







2024/2/19
N叉树后续遍历
模板题,直接DFS遍历即可
class Solution {
public List<Integer> list;
public void dfs(Node root){
if(root == null)return;
for(Node child:root.children){
dfs(child);
}
list.add(root.val);
}
public List<Integer> postorder(Node root) {
this.list = new ArrayList<>();
dfs(root);
return list;
}
}
2024/2/20
从前序与中序遍历序列构造二叉树
主要逻辑:
先序:根左右
中序:左根右
根据先序确定根,然后在中序中找到根,划分子树。根之前为左子树,根之后为右子树。
之后继续划分,直到无法细分为止。
我的做法:按照中序进行划分区间,找区间内谁第一个在先序中出现。
题解(更好的做法):先前序,后中序。这样可以一次找出结果,而不需要遍历。
//我的做法
class Solution {
Map<Integer,Integer> preorderIndex;
public TreeNode dfs(int l,int r,int[] preorder,int[] inorder){
if(r - l == 0){
return new TreeNode(inorder[l],null,null);
}
int minIndex = -1;
int mins = 3005;
for(int i = l;i <= r;i++){
if(preorderIndex.get(inorder[i]) < mins){
mins = preorderIndex.get(inorder[i]);
minIndex = i;
}
}
//此时已经找到根
TreeNode root = new TreeNode(inorder[minIndex],null,null);
if(minIndex != l){
root.left = dfs(l,minIndex - 1,preorder,inorder);
}
if(minIndex != r){
root.right = dfs(minIndex + 1,r,preorder,inorder);
}
return root;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
preorderIndex = new HashMap<>();
int n = preorder.length;
for(int i = 0;i < n;i++){
preorderIndex.put(preorder[i],i);
}
TreeNode root = dfs(0,n - 1,preorder,inorder);
return root;
}
}
//题解的做法
class Solution {
Map<Integer,Integer> inorderIndex;
public TreeNode dfs(int pl,int pr,int il,int ir,int[] preorder,int[] inorder){
if(pl > pr)return null;
int rootIndex = inorderIndex.get(preorder[pl]);//找到了根的位置,可以计算出左子树的长度和右子树的长度
//此时已经找到根
TreeNode root = new TreeNode(inorder[rootIndex],null,null);
//计算左子树长度
int left_size = rootIndex - il;
//构造左子树
root.left = dfs(pl + 1,pl + left_size,il,rootIndex - 1,preorder,inorder);
//计算右子树长度
int right_size = ir - rootIndex;
//构造右子树
root.right = dfs(pl + left_size + 1,pr,rootIndex + 1,ir,preorder,inorder);
return root;
}
public TreeNode buildTree(int[] preorder, int[] inorder) {
inorderIndex = new HashMap<>();
int n = preorder.length;
for(int i = 0;i < n;i++){//找到先序数据在inorder中的位置
inorderIndex.put(inorder[i],i);
}
TreeNode root = dfs(0,n - 1,0,n - 1,preorder,inorder);
return root;
}
}
2024/2/21
从中序与后序遍历序列构造二叉树
中序:左中右
后序:左右中
[[左子树]根[右子树]]
[[左子树][右子树]根]
逆序遍历postorder数组,找到根,利用Map记录根在inorder中的index,完成操作。
class Solution {
Map<Integer,Integer> map = new HashMap<>();
TreeNode dfs(int il,int ir,int pl,int pr,int[] inorder,int[] postorder){
if(pr < pl)return null;
//获取根在中序中的位置
int rootIndex = map.get(postorder[pr]);
//创建根节点
TreeNode root = new TreeNode(postorder[pr]);
//获取左右子树长度
int left_size = rootIndex - il;
int right_size = ir - rootIndex;
//遍历左右子树
root.left = dfs(il,rootIndex - 1,pl,pl + left_size - 1,inorder,postorder);
root.right = dfs(rootIndex + 1,ir,pr - right_size,pr - 1,inorder,postorder);
return root;
}
public TreeNode buildTree(int[] inorder, int[] postorder) {
int n = postorder.length;
for(int i = 0;i < n;i++){
map.put(inorder[i],i);
}
return dfs(0,n - 1,0,n - 1,inorder,postorder);
}
}
2024/2/22
根据前序和后序遍历构造二叉树
先序:根左右
后序:左右根
[根,左子树,右子树]
[左子树,右子树,根]
存在多个答案,即遍历合理即可。
根后的第一个元素,是左子树的根,可以找到对应于后续的index,然后算出左子树的长度。
class Solution {
Map<Integer,Integer> map = new HashMap<>();
TreeNode dfs(int preL,int preR,int postL,int postR,int[] preorder,int[] postorder){
if(preR < preL) return null;
//创建root
TreeNode root = new TreeNode(preorder[preL]);
//计算左子树长度
int leftSize = preL + 1 < preR ? map.get(preorder[preL + 1]) - postL + 1: 0;
//计算右子树长度
int rightSize = preR - preL - leftSize;
//算出左右子树
root.left = dfs(preL + 1,preL + leftSize,postL,postL + leftSize - 1,preorder,postorder);
root.right = dfs(preL + leftSize + 1,preR,postL + leftSize,postR - 1,preorder,postorder);
return root;
}
public TreeNode constructFromPrePost(int[] preorder, int[] postorder) {
int n = preorder.length;
for(int i = 0;i < n;i++){
map.put(postorder[i],i);
}
return dfs(0,n-1,0,n-1,preorder,postorder);
}
}
2024/2/23
二叉树中的第 K 大层和
自己的思路:深度遍历+map记录+sort排序。但是这样很浪费时间,不是最优。
应该的做法:BFS+双队列记录当前层次的所有节点+排序,节约时间。
//自己做法
class Solution {
Map<Integer,Long> map = new HashMap<Integer,Long>();
public void dfs(int index,TreeNode root){
if(root == null)return;
map.put(index,map.getOrDefault(index,0L) + root.val);
dfs(index + 1,root.left);
dfs(index + 1,root.right);
}
public long kthLargestLevelSum(TreeNode root, int k) {
dfs(1,root);
Set<Integer> set = map.keySet();
List<Long> list = new ArrayList<>();
for(Integer key:set){
list.add(map.get(key));
}
if(k > list.size())return -1L;
Collections.sort(list,Collections.reverseOrder());
return list.get(k - 1);
}
}
//题解
class Solution {
public long kthLargestLevelSum(TreeNode root, int k) {
List<Long> a = new ArrayList<>();
List<TreeNode> q = List.of(root);
while (!q.isEmpty()) {
long sum = 0;
List<TreeNode> tmp = q;
q = new ArrayList<>();
for (TreeNode node : tmp) {
sum += node.val;
if (node.left != null) q.add(node.left);
if (node.right != null) q.add(node.right);
}
a.add(sum);
}
int n = a.size();
if (k > n) {
return -1;
}
Collections.sort(a);
return a.get(n - k);
}
}
2024/2/24
二叉搜索树最近节点查询
BFS + 二分。
二分需要再学一学,模板有问题。
/*
BFS + 二分
*/
class Solution {
public List<List<Integer>> closestNodes(TreeNode root, List<Integer> queries) {
Queue<TreeNode> pq = new LinkedList<>();
