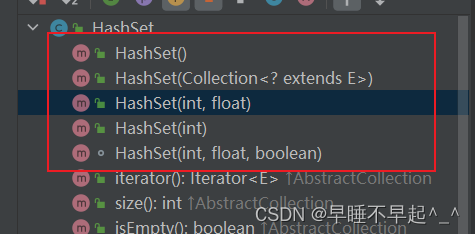
HashSet():构造一个新的空集合; 背景HashMap实例具有默认初始容量(16)和负载因子(0.75)HashSet(Collection<? extends E> c):构造一个包含指定集合中的元素的新集合。HashSet(int initialCapacity): 构造一个新的空集合; 背景HashMap实例具有指定的初始容量和默认负载因子(0.75)。HashSet(int initialCapacity, float loadFactor):构造一个新的空集合; 背景HashMap实例具有指定的初始容量和指定的负载因子。
注意:负载因子是HashSet扩容的关键参数,每次扩容大小取决与初始容量*负载因子
2、HashSet扩容源码分析
- HashSet的底层是HashMap,HashMap的底层实现是数组+链表+红黑树
- HashSet的去重机制是通过比较HashCode()和equals(),此处的hashCode和哈希值不一样
- HashSet当数组长度超过64且链表深度超过8才会树化
hashSet的结构分析
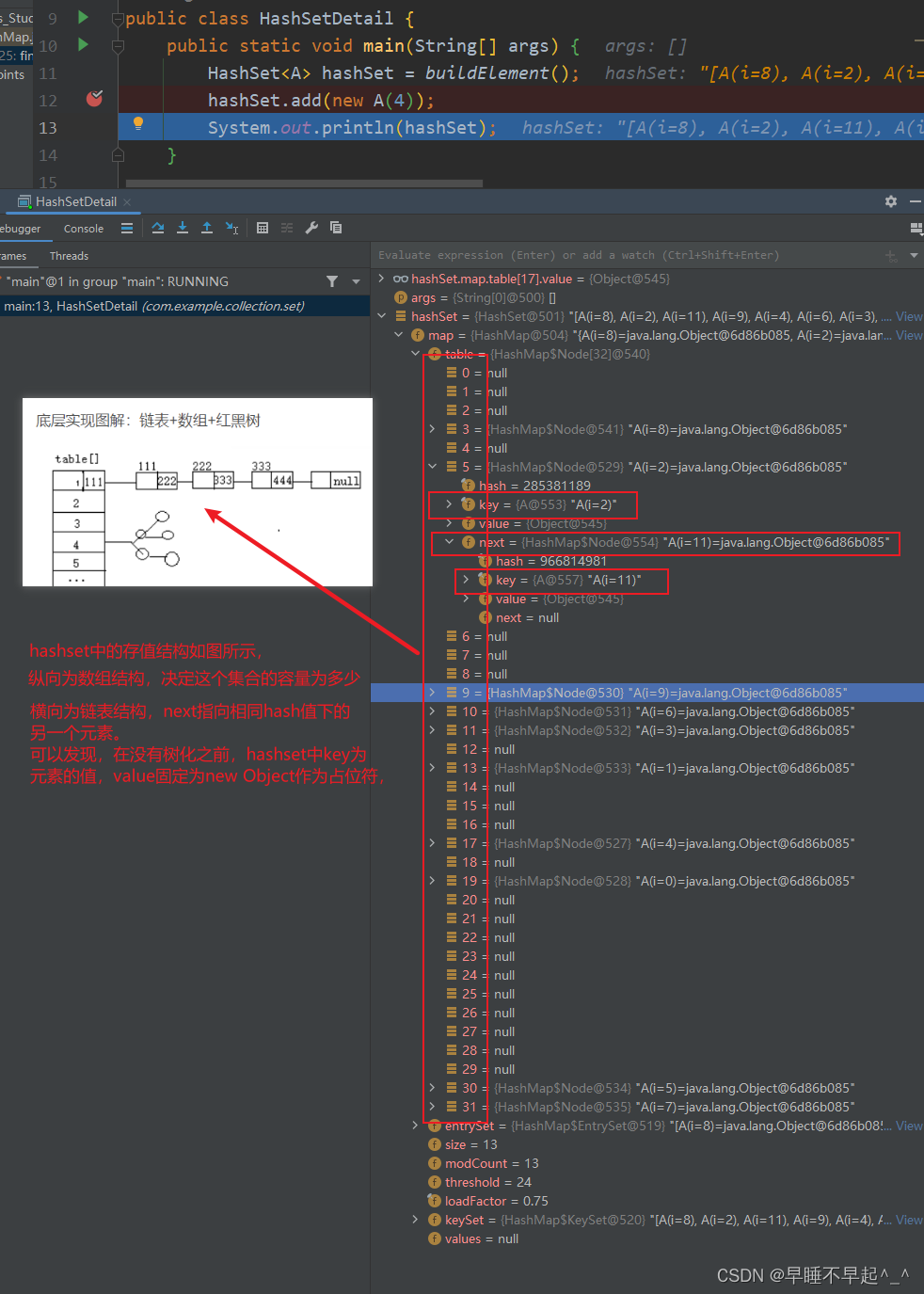
(1)源码可以看出,HashSet实际就是调用HashMap的构造方法,添加元素时也是把key作为HashMap的key,其值存入的为一个空对象
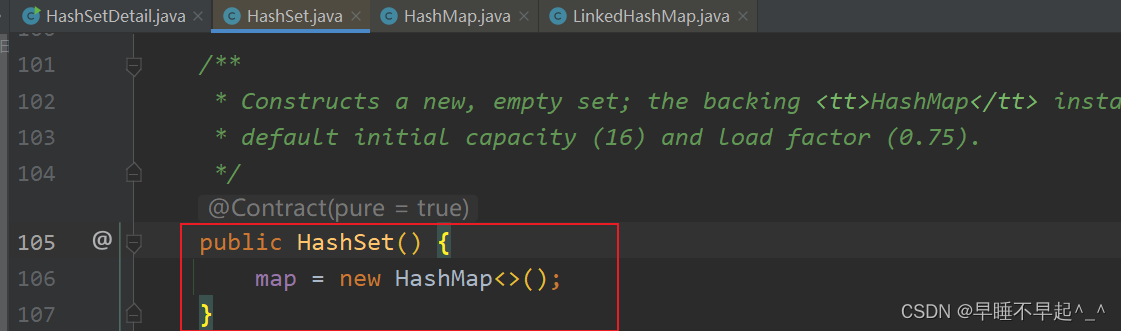
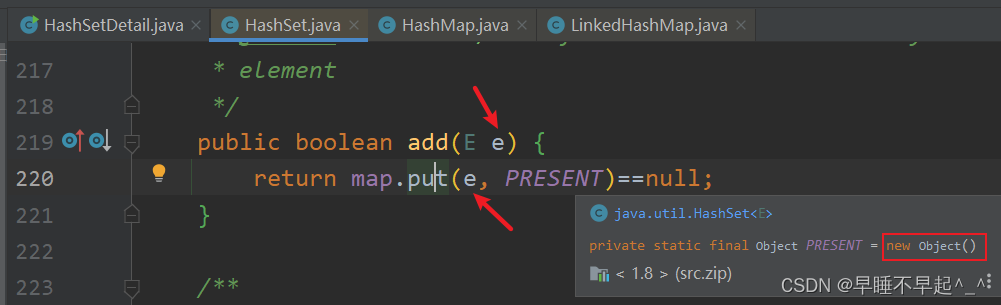
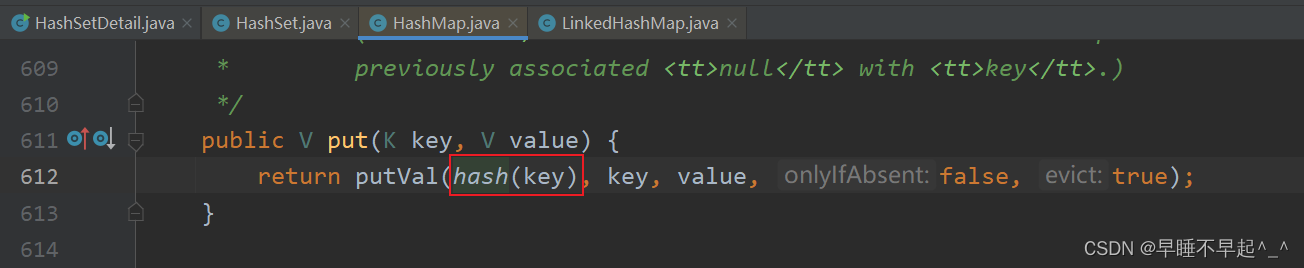
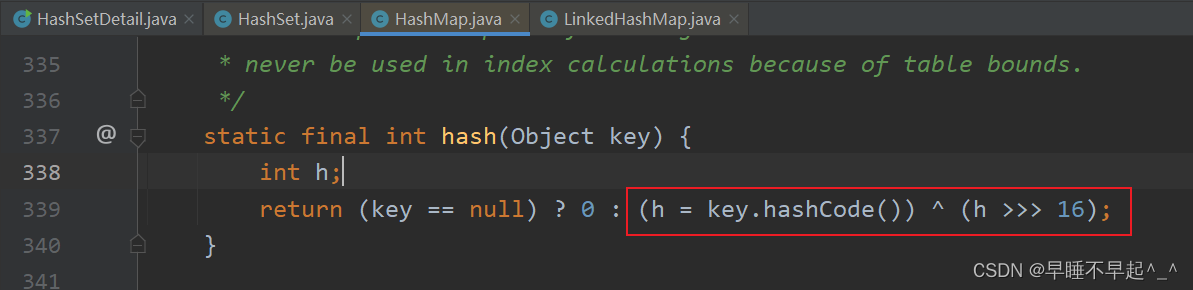
