







Zookeeper
一 Zookeeper概述
1 什么是Zoopeeper
官方文档上这么解释zookeeper,它是一个分布式协调框架,是Apache Hadoop 的一个子项 目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
2 Zookeeper的核心概念
Zookeeper 是一个用于存储少量数据的基于内存 的数据库,主要有如下两个核心的概念:文件系统数据结构+监听通知机制。
文件系统数据结构
Zookeeper维护一个类似文件系统的数据结构:
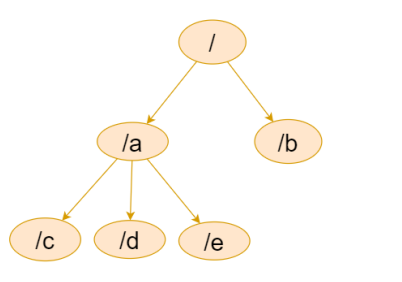
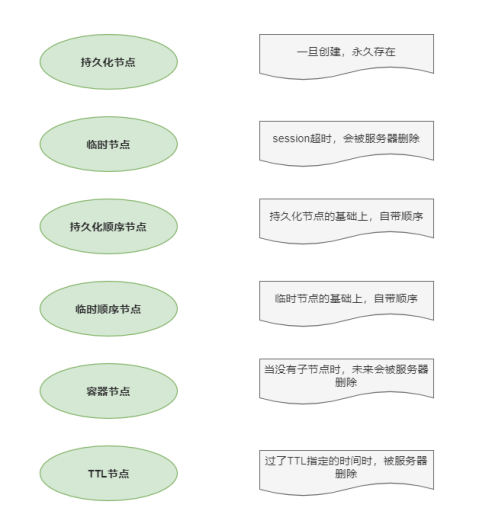
每个子目录项都被称作为 znode(目录节点),和文件系统类似,我们能够自由的增加、删除 znode,在一个znode下增加、删除子znode。 有六种类型的znode:
1、PERSISTENT持久化目录节点,客户端与zookeeper断开连接后,该节点依旧存在,只要不手动删除该节点,他将永远存在
2、PERSISTENT_SEQUENTIAL持久化顺序编号目录节点,客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL临时目录节点,客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL临时顺序编号目录节点 客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
5、Container 节点(3.5.3 版本新增,如果Container节点下面没有子节点,则Container节点 在未来会被Zookeeper自动清除,定时任务默认60s 检查一次)
6、TTL 节点( 默认禁用,只能通过系统配置 zookeeper.extendedTypesEnabled=true 开启,不稳定)
监听机制
客户端注册监听它关心的任意节点,或者目录节点及递归子目录节点
- 如果注册的是对某个节点的监听,则当这个节点被删除,或者被修改时,对应的客户端将被通知
- 如果注册的是对某个目录的监听,则当这个目录有子节点被创建,或者有子节点被删除,对应的客户端将被通知
- 如果注册的是对某个目录的递归子节点进行监听,则当这个目录下面的任意子节点有目录结构 的变化(有子节点被创建,或被删除)或者根节点有数据变化时,对应的客户端将被通知。
注意:所有的通知都是一次性的,及无论是对节点还是对目录进行的监听,一旦触发,对应的监 听即被移除。递归子节点,监听是对所有子节点的,所以,每个子节点下面的事件同样只会被触 发一次。
3 Zookeeper经典的应用场景
- 分布式配置中心
- 分布式注册中心
- 分布式锁
- 分布式队列
- 集群选举
- 分布式屏障
- 发布/订阅
二 Zookeeper实战
1 节点操作
创建zookeeper节点语法
create [‐s] [‐e] [‐c] [‐t ttl] path [data] [acl]
-s: 顺序节点
-e: 临时节点
-c: 容器节点
-t: 可以给节点添加过期时间,默认禁用,需要通过系统参数启用
(-Dzookeeper.extendedTypesEnabled=true, znode.container.checkIntervalMs : (Java system property only) New in 3.5.1: The time interval in milliseconds for each check of candidate container and ttl nodes. Default is “60000”.)
