







一切皆文件,每个文件都有具体的用途
命令快捷查看目录
常用命令 - 目录类
1、ls 查看当前目录下的文件
- -a 显示所有文件及目录,能看到包括隐藏文件(以.开头的文件)及所有文件
- -l 详细信息(简写形式ll)
- -r 将文件以相反次序显示
- -t 将文件依建立的时间先后次序进行列出
- -A 同-a,但不列出 “.”,当前目录,“…”父目录
- -F 在列出文件后增加符合,例如目录后加“/”,可执行文件加“*”
- -R 若文件目录下有文件,则以下文件都依次列出(递归式列出全部文件)
[hadoop@node100 home]$ ls -a
. 1 2 3 abc.tar.gz emp文本.txt hxx qingtest test
.. 1.txt 2024 6.txt emp.txt hadoop oracle task.sh zhangsan
[hadoop@node100 home]$ ls -A
1 2 3 abc.tar.gz emp文本.txt hxx qingtest test
1.txt 2024 6.txt emp.txt hadoop oracle task.sh zhangsan
[hadoop@node100 home]$ ll
总用量 32
-rw-rw-r-- 1 hadoop hadoop 8 10月 21 2021 1
-rw-rw-r-- 1 hadoop hadoop 29 6月 4 16:25 1.txt
-rw-rw-r-- 1 hadoop hadoop 0 10月 21 2021 2
drwxrwxr-x 2 hadoop hadoop 6 6月 3 18:39 2024
drwxrwxr-x 2 hadoop hadoop 6 10月 21 2021 3
-rw-rw-r-- 1 hadoop hadoop 97 6月 4 15:56 6.txt
-rw-rw-r-- 1 hadoop hadoop 238 10月 21 2021 abc.tar.gz
-rw-r--r-- 1 root root 679 6月 4 15:44 emp.txt
-rw-r--r-- 1 root root 679 6月 4 15:44 emp文本.txt
drwx------. 16 hadoop hadoop 4096 6月 4 16:25 hadoop
drwxrwxr-x 3 hadoop hadoop 74 6月 4 15:30 hxx
drwx------ 2 oracle oracle 62 10月 21 2021 oracle
drwxrwxr-x 3 hadoop hadoop 34 6月 3 18:47 qingtest
-rwxrw-r-- 1 hadoop hadoop 20 10月 21 2021 task.sh
drwxr--r--. 3 hadoop hadoop 165 6月 3 17:36 test
drwx------ 4 1002 1002 112 10月 21 2021 zhangsan
[hadoop@node100 home]$
ll显示指定文件或目录的详细属性信息
文件类型,所有者、所属者、其他人的权限,目录或者链接的个数,所有者及所在的组,文件大小,文件最后修改日期时间,文件名,字体颜色(系统默认颜色)
- 灰白色表示普通文件;
- 亮绿色表示可执行文件;
- 亮红色表示压缩文件;
- 灰蓝色表示目录;
- 亮蓝色表示链接文件;
- 亮黄色表示设备文件
2、man查看命令详细信息
man ls
man cd
3、pwd 查看当前目录 -
返回绝对路径下的位置
[hadoop@node100 home]$ pwd
/home
4、cd 进入目录
~ 家目录,当前登录用户的用户目录
. 当前目录
… 上一级目录
…/… 上上层目录
- 回退到上一个操作
[root@node100 home]# pwd
/home
[root@node100 home]# cd .
[root@node100 home]# cd ..
[root@node100 /]# cd /home/hxx
[root@node100 hxx]# cd ../..
[root@node100 /]# cd -
/home/hxx
[root@node100 hxx]#
5、清屏命令
ctrl + l 或者 输入clear
6、mkdir创建目录
-p 可以递归创建文件夹,确保目录名称存在,不存在就创建
[hadoop@node100 hxx]$ ls
12.txt 2.txt 3.txt hxx_2023 test
[hadoop@node100 hxx]$ mkdir 2024
[hadoop@node100 hxx]$ ls