List<Integer> querySum = new ArrayList<>();
pq.offer(root);
while(!pq.isEmpty()){
Queue<TreeNode> lq = pq;
pq = new LinkedList<>();
for(TreeNode temp:lq){
querySum.add(temp.val);
if(temp.left != null)pq.offer(temp.left);
if(temp.right != null)pq.offer(temp.right);
}
}
Collections.sort(querySum);
List<List<Integer>> ans = new ArrayList<>();
// return ans;
int n = querySum.size();
int[] a = new int[n];
for(int i = 0;i < n;i++)a[i] = querySum.get(i);
for(Integer i:queries){
int j = lowerBound(a, i);
int mx = j == n ? -1 : a[j];
if (j == n || a[j] != i) { // a[j]>i, a[j-1]<i
j--;
}
int mn = j < 0 ? -1 : a[j];
ans.add(List.of(mn, mx));
}
return ans;
}
private int lowerBound(int[] a, int target) {
int left = -1, right = a.length; // 开区间 (left, right)
while (left + 1 < right) { // 区间不为空
int mid = (left + right) >>> 1; // 比 /2 快
if (a[mid] >= target) {
right = mid; // 范围缩小到 (left, mid)
} else {
left = mid; // 范围缩小到 (mid, right)
}
}
return right;
}
}
2024/2/25
二叉搜索树的最近公共祖先
我的做法:遍历每个结点,然后记录路径,最后使用双层循环进行匹配最近节点。
题解:p、q一起遍历,对于当前root如果是相同的比较结果,证明不是分岔点,如果有不同的比较结果,那么就是分岔点,当前root就为最终结果。
//我的做法
class Solution {
List<TreeNode> list;
public void dfs(TreeNode root,TreeNode x){
if(root == null){
return;
}
list.add(root);
if(root.val == x.val)return;
if(root.val > x.val)dfs(root.left,x);
else dfs(root.right,x);
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
list = new ArrayList<>();
dfs(root,p);
List<TreeNode> pList = list;
list = new ArrayList<>();
dfs(root,q);
int n = pList.size();
int m = list.size();
for(int i = n - 1;i >=0;i--){
for(int j = m - 1;j >= 0;j--){
if(pList.get(i).val == list.get(j).val){
return pList.get(i);
}
}
}
return null;
}
}
//题解:
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
TreeNode ancestor = root;
while (true) {
if (p.val < ancestor.val && q.val < ancestor.val) {
ancestor = ancestor.left;
} else if (p.val > ancestor.val && q.val > ancestor.val) {
ancestor = ancestor.right;
} else {
break;
}
}
return ancestor;
}
}
2024/2/26
二叉搜索树的范围和
我的思路:中序遍历+遍历求解。比较浪费时间,其实可以dfs的时候就可以进行求解。
题解思路:判断是否遍历左右子树,直接求解。
//我的
class Solution {
List<Integer> list = new ArrayList<>();
public void dfs(TreeNode root){
if(root == null)return;
dfs(root.left);
list.add(root.val);
dfs(root.right);
}
public int rangeSumBST(TreeNode root, int low, int high) {
//中序遍历,并求值
dfs(root);
int n = list.size();
int ans = 0;
for(int i = 0;i < n;i++){
if(list.get(i) > high)break;
if(list.get(i) >= low)ans+=list.get(i);
}
return ans;
}
}
//题解
class Solution {
public int dfs(TreeNode root,int low,int high){
if(root == null)return 0;
if(root.val > high){
return dfs(root.left,low,high);
}
if(root.val < low){
return dfs(root.right,low,high);
}
return root.val + dfs(root.left,low,high) + dfs(root.right,low,high);
}
public int rangeSumBST(TreeNode root, int low, int high) {
return dfs(root,low,high);
}
}
2024/2/27
统计树中的合法路径项目
冥思苦想1.30个小时,没找到正确的思路。被提示误导,以为就是深搜之后根据不同的类型进行动态规划。
正确的题解:
1.利用埃氏筛计算质数
2.枚举所有质数节点,对于当前的质数来说,会将整个树划分为多个连通块。对于每个连通块,记录所有合法的路径(即全是合数的路径,这样可以与当前质数节点形成一条合法的路径)。此时,不同连通块之间的合数路径,可以通过当前的质数节点进行相连,两者之间进行选择,此时为最终的结果。
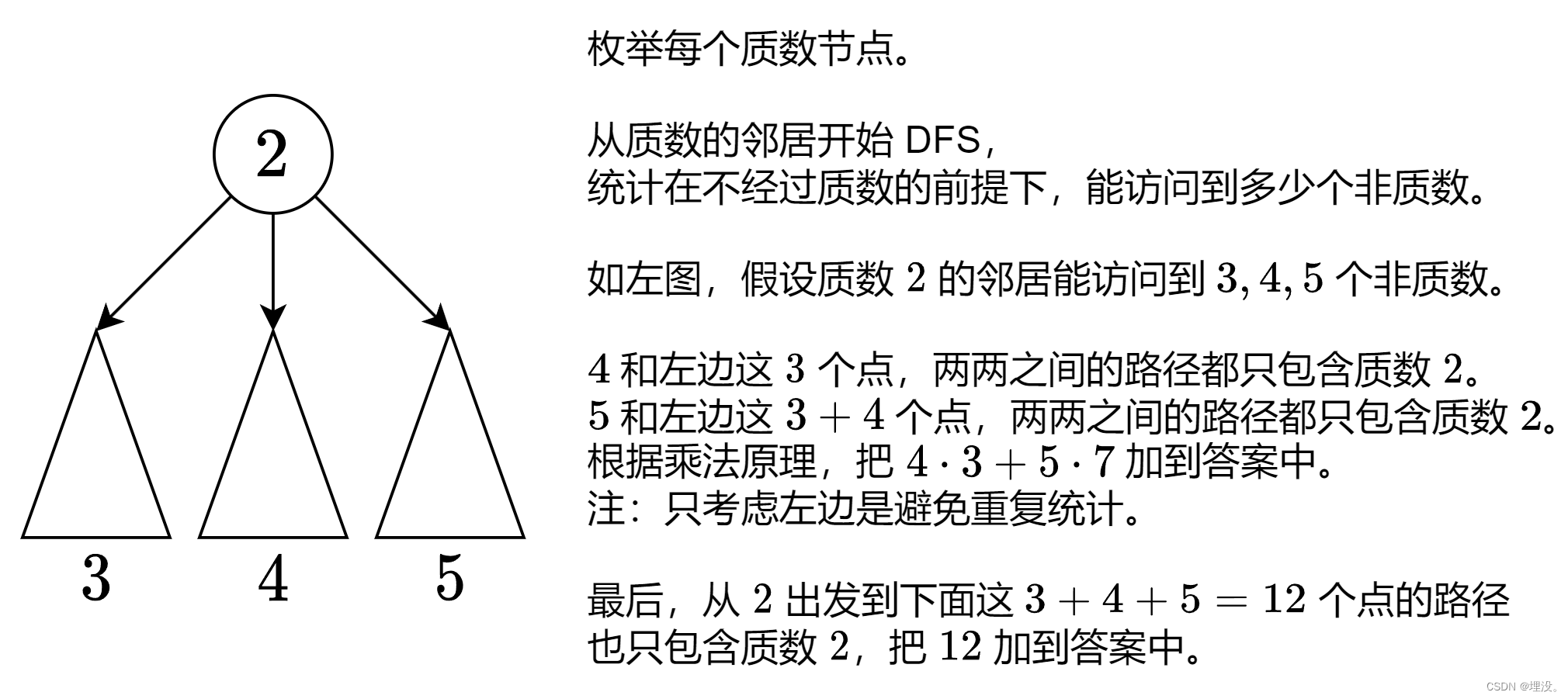
class Solution {
private final static int MX = (int)1e5;
private final static boolean[] prime = new boolean[MX + 5];//质数为false,非质数为true
static{
prime[1] = true;
for(int i = 2;i * i <= MX;i++){
if(prime[i])continue;
for(int j = i * i;j <= MX;j+=i){
prime[j] = true;
}
}
}
public long countPaths(int n, int[][] edges) {
//将树建为图
List<Integer>[] g = new ArrayList[n + 1];
Arrays.setAll(g,e -> new ArrayList<>());//建立邻接表
for(int i = 0;i < n - 1;i++){
int x = edges[i][0];
int y = edges[i][1];
g[x].add(y);
g[y].add(x);
}
long ans = 0;
int[] size = new int[n + 1];//一个trick,用于记录是否遍历过,以及记录
List<Integer> nodes = new ArrayList<>();//用于记录当前连通块数量
for(int x = 1;x <= n;x++){
if(prime[x])continue;//跳过质数
int sums = 0;
for(int y:g[x]){//当前质数x,将整棵树划分为了多个子连通块
if(!prime[y])continue;//如果当前为质数,则跳过
if(size[y] == 0){//当前节点的连通合数并未计算
nodes.clear();//用于统计从当前点出发能遍历到的所有合数
dfs(y,-1,g,nodes);//遍历y所在的连通块,在不经过质数的情况,能有多少非质数。
for(int z:nodes){// 连通块中的节点能到达的合数数量是一致的,记录
size[z] = nodes.size();
}
}
//这size[y]个质数与之前遍历的sum个非质数,两两之间的路径只包含当前x
ans += (long) size[y] * sums;
sums += size[y];
}
ans += sums;
}
return ans;
}
private void dfs(int x,int fa,List<Integer>[] g,List<Integer> nodes){
//fa保证不往回走
nodes.add(x);
for(int y:g[x]){
if(y != fa && prime[y]){
dfs(y,x,g,nodes);
}
}
}
}
2024/2/28
使二叉树所有路径值相等的最小代价
我的思路:1.只能增加,不能减少,因此只能向最大值进行靠近。2.若同属于一个根节点的两个子节点都需要更新,那么就更新两者最小值到父节点,递归进行。
题解思路:对于两个有相同根的叶子节点来说,除了自己以外其余所有路径都相同,因此只需要将小的往大的靠就可以实现路径相等。对于不是叶子的兄弟节点,从根到当前节点的路径,除了这两个兄弟节点不一样,其余节点都一样,所以把路径和从叶子往上传,这样就可以按照叶子节点的方式进行比较和更新了。
//我的做法:
class Solution {
int[] addCost;
public void dfs(int index,int[] pathCost,int maxs,int n){
if(index > n)return;
dfs(index << 1,pathCost,maxs,n);
dfs(index << 1 | 1,pathCost,maxs,n);
if(index * 2 > n){//子节点
if(pathCost[index] < maxs){
addCost[index] = maxs - pathCost[index];
}
return;
}
//非子节点,判断子节点更新的次数
int mins = Math.min(addCost[index * 2],addCost[index * 2 + 1]);
addCost[index] += mins;
addCost[index * 2] -=mins;
addCost[index * 2 + 1] -= mins;
}
public int minIncrements(int n, int[] cost) {
/*
1.只能增加,不能减少,因此只能向最大值进行靠近
2.若同属于一个根节点的两个子节点都需要更新,那么就更新两者最小值到父节点,递归进行。
*/
int[] pathCost = new int[n + 1];
