







目录
-
-
线性表
-
根据物理存储位置是否连续
- 顺序表
- 表中元素顺序的存储在一片连续的存储空间中
- 链式表
- 表中元素存放在通过链接构造在一起的存储空间中
- 顺序表
-
线性表的ADT
-
-
-
顺序表
-
数据结构
- 逻辑结构
- 数据本身/数据的地址顺序存储
- 物理结构
- 连续的内存空间
- 逻辑结构
-
实现
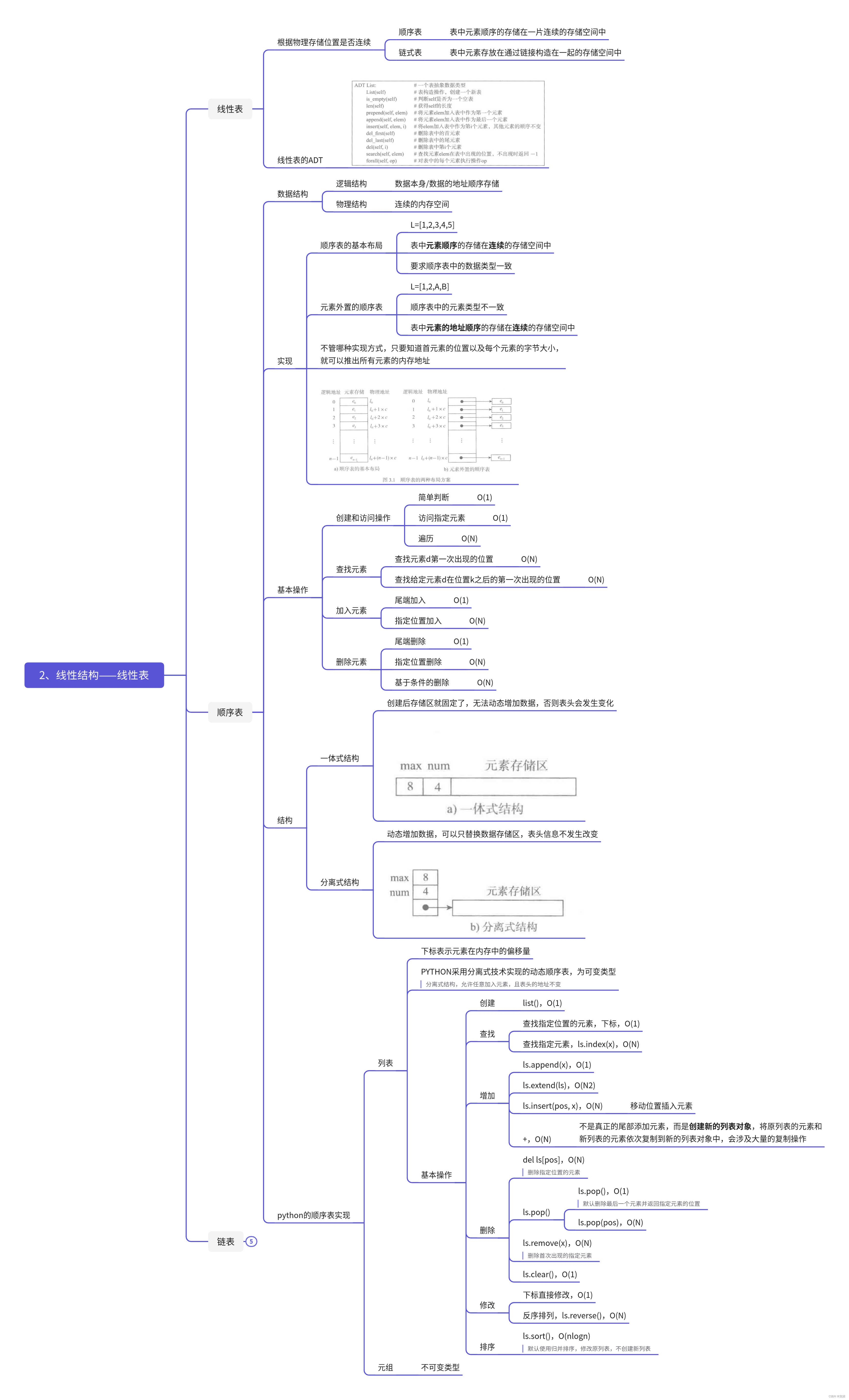
- 顺序表的基本布局
- L=[1,2,3,4,5]
- 表中元素顺序的存储在连续的存储空间中
- 要求顺序表中的数据类型一致
- 元素外置的顺序表
- L=[1,2,A,B]
- 顺序表中的元素类型不一致
- 表中元素的地址顺序的存储在连续的存储空间中
- 不管哪种实现方式,只要知道首元素的位置以及每个元素的字节大小,就可以推出所有元素的内存地址
-

- 顺序表的基本布局
-
基本操作
- 创建和访问操作
- 简单判断
- O(1)
- 访问指定元素
- O(1)
- 遍历
- O(N)
- 简单判断
- 查找元素
- 查找元素d第一次出现的位置
- O(N)
- 查找给定元素d在位置k之后的第一次出现的位置
- O(N)
- 查找元素d第一次出现的位置
- 加入元素
- 尾端加入
- O(1)
- 指定位置加入
- O(N)
- 尾端加入
- 删除元素
- 尾端删除
- O(1)
- 指定位置删除
- O(N)
- 基于条件的删除
- O(N)
- 尾端删除
- 创建和访问操作
-
结构
- 一体式结构
- 创建后存储区就固定了,无法动态增加数据,否则表头会发生变化
-

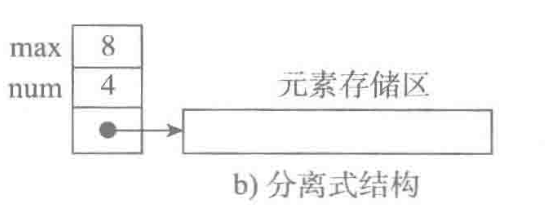
- 分离式结构
- 动态增加数据,可以只替换数据存储区,表头信息不发生改变
-
- 一体式结构
-
python的顺序表实现
-
列表
- 下标表示元素在内存中的偏移量
- PYTHON采用分离式技术实现的动态顺序表,为可变类型
分离式结构,允许任意加入元素,且表头的地址不变 - 基本操作
- 创建
- list(),O(1)
- 查找
- 查找指定位置的元素,下标,O(1)
- 查找指定元素,ls.index(x),O(N)
- 增加
- ls.append(x),O(1)
- ls.extend(ls),O(N2)
- ls.insert(pos, x),O(N)
- 移动位置插入元素
- +,O(N)
- 不是真正的尾部添加元素,而是创建新的列表对象,将原列表的元素和新列表的元素依次复制到新的列表对象中,会涉及大量的复制操作
- 删除
- del ls[pos],O(N)
删除指定位置的元素 - ls.pop()
- ls.pop(),O(1)
默认删除最后一个元素并返回指定元素的位置 - ls.pop(pos),O(N)
- ls.pop(),O(1)
- ls.remove(x),O(N)
删除首次出现的指定元素 - ls.clear(),O(1)
- del ls[pos],O(N)
- 修改
- 下标直接修改,O(1)
- 反序排列,ls.reverse(),O(N)
- 排序
- ls.sort(),O(nlogn)
默认使用归并排序,修改原列表,不创建新列表
- ls.sort(),O(nlogn)
- 创建
-
元组
- 不可变类型
-
-

















 2808
2808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