12.txt 2024 2.txt 3.txt hxx_2023 test
[hadoop@node100 hxx]$ mkdir -p 2024/2023/2022
[hadoop@node100 hxx]$ ls
12.txt 2024 2.txt 3.txt hxx_2023 test
[hadoop@node100 hxx]$ cd 2024
[hadoop@node100 2024]$ ls
2023
[hadoop@node100 2024]$
7、du查看文件或者文件夹大小
-h 以K,M,G为单位,提高信息的可读性
-k 以1024bytes为单位
-m 以1M为单位
[hadoop@node100 home]$ ls
1 2 3 abc.tar.gz emp文本.txt hxx qingtest test
1.txt 2024 6.txt emp.txt hadoop oracle task.sh zhangsan
[hadoop@node100 home]$ du -h abc.tar.gz
4.0K abc.tar.gz
[hadoop@node100 home]$ du -k task.sh
4 task.sh
[hadoop@node100 home]$ du -m abc.tar.gz
1 abc.tar.gz
常用命令 - 文件类
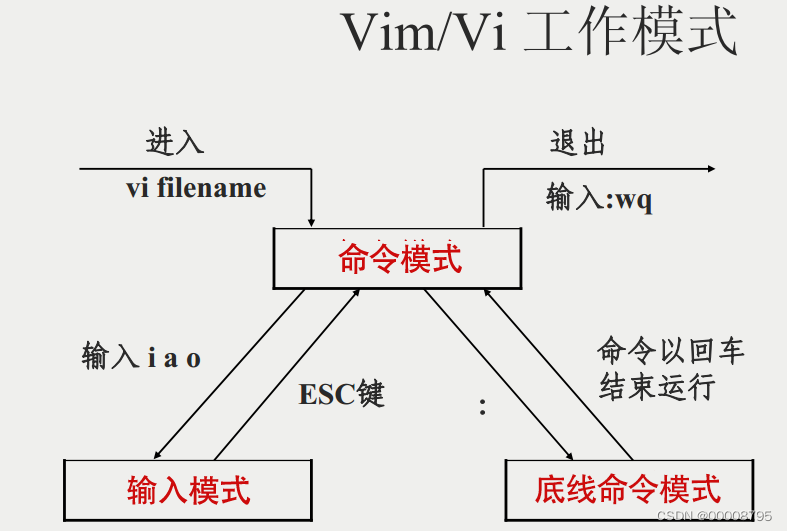
1、vim/vi使用
vim/vi finename 进入文件查看模式,vim是vi的增强版。使用vim/vi如果没有该文件时会自动创建一个临时文件,保存退出后会生成文件,不用是touch创建也可以
从查看模式进入插入/输入模式:i/o/a
查看模式下
:q 退出
:w 保存文件
:q! 强制退出
:wq 保存并退出
:ZZ 保存并退出
光标移动:
- gg 光标移动到文件头部
- G 光标移动到文件尾部
- H 光标移动到屏幕最顶端的一行
- M 光标移动到屏幕中间的一行
- L 光标移动到屏幕最底端的一行
yy 复制
p粘贴
5yy 当前行开始向下复制5行,p粘贴至下一行
dd 删除当前行,5dd删除当前行开始向下的5行内容
u 取消上一步操作
关键字查找内容
/匹配内容 然后回车; /开 匹配内容开字
n 查看下一个
:noh 取消查找
:set nu显示行号
:set nonu取消显示行号
以上都是在查看模式下进行的操作。
 菜鸟教程详细解答
菜鸟教程详细解答
 点击Esc键退出插入模式进入查看模式,然后:wq可以保存退出
点击Esc键退出插入模式进入查看模式,然后:wq可以保存退出
2、cat 查看文件内容
3、less / more 查看文件内容
less filename 查看文件内容,可以分页查看
上下箭头:上一行下一行
- G:最后一页
- g:第一页
- 空格:下一页
- b:上一页
- /:关键词 搜索关键词
- q:退出
按到最后一页不会自动退出
more filename 查看文件内容 分页查看,按到最后一页会退出查看模式
more -5 3.txt 限定每页展示5行,页数会按照指定的5行进行分页
回车后 按enter键 按行展示,按空格键,按页展示。
3、cp 复制文件
- -r 若给出的源文件是一个目录,此时将复制该目录下所有的子目录和文件
- -i 在覆盖目标文件之前,提示是否覆盖(-f不提示);如果本来没有这个文件就不会提示,会直接添加到指定的目录。
[hadoop@node100 hxx]$ ls
12.txt 2014 2024年06月04日 3.txt nofile.txt tar1
1.tar.gz 2024 2.txt hxx_2023 qq.txt test
[hadoop@node100 hxx]$ cp -i 12.txt 13.txt
[hadoop@node100 hxx]$ ls
12.txt 1.tar.gz 2024 2.txt hxx_2023 qq.txt test
13.txt 2014 2024年06月04日 3.txt nofile.txt tar1
[hadoop@node100 hxx]$ cp -i 12.txt 13.txt
cp:是否覆盖"13.txt"? y
4、mv 改名/剪切
- 改名:mv source_finame destination_filename
- 剪切:mv source_filename 目标目录
- 剪切目录:mv souce_directory 目标目录
如果不是当前目录的文件或者目录进行改名或者剪切要用绝对路径
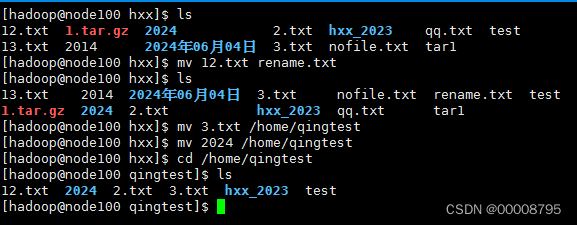
5、rm 删除
- -r 将目录及以下文档逐一删除
- -i 删除前逐一询问确认
- -f 直接删除 无需进行确认