pathCost[0] = 0;
int maxs = -1;//最大权值
for(int i = 0;i < n;i++){
int index = i + 1;
pathCost[index] = pathCost[index / 2] + cost[i];
maxs = Math.max(maxs,pathCost[index]);
}
addCost = new int[n + 1];
Arrays.fill(addCost,0);
dfs(1,pathCost,maxs,n);
int ans = 0;
for(int i = 1;i <= n;i++)ans+=addCost[i];
return ans;
}
}
//题解做法:
class Solution {
public int minIncrements(int n, int[] cost) {
int ans = 0;
for (int i = n / 2; i > 0; i--) { // 从最后一个非叶节点开始算
ans += Math.abs(cost[i * 2 - 1] - cost[i * 2]); // 两个子节点变成一样的
cost[i - 1] += Math.max(cost[i * 2 - 1], cost[i * 2]); // 累加路径和
}
return ans;
}
}
2024/2/29
统计可能出现的树根数目
未做出来的题:虽然有想到根与子树之间的换根,只需要记录交换根本身与子节点之间的序列变化,即可完成该题,但对于如何记录以及求得以root为根的树正确的猜测,还是有点无从下手。
该题是一个换根DP问题,前置知识为:树中距离之和
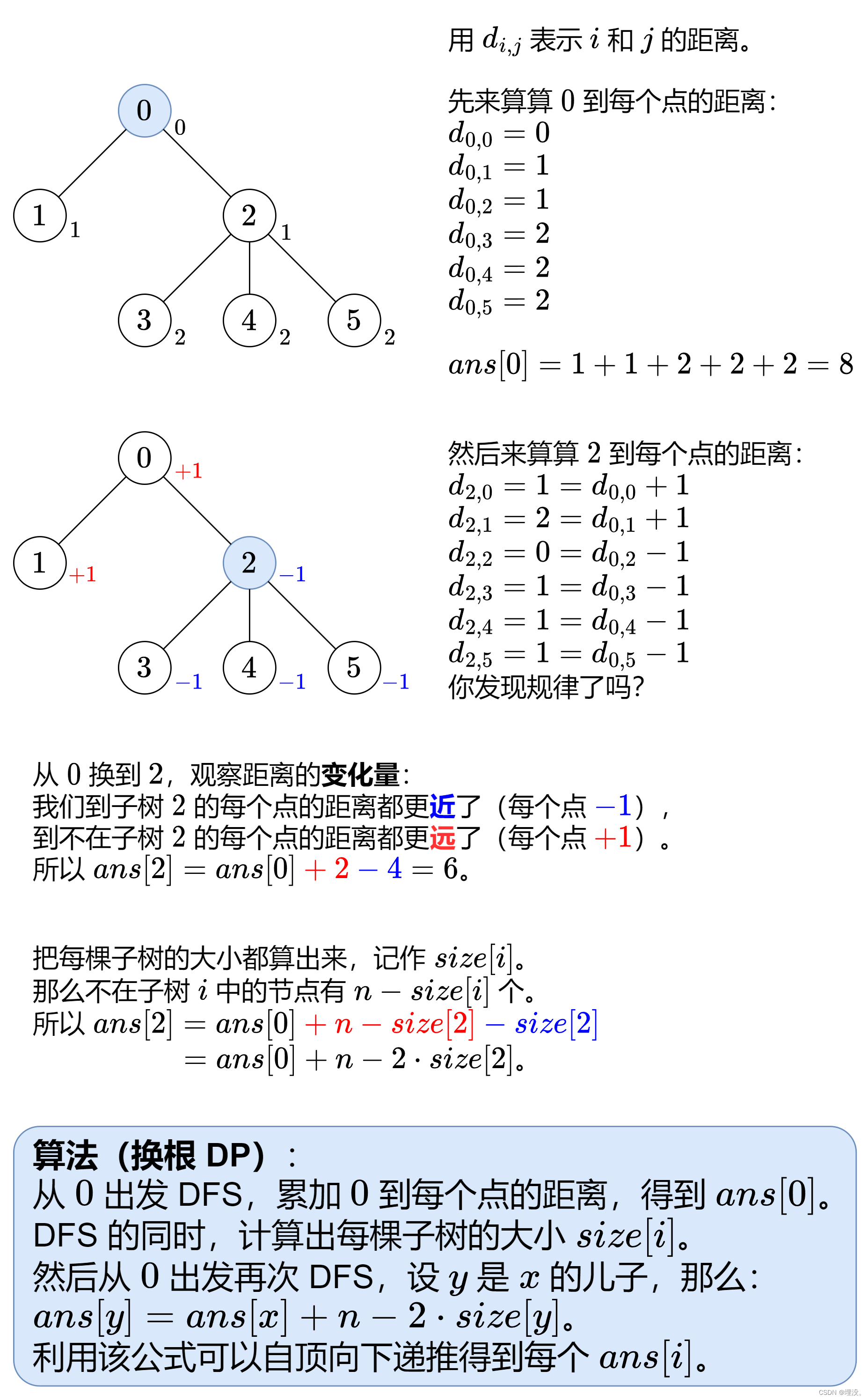
子树大小计算:后序遍历并统计。
保证每个节点只递归访问1次:对于图来说,使用vis数组记录每个点的访问次数。但是对于树来说,一直向下递归,就不会遇到之前访问的点,所以不需要数组,只需要避免重复访问父节点即可。
树中距离之和:
class Solution {
private List<Integer>[] g;
private int[] ans,size;
public int[] sumOfDistancesInTree(int n, int[][] edges) {
g = new ArrayList[n];
Arrays.setAll(g,e -> new ArrayList<>());
for(int[] e:edges){
g[e[0]].add(e[1]);
g[e[1]].add(e[0]);
}
ans = new int[n];
size = new int[n];
Arrays.fill(ans,0);
dfs(0,-1,0);
reboot(0,-1);
return ans;
}
private void dfs(int index,int fa,int depth){
ans[0] += depth;
size[index] = 1;
for(int y:g[index]){
if(y != fa){
dfs(y,index,depth + 1);
size[index] += size[y];
}
}
}
private void reboot(int x,int fa){
for(int y:g[x]){
if(y!=fa){
ans[y] = ans[x] + g.length - 2 * size[y];//ans[y] = ans[x] - size[y] + (n - size[y])
reboot(y,x);//以y为根,x为父节点
}
}
}
}
对于本题来说:
如果节点x和y相邻,那么[以x为根的树]变为[以y为根的树],就只有x和y的父子关系改变了,其余相邻节点之间的父子关系没有改变。所以只有[x,y]和[y,x]这两个猜测的正确性变化了,其余猜测的正确性不变。
因此,在计算出以0为根的cnt之后,可以再次从0出发,DFS这颗树。从节点x递归到节点y时:
若有猜测[x,y],那么猜对的次数-1。
若有猜测[y,x],那么猜对的次数+1。
DFS的同时,统计猜对次数>=k的节点个数,即为答案。
这里我所担心的:可能出现的可行解但是次序相反的问题不会出现,所以建树即可。
统计可能出现的树根数目:
class Solution {
private List<Integer>[] g;
private Set<Long> set;
int k,ans,cnt0;
public int rootCount(int[][] edges, int[][] guesses, int k) {
this.k = k;
//建树
g = new ArrayList[edges.length + 1];
Arrays.setAll(g,e -> new ArrayList<>());
for(int[] e:edges){
g[e[0]].add(e[1]);
g[e[1]].add(e[0]);
}
//将guesses映射到set中,将2个4字节映射为1个8字节。
set = new HashSet<>();
for(int[] guess:guesses){
set.add((long)guess[0] << 32 | guess[1]);
}
cnt0 = 0;
dfs(0,-1);
ans = 0;
reroot(0,-1,cnt0);
return ans;
}
private void dfs(int x,int fa){
for(int y:g[x]){
if(y != fa){
if(set.contains((long)x << 32 | y))cnt0++;
dfs(y,x);
}
}
}
private void reroot(int x,int fa,int cnt){
if(cnt >= k)ans++;
for(int y:g[x]){
if(y != fa){
int c = cnt;
if(set.contains((long)x << 32 | y))c--;
if(set.contains((long)y << 32 | x))c++;
reroot(y,x,c);
}
}
}
}
2024/3/1
检查数组是否有效划分
dp问题,一开始自己是把模型都建立出来了,但是却错误纠结覆盖子数组中是否有被其它数组挪用的情况。对于f[i]来说,只要前2个或者3个是能划分的,那么就能判定当前的子数组是否能划分。
也就是说,这里我思考的:
dp[i]前i个数字是否能有效划分
对于i来说,若能划分,有这些情况:
1.dp[i - 1]能划分,但dp[i - 2]不能划分,且nums[i - 1] = nums[i - 2] = nums[i]
2.dp[i - 1]不能划分,但dp[i - 2]能划分,且nums[i - 1] = nums[i]
3.dp[i - 1]不能划分,且dp[i - 2]也不能划分,但dp[i - 3]能划分,且有nums[i] = nums[i - 1] + 1 = nums[i - 2] + 2
只需要考虑能划分,不需要思考中间的数据不被划分的情况。
此时可以进行递推,得到最终的结果。
class Solution {
public boolean validPartition(int[] nums) {
/*
dp[i]前i个数字是否能有效划分
对于i来说,若能划分,有这些情况:
1.dp[i - 1]能划分,但dp[i - 2]不能划分,且nums[i - 1] = nums[i - 2] = nums[i]
2.dp[i - 1]不能划分,但dp[i - 2]能划分,且nums[i - 1] = nums[i]
3.dp[i - 1]不能划分,且dp[i - 2]也不能划分,但dp[i - 3]能划分,且有nums[i] = nums[i - 1] + 1 = nums[i - 2] + 2
会不会出现这种情况:
4,4,4,4
*/
int n = nums.length;
boolean[] f = new boolean[n + 1];
f[0] = true;
for(int i = 1;i < n;i++){
if (f[i - 1] && (nums[i] == nums[i - 1])||
i > 1 && f[i - 2] && ((nums[i] == nums[i - 1] && nums[i - 1] == nums[i - 2]) ||
nums[i] == nums[i - 1] + 1 && nums[i] == nums[i - 2] + 2))
f[i + 1] = true;
}
return f[n];
}
}
2024/3/2
受限条件下可到达节点的数量
DFS遍历,唯一注意点的就是不要遍历到父节点。
class Solution {
int cnt = 0;
public int reachableNodes(int n, int[][] edges, int[] restricted) {
boolean[] isrestricted = new boolean[n];
for (int x : restricted) {
isrestricted[x] = true;
}
List<Integer>[] g = new List[n];
for (int i = 0; i < n; i++) {
g[i] = new ArrayList<Integer>();
}
for (int[] v : edges) {
g[v[0]].add(v[1]);
g[v[1]].add(v[0]);
}
dfs(0, -1, isrestricted, g);
return cnt;
}
public void dfs(int x, int f, boolean[] isrestricted, List<Integer>[] g) {
cnt++;
for (int y : g[x]) {
if (y != f && !isrestricted[y]) {
dfs(y, x, isrestricted, g);
}
}
}
}
2024/3/3
用队列实现栈
简单题,运用Deque即可。
offerLast,peekLast,pollLast,offerFirst,peekFirst,pollFirst,new LinkedList<>()
class MyStack {
private Deque<Integer> deque;
public MyStack() {
this.deque = new LinkedList<>();
}
public void push(int x) {
deque.offerLast(x);
}
public int pop() {
return deque.pollLast();
}
public int top() {
return deque.peekLast();
}
public boolean empty() {
return deque.isEmpty();
}
}
删除有序数组中的重复项
面试150题中的中等题。
我的思路就是纯模拟,时间复杂度略高,代码量也大一点。对于双指针运用有点不熟练,需要多练习。
题解思路:利用slow和fast双指针并行操作,slow用于更新,fast用于遍历。由于数组以及排好序了,所以对当前的fast来说,只要当前值与slow - 2的值不重复,就代表满足条件,否则slow就更新。
//我的代码
class Solution {
public int removeDuplicates(int[] nums) {
//找需要替换的子数组开始和结束坐标
int i = 0;
int pre = -1;
int ans = nums.length;
int cnt = 0;
int from,to;
while(true){
if(i >= ans)return ans;
if(nums[i] != pre){