(2)添加元素进来时,会根据传入元素的值调用hash(),这里可以看出HashSet的HashCode()和哈希值不是同一个,哈希值是通过hashCode方法加上计算出的哈希值再右移16位计算出来的
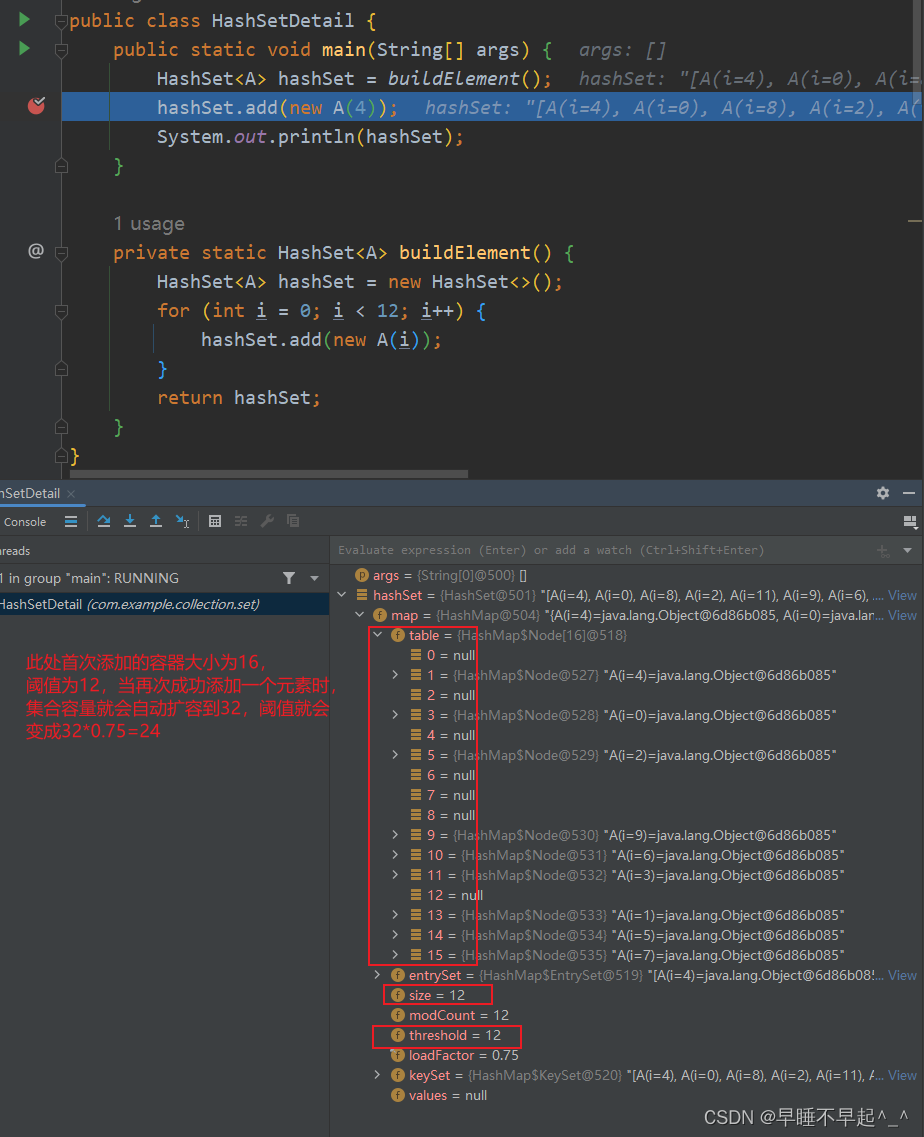
(3)通过断点调试发现,首次添加元素,会调用resize(),会初始将table扩容为16个空间大小,扩容的阈值为16*0.75(负载因子)计算出下次要扩容的临界值12。由于是首次添加,将元素添加到集合中
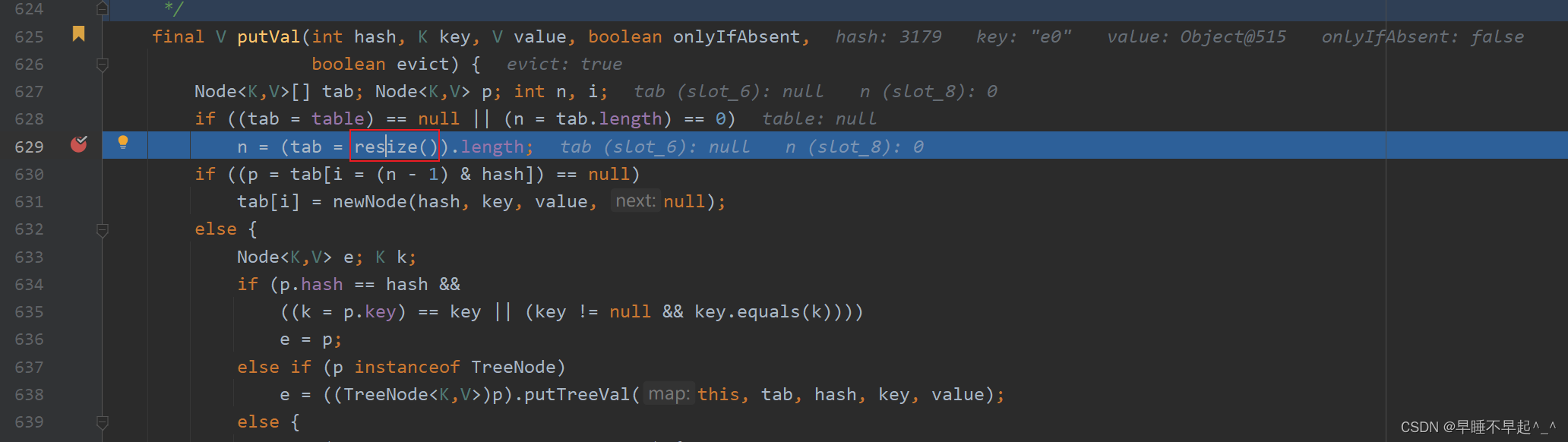
首次扩容方法
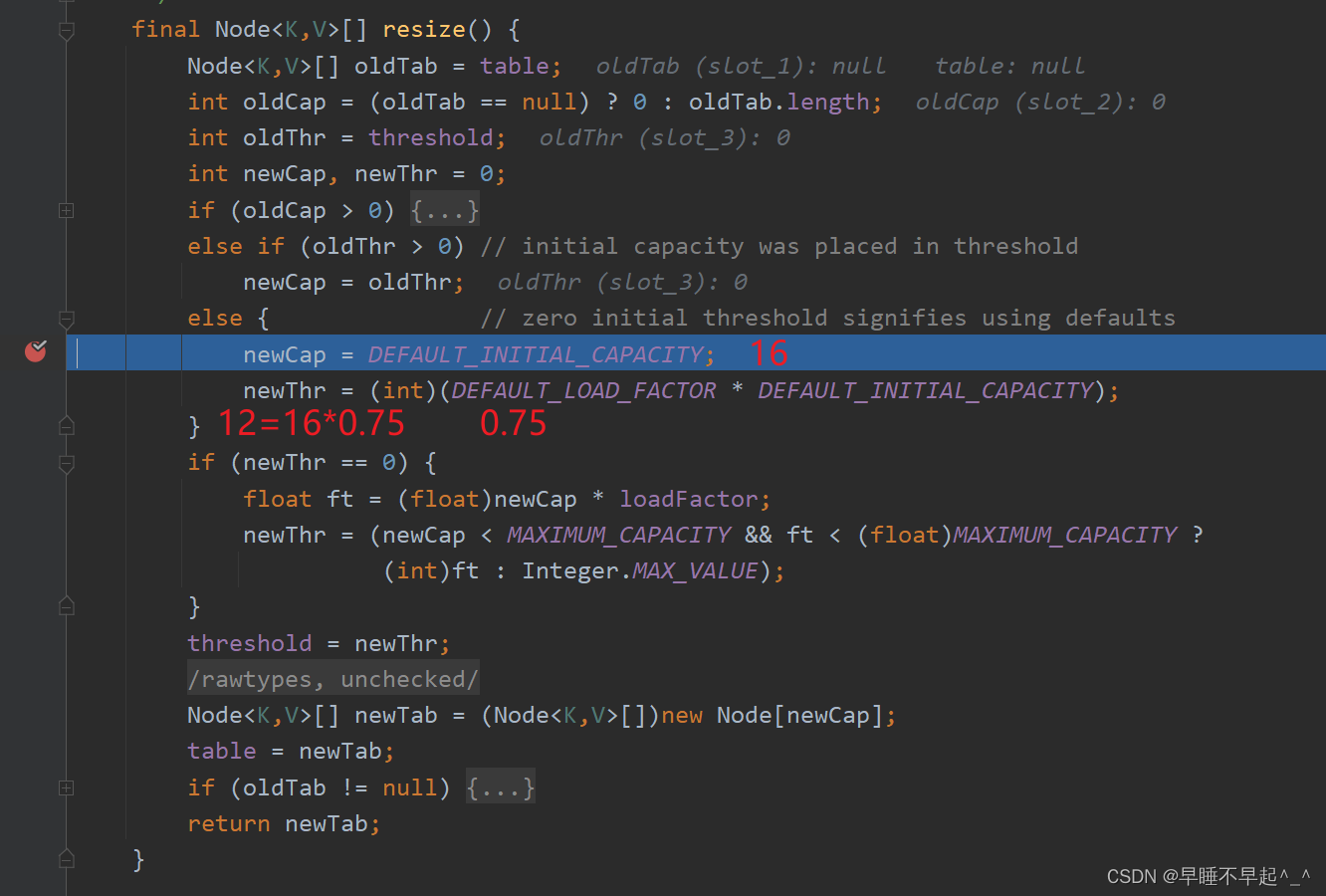
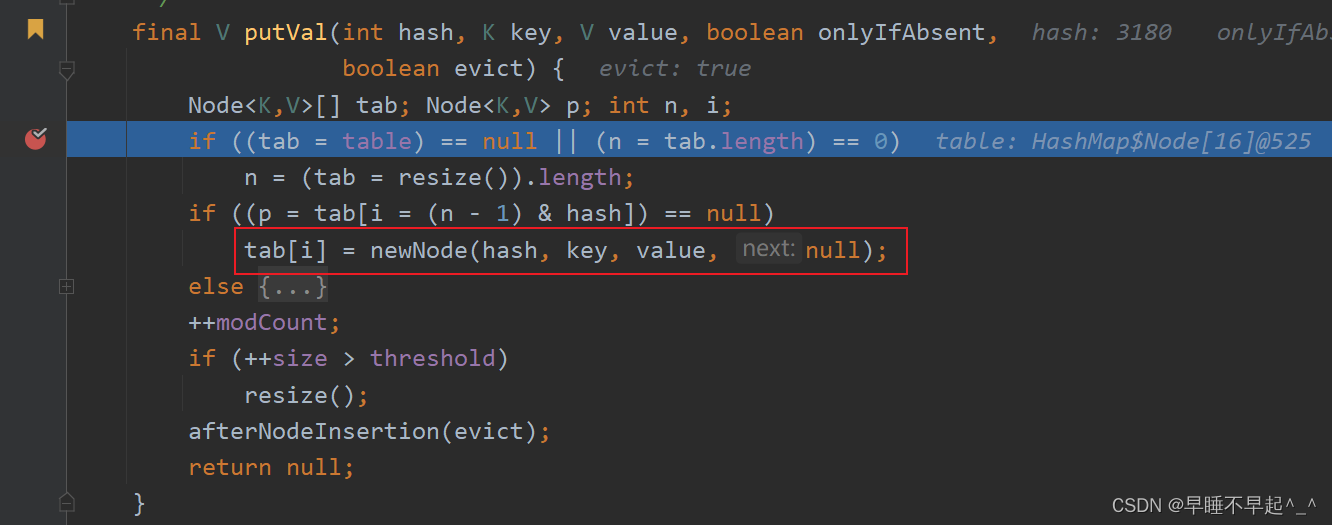