- rmdir 专门删除空目录
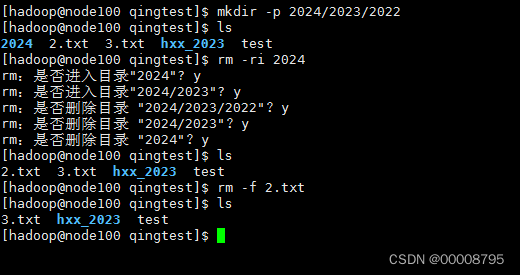
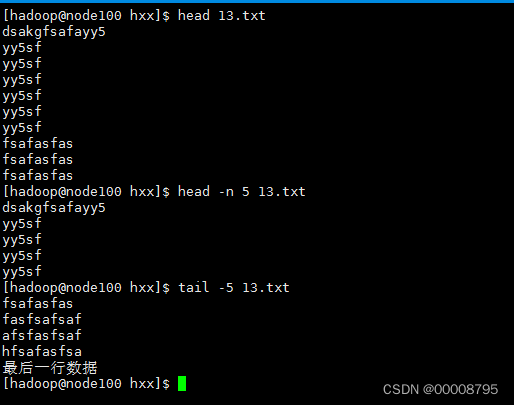
6、head/tail 查看文件前几行或者后几行
head 文件名 默认是头部10行
head -n 行数 文件名
head -n 5 a.txt
head -5 a.txt 可以省略n
查看文件末尾几行
tail 文件名 默认是尾部10行
tail -n 行数 文件名
tail -n 5 a.txt
tail -5 a.txt
7、tailf 监听文件尾部的变化
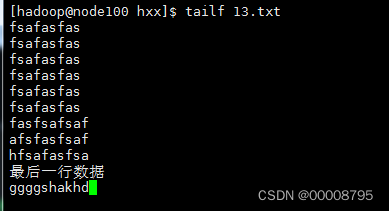 ctrl+c退出监听
ctrl+c退出监听
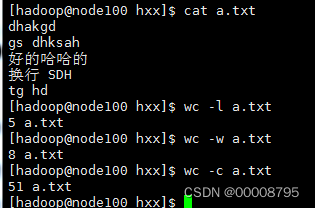
8、wc(word count) 查看文件行数
- wc -l 文件名称 查看文件行数
- wc -w 文件名称 查看文件有多少个单词(以空格或换行划分一个单词)
- wc -c 文件名称 查看文件有多少个字节;
-gbk中文字符占据两个,utf-8中文占据3个字节。在脚本中中文占据三个,注意空格会占据一个字节,换行会占据一个字节,光标结束符会占据一个字节
9、| 管道命令
把管道前面的命令当做管道后面命令的输入(a | b, 就是a命令最终结果是b的初始值)
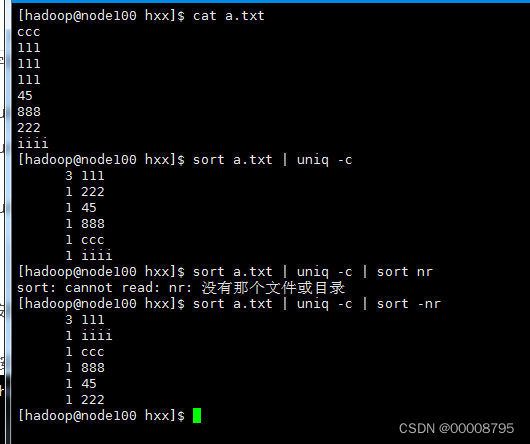
10、sort 对文件进行统计和排序
以行位单位,从首字符,逐位比较ASCII值
- sort filename | uniq -c 统计每行出现的次数
- sort filename | uniq -c | sort -n 按出现的次数进行升序排序
- sort filename | uniq -c | sort -n -r 按出现的次数进行降序排序
结合使用
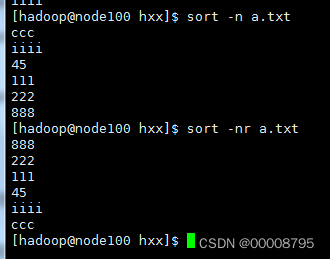
sort -n 升序排序(按照数字列进行升序排序)
sort -n -r 降序排序
sort -nr 降序排序(按照数字列进行降序排序 )
11、sed linux三剑客之一
对文件以行为单位进行增删改查
sed 命令操作 文件名字 (将操作结果显示在命令行里面,但是不会操作文件本身)
sed -i 命令操作 文件名字 (将操作结果写入到文件里面,但是不会显示在命令行中)
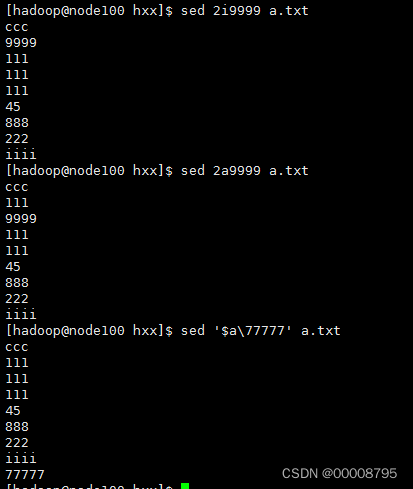
1、新增数据 将数据写入到某一行
sed ‘行号i\写入的内容’ 文件名字 (写入到指定的行)
sed ‘行号a\写入的内容’ 文件名字 (写入到指定行的下一行)
$:表示最后一行
如果没有特殊字符可以不用打引号
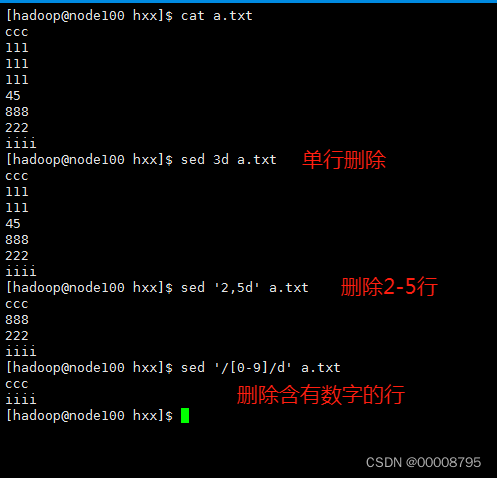
2、删除行数据
sed ‘行号d’ 文件名
sed 2d a.txt
删除多行数据
sed ‘开始行号,结束行号d’ 文件名
sed ‘d’ a.txt 删除所有行
sed ‘1,$d’ a.txt 删除所有行
sed -i ‘1,$d’ a.txt 会修改到文件本事
结合正则进行删除
sed ‘/正则/d’ 文件名
sed ‘/hello/d’ 8.txt
sed ‘/^[0-9].*[a-z]$/d’ 8.txt
–若要删除文件中的空行
sed ‘/^$/d’ 文件名
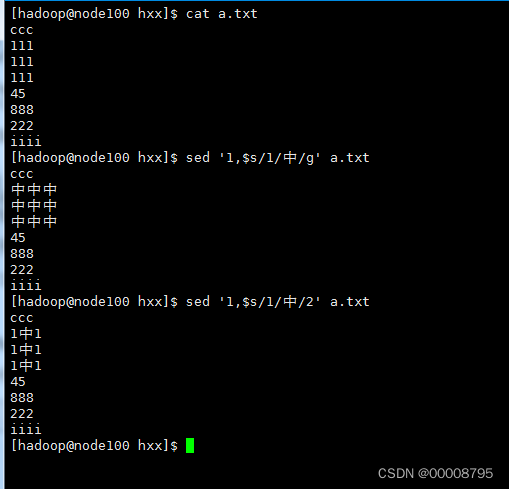
3、修改行数据
sed ‘行号s/要被修改的内容/修改成的内容/g’ 文件名
sed ‘1,$s/apple/苹果/g’ a.txt
s:表示查找 g:表示全部替换
若只替换个别 用数字1,2,3(匹配的全部行的第几个,然后替换指定的第几个)
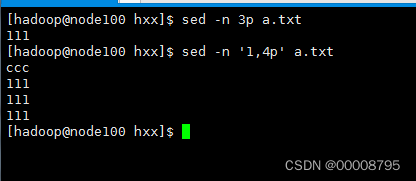
4、查询行数据
sed -n ‘行号p’ 文件名
sed -n ‘5p’ a.txt
sed -n ‘开始行号,结束行号p’ 文件名
sed -n ‘3,5p’ a.txt
试题
创建文件 /home/test1.txt
只查看每一行第一个点前面的数据:
www.baidu.com
image.baidu.com
tieba.baidu.com
v.baidu.com
map.baidu.com
map.baiduccom.com
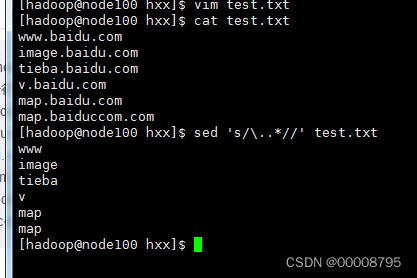
方法一:sed ‘s/.baidu.*//g’ /home/test1.txt
方法二:sed ‘1,$s/.baidu.*//g’ /home/test1.txt