创建持久化节点:
不指定参数默认创建的是持久化节点
[zk: localhost:2181(CONNECTED) 0] create /test data1

查看节点:
[zk: localhost:2181(CONNECTED) 1] get /test

修改节点:
[zk: localhost:2181(CONNECTED) 2] set /test update1

查看节点状态信息:
[zk: localhost:2181(CONNECTED) 4] stat /test
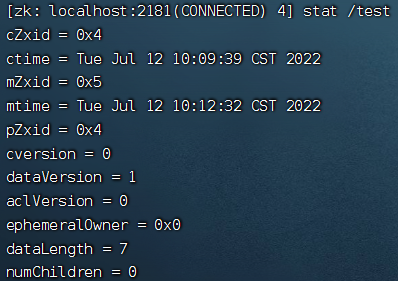
参数说明:
- cZxid:创建znode的事务ID(Zxid的值)。
- mZxid:最后修改znode的事务ID。
- pZxid:最后添加或删除子节点的事务ID(子节点列表发生变化才会发生改变)。
- ctime:znode创建时间。
- mtime:znode最近修改时间。
- dataVersion:znode的当前数据版本
- cversion:znode的子节点结果集版本(一个节点的子节点增加、删除都会影响这个 版本)。
- aclVersion:表示对此znode的acl版本。
- ephemeralOwner:znode是临时znode时,表示znode所有者的 session ID。 如果 znode不是临时znode,则该字段设置为零。
- dataLength:znode数据字段的长度。
- numChildren:znode的子znode的数量。
查看节点状态信息同时查看数据
[zk: localhost:2181(CONNECTED) 5] get -s /test
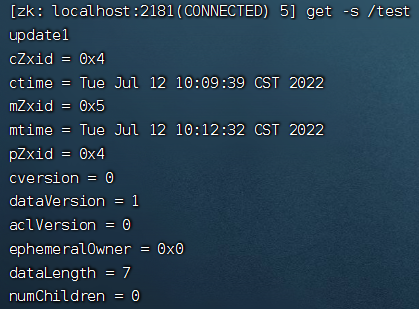
根据状态数据中的版本号有并发修改数据实现乐观锁的功能
比如: 客户端首先获取版本信息
/test 当前的数据版本是 1 , 这时客户端 用 set 命令修改数据的时候可以把版本号带上
[zk: localhost:2181(CONNECTED) 6] set -v 1 /test update2
如果在执行上面 set命令前, 有人修改了数据,zookeeper 会递增版本号, 这个时候,如果再用 以前的版本号去修改,将会导致修改失败,报如下错误。

创建子节点
zookeeper是以节点组织数据的,没有相对路径这么一说,所以,所有的节点一定是以 / 开头。
[zk: localhost:2181(CONNECTED) 9] create /test/sub0
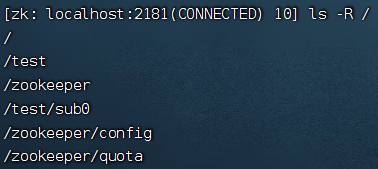
查看子节点信息
查看子节点信息,比如根节点下面的所有子节点, 加一个大写 R 可以查看递归子节点列表
ls -R /
创建临时节点
create 后跟一个 -e 创建临时节点 , 临时节点不能创建子节点
[zk: localhost:2181(CONNECTED) 11] create -e /ephemeral ephemeraldata
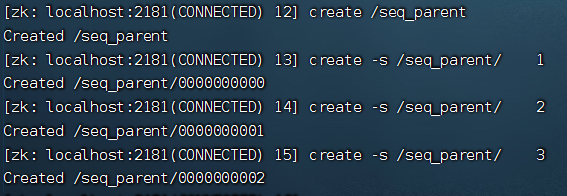
创建序号节点
[zk: localhost:2181(CONNECTED) 12] create /seq_parent #创建一个父节点
[zk: localhost:2181(CONNECTED) 13] create -s /seq_parent/ 1
[zk: localhost:2181(CONNECTED) 14] create -s /seq_parent/ 2
[zk: localhost:2181(CONNECTED) 15] create -s /seq_parent/ 3
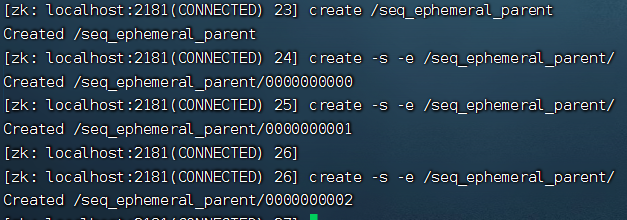
创建临时顺序节点
[zk: localhost:2181(CONNECTED) 23] create /seq_ephemeral_parent
[zk: localhost:2181(CONNECTED) 24] create -s -e /seq_ephemeral_parent/
[zk: localhost:2181(CONNECTED) 25] create -s -e /seq_ephemeral_parent/