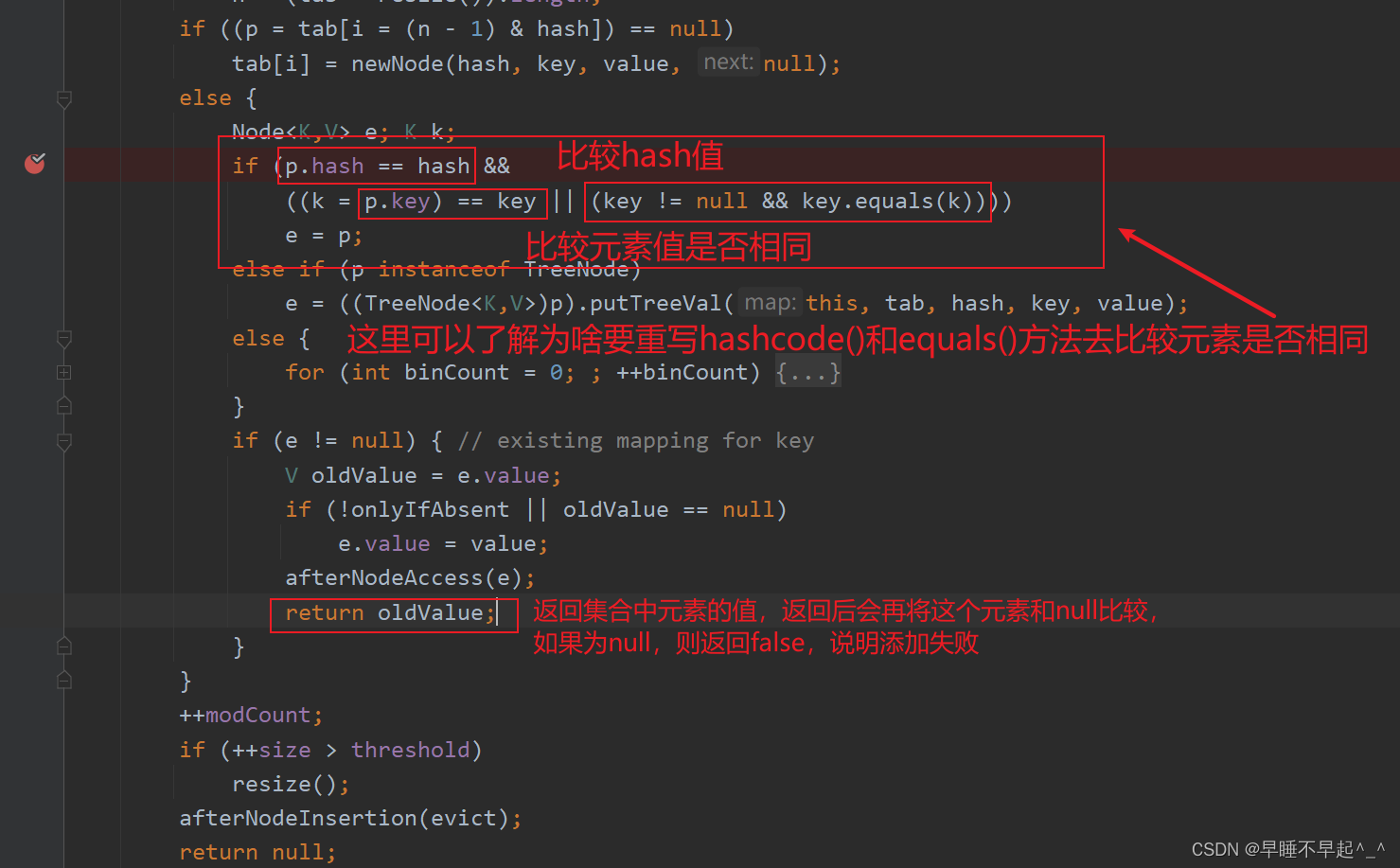
再次添加时,如果被添加元素的哈希值和集合中的元素存在相同的哈希值,并且被添加元素的值和集合中相同,则返回集合中已存在的值,则会添加失败,这里可以理解为啥都要重写hash值和equals去比较两个元素是否相同
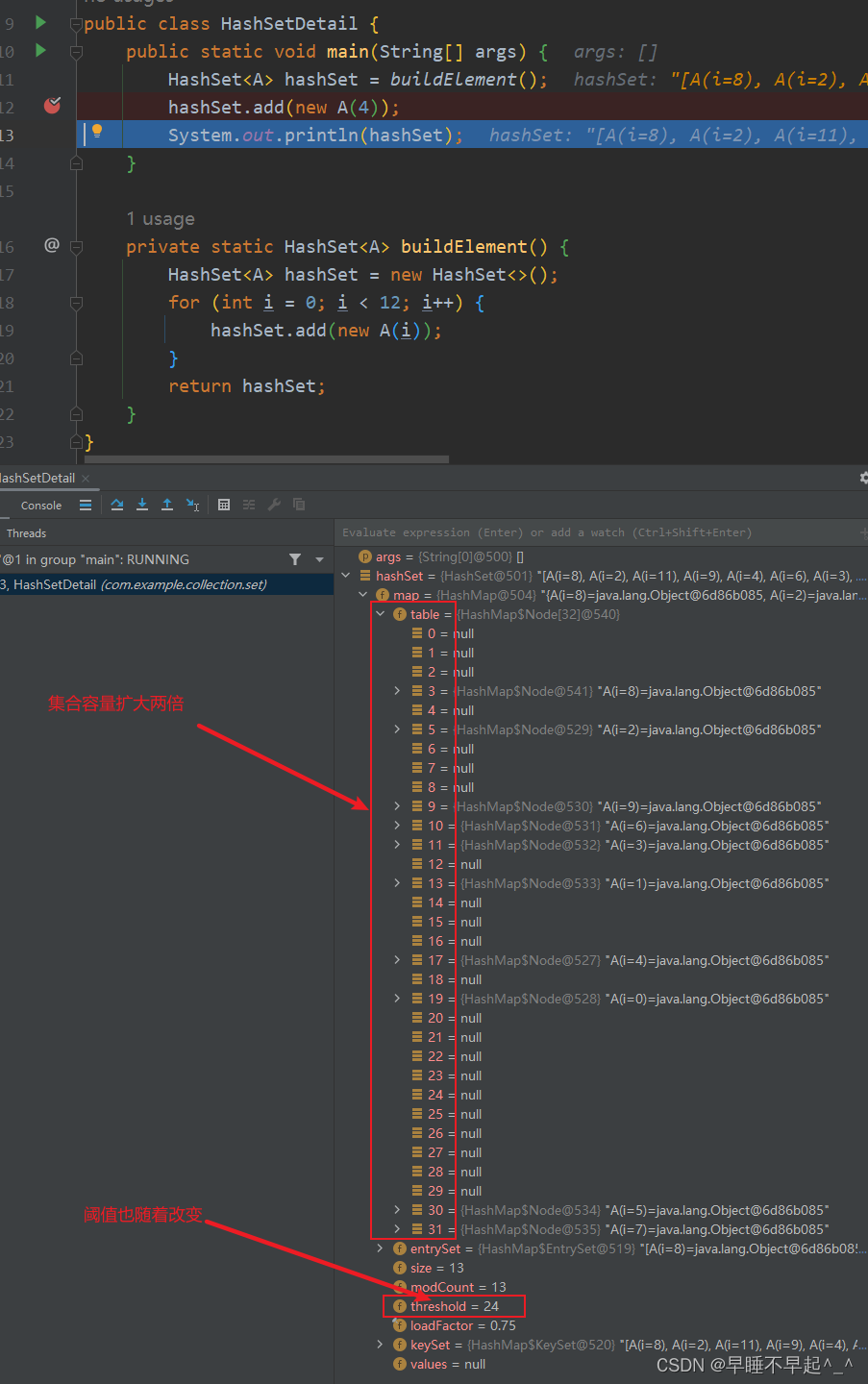
再次添加时,循环判断该链表上的后续元素是不是为空,如果不为null,再判断链表的深度是否超过8;如果超过8,再次调用resize()方法进行判断table数组的长度是否超过64,超过64则进行树化(待补充),否则,继续进行table数组的扩容。此处断点可以看出真正树化操作是在数组长度大于64且链表深度超过8两个条件都满足时才进行树化
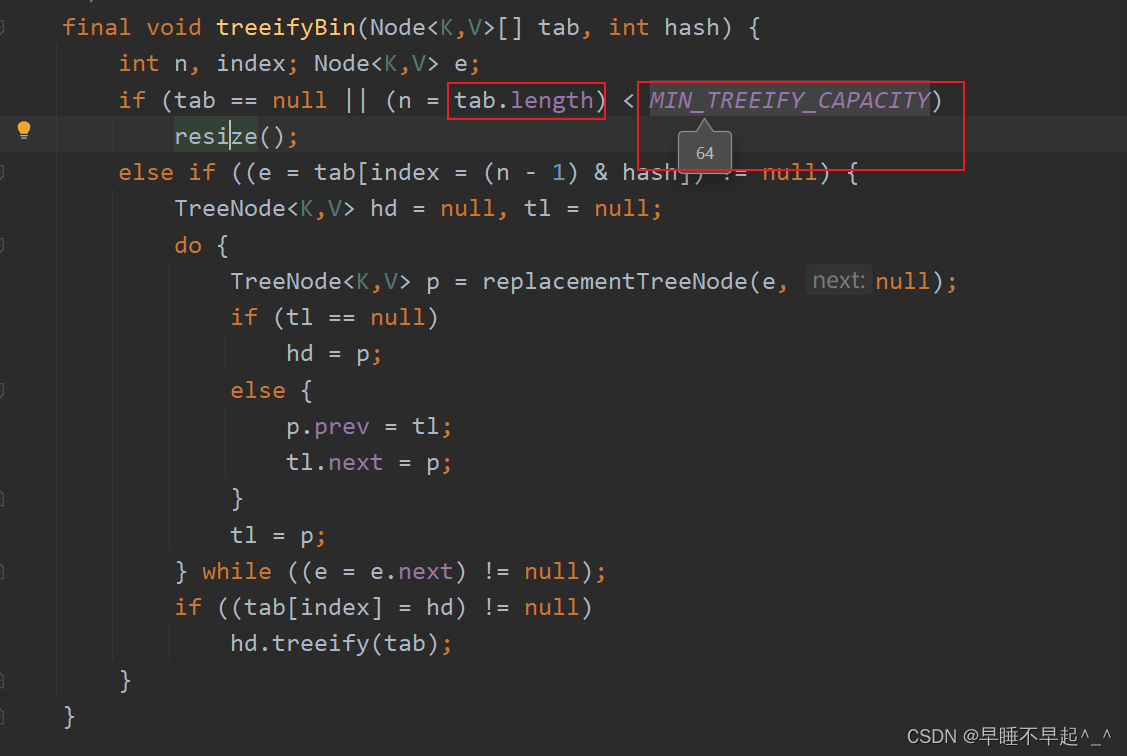
逻辑示意图如下