方法三:sed ‘s/[.].*//g’ /home/test1.txt
方法四:awk -F ‘.’ ‘{print $1}’ test1.txt
12、grep linux三剑客之二
筛选和查找行数据(结合正则)
grep 正则 文件名
- 查询文件里所有数字开头的行的信息
grep '^[0-9]' a.txt
- 123或789开头的
grep '[1-37-9]' a.txt
- 查询文件里面,以大写字母结尾的数据
$ 进行结尾数据的判断
grep '[A-Z]$' e.txt
- 查找不是用H结尾的数据
grep '[^H]$' e.txt
- 查找所有大写结尾的数据但是不要大写H
grep '[A-Z]$' e.txt | grep '[^H]$'
grep '[A-GI-Z]\$' e.txt
- 查找以数字结尾的第二行信息
grep '[0-9]$' e.txt | sed -n '2p'
- 查找数字开头,并且是小写结尾的行
grep '^[0-9].*[a-z]$' e.txt
grep '[a-z]\{5\}\.*[0-9]$' 3.txt
带{5}次数的需要转义符号,否则无效
需要注意的是,grep不像sed正则需要加两个斜杠匹配
13、awk linux三剑客之三
以行为单位,进行读入,根据分隔符对每行数据进行切割,进行数据列的查看;
注意:如果需要下载和上传的操作可以先看第14
1、使用分隔符来对某个列进行数据的查看
awk ‘{列的操作}’ 文件名
awk ‘{print $1,$2}’ 文件名 ($0 表示全部列,$1表示第一个列)
如果文件分割符是除空格之外的其他符合需要指明分隔符
awk -F ‘文件的分隔符合’ ‘{列的操作}’ 文件名
[hadoop@node100 hxx]$ cat emp.txt
EMPNO;ENAME;JOB;MGR;HIREDATE;SAL;COMM;DEPTNO
7369;SMITH;CLERK;7902;1980/12/17;800;;20
7499;ALLEN;SALESMAN;7698;1981/02/20;1600;300;30
7521;WARD;SALESMAN;7698;1981/02/22;1250;500;30
7566;JONES;MANAGER;7839;1981/04/02;2975;;20
7654;MARTIN;SALESMAN;7698;1981/09/28;1250;1400;30
7698;BLAKE;MANAGER;7839;1981/05/01;2850;;30
7782;CLARK;MANAGER;7839;1981/06/09;2450;;10
7788;SCOTT;ANALYST;7566;1987/04/19;3000;;20
7839;KING;PRESIDENT;;1981/11/17;5000;;10
7844;TURNER;SALESMAN;7698;1981/09/08;1500;0;30
7876;ADAMS;CLERK;7788;1987/05/23;1100;;20
7900;JAMES;CLERK;7698;1981/12/03;950;;30
7902;FORD;ANALYST;7566;1981/12/03;3000;;20
7934;MILLER;CLERK;7782;1982/01/23;1300;;10
[hadoop@node100 hxx]$ awk -F ';' '{print $1,$2}' emp.txt
EMPNO ENAME
7369 SMITH
7499 ALLEN
7521 WARD
7566 JONES
7654 MARTIN
7698 BLAKE
7782 CLARK
7788 SCOTT
7839 KING
7844 TURNER
7876 ADAMS
7900 JAMES
7902 FORD
7934 MILLER
2、使用变量,对读取的列的数据进行计算
awk -F ‘分隔符’ -v变量名1=值 -v变量名2=值 ‘数据的展示’ filename
查询员工的年薪和月薪
awk -F ';' -vy=12 -vm=22 '{print $2,$6*y,$6/22}' emp.txt
3、使用逻辑对数据进行判断(相应操作不要带花括号)
找出比两千工资大的信息:
awk -F ';' '$6>2000' emp.txt
找出工资小于2000并且有奖金的用户信息
awk -F ';' '$6<2000 && $7>0' emp.txt
找出工资等于3000或者等于5000的数据
awk -F ';' '$6==5000 || $6==3000' emp.txt
----awk不支持 !(非) 判断 相当于not
练习
查询出emp表每一年分别有多少人入职?