[zk: localhost:2181(CONNECTED) 26] create -s -e /seq_ephemeral_parent/
创建容器节点
[zk: localhost:2181(CONNECTED) 27] create -c /container

容器节点主要用来容纳子节点,如果没有给其创建子节点,容器节点表现和持久化节点一样,如果给容器节点创建了子节点,后续又把子节点清空,容器节点也会被zookeeper删除。
2.事件监听机制
(1)对节点监听
针对节点的监听:一旦事件触发,对应的注册立刻被移除,所以事件监听是一次性的
get ‐w /path # 注册监听的同时获取数据
stat ‐w /path # 对节点进行监听,且获取元数据信息
get -w /test
set /test update3
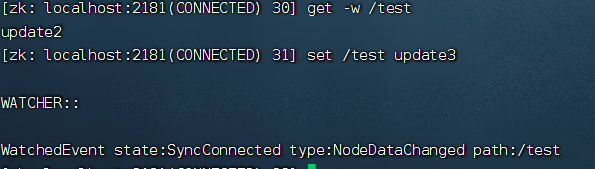
(2)针对目录的监听,如下图,目录的变化,会触发事件,且一旦触发,对应的监听也会被移除,后续对节点的创建没有触发监听事件
ls ‐w /path
[zk: localhost:2181(CONNECTED) 32] ls -w /test
[sub0]
[zk: localhost:2181(CONNECTED) 33] create /test/sub1
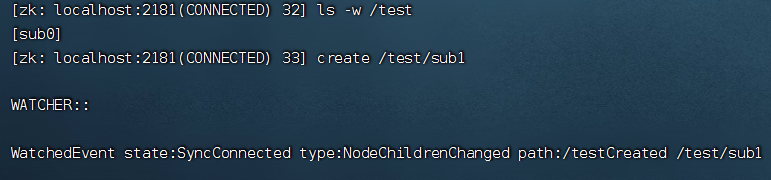
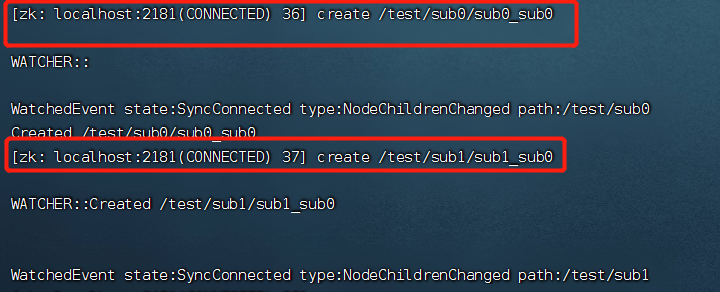
(3)针对递归子目录的监听
ls ‐R ‐w /path #‐R 区分大小写,一定用大写
如下对/test 节点进行递归监听,但是每个目录下的目录监听也是一次性的,如第一次在/test 目 录下创建节点时,触发监听事件,第二次则没有,同样,因为时递归的目录监听,所以 在/test/sub0下进行节点创建时,触发事件,但是再次创建/test/sub0/subsub1节点时,没有触发事件。
Zookeeper事件类型:
- None: 连接建立事件
- NodeCreated: 节点创建
- NodeDeleted: 节点删除
- NodeDataChanged:节点数据变化
- NodeChildrenChanged:子节点列表变化
- DataWatchRemoved:节点监听被移除
- ChildWatchRemoved:子节点监听被移除
3.Zookeeper 的 ACL 权限控制
Zookeeper 的ACL 权限控制,可以控制节点的读写操作,保证数据的安全性,Zookeeper ACL 权 限设置分为 3 部分组成,分别是:权限模式(Scheme)、授权对象(ID)、权限信息 (Permission)。最终组成一条例如“scheme🆔permission”格式的 ACL 请求信息。下面我们具体看一下这 3 部分代表什么意思:
Scheme(权限模式):用来设置 ZooKeeper 服务器进行权限验证的方式。ZooKeeper 的权限验证方式大体分为两种类型:
一种是范围验证。所谓的范围验证就是说 ZooKeeper 可以针对一个 IP 或者一段 IP 地址授予某种权限。比如我们可以让一个 IP 地址为“ip:192.168.0.110”的机器对服务器上的某个数据节 点具有写入的权限。或者也可以通过“ip:192.168.0.1/24”给一段 IP 地址的机器赋权。
另一种权限模式就是口令验证,也可以理解为用户名密码的方式。在 ZooKeeper 中这种验证方式是 Digest 认证,而 Digest 这种认证方式首先在客户端传送“username:password”这种形式的权限表示符后,ZooKeeper 服务端会对密码部分使用 SHA-1 和 BASE64 算法进行加密, 以保证安全性。
还有一种Super权限模式, Super可以认为是一种特殊的 Digest 认证。具有 Super 权限的客户端 可以对 ZooKeeper 上的任意数据节点进行任意操作。
授权对象(ID):授权对象就是说我们要把权限赋予谁,而对应于 4 种不同的权限模式来说,如果我们选择采用 IP 方式,使用的授权对象可以是一个 IP 地址或 IP 地址段;而如果使用 Digest 或 Super 方式,则对应于一个用户名。如果是 World 模式,是授权系统中所有的用户。