cnt = 1;
pre = nums[i];
i++;
continue;
}
cnt++;
if(cnt > 2){
from = i;
while(i + 1 < ans && nums[++i] == pre){
cnt++;
}
int j = i;
int k = from;
while(j < ans){
nums[k++] = nums[j++];
}
ans -= (cnt - 2);
i = from;
}
else i++;
}
}
}
//题解:
class Solution {
public int removeDuplicates(int[] nums) {
int n = nums.length;
if(n <= 2)return n;//对于数组长度为2的,直接返回
int fast = 2,slow = 2;
while(fast < n){
if(nums[slow - 2] != nums[fast]){
nums[slow++] = nums[fast];
}
fast++;
}
return slow;
}
}
2024/3/4
栈实现队列
Deque操作即可。
class MyQueue {
Deque<Integer> deque;
public MyQueue() {
this.deque = new LinkedList<Integer>();
}
public void push(int x) {
deque.addLast(x);
}
public int pop() {
return deque.pollFirst();
}
public int peek() {
return deque.peekFirst();
}
public boolean empty() {
return deque.isEmpty();
}
}
轮转数组
第一种方法:使用额外数组存储。
第二种方法(题解):首先,将数组进行整体反转,此时后k % n位到前面来了。然后将前k位进行反转,得到正确的k % n位顺序,最后将后 n - (k % n)位进行反转,得到正确的前置顺序。
class Solution {
public void rotate(int[] nums, int k) {
// for(int i = 0;i < k;i++)rotateOneStep(nums);//这样O(nk)会超时
//后k个数可以视为一个子数组,顺序是不变的,依次放入即可,空间复杂度为O(k)
int[] kNums = new int[k];
int n = nums.length;
k = k % n;
if(n == 1)return;
for(int j = 0;j < k;j++){
kNums[j] = nums[j + n - k];
}
for(int i = n - k - 1;i >= 0;i--){
nums[i + k] = nums[i];
}
for(int i = 0;i < k;i++){
nums[i] = kNums[i];
}
}
public void rotateOneStep(int[] nums){
int n = nums.length;
int last = nums[n - 1];
for(int i = n - 1;i > 0;i--){
nums[i] = nums[i - 1];
}
nums[0] = last;
}
}
//题解:
class Solution {
public void rotate(int[] nums, int k) {
/*
首先,将数组进行整体反转,此时后k % n位到前面来了
然后将前k位进行反转,得到正确的k % n位顺序
最后将后 n - (k % n)位进行反转,得到正确的前置顺序
*/
int n = nums.length;
k %= n;
reverse(nums,0,n - 1);
reverse(nums,0,k - 1);
reverse(nums,k,n - 1);
}
public void reverse(int []nums,int s,int e){
int temp;
while(s < e){
temp = nums[s];
nums[s] = nums[e];
nums[e] = temp;
s++;
e--;
}
}
}
买卖股票的最佳时机I
从前往后,记录直到现在的最小购入价格,同时计算最大利润。
class Solution {
public int maxProfit(int[] prices) {
int mins = 10005;
int ans = 0;
for(int i = 0;i < prices.length;i++){
ans = Math.max(ans,prices[i] - mins);
mins = Math.min(mins,prices[i]);
}
return ans;
}
}
买卖股票的最佳时机II
我的思路:逆序递推,dp[i]从当天开始进行操作能获取到的最大利润。若当天选择不买入,则dp[i] = dp[i + 1],若当天选择买入,则枚举后续值是否有操作比当前还大。时间复杂度为(O(n2)),案例较弱,让我混过去了。
题解dp:dp[i][0]表示第i天交易完后手里没有股票的最大利润,dp[i][1]代表第i天交易完后手里持有一只股票的最大利润。
dp[i][0] = max(dp[i-1][0],dp[i-1][1] + prices[i])
dp[i][1] = max(dp[i - 1][1],dp[i - 1][0] - prices[i])
dp[0][0] = 0
dp[0][1] = -prices[0]
最后答案为dp[n-1][0]
题解贪心:题目中给定的描述是,可以当天买入,当天卖出。所以即时第三天直接卖出的利润比第四天卖出的利润要小,但是由于这个设置,我们可以在第三天卖出之后再买入,再在第四天卖出,实际的利润也等于第四天直接卖出。所以只需要统计所有上升的窗口为2的数组即可。
//我的dp
class Solution {
public int maxProfit(int[] prices) {
int n = prices.length;
int[] dp = new int[prices.length + 1];
dp[n - 1] = 0;
dp[n] = 0;
int ans = 0;
for(int i = n - 2;i >= 0;i--){
dp[i] = dp[i + 1];//当前不买
for(int j = i + 1;j < n;j++){
dp[i] = Math.max(dp[i],prices[j] - prices[i] + dp[j + 1]);
}
ans = Math.max(ans,dp[i]);
}
return ans;
}
}
//题解dp
class Solution {
public int maxProfit(int[] prices) {
int n = prices.length;
int[][] dp = new int[n][2];
dp[0][0] = 0;
dp[0][1] = -prices[0];
for (int i = 1; i < n; ++i) {
dp[i][0] = Math.max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
}
return dp[n - 1][0];
}
}
//题解贪心
class Solution {
public int maxProfit(int[] prices) {
int n = prices.length;
int dp0 = 0, dp1 = -prices[0];
for (int i = 1; i < n; ++i) {
int newDp0 = Math.max(dp0, dp1 + prices[i]);
int newDp1 = Math.max(dp1, dp0 - prices[i]);
dp0 = newDp0;
dp1 = newDp1;
}
return dp0;
}
}
2024/3/5
到达目的地的方案数
在用dij求最短路径时,利用dp记录方案数量。
dp[i] = 从起点0到达i的最少时间方案数量。
dp[0] = 1
如果dis[i] > dis[index] + g[index][i],代表最短路被更新,那么dp[i] = dp[index]
如果dis[i] == dis[index] + g[index][i],那么代表有另外的最短路方案,dp[i] += dp[index]
需要注意的点是,time < 1e9,而Integer.MAX_VALUE ≈ 1e9,若用其做最大值标注,可能出现溢出的情况,保险起见,还是用Long来记录图和dis。
由于是稠密图,所以无需使用堆进行优化。
class Solution {
private int mod = (int)1e9 + 7;
/*
dp[i]:从起点0出发到达i的最少时间的方案数量。
dp[i][j]:从i到j的最少时间方案数量
dis[i]:从起点0出发到达i的最少时间
vis[i]:i是否已经被访问了
*/
long[][] g;
long[] dis;
int[] dp;
boolean[] vis;
public int countPaths(int n, int[][] roads) {
g = new long[n][n];
dis = new long[n];
dp = new int[n];
vis = new boolean[n];
for(int i = 0;i < n;i++)Arrays.fill(g[i],Long.MAX_VALUE / 2);
for(int i = 0;i < roads.length;i++){
g[roads[i][0]][roads[i][1]] = roads[i][2];
g[roads[i][1]][roads[i][0]] = roads[i][2];
}
Arrays.fill(dis,Long.MAX_VALUE / 2);
Arrays.fill(dp,0);
Arrays.fill(vis,false);
dij(n);
return dp[n - 1] % mod;
}
public void dij(int n){
dis[0] = 0;
vis[0] = true;
dp[0] = 1;
//初始化
for(int i = 1;i < n;i++){
dis[i] = g[0][i];
if(dis[i] != Long.MAX_VALUE / 2)dp[i] = 1;
}
for(int i = 0;i < n;i++){
//找n - 1条路径
long mins = Long.MAX_VALUE / 2;
int index = 0;
for(int k = 0;k < n;k++){
if(!vis[k] && mins > dis[k]){
mins = dis[k];
index = k;
}
}
//更新vis
vis[index] = true;
//遍历剩余节点,更新dis和dp
for(int k = 0;k < n;k++){
if(!vis[k] && dis[k] > dis[index] + g[index][k]){
dis[k] = dis[index] + g[index][k];
dp[k] = dp[index];//最短距离更新了,那么对应的方案也需要更新。
}
else if(!vis[k] && dis[k] == dis[index] + g[index][k]){
dp[k] += dp[index];
dp[k] %= mod;
}
}
}
}
}
跳跃游戏
贪心:策略是花更少的步数走的更远。
因此对于当前所在的位置i来说,停留的位置为max j + nums[i + j],其中0 < j <= nums[i].