[hadoop@node100 hxx]$ awk -F ';' '{print $5}' emp.txt
HIREDATE
1980/12/17
1981/02/20
1981/02/22
1981/04/02
1981/09/28
1981/05/01
1981/06/09
1987/04/19
1981/11/17
1981/09/08
1987/05/23
1981/12/03
1981/12/03
1982/01/23
[hadoop@node100 hxx]$ awk -F ';' '{print $5}' emp.txt | sed 1d
1980/12/17
1981/02/20
1981/02/22
1981/04/02
1981/09/28
1981/05/01
1981/06/09
1987/04/19
1981/11/17
1981/09/08
1987/05/23
1981/12/03
1981/12/03
1982/01/23
[hadoop@node100 hxx]$ awk -F ';' '{print $5}' emp.txt | sed 1d | awk -F '/' '{print $1}'
1980
1981
1981
1981
1981
1981
1981
1987
1981
1981
1987
1981
1981
1982
[hadoop@node100 hxx]$ awk -F ';' '{print $5}' emp.txt | sed 1d | awk -F '/' '{print $1}' | sort | uniq -c
1 1980
10 1981
1 1982
2 1987
[hadoop@node100 hxx]$
##方法一
awk -F ';' '{print $5}' emp.txt|sed -n '2,$p'|awk -F '/' '{print $1}'|sort|uniq
-c|sort -nr
##方法二
awk -F ';' '{print $5}' emp.txt|sed -n '2,$p'|sed '1,$s/\/.*//g'|sort|uniq -c|
sort -nr
14、rz/sz文件的上传与下载
yum -y install lrzsz
如果无法执行,则使用su命令切换到root
su 用户名 (临时切换)
su - 用户名 (完全切换)
sz 文件名 --下载文件
rz 上传文件到当前目录 (会直接弹框,可以选择指定文件) 也可以直接从拖拽到会话框
14、date
创建一个今天年月日命名的文件
date 会返回当前系统时间
date “+%Y-%m-%d %H:%M:%S”
也可以用单引号
`` 反引号表示要引用一个命令的结果,将这个结果放到另一个命令中当成条件去使用。
$() 与 `` 功能一样
touch `date | awk '{print $1$2$3}'`.txt
touch $(date | awk '{print $1$2$3}').txt
touch `date +%Y-%m-%d`.txt
touch $(date +%Y-%m-%d).txt
--date -d "2 days ago" "+%Y-%m-%d" --2天前
--date -d "-2 days" "+%Y-%m-%d" --2天前
--date -d "2 moths ago" "+%Y-%m-%d"--2个月前
--date -d "2 years ago" "+%Y-%m-%d"--2年前
[hadoop@node100 hxx]$
[hadoop@node100 hxx]$ date
2024年 06月 04日 星期二 21:48:10 CST
[hadoop@node100 hxx]$ date '+%Y-%m-%d %H:%M:%S'
2024-06-04 21:48:55
[hadoop@node100 hxx]$ touch `date | awk '{print $4$5$6}'`.txt
[hadoop@node100 hxx]$ ls
13.txt 2024年06月04日 emp.txt qq.txt test
1.tar.gz 2.txt hxx_2023 rename.txt test.txt
2014 a.txt nofile.txt tar1 星期二21:49:40CST.txt
[hadoop@node100 hxx]$ date -d '-2 days' '+%Y-%m-%d'
2024-06-02
[hadoop@node100 hxx]$ date -d '-2 days ago' '+%Y-%m-%d'
2024-06-06
如果当前系统时间不正确需要改正
设置系统定时调度的方法:
-
确认时间是否正确: date
-
安装时间服务器: yum -y install ntp
-
启动时间服务器:service ntpd start
-
选择时区的内容:tzselect --timezone
-
更改系统的时区的文件:cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
硬件操作
cpu
查看cpu的基本信息
cat /proc/cpuinfo