权限信息(Permission): 权限就是指我们可以在数据节点上执行的操作种类,如下所示:在 ZooKeeper 中已经定义好的 权限有 5 种:
数据节点(c: create):创建权限,授予权限的对象可以在数据节点下创建子节点;
数据节点(w: wirte):更新权限,授予权限的对象可以更新该数据节点;
数据节点(r: read):读取权限,授予权限的对象可以读取该节点的内容以及子节点的列表信息;
数据节点(d: delete):删除权限,授予权限的对象可以删除该数据节点的子节点;
数据节点(a: admin):管理者权限,授予权限的对象可以对该数据节点体进行 ACL 权限设置。
命令:
getAcl:获取某个节点的acl权限信息
setAcl:设置某个节点的acl权限信息
addauth: 输入认证授权信息,相当于注册用户信息,注册时输入明文密码,zk将以密文的形式存储
可以通过系统参数zookeeper.skipACL=yes进行配置,默认是no,可以配置为true, 则配置过的 ACL将不再进行权限检测
生成授权ID的两种方式:
a.代码生成ID:
public static void main(String[] args) {
String sId = DigestAuthenticationProvider.generateDigest("luoxue:luoxue");
System.out.println(sId);
}
b.在xshell 中生成
echo ‐n <user>:<password> | openssl dgst ‐binary ‐sha1 | openssl base64
[root@lx ~]# echo -n luoxue:luoxue | openssl dgst -binary -sha1 |openssl base64

设置ACL有两种方式
a.节点创建的同时设置ACL
create [-s] [-e] [-c] path [data] [acl]
[zk: localhost:2181(CONNECTED) 39] create /acl acldata digest:luoxue:GVyBkJQDkCoX8QsphqTS4ndiXpw=:cdrwa

或者setAcl设置
setAcl /acl digest:luoxue:GVyBkJQDkCoX8QsphqTS4ndiXpw=:cdrw
添加授权信息后是不能直接访问的,直接访问会报以下异常信息:

访问前需要添加授权信息
addauth digest luoxue:luoxue

b.auth 明文授权
使用之前需要先 addauth digest username:password 注册用户信息,后续可以直接用明文授权
[zk: localhost:2181(CONNECTED) 43] addauth digest luoxue1:luoxue1
[zk: localhost:2181(CONNECTED) 44] create /acl2 acl2data auth:luoxue1:luoxue1:cdwra

ip授权模式:
setAcl /node‐ip ip:192.168.109.128:cdwra
create /node‐ip data ip:192.168.109.128:cdwra
多个指定IP可以通过逗号分隔, 如 setAcl /node-ip ip:IP1:rw,ip:IP2:a
Super 超级管理员模式
这是一种特殊的Digest模式, 在Super模式下超级管理员用户可以对Zookeeper上的节点进行任何的操作。 需要在启动了上通过JVM 系统参数开启:
DigestAuthenticationProvider中定义
‐Dzookeeper.DigestAuthenticationProvider.superDigest=super:
<base64encoded(SHA1(password))
4.ZooKeeper 内存数据和持久化
Zookeeper数据的组织形式为一个类似文件系统的数据结构,而这些数据都是存储在内存中的, 所以我们可以认为,Zookeeper是一个基于内存的小型数据库.