class Solution {
public int jump(int[] nums) {
/*
[2,1,1,1,4]
贪心策略,目的是花更少的步数走的更远
因此,走到范围内和加起来最多的即可。
*/
int n = nums.length;
int ans = 0;
int idx = 0;//当前所在的坐标
while(true){
if(idx >= n - 1)break;
int maxs = 0;
int index = -1;
for(int i = 1;i <= nums[idx];i++){
if(idx + i >= n - 1)return ans + 1;
if(i + nums[idx + i] > maxs){
maxs = i + nums[idx + i];
index = idx + i;
}
}
if(index != -1){
ans++;//走到下一步。
idx = index;
}
}
return ans;
}
}
H指数
二分搜索,在[0,n]中搜索K是否满足要求。
class Solution {
public int hIndex(int[] citations) {
int n = citations.length;
/*
[0,n]搜索
check一下
*/
int left = 0,right = n;
Arrays.sort(citations);
while(left <= right){
int mid = (left + right) >> 1;
if(check(mid,n,citations)){
left = mid + 1;
}else{
right = mid - 1;
}
}
return left - 1;
}
boolean check(int h,int n,int[] citations){
int i = n - 1;//检查是否>h
while(i >= 0 && citations[i] >= h)i--;
return (n - i - 1) >= h;
}
}
2024/3/6
找出数组中的K-or值
用的map记录,但可以通过枚举每一个32个bit位判断,自己的方法有点浪费时间。
class Solution {
public int findKOr(int[] nums, int k) {
Map<Integer,Integer> map = new HashMap<>();
for(int i = 0;i < nums.length;i++){
int x = nums[i];
int cnt = 0;
while(x!=0){
if((x & 1) == 1){
map.put(cnt,map.getOrDefault(cnt,0) + 1);
}
cnt++;
x >>= 1;
}
}
Set<Integer> set = map.keySet();
int ans = 0;
for(Integer i:set){
if(map.get(i) >= k){
ans += (1 << i);
}
}
return ans;
}
}
//题解:
class Solution {
public int findKOr(int[] nums, int k) {
int ans = 0;
for (int i = 0; i < 31; ++i) {
int cnt = 0;
for (int num : nums) {
if (((num >> i) & 1) != 0) {
++cnt;
}
}
if (cnt >= k) {
ans |= 1 << i;
}
}
return ans;
}
}
O(1)时间插入、删除和获取随机元素值
我只用了一个set进行操作,但是这样在随机获取元素值时,就只能遍历,最坏情况为O(n)。
可以利用list同步记录操作,由于数字的顺序无关,可以将最后一个值放入需要remove的地方,然后移除掉最后一个值。
class RandomizedSet {
Set<Integer> set;
public RandomizedSet() {
set = new HashSet();
}
public boolean insert(int val) {
if(set.contains(val) == true)return false;
set.add(val);
return true;
}
public boolean remove(int val) {
if(set.contains(val) == false) return false;
set.remove(val);
return true;
}
public int getRandom() {
int idx = new Random().nextInt(set.size());
int cnt = 0;
for(Integer i:set){
if(idx == cnt)return i;
cnt++;
}
return 0;
}
}
//题解:
class RandomizedSet {
Random random;
HashMap<Integer,Integer> map;
ArrayList<Integer> list;
public RandomizedSet() {
map = new HashMap();
list = new ArrayList();
random = new Random();
}
public boolean insert(int val) {
if(map.containsKey(val)){
return false;
}
int index = list.size();
list.add(val);
map.put(val,index);
return true;
}
public boolean remove(int val) {
if(!map.containsKey(val)){
return false;
}
int index = map.get(val);
int last = list.get(list.size()-1);
list.set(index,last);
map.put(last,index);
map.remove(val);
list.remove(list.size()-1);
return true;
}
public int getRandom() {
return list.get(random.nextInt(list.size()));
}
}
除自身以外的乘积
对前缀思想的利用。只记住前缀和是不行的。
除自身以外的乘积,是由左部分的乘积 * 右部分的乘积。
因此利用前缀的思想,将左部分的乘积和右部分的乘积单独进行记录。
最终答案 = L[i] * R[i]
class Solution {
public int[] productExceptSelf(int[] nums) {
int n = nums.length;
int[] L = new int[n];
int[] R = new int[n];
L[0] = 1;
for(int i = 1;i<n;i++){//左边第一个元素没有左乘积
L[i] = nums[i - 1] * L[i - 1];
}
R[n - 1] = 1;
for(int i = n - 2;i >=0 ;i--){//右边第一个元素没有右乘积
R[i] = nums[i + 1] * R[i + 1];
}
for(int i = 0;i < n;i++){
nums[i] = L[i] * R[i];
}
return nums;
}
}
2024/3/7
2575. 找出字符串的可整除数组
看了提示,才想到可以由上一步的余数推导出当前的余数。
假设上一步的数为x,倍数为y,余数为z,则有
x = y * m + z
假设当前步增加h
x * 10 + h = 10 * (y * m + z) + h = 10 * y * m + 10 * z + h
余数应为:(10 * z + h) % m
需要注意的点:即时是上一步遗留的余数*10+h,有可能会爆int,因为m给的范围很大。
class Solution {
public int[] divisibilityArray(String word, int m) {
/*
卡大数据long也没法过。
z = x % m;
x = m * y + z;
x * 10 + h = (m * y + z) * 10 + h = 10 * y * m + 10 * z + h
x * 10 + h = 10y * m + 10 * z + h;
10 * z + h 就为x * 10 + h的余数
*/
int n = word.length();
int[] div = new int[n];
int[] dp = new int[n];
long preMod = 0;
Arrays.fill(div,0);
for(int i = 0;i < n;i++){
int c = word.charAt(i) - '0';
preMod = (preMod * 10 + c) % m;
if(preMod == 0){
div[i] = 1;
}
}
return div;
}
}
134. 加油站
看了题解,一目了然。
本质上是利用一个可以传递的性质,进行一次遍历。
对于从x出发,最多能到达的加油站y来说,对于所有在其中间的加油站j(x < j < y),其最远距离都只能到达y。因为从x到j,其油量必须>=0,对于=0来说,j能到达y,对于>0来说,可能连y都达不到。
因此,可以利用一次遍历,对于当前起点i来说,若走到y之后走不下去了,就换到起点y + 1进行遍历。
class Solution {
public int canCompleteCircuit(int[] gas, int[] cost) {
int n = gas.length;
int i = 0;//记录起点
while(i < n){
int cnt = 0;//记录当前的遍历次数
int gasSum = 0;//剩余油量
int idx = i;
while(cnt < n){
gasSum += gas[idx];
gasSum -= cost[idx];
if(gasSum < 0){
break;
}
idx = (idx + 1) % n;
cnt++;
}
if(cnt == n){
return i;
}
i = i + cnt + 1;
}
return -1;
}
}
2024/3/8
2834. 找出美丽数组的最小和
贪心策略,若想放入值最小,那么就应该从1开始放入,但是又要避免不美丽的情况,对于1来说,target - 1就不能放入了,以此类推。
因此,假设[1,target)中填充m个数组,那么m = target / 2个,其中的数据分别为[1,2,…,m],对于>=target的数据来说,则挨着存即可,[target,target + n - m],等差数列求和。
需要注意的点是,存在有n远远小于target的情况,当满足条件target > 2 * n + 1,代表及时[1,n]全部填充,也不会到达target。
class Solution {
public int mod = (int)1e9 + 7;
public int minimumPossibleSum(int n, int target) {
/*
填充规则:从1开始,如果当前值<target,那么,只填充i,不填充target - i。直到 >= target为止。
分为两部分[1,target).length = m,[target,target + n - m]
*/
long sums = 0;
//1 + ... + target/2
if(target > 2 * n + 1){
sums = n * (n + 1) / 2 % mod;
return (int)sums % mod;
}
long m = target / 2;
sums += (m * (m + 1) / 2) % mod;
//target + ... + target + n - m
long k = n - m;
sums += (k * (target + target + k - 1) / 2) % mod;
return (int) sums % mod;
}
}
42. 接雨水
我的思路:利用单调栈进行求解,从大到小记录高度,若当前高度<=栈顶高度,则加入。
若当前高度>栈顶高度,则开始循环判断,若前面的数据中存在落差(即height[j] > pre,pre = height[j]),则计算当前能存储的雨量,并将该落差填平。
因此当当前高度>栈顶高度,开始判断时,有以下情况:
- 存在落差(栈不为空,且有前面的数据 > 后面的数据的情况)
此时需要计算填充的数量。利用idx记录左右两边的坐标,以最小的高度 * 长度,算出最大能填充的数量,并减去pre高度 * 长度(易见,在这种情况下,中间全是pre高度,否则早就形成了落差并填平)。
算出后,将原有左端点继续放入栈中,代表填平。
仍存在两种情况,一种当前高度<=左边高度,那么以当前高度为右的区域就不能再形成落差,那么就可以结束当前循环。
若当前高度>左边的高度,那么可能还存在左边还有更高的高度能和当前形成落差,因此循环继续。 - 不存在落差,结束当次循环
