







1.变量类型不用声明,直接赋值。
data='Hello word!'
a=452
b=8.98
true=True
多变量赋值:a,b,c=1,'hello',True
2.控制语句后边跟冒号,空格缩进区分代码块
if value==1:
print('a')
elif value>10:
print('b')
else:
print('c')
3.元组:
只读的集合类型,初始化后,元组元素不能重新赋值
a=(1,2,3)
print(a)
print(a[0])
4.列表:
列表元素可以重新赋值,对列表元素增加列表项用append()函数
a=[1,2,3]
print(a)
a.append(4)(加在列表最后边)
5.字典:
可变容器模型,可存储任意类型的对象,键值对(Key,value)用冒号:分开,键值对之间用,号分开
mydict={'a':6.18,'b':'str','c':True}
print('A value:%.2f'% mydict['a'])
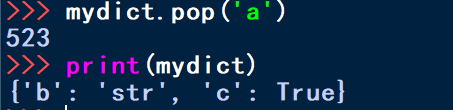
mydict['a']=523
print('A value: %d'%mydict['a'])
print('keys:%s' % mydict.key())
print('values:%s' % mydict.values())
for key in mydict:
print(mydict[key])
numpy库:

mumpy作为算数运算(矩阵运算):

Matplotlib库:
1.初始化绘图
2.设定x轴,y轴,用xlabe(),ylabel()方法设置标签
3.展示绘图结果用show()方法


散点图:

效果:

Pandas:
Series:一维数组,只允许存储相同数据类型

DataFrame:
DataFrame是可以指定行和列标签的二维数组,数据可以通过指定列名访问特定列的数据,是一个对数据进行切片的工具

数据导入:
(1)使用Numpy导入数据:
使用NumPy的loadtxt()函数导入数据,这个函数处理的数据没有文件头,所有的数据结构是一样的。

(2)使用Pandas导入数据:
要使用Pandas.read_csv()函数,函数的返回值是DataFrame.

(3)使用标准Python类库导入数据:

数据理解:
显示数据前10行

DataFrame的Shape属性可以知道数据的维度,多少行多少列

显示数据属性和类型

描述性统计:

describe()方法结果显示:
数据的分布分析:DataFrame的skew()可以计算所有数据属性的高斯分布(正态分布)偏离情况,shew()函数的结果显示数据分布是左偏还是右偏。数据接近0时,表示数据偏差非常小。

数据可视化:
(1)直方图(Histogram)也称质量分布图,一般用横轴表示数据类型,纵轴表示分布情况。

执行结果如图所示:(用到hist()函数)

密度图:一般用于呈现连续变量,类似于对直方图进行抽象,用平滑曲线来描述数据分布。

结果:

箱线图:用于显示一组数据分散情况的统计图。首先画一条中位数线,然后以下四分位数和上四分位数画一个盒子,上下各有一条横线,表示上边缘和下边缘,通过横线来显示数据的伸展状况,游离在边缘之外的点为异常值。

相关矩阵图:用来展示两个不同属性相影响的程度,如果两个属性按照相同的方向变化,说明是正向影响,反之则是负向影响。


散点矩阵图:表示因变量随自变量变化的大致趋势,

















 5758
5758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