内存中的数据:
public class DataTree {
private final ConcurrentHashMap<String, DataNode> nodes =
new ConcurrentHashMap<String, DataNode>();
private final WatchManager dataWatches = new WatchManager();
private final WatchManager childWatches = new WatchManager();
}
DataNode 是Zookeeper存储节点数据的最小单位
public class DataNode implements Record {
byte data[];
Long acl;
public StatPersisted stat;
private Set<String> children = null;
}
事务日志
针对每一次客户端的事务操作,Zookeeper都会将他们记录到事务日志中,当然,Zookeeper也会将数据变更应用到内存数据库中。我们可以在zookeeper的主配置文件zoo.cfg 中配置内存中的数据持久化目录,也就是事务日志的存储路径 dataLogDir. 如果没有配置dataLogDir(非必 填), 事务日志将存储到dataDir (必填项)目录, zookeeper提供了格式化工具可以进行数据查看事务日志数据
查看事务日志文件
cd data/version-2/
ls
查看事务日志内容
[root@lx version-2]# cd ../../lib/
java -classpath .:slf4j-api-1.7.25.jar:zookeeper-3.5.8.jar:zookeeper-jute-3.5.8.jar org.apache.zookeeper.server.LogFormatter /usr/environment/zookeeper/apache-zookeeper-3.5.8-bin/data/version-2/log.1
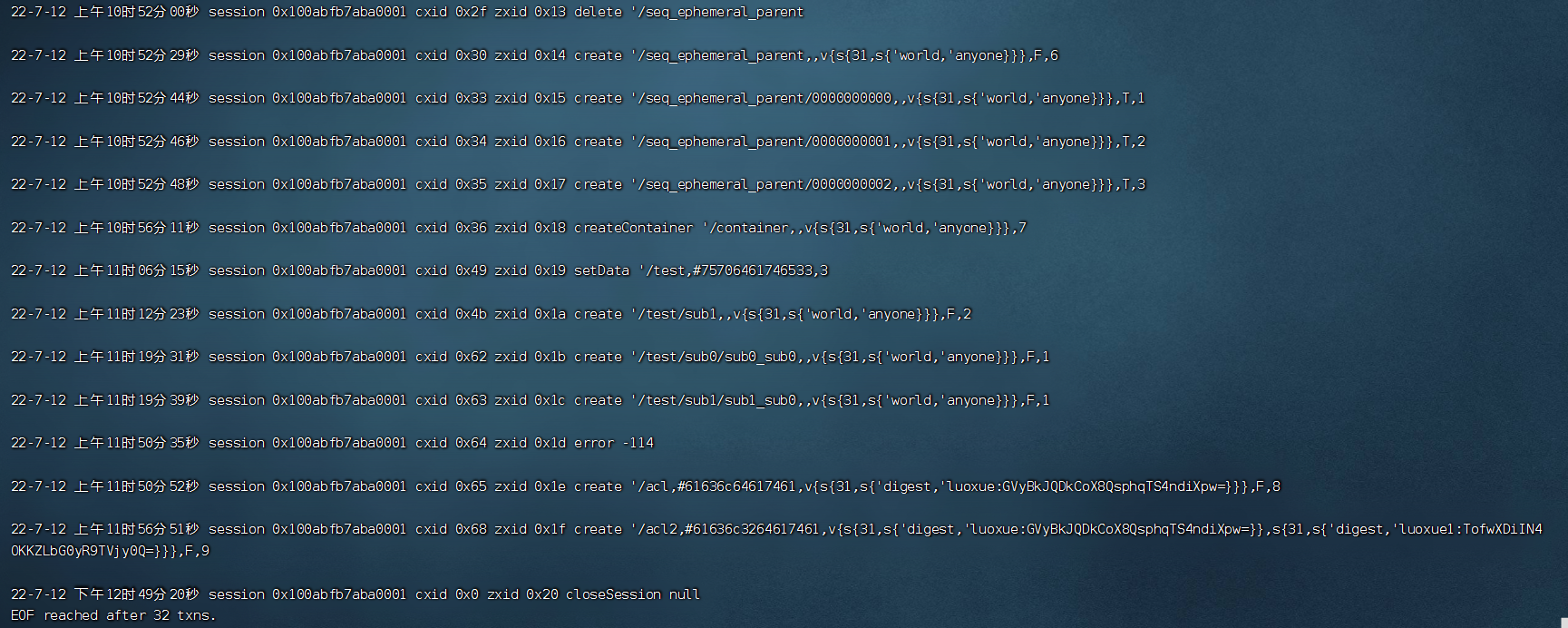
从左到右分别记录了操作时间,客户端会话ID,CXID,ZXID,操作类型,节点路径,节点数据(用 #+ascii 码表示),节点版本。
Zookeeper进行事务日志文件操作的时候会频繁进行磁盘IO操作,事务日志的不断追加写操作会触发底层磁盘IO为文件开辟新的磁盘块,即磁盘Seek。因此,为了提升磁盘IO的效率, Zookeeper在创建事务日志文件的时候就进行文件空间的预分配- 即在创建文件的时候,就向操作系统申请一块大一点的磁盘块。这个预分配的磁盘大小可以通过系统参数 zookeeper.preAllocSize 进行配置。 事务日志文件名为: log.<当时最大事务ID>,因为日志文件是顺序写入的,所以这个最大事务 ID也将是整个事务日志文件中,最小的事务ID,日志满了即进行下一次事务日志文件的创建
数据快照
数据快照用于记录Zookeeper服务器上某一时刻的全量数据,并将其写入到指定的磁盘文件中。 可以通过配置snapCount配置每间隔事务请求个数,生成快照,数据存储在dataDir 指定的目录 中
可以通过如下方式进行查看快照数据( 为了避免集群中所有机器在同一时间进行快照,实际的快照生成时机为事务数达到 [snapCount/2 + 随机数(随机数范围为1 ~ snapCount/2 )] 个数时开始快照)
java -classpath .:slf4j-api-1.7.25.jar:zookeeper-3.5.8.jar:zookeeper-jute-3.5.8.jar org.apache.zookeeper.server.LogFormatter /usr/environment/zookeeper/apache-zookeeper-3.5.8-bin/data/version-2/snapshot.0