最后,将当前高度加入到栈顶。
class Solution {
public int trap(int[] height) {
/*
单调栈问题:
从大到小记录高度,若当前高度<=栈顶高度,则加入。
若当前高度>栈顶高度,则开始出栈,由于是需要形成一个水坝,所以需要找到落差。
出栈终止条件为,栈顶>pre,出栈时记录出栈元素,计算出后,把当前计算的值填充并加入栈,再把当前元素加入到栈。
*/
int n = height.length;
class Node{
int val;
int idx;
Node(int x,int y){
this.val = x;
this.idx = y;
}
}
Deque<Node> dq = new LinkedList<>();
int sums = 0;
for(int i = 0;i < n;i++){
if(dq.isEmpty() || height[i] <= dq.peekLast().val){
dq.addLast(new Node(height[i],i));
}
else{
//出栈,并判断是否有落差,记录cnt
while(true){
int cnt = 0;
int pre = height[i];
while(!dq.isEmpty()&&pre >= dq.peekLast().val){
pre = dq.pollLast().val;
cnt++;
}
//若不存在落差
if(dq.isEmpty() || cnt == 0){
break;
}
//存在落差,计算值
Node temp = dq.pollLast();
int mins = Math.min(temp.val,height[i]);
//计算距离
int dis = i - temp.idx - 1;
sums += mins * dis - pre * dis;//计算最终的雨量
dq.addLast(temp);
if(height[i] <= temp.val){
break;
}
}
dq.addLast(new Node(height[i],i));
}
}
return sums;
}
}
2024/3/9
2386. 找出数组的第 K 大和
我的思路:有考虑到利用绝对值+优先队列的方式求解。但是并没有将问题转化为找第k小子序列问题。
题解思路:
对于最大值,可以通过计算数组中的所有正数进行计算。对于第k大和来说,可以在最大值的基础上减去一个正数或者加上负数,其实本质上都是减去其绝对值。此时可以将问题变为nums[i]取绝对值之后的第k小子序列,最后的第K大和答案就是最大值-第k小子序列。
如何构造第k小子序列?最小的子序列一定是空集,在空集的基础上,可以通过替换一个值或者增加一个值进行构建子序列。比如序列[1,2,3]的最小子序列:
1.[]
2.[1] -> 空集基础上增加1
3.[2] -> 步骤2的基础上将1换为2
4.[1,2] -> 步骤2的基础上增加2
5.[3] -> 步骤3的基础上将2换为3
6.[1,3] -> 步骤4的基础上将2换为3
7.[2,3] -> 步骤3的基础上增加3
8.[1,2,3] -> 步骤4的基础上增加3
利用堆记录最小子序列之和,即可求解。
class Solution {
public long kSum(int[] nums, int k) {
/*
题解:将问题转换为nums[i]取绝对值后找第k小子序列。
对于非负子序列来说,最小值为空集,0;
对于样例[2,4,-2]来说,转换为绝对值后,[2,4,2] -> [2,2,4];
(1) => []
(2) => [2]
(3) => [2]
(4) => [4]
(5) => [2,2]
(6) => [2,4]
(7) => [2,4]
(8) => [2,2,4]
之后利用最大值减去第k最小值,就为最终的答案。
利用优先队列记录当前子序列的和,以及下一个子序列要增加和替换的元素。
*/
long total = 0;
int n = nums.length;
for(int i = 0;i < n;i++){
if(nums[i] >= 0){
total += nums[i];
}else{
nums[i] = -nums[i];
}
}
Arrays.sort(nums);
PriorityQueue<Pair<Long,Integer>> pq = new PriorityQueue<>((a,b) -> Long.compare(a.getKey(),b.getKey()));
pq.offer(new Pair<>(0L,0));
while(--k > 0){
Pair<Long,Integer> temp = pq.poll();
long ret = temp.getKey();
int i = temp.getValue();
if(i < n){
pq.offer(new Pair<>(ret + nums[i],i + 1));
if(i > 0){
pq.offer(new Pair<>(ret + nums[i] - nums[i - 1],i + 1));
}
}
}
return total - pq.peek().getKey();
}
}
2024/3/10
299. 猜数字游戏
两次遍历,先把公牛的数量求出,此时,将公牛所在的数字位去除,然后分别统计原始和猜测的数字位出现的次数,再利用数组(这里用的hashmap,其实可以用数组)进行记录,最后取两者最小值。
class Solution {
public String getHint(String secret, String guess) {
int n = secret.length();
//统计公牛个数
int bullsCnt = 0;
Map<Character,Integer> secretMap = new HashMap<>();
Map<Character,Integer> guessMap = new HashMap<>();
for(int i = 0;i < n;i++){
if(secret.charAt(i) == guess.charAt(i)){
bullsCnt++;
}else{
secretMap.put(secret.charAt(i),secretMap.getOrDefault(secret.charAt(i),0) + 1);
guessMap.put(guess.charAt(i),guessMap.getOrDefault(guess.charAt(i),0) + 1);
}
}
int cowCnt = 0;
Set<Character> set = secretMap.keySet();
for(Character c:set){
int a = secretMap.get(c);
int b = guessMap.getOrDefault(c,0);
cowCnt += Math.min(a,b);
}
String ans = String.format("%dA%dB",bullsCnt,cowCnt);
return ans;
}
}
135. 分发糖果
思路:也考虑过利用左右乘积的思想,完成该题,但是没有动手写,遗憾。
题解:将规则拆分为左规则和右规则,遍历两次,取左右规则最大的值作为最终值。
class Solution {
public int candy(int[] ratings) {
int n = ratings.length;
int[] left = new int[n];
Arrays.fill(left,1);
for(int i = 0;i < n - 1;i++){
if(ratings[i + 1] > ratings[i]){
left[i + 1] = left[i] + 1;
}
}
int[] right = new int[n];
Arrays.fill(right,1);
for(int i = n - 1;i > 0;i--){
if(ratings[i - 1] > ratings[i]){
right[i - 1] = right[i] + 1;
}
}
int ans = 0;
for(int i = 0;i < n;i++){
ans+= Math.max(right[i],left[i]);
}
return ans;
}
}
2024/3/11
2129. 将标题首字母大写
转为小写,再判断
class Solution {
public String capitalizeTitle(String title) {
String[] words = title.split(" ");
StringBuilder ans = new StringBuilder();
int n = words.length;
for(int i = 0;i < n;i++){
String word = words[i].toLowerCase();
int m = word.length();
for(int j = 0;j < m;j++){
if(m > 2 && j == 0){
ans.append((char)('A' + word.charAt(j) - 'a') + "");
}else{
ans.append(word.charAt(j) + "");
}
}
if(i != n - 1)ans.append(" ");
}
return ans.toString();
}
}
151. 反转字符串中的单词
trim和split划分
class Solution {
public String reverseWords(String s) {
String[] words = s.split(" ");
StringBuilder ans = new StringBuilder();
for(int i = words.length - 1;i >= 0;i--){
String word = words[i].trim();
int m = word.length();
int cnt = 0;
for(int j = 0;j < m;j++){
if(word.charAt(j) != ' '){
ans.append(word.charAt(j) + "");
cnt++;
}
}
if(cnt == 0)ans.deleteCharAt(ans.length()-1);
if(i != 0)ans.append(" ");
}
return ans.toString();
}
}
167. 两数之和 II - 输入有序数组
应该用双指针进行求解,这里用二分进行取巧了,时间复杂度为O(nlogn),样例比较弱。
题解:双指针
我存在的问题,老是把双指针当作滑动窗口进行思考,其实双指针的指向应该是没有限制的。
两个指针分别指向第一个元素位置和最后一个元素位置,若=target,则返回,若>target,则右侧–,若<target则左侧++。
是否会漏掉解?设i,j为答案,0 <= i < j <= n - 1。左指针指向的下标<=i,右指针指向的下标>=j,当解不是在初始位置时,一定有左指针先到达i或者右指针先到达j。
对于左指针先到达i的情况,此时右指针还在j的右边,sum > target,右指针左移
对于右指针先到达的情况,此时左指针在i的左边,sum < target。
可以看出不会把可能的解过滤掉,确保肯定能找到答案。
class Solution {
public int[] twoSum(int[] numbers, int target) {
/*
二分搜索,找到与target的差数,然后二分
*/
for(int i = 0;i < numbers.length;i++){
int temp = numbers[i];
numbers[i]-=1;
int idx = Arrays.binarySearch(numbers,target - temp);
numbers[i]+=1;
if(idx >=0 && idx < numbers.length){
return new int[]{i + 1,idx + 1};
}
}
return new int[]{0,1};
}
}
//题解
class Solution {
public int[] twoSum(int[] numbers, int target) {
/*
双指针法
*/
int left = 0,right = numbers.length - 1;
while(left < right){
int sums = numbers[left] + numbers[right];
if(sums == target){
return new int[]{left + 1,right + 1};
}
if(sums > target){
right--;
}
else{
left++;
}
}
return new int[]{-1,-1};
}
}
2024/3/12
1261. 在受污染的二叉树中查找元素
我的做法:死板做法,先生成树,再接着遍历。
两种方式进行优化:1.建立树时将值用set保存,find直接判断即可。
2.利用位运算进行优化,左边为左移并加1,右边为左移加2.