注意:每次成功添加元素后的size都会加一,这里作用是为了记录集合长度到阈值后,下次就会直接将集合扩容
在到达阈值后再次添加元素,直接扩容
二、LinkedHashSet
LinkedHashSet是Set中唯一一个有序的集合,其底层是LinkedHashMap,通过数组+双向链表+红黑树实现。
LinkedHashSet特点:
- LinkedHashSet中没有重复元素
- LinkedHashSet中维护了元素的添加顺序,所以是有序的
1、构造方法
LinkedHashSet()构造一个具有默认初始容量(16)和负载因子(0.75)的新的,空的链接散列集。LinkedHashSet(Collection<? extends E> c)构造与指定集合相同的元素的新的链接散列集。LinkedHashSet(int initialCapacity)构造一个具有指定初始容量和默认负载因子(0.75)的新的,空的链接散列集。LinkedHashSet(int initialCapacity, float loadFactor)构造具有指定的初始容量和负载因子的新的,空的链接散列集。
2、LinkedHashSet扩容源码分析
LinkedHashSet的底层是LinkedHashMap,LinkedHashSet继承了HashSet,扩容机制和HashSet类似;与HashSet不同的是,LinkedHashSet是有序的,内部是通过双向链表来确定元素的顺序。
LinkedHashSet添加元素扩容和HashSet类似,不在赘述,下面仅仅分析差异点。
① LinkedHashSet中多了head和tail两个属性记录集合的头和尾节点
② LinkedHashSet的table中存储的元素类型为LinkedHashMap$Entry,而HashSet中存储为Node类型,LinkedHashSet的table中的Entry中通过before和after记录元素的顺序