内存
查看内存的基本信息
方法一:cat /proc/meminfo
方法二:free -h
free显示系统内存的指定情况,包括物理内存、交换内存和内核缓冲区内存
-b 以bytes为单位显示内存使用情况 free -b
-k 以KB为单位显示内存使用情况 free -k
-m 以MB为单位显示内存使用情况 free -m
-h 以合适的单位显示内存使用情况,最大为三位数,自动计算
对应的单位 free -h
-t 显示内存总和 free -t
硬盘
查看硬盘的基本使用情况
df -h
网卡
查看网卡的基本情况
ip add 查看IP
ip add 查看IP
ifconfig 查看IP
查看自己的网络和其他另一个地址之间的网络是否通畅:
ping 另一个ip地址或者域名
ping www.baidu.com
ping www.sohu.com
打包和压缩
tar包仅仅是打包,但是不会进行压缩的方法
- tar -cf 包名 要被打包的文件名 (c–create)
tar -cf 1.tar *.txt
- 查看包有什么内容( t–list)
tar -tf 包的名字
tar -tf 1.tar
- 解包,拿出里面的文件( x–extract )
tar -xf 1.tar
如果当前有相同的文件名,会对文件内容进行替换
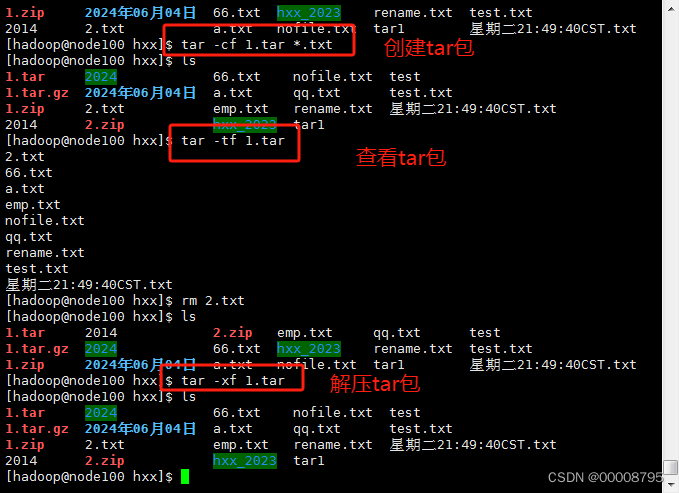
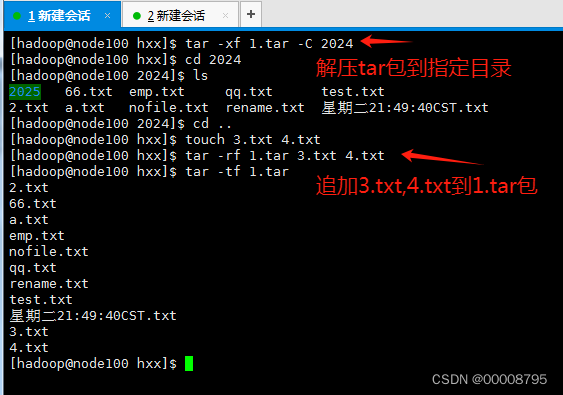
- 解开包到指定目录 tar -xf 包名 -C 指定目录
- 追加一个或者多个文件到包里面:tar -rf 包的名字 要追加的文件名
tar -rf 1.tar world.txt
tar -rf 1.tar apple.txt pear.txt
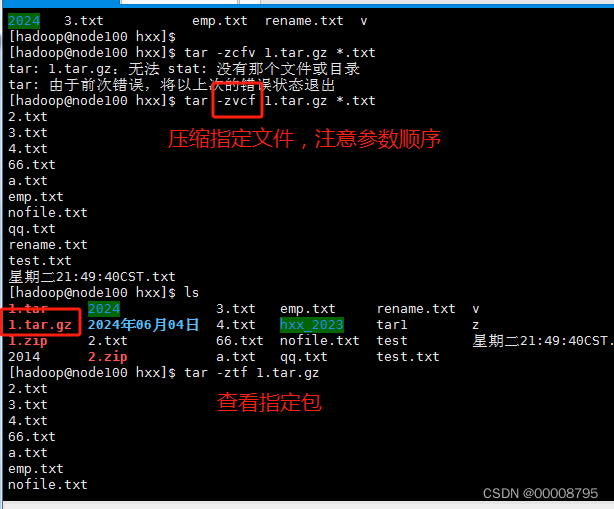
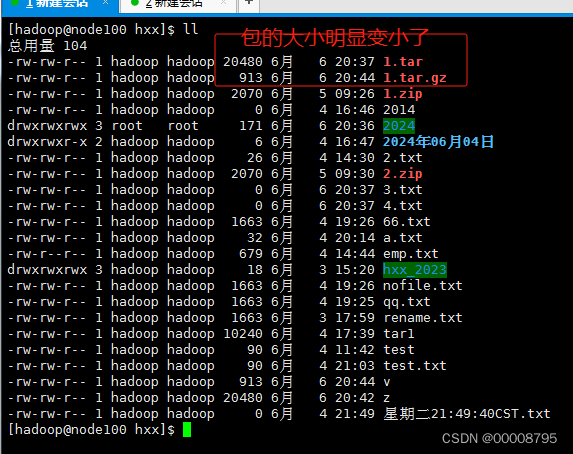
压缩
tar.gz包:在打包的同时,进行数据的压缩
v:显示一个过程
打包并且压缩:tar -zvcf 包名 要被打包的文件名
tar -zvcf 1.tar.gz *.txt
查看压缩包:tar -ztf 包的名字
tar -ztf 1.tar.gz
解压缩这个包:tar -zvxf 包的名字
tar -zxf 1.tar.gz
安装zip的压缩包:
yum -y install zip
yum -y install unzip
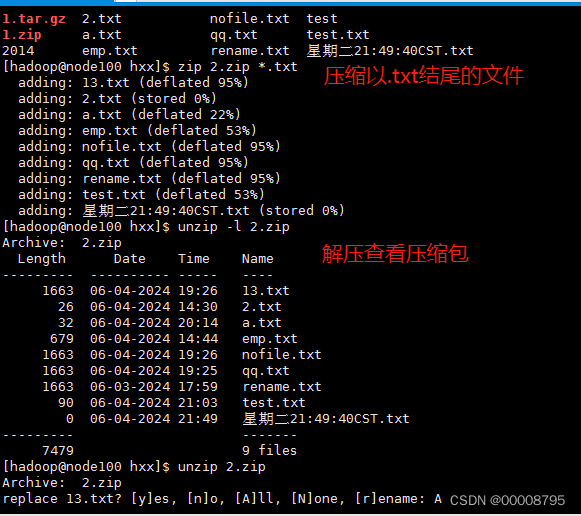
打包并且压缩:zip 包名 要打包的文件名
zip 1.zip *.txt
查看压缩包的内容:unzip -l 包名
unzip -l 1.zip
解压缩包:unzip 包名
unzip 1.zip
进程相关命令
top 实时显示当前资源占用靠前的进程和程序名字以及概况
实时显示当前资源占用靠前的进程和程序的名字以及概况
top -p pid 可以查看指定pid
top查看页面可使用的命令
- ? 显示top中可以输入的ml
- P 按CPU占用排序
- M 按内存占用排序
- T 按使用CPU时间排序
- N 按进程编号pid排序
- R 结合上述使用,反向排序
- q或者ctrl+c可以退出当前查看页面


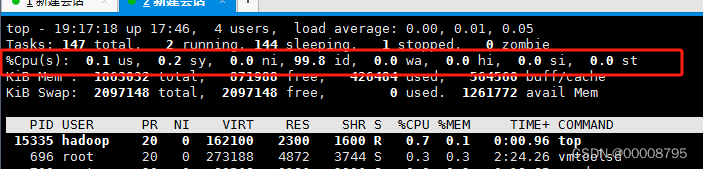
- 0.1us 用户空间占用CPU比例
- 0.2 sy 内核空间占用CPU比例
- 0.0 ni 用户进程空间内改变过优先级的进程占用比
- 99.8 id 空闲cpu 百分比
- 0.0 wa 等待输入输出的cpu时间比
- 0.0 hi 硬中断(Hardware IRQ)占用CPU比例
- 0.0 si 软中断(Software Interrupts)占用CPU的比例
- 0.0 st 用于有虚拟cpu的情况,用来指示被虚拟机偷掉的cpu时间

- 1863832 totla 物理内存占比
- 872292 free 空闲内存总量
- 426188 used 使用的物理内存总量
- 564568 buff 用做内核缓存的内存量
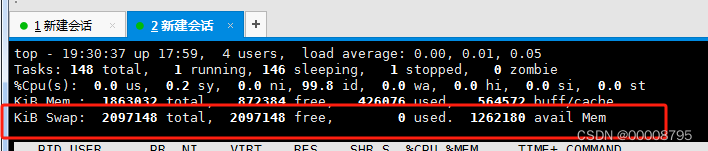
- 2097148 total 交换区总量
- 2097148 free 空闲的交换区总量
- 0 used 已使用的交换区总量
- 1262364 avail Mem 可用的交换区总量
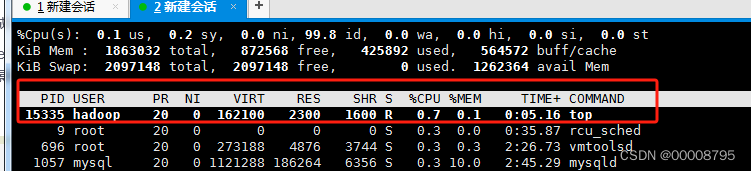
- PID 进程名称
- USER 进程所有者的用户名
- PR 优先级
- NI nice值,负值高优先级,正值低优先级
- VIRT 进程使用的虚拟内存,单位kb ,VIRT=SWAP+RES
- RES 进程使用的、未被换出的物理内存大小,单位kb,RES=CODE+DATA
- SHR 共享内存大小,单位kb
- S 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
- %CPU 上次更新到现在的CPU时间占用百分比
- %MEM 进程使用的物理内存百分比
- TIME+ 进程使用的CPU时间总计,单位1/100秒