class FindElements {
private TreeNode root;
private boolean flag;
public void FindElementsHelp(TreeNode root,int val){
if(root == null)return;
root.val = val;
FindElementsHelp(root.left,val * 2 + 1);
FindElementsHelp(root.right,val * 2 + 2);
}
public FindElements(TreeNode root) {
FindElementsHelp(root,0);
this.root = root;
}
public void findHelp(TreeNode root,int val){
if(root == null)return;
if(flag == true)return;
if(root.val == val){
flag = true;
return;
}
if(root.val > val){
return;
}
findHelp(root.left,val);
findHelp(root.right,val);
}
public boolean find(int target) {
//根 < 左 < 右
flag = false;
findHelp(this.root,target);
return flag;
}
}
2024/3/13
class Solution {
public String maximumOddBinaryNumber(String s) {
int n = s.length();
StringBuilder ans = new StringBuilder();
int m = 0;
for(int i = 0;i < n;i++){
if(s.charAt(i) == '1')m++;
}
for(int i = 0;i < m - 1;i++){
ans.append("1");
}
for(int i = 0;i < n - m;i++){
ans.append("0");
}
if(m >= 1){
ans.append("1");
}
return ans.toString();
}
}
2024/3/14
2789. 合并后数组中的最大元素
贪心策略还是有点不太会找,以后按照这种方式进行思考:1.先找到暴力解法,2.根据暴力解法一步步进行优化。
暴力解法:
枚举从第i个元素开始向左开始合并,总的时间复杂度是O(n2)
思考优化:
若从第n-1个元素开始枚举,逆序合并,到第j个元素结束合并。那么则有nums[j - 1] > nums[j] + nums[j + 1] + … + nums[n - 1],对于j 到n - 2中的任意元素,都不需要再次枚举了,因为数组为正数,它们不可能再获得比从n-1开始更大的元素值了。此时,再从j - 1开始枚举即可,最大值也是nums[j - 1]。这样就可以一次遍历出最终答案。
class Solution {
public long maxArrayValue(int[] nums) {
long sum = nums[nums.length - 1];
for (int i = nums.length - 2; i >= 0; i--) {
sum = nums[i] <= sum ? nums[i] + sum : nums[i];
}
return sum;
}
}
impl Solution {
pub fn max_array_value(nums: Vec<i32>) -> i64 {
let n = nums.len();
let mut sums:i64 = nums[n - 1] as i64;
for i in (0..n-1).rev(){
let x:i64 = nums[i] as i64;//get获得是借用
sums = if x <= sums {sums + x} else {x};
}
sums
}
}
2024/3/19
1793. 好子数组的最大分数
伪装成为困难题的中等题。
贪心+双指针。贪心策略:在最小值不变的情况下,尽可能扩大区间长度。对于左右来说,选择两者最小值进行扩散。
class Solution {
public int maximumScore(int[] nums, int k) {
/*
往左或者往右扩散,其长度加大,但是其元素大小可能会发生变化。
双指针问题?
1.对于左右两个指针,若找到不会让元素大小变小的树,则直接开始扩散
2.若找到会让元素大小变小的数,则记录一次ans值,然后进行扩散。
*/
int left = k,right = k,ans = nums[k];
int mins = nums[k];
while(left >= 0 || right <nums.length){
while(left >= 0 && nums[left] >= mins){
left--;
}
while(right < nums.length && nums[right] >= mins){
right++;
}
//如果没有直接找到结果
if(left >= 0 && right < nums.length){
//对于不更新最小值的进行计算
ans = Math.max(ans,((right - 1 - (left + 1) + 1)) * mins);
//左右两边都有小于mins的值,取两者最大的进行计算
if(nums[right] >= nums[left]){
mins = nums[right];
left++;
//计算ans
}
else{
mins = nums[left];
right--;
}
int sums = (right - left + 1) * mins;
if(sums > ans){
ans = sums;
}
}else if(left >= 0){
//对于不更新最小值的进行计算
ans = Math.max(ans,((right - 1 - (left + 1) + 1)) * mins);
mins = nums[left];
int sums = (right - left) * mins;
if(sums > ans){
ans = sums;
}
}else if(right < nums.length){
//对于不更新最小值的进行计算
ans = Math.max(ans,(right - 1 - (left + 1) + 1) * mins);
mins = nums[right];
int sums = (right - left)* mins;
if(sums > ans){
ans = sums;
}
}else{
int sums = (right - 1 - (left + 1) + 1) * mins;
if(sums > ans){
ans = sums;
}
}
}
return ans;
}
}
impl Solution {
pub fn maximum_score(nums: Vec<i32>, k: i32) -> i32 {
let mut sums;
let mut left = k;
let mut right = k;
let mut ans = nums[k as usize];
let mut mins = nums[k as usize];
while(left >= 0 || (right < nums.len() as i32)){
while(left >= 0 && nums[left as usize] >= mins){
left-=1;
}
while((right < nums.len() as i32) && nums[right as usize] >= mins){
right+=1;
}
if(left >= 0 && (right < nums.len() as i32)){
sums = (right - 1 - (left + 1) + 1) * mins;
ans = ans.max(sums);
if(nums[right as usize] >= nums[left as usize]){
mins = nums[right as usize];
left+=1;
}else{
mins = nums[left as usize];
right-=1;
}
sums = (right - left + 1) * mins;
if(sums > ans){
ans = sums;
}
}else if(left >= 0){
ans = ans.max((right - 1 - left) * mins);
mins = nums[left as usize];
sums = (right - left) * mins;
if(sums > ans){
ans = sums;
}
}else if((right < nums.len() as i32)){
ans = ans.max((right - 1 - left) * mins);
mins = nums[right as usize];
sums = (right - left) * mins;
if(sums > ans){
ans = sums;
}
}
else{
sums = (right - 1 - (left + 1) + 1) * mins;
if(sums > ans) {
ans = sums;
}
}
}
ans
}
}
rust重点注意left - 1之后0溢出的问题。
2024/3/20
数论题,有点不太会
1969. 数组元素的最小非零乘积
/*
1.交换后所有数字之和不变
2.交换是交换,上限不超2^p - 1
3.二进制位上0、1数量是相对不变的
4.1要尽可能的多,末位的1的数量给出上限。
5.所以就是2^(p - 1) - 1个1,2^(p - 1) - 1个2^ (p - 2),还有一个2^(p - 1)
*/
class Solution {
public int minNonZeroProduct(int p) {
/*
1.交换后所有数字之和不变
2.交换是交换,上限不超2^p - 1
3.二进制位上0、1数量是相对不变的
4.1要尽可能的多,末位的1的数量给出上限。
5.所以就是2^(p - 1) - 1个1,2^(p - 1) - 1个2^ (p - 2),还有一个2^(p - 1)
*/
int[] ans = {0, 1, 6, 1512, 581202553, 202795991, 57405498, 316555604, 9253531, 857438053, 586669277, 647824153, 93512543, 391630296, 187678728, 431467833, 539112180, 368376380, 150112795, 484576688, 212293935, 828477683, 106294648, 618323081, 186692306, 513022074, 109245444, 821184946, 2043018, 26450314, 945196305, 138191773, 505517599, 861896614, 640964173, 112322054, 217659727, 680742062, 673217940, 945471045, 554966674, 190830260, 403329489, 305023508, 229675479, 865308368, 689473871, 161536946, 99452142, 720364340, 172386396, 198445540, 265347860, 504260931, 247773741, 65332879, 891336224, 221172799, 643213635, 926891661, 813987236};
return ans[p];
}}
2024/3/21
2671. 频率跟踪器
利用两个Map进行操作,第一个记录每一个元素的频率,第二个记录每个频率对应的元素。
细节:对于出现过但是频率为0的数,不能让其频率为-1
class FrequencyTracker {
/*
对于i来说,频率为j
删除则j--
增加则j++
如何做到O(1)时间内进行更新和查询?