快照事务日志文件名为: snapshot.<当时最大事务ID>,日志满了即进行下一次事务日志文件的创建.
有了事务日志,为啥还要快照数据。 快照数据主要时为了快速恢复, 事务日志文件是每次事务请求都会进行追加的操作,而快照是达到某种设定条件下的内存全量数据。所以通常快照数据是反应当时内存数据的状态。事务日志是更全面的数据,所以恢复数据的时候,可以先恢复快照数据,再通过增量恢复事务日志中的数据即可。
三 Zookeeper客户端
1 Zookeeper Java客户端
(1)步骤一:环境搭建
pom:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.8</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.3</version>
</dependency>
</dependencies>
(2)步骤二:编写创建客户端实例代码
@Slf4j
public class ZookeeperClientTest {
private static final String ZK_ADDRESS="192.168.109.200:2181";
private static final int SESSION_TIMEOUT = 5000;
private static ZooKeeper zooKeeper;
private static final String ZK_NODE="/zk‐node";
@Before
public void init() throws IOException, InterruptedException {
final CountDownLatch countDownLatch=new CountDownLatch(1);
zooKeeper = new ZooKeeper(ZK_ADDRESS,SESSION_TIMEOUT,watchedEvent -> {
if(watchedEvent.getState()==Watcher.Event.KeeperState.SyncConnected&&watchedEvent.getType()==Watcher.Event.EventType.None){
countDownLatch.countDown();
log.info("连接成功!");
}
});
log.info("连接中....");
countDownLatch.await();
}
}
ZooKeeper构造方法参数说明:
connectString:ZooKeeper服务器列表,由英文逗号分开的host:port字符串组成, 每一个都代表一台ZooKeeper机器,如, host1:port1,host2:port2,host3:port3。另外,也可以在connectString中设 置客户端连接上ZooKeeper 后的根目录,方法是在host:port字符串之后添加上这个根目录,例 如,host1:port1,host2:port2,host3:port3/zk-base,这样就指定了该客户端连 接上ZooKeeper服务器之后,所有对ZooKeeper 的操作,都会基于这个根目录。例如,客户端对/sub-node 的操作,最终创建 /zk-node/sub-node, 这个目录也叫Chroot,即客户端隔离命名空间。
sessionTimeout:会话的超时时间,是一个以“毫秒”为单位的整型值。在ZooKeeper中有会话的概念,在一个会话周期内,ZooKeeper客户端和服务器之间会通过心跳检测机制来维持会话的有效性,一旦在sessionTimeout时间内没有进行有效的心跳检测,会话就会失效.