差异点①
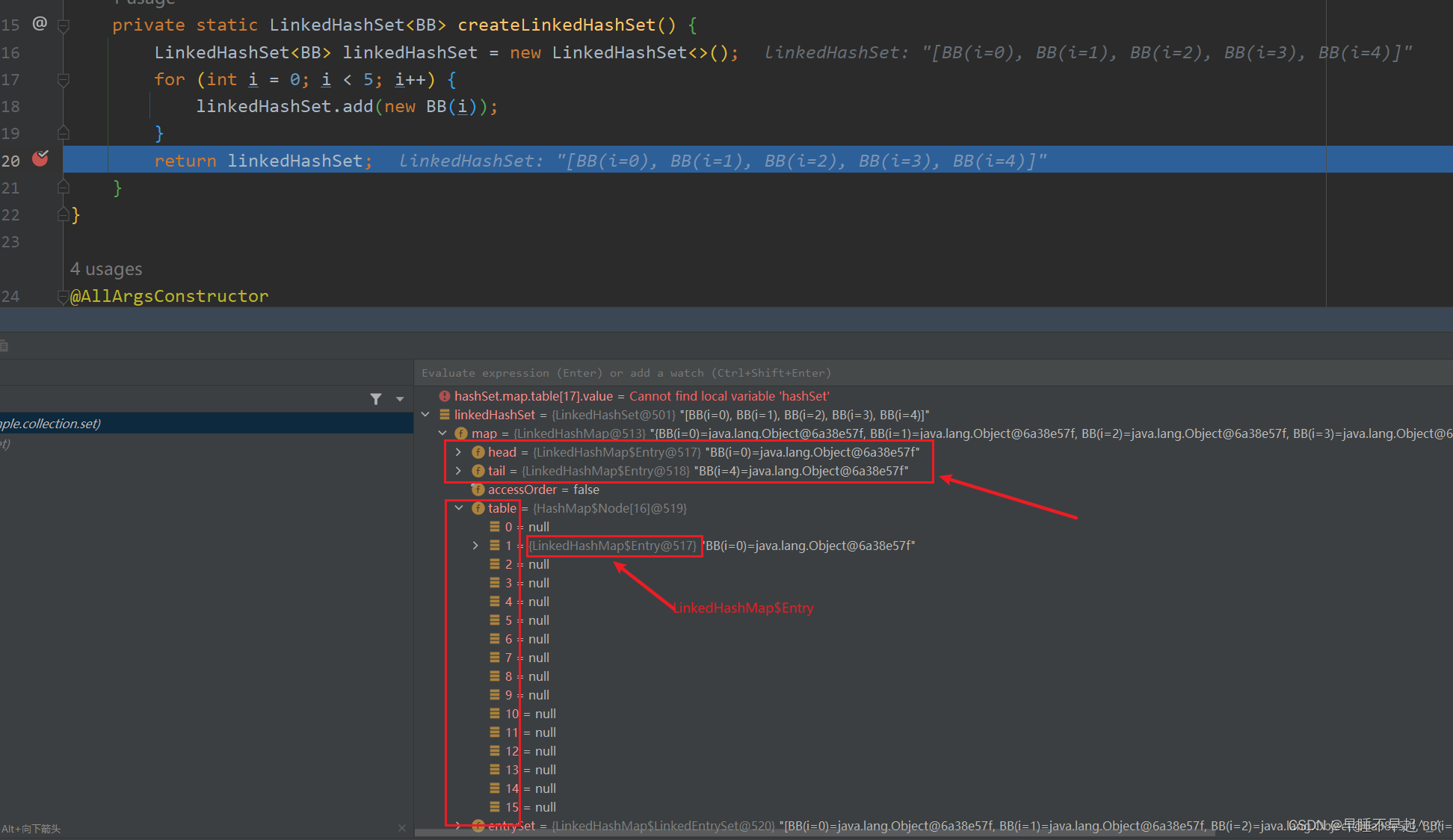
差异点②,源码可以看出Entry继承了HashMap.Node这个静态内部类实现,但是LinkedHashMap多了before和after去记录元素间的顺序
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
添加元素时,LinkedHashMap的重写newNode方法,创建前后两个元素的关联关系
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
// 判断集合的尾节点元素是否为空,
if (last == null)
// 为空则将head也指向被创建的元素,
head = p;