*/
Map<Integer,Integer> cntMap;
Map<Integer, Set<Integer>> frequencyMap;
public FrequencyTracker() {
cntMap = new HashMap<>();
frequencyMap = new HashMap<>();
}
public void add(int number) {
int temp = cntMap.getOrDefault(number,0);
cntMap.put(number,temp + 1);
if(temp != 0 && frequencyMap.containsKey(temp)){
frequencyMap.get(temp).remove(number);
}
if(!frequencyMap.containsKey(temp + 1)){
frequencyMap.put(temp + 1,new HashSet<Integer>());
}
frequencyMap.get(temp + 1).add(number);
}
public void deleteOne(int number) {
if(!cntMap.containsKey(number))return;
int temp = cntMap.get(number);
if(temp == 0)return;
cntMap.put(number,temp - 1);
frequencyMap.get(temp).remove(number);
if(temp - 1 != 0 && !frequencyMap.containsKey(temp - 1)){
frequencyMap.put(temp - 1,new HashSet<Integer>());
}
if(temp - 1 != 0)frequencyMap.get(temp - 1).add(number);
}
public boolean hasFrequency(int frequency) {
if(!frequencyMap.containsKey(frequency))return false;
return frequencyMap.get(frequency).size() > 0;
}
}
2024/3/22
使用记忆化搜索完成,超时,卡最后几个样例,还是没想好应该如何优化。
题解:dp + 单调栈优化。
dp[i][j]:从i,j到m - 1,n - 1所需要的最小操作数。
对于i,j来说,可以往右走:k = j + g[i][j],也可以往下走,k = i + g[i][j],目标是找到所需移动的最小值。
利用单调栈进行优化,有这样一个性质,对于枚举j时,k的左边界j + 1是单调减小的,但是右边界没有单调性。因此,我们利用f值(最小移动数量)底小顶大的单调栈维护其dp[i][j]和下标j,由于j是倒叙枚举,单调栈中的下标是底大顶小的,那么在单调栈上二分查找最大的不超过 j+g 的下标 k,对应的dp[i][k]就是要计算的最小值。
class Solution {
public int minimumVisitedCells(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
int mn = 0;//记录当前最小值下标
List<int[]>[] colStacks = new ArrayList[n];//每个列的单调栈,由于要使用二分,所以不用stack
Arrays.setAll(colStacks,i -> new ArrayList<>());
List<int[]> rowSt = new ArrayList<>();
//由于是先行后列进行遍历,所以只需要一个行单调栈即可,所有列都需要一个单调栈
for(int i = m - 1;i >= 0;i--){
rowSt.clear();
for(int j = n - 1;j >= 0;j--){
int g = grid[i][j];
List<int[]> colSt = colStacks[j];//当前列的单调栈
mn = i < m - 1 || j < n - 1 ? Integer.MAX_VALUE : 1;//记录最小跳数
if(g > 0){
//可以向右,或者向下跳
int k = search(rowSt,j + g);//找向下跳的最小值
if(k < rowSt.size()){
mn = rowSt.get(k)[0] + 1;
}
k = search(colSt,i + g);//向右跳的最小值
if(k < colSt.size()){
mn = Math.min(mn,colSt.get(k)[0] + 1);
}
}
//代表可以到达m,n,此时更新单调栈
if(mn < Integer.MAX_VALUE){
//插入行单调栈
while(!rowSt.isEmpty() && mn <= rowSt.get(rowSt.size() - 1)[0]){
rowSt.remove(rowSt.size() - 1);
}
rowSt.add(new int[]{mn,j});
//插入列单调栈
while(!colSt.isEmpty() && mn <= colSt.get(colSt.size() - 1)[0]){
colSt.remove(colSt.size() - 1);
}
colSt.add(new int[]{mn,i});
}
}
}
return mn < Integer.MAX_VALUE ? mn : -1; // 最后一个算出的 mn 就是 f[0][0]
}
private int search(List<int[]> st,int target){
int left = -1,right = st.size();//开区间
while(left + 1 < right){
//区间不为空
int mid = left + (right - left) / 2;
if(st.get(mid)[1] <= target){
right = mid;
}
else{
left = mid;
}
}
return right;
}
}
2024/3/24
322. 零钱兑换
完全背包问题变种,从记忆化搜索->二维数组->单数组优化如下:
class Solution {
//记忆化搜索版本
int[] coins;
int[][] memo;
public int coinChange(int[] coins, int amount) {
memo = new int[coins.length][amount + 1];
this.coins = coins;
for(int[] row:memo){
Arrays.fill(row,-1);
}
int ans = dfs(coins.length - 1,amount);
if(ans >= Integer.MAX_VALUE / 2){
return -1;
}
return ans;
}
int dfs(int i,int amount){
if(i < 0){
if(amount == 0)return 0;
return Integer.MAX_VALUE / 2;//不能组成金额,则置为最大值
}
if(memo[i][amount] != -1){
return memo[i][amount];//记忆化搜索
}
if(coins[i] > amount){
//当前硬币不能选择
return memo[i][amount] = dfs(i - 1,amount);
}
return memo[i][amount] = Math.min(dfs(i - 1,amount),dfs(i,amount - coins[i]) + 1);
}
}
class Solution {
//朴素dp版本
public int coinChange(int[] coins, int amount) {
int[][] dp = new int[coins.length + 1][amount + 1];
for(int i = 0;i <= coins.length;i++){
Arrays.fill(dp[i],Integer.MAX_VALUE / 2);
}
/*
dp[i][j]:前i个硬币,所能构成数额j的最小硬币数量
*/
dp[0][0] = 0;
for(int i = 0;i < coins.length;i++){
for(int j = 0;j <= amount;j++){
if(j < coins[i]){
dp[i + 1][j] = dp[i][j];
continue;
}
dp[i + 1][j] = Math.min(dp[i][j],dp[i + 1][j - coins[i]] + 1);
}
}
if(dp[coins.length][amount] >= Integer.MAX_VALUE / 2)return -1;
return dp[coins.length][amount];
}
}
class Solution {
//单个数组版本
public int coinChange(int[] coins,int amount){
int n = coins.length;
int[] dp = new int[amount + 1];//dp[i]代表amount使用的最小硬币数量
Arrays.fill(dp,Integer.MAX_VALUE / 2);
dp[0] = 0;
for(int i = 0;i < n;i++){
for(int j = coins[i];j <= amount;j++){
//可以重复选择多个,因此可以从前往后进行dp,此时用于更新的数据永远是最优的
dp[j] = Math.min(dp[j],dp[j - coins[i]] + 1);
}
}
if(dp[amount] >= Integer.MAX_VALUE / 2)return -1;
return dp[amount];
}
}
记住:01背包从后往前,完全背包从前往后
2024/3/25
依然是完全背包变种
518. 零钱兑换 II
class Solution {
int[] coins;
int[][] memo;
public int change(int amount, int[] coins) {
/*
记忆化搜索方案:
对于第i个硬币,可以选或者不选,对于不选,则选择其下一个硬币。
搜索策略:
从后往前记录当前搜索需要组合成为的金额
记忆化策略,记录第i个硬币组合为金额x的方案数量
*/
memo = new int[coins.length][amount + 1];
for(int[] row:memo){
Arrays.fill(row,-1);//-1代表未访问
}
this.coins = coins;
return dfs(coins.length - 1,amount);
}
int dfs(int i,int amount){
if(i < 0){
if(amount == 0)return 1;
else return 0;
}
if(memo[i][amount] != -1)return memo[i][amount];
if(coins[i] > amount){
return memo[i][amount] = dfs(i - 1,amount);
}
return memo[i][amount] = dfs(i - 1,amount) + dfs(i,amount - coins[i]);
}
}
//dp
class Solution {
public int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
/*
dp[i]:凑齐金额i的硬币组合数量
对于每一个coin来说,若当前coin与前面金额进行组合并能凑齐当前金额,则有:
dp[i] += dp[i - coin[j]]
但对于之前的金额来说,可能存在重复的方案,如何进行去除呢?依次枚举金币即可
*/
dp[0] = 1;
//凑齐金额i的方案数量
for(int i = 0;i < coins.length;i++){
for(int j = coins[i];j <= amount;j++){
dp[j] += dp[j - coins[i]];
}
}
return dp[amount];
}
}
2024/3/26
对于>=第一个数得二分模板如下:
//左闭右闭
public int lower_bound(int[] nums,int target){
int left = 0,right = nums.length - 1;
while(left <= right){
int mid = left + (right - left) / 2;
if(nums[mid] < target){//找的是第一个>所以不用判断等于的情况
left = mid + 1;
}else{
right = mid - 1;
}
}
return left;//right + 1 也是解
}
//左闭右开
public int lower_bound2(int[] nums,int target){
int left = 0,right = nums.length;//左闭右开
while(left < right){
int mid = left + (right - left) / 2;
if(nums[mid] < target){
left = mid + 1;
}
else{
right = mid;//右开
}
}
return left;//left和right都是解
}
//左开右开
int lower_bound3(int[] nums,int target){
int left =-1;
int right = nums.length;
while (left + 1 < right){
int mid = left + (right - left) / 2;
if(nums[mid] < target){
left = mid;
}else{
right = mid;
}
}
return right;
}
/*
以上都是>=的情况
对于>的情况:可以视为 >= x + 1
对于<的情况,可以视为(>=x) - 1
对于<=的情况,可以视为(>x) - 1
*/
以上都是>=的情况
对于>的情况:可以视为 >= x + 1
对于<的情况,可以视为(>=x) - 1
对于<=的情况,可以视为(>x) - 1















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