- COMMAND 命令名/命令行
ps 查看所有资源占用靠前的进程和查询名字以及概况
| 参数 | 含义 |
|---|---|
| -a | 显示所有进程信息 |
| -u | 使用用户为主的格式来显示程序状态 |
| -x | 不区分终端主机 |
| -e | 显示环境变量信息 |
| -f | 用ASCII字符显示树状结构 |
| -g | 显示所有程序及其所属组的程序 |
| -h | 不显示标题信息 |
| -H | 使用树状结构展示程序间的相互关系 |
| -l | 使用详细格式显示程序状态 |
常用的是组合的方式
ps -aux
ps -ef
kill 结束掉正在运行的程序
kill 进程编号
kill -KILL 进程编号 ---强制结束进程
kill -9 进程编号 --无论如何都要结束进程(常用)
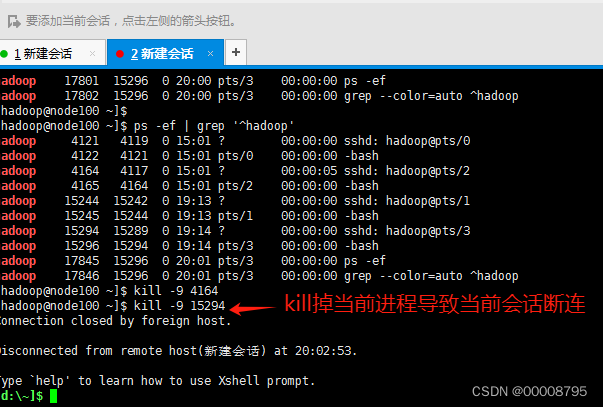
将过滤出的hadoop用户进程kill
[hadoop@node100 ~]$ kill -9 $(ps -ef | gre '^hadoop'| awk -F '' '{print $2}')
如果开了多个会话窗口,即使是想kill掉所有的终端会话,但是可能由于会终端会话创建的时间不一致,kill掉当前的终端进程后,由于一部分创建终端的时间晚于当前的会话终端,所以会被保留下来。(简单理解就是我能干掉比我年龄大的,比我小的在被我干翻之前,我自己就崩了自己)
screen 多重视窗管理程序
当使用一些需要实时显示的数据,导致无法操作命令框,可以使用虚拟屏进行实时数据挂起操作,方便显示数据的同时操作命令终端。
类似一些股票管理软件,左侧实时大盘数据,右侧账户信息。
特点
- 会话恢复:只要Screen本身没有终止,在其内部运行的会话都可以恢复
- 多窗口:在Screen环境下,所有的会话都独立的运行,并拥有各自的编号、输入、输出和窗口缓存
- 会话共享:Screen可以让一个或多个用户从不同终端多次登录一个会话,并共享会话的所有特性(比如可以看到完全相同的输出)。它同时提供了窗口访问权限的机制,可以对窗口进行密码保护。
两个状态,通常情况下不需要关注
通常情况下,screen创建的虚拟终端,有两个工作模式:
Attached:表示当前screen正在作为主终端使用,为活跃状态。
Detached:表示当前screen正在后台使用,为非激发状态。
以下视窗作业等同与虚拟屏,就是换了个称呼
需要先切换到root下安装screen
yum -y install screen
显示完后切回hadoop用户
| 参数 | 含义 |
|---|---|
| -S | 建立并直接进入到新的视窗作业 |
| -r | 恢复指定视窗作业 |
| -R | 先尝试恢复离线作业,失败建立新的视窗作业 |
| -ls | 显示全部的作业 |
| -wipe | 检查所有的作业并删除无法使用的 |
| -x | 恢复此前以离线的视窗作业 |
| -v | 显示版本信息 |
| -d | 将指定视窗作业离线 |
- 创建虚拟屏 screen -S 虚拟屏名
- ctrl + a + d 退出虚拟屏
- screen -r 虚拟屏名 进入虚拟屏
- screen -R 会先试图回复原来离线的虚拟屏作业,如果找不到就会创建新的screen。xshell脚本关闭了,但是虚拟机没有关机,这个虚拟屏还是会在挂起的状态
- screen -ls 查看所有的screen作业
- screen -wipe 清楚dead状态的screen
- kill -9 虚拟屏作业编号 可以kill掉screen作业
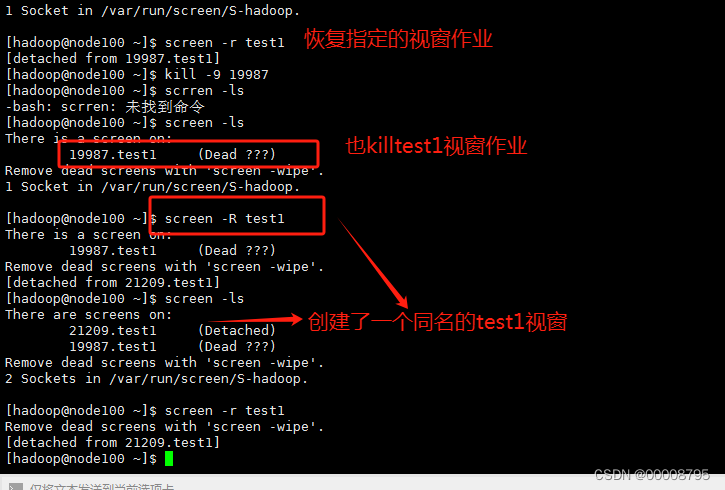 screen -R test1 如果状态处于被kill会创建一个新的视窗作业,如果是detached状态,会直接进入已经创建好的视窗作业
screen -R test1 如果状态处于被kill会创建一个新的视窗作业,如果是detached状态,会直接进入已经创建好的视窗作业
用户身份与文件权限
用户身份
- uid为0的是管理员
- uid 1~999是系统用户
- uid 1000开始是普通用户
Linux系统中创建每个用户时,将自动创建一个与其同名的基本用户组,而且这个基本用户组只有该用户一个人。如果该用户以后被归纳到其他用户组,则这个其他用户组称之为扩展用户组。一个用户只有一个基本用户组,但是可以有多个扩展用户组,从而满足日常的工作需要。
基本用户组就像是原生家庭,是在创建账号(出生)时就自动生成的;而扩展用户组则像工作单位,为了完成工作,需要加入到各个不同的群体中,这是需要手动添加的。
文件权限与归属
| r(read) | w(write) | x(execute) |
|---|---|---|
| 可读 | 可写 | 可操作 |
 drwxrwxr-x:首字母d代表文件类型为目录
drwxrwxr-x:首字母d代表文件类型为目录
rwxrwxr-x:表示访问权限
hadoop:所有者(属主)第一个
hadoop:所属组(属组)第二个
rwxrwxr-x,划分为三段
- 第一段为rwx所有者权限为可读可写可执行
- 第二段为rwx所属组权限为可读可写可执行