else {
// 不为空,则通过before指向上一个元素,上一个元素的last指向该元素
p.before = last;
last.after = p;
}
}
如果集合中元素的hash值不一样,只会记录元素的before和after的关联关系
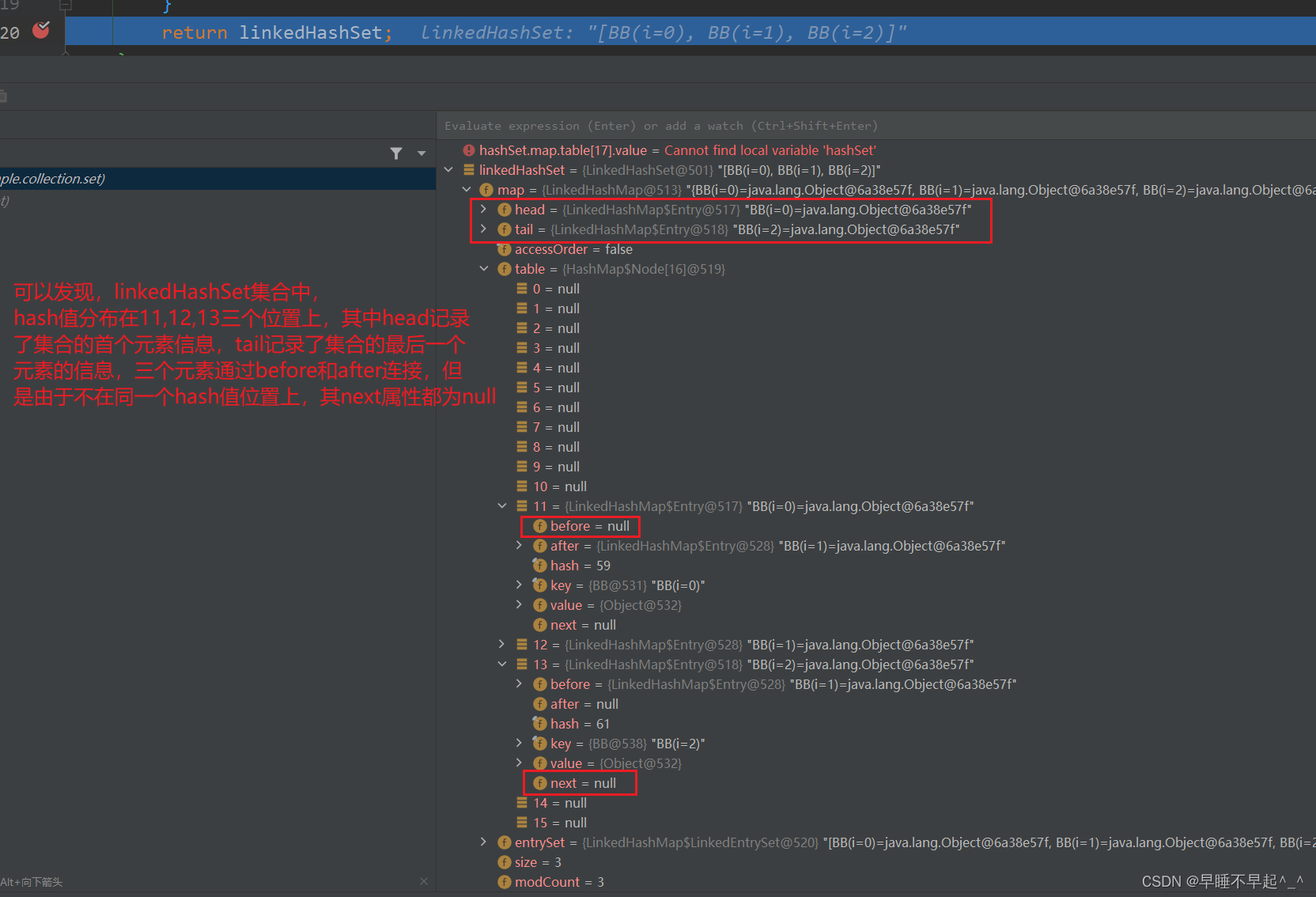
如果两个元素的hash值一样,也会通过next记录在同一个hash值的元素信息
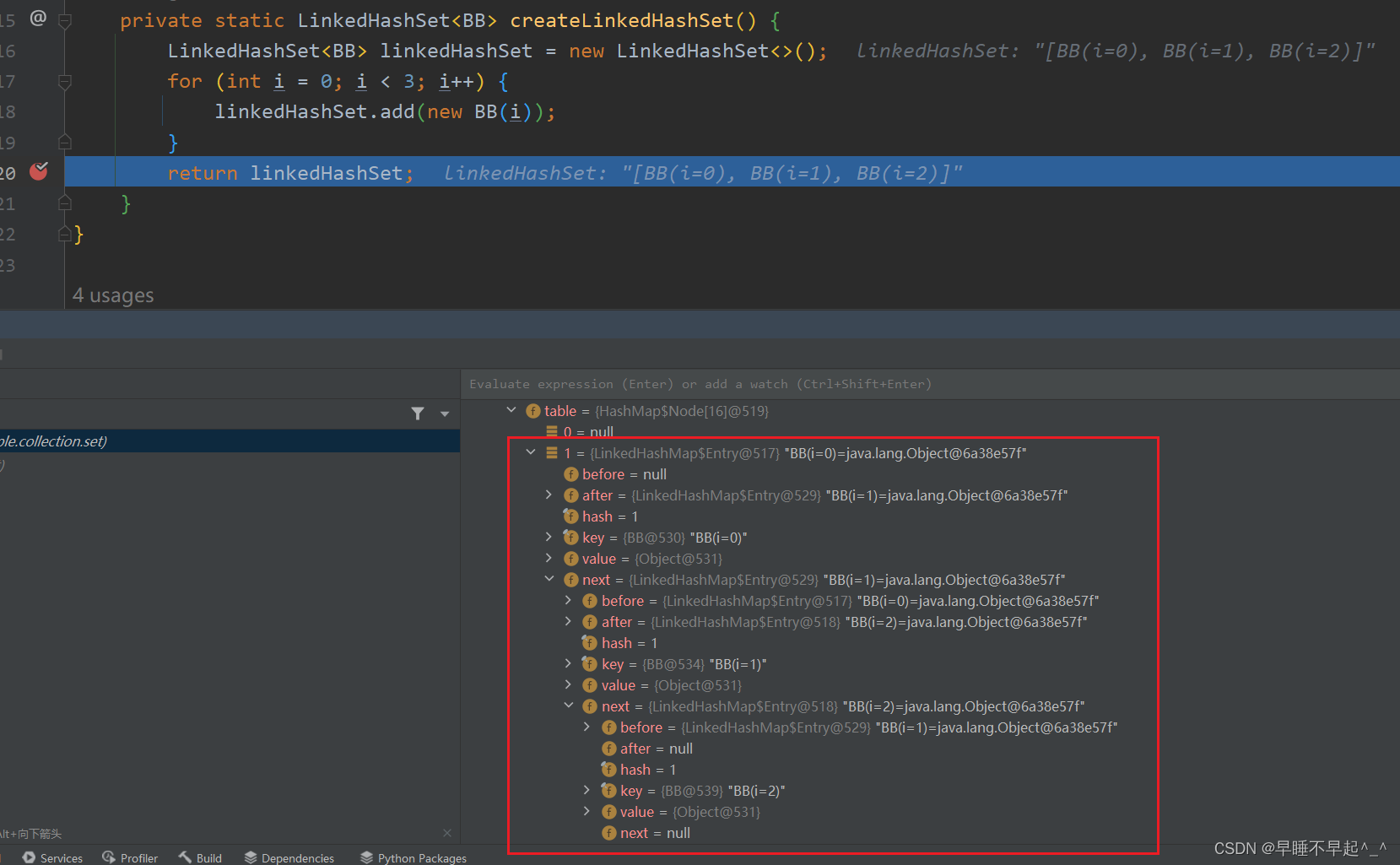
由此可以发现,next字段记录的是在同一个hash值上,也就是table的同一个位置,链表上存在不同元素的关联关系















 173
173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