- 第三段为r_x其他人权限为可读可执行,_表示这个位置上没有权限
常用文件类型
| 简写字母 | 文件类型 |
|---|---|
| - | 普通文件(一般是纯文本信息、服务配置信息、日志信息以及Shell脚本) |
| d | 目录文件 |
| l | 链接文件 |
| p | 管道文件 |
| b | 块设备文件 |
| c | 字符设备文件(一般指硬件设备,比如鼠标、键盘、光驱、硬盘) |
| s | 套接字文件 |
chmod改变文件或目录的权限
- u 自己的权限 user
- g 组员的权限 group
- o 其他人的权限 other
- a 所有人
| - | = | + |
|---|---|---|
| 去掉权限 | 设置权限 | 增加权限 |
| chmod o-rw baidu.txt | chmod o=rw baidu.txt | chmod o+rw baidu.txt |
chmod +x baidu.txt --默认给所有人添加执行权限
chmod u=rwx,g=rw,o=r 1.txt
数字与权限的转换,数字是二进制。
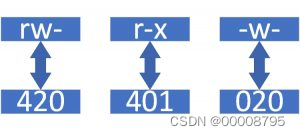
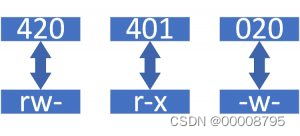
| 权限 | 数字 | 二进制 |
|---|---|---|
| r– | 4 | 100 |
| -w- | 2 | 010 |
| –x | 1 | 001 |
| rw- | 6 | 110 |
| r-x | 5 | 101 |
| -wx | 3 | 011 |
| rwx | 7 | 111 |
| —(三个横) | 0 | 000 |
chmod 753 a2.txt
chmod 654 a2.txt
chmod -R 777 /home/year --就是把home下的year文件夹及其所有文件都加上了所有权限
批量修改权限
统一修改文件夹和里面所有文件的权限:
chmod -R 权限 文件夹名字
chmod -R 774 /home/year
用户管理命令
useradd创建并设置用户信息
创建用户:
useradd 用户名
useradd xiaoli
创建用户密码:
passwd 用户名
usermod修改用户信息
修改用户放入到其他的组:
usermod -g 组名 用户名
usermod -g root xiaoli
查看所有组的信息
cat /etc/group
id显示用户和用户组信息
查看用户的组信息:
id 用户名
id lilei
userdel删除用户信息
删除用户:
userdel -r 用户名 —(递归式删除用户,会删除与用户相关的一切东西)
userdel 用户名 —会保留家目录
groupdel删除用户组
删除组
groupdel 组名 --不能删除掉用户的主组 删除后可以cat /etc/group看是否存在
groupadd新增用户组
新增组
groupadd 组名
chown 改变文件或目录的用户和用户组
chown 新用户名 文件名 --修改文件的所有者
chown :新组名 文件名 --修改文件的所属组
chown 新用户名:新组名 文件名 --修改文件的所有者,所属组
批量处理
-R 处理目录及目录下所有文件与子目录
实例:
chown -R root:root /home/year 批量改变所有者,所属组
切换用户登录:
su 用户名 – 不会刷新登录窗口 --临时切换用户 switch user 切换用户
su - 用户名 会刷新登录窗口 --完全切换用户
其他
find 查找系统中文件的位置
find 查找的范围 查找的方法 查找的内容
按名字查找文件: —支持个别正则符号
-
查找系统里面,有没有hello.txt的文件
find / -name hello.txt
-
查找所有的 a 开头的, .txt结尾的文件名字和位置
find / -name ‘a*.txt’ --'a*.txt’或者"a*.txt"
-
查找所有的 a开头 txt结尾的文件夹的名字和位置
find / -type d -a -name “a*txt”
–布尔运算符
-a 相当于and
-o 相当于or
! 相当于not
根据文件的大小来查找:
c(字节) k M G
在home目录中,查询所有大于2k的文件 + 大于 - 小于
find /home -size +2k -a -type f
查找所有小于100K的jpg图片 或者 大于300k的png图片
find / -size -100k -a -name “.jpg" -o -size +300k -a -name ".png”
查找空的文件夹或者文件:
find /home -empty
根据文件的权限进行查找:
find /home -perm 权限的数字
find /home -perm 644
-user 按用户名查找
find /home -user hadoop
面试点:ll(能查看什么内容) 硬件 三剑客 打包压缩 修改权限
—待续更新中

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