watcher:ZooKeeper允许客户端在构造方法中传入一个接口 watcher (org.apache. zookeeper. Watcher)的实现类对象来作为默认的 Watcher事件通知处理器。当然,该参数可以设置为null 以表明不需要设置默认的 Watcher处理器。
canBeReadOnly:这是一个boolean类型的参数,用于标识当前会话是否支持“read-only(只 读)”模式。默认情况下,在ZooKeeper集群中,一个机器如果和集群中过半及以上机器失去了网络连接,那么这个机器将不再处理客户端请求(包括读写请求)。但是在某些使用场景下,当ZooKeeper服务器发生此类故障的时候,我 们 还是希望ZooKeeper服务器能够提供读服务(当然写服务肯定无法提供)—— 这就是 ZooKeeper的“read-only”模式。
sessionId和 sessionPasswd:分别代表会话ID和会话秘钥。这两个参数能够唯一确定一个会话,同时客户端使用这两个参数可以实现客户端会话复用,从而达到恢复会话的效果。具体使用方法是,第一次连接上ZooKeeper服务器时,通过调用ZooKeeper对象实例的以下两个接口,即可获得当前会话的ID和秘钥: long getSessionId(); byte[]getSessionPasswd( ); 荻取到这两个参数值之后,就可以在下次创建ZooKeeper对象实例的时候传入构造方法了
同步创建节点
@Test
public void createNode() throws KeeperException, InterruptedException {
//参数说明
//第一个参数是path路径
//第二个参数是data
//第三个数据的acl权限
//第四个参数是节点类型
String path = zooKeeper.create(ZK_NODE, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
log.debug("create path:{}",path);
}
异步创建节点
@Test
public void createNodeAsync() throws InterruptedException {
//参数说明:
//第一个参数是path路径
//第二个参数是data
//第三个数据的acl权限
//第四个参数是节点类型
//第五个参数是回调接口 rc:响应码 path:节点路径 ctx:上下文 name:节点名称
zooKeeper.create(ZK_NODE_ASYNC, "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT,(rc, path, ctx, name)->{
Thread thread = Thread.currentThread();
log.debug("currentThread:{},rc:{},path:{},ctx:{},name:{}",thread.getName(),rc,path,ctx,name);
},"centext");
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
}
修改节点数据
@Test
public void updateNode() throws KeeperException, InterruptedException {
Stat stat = new Stat();
byte[] data = zooKeeper.getData(ZK_NODE, false, stat);
log.debug("修改前: {}",new String(data));
//通过version实现乐观锁 期间有其它线程也修改了数据 则更新不会成功
zooKeeper.setData(ZK_NODE, "changed!".getBytes(), stat.getVersion());
byte[] dataAfter = zooKeeper.getData(ZK_NODE, false, stat);
log.debug("修改后: {}",new String(dataAfter));
}
2 Curator
什么是Curator
Curator 是一套由netflix 公司开源的,Java 语言编程的 ZooKeeper 客户端框架,Curator项目是现在ZooKeeper 客户端中使用最多,对ZooKeeper 版本支持最好的第三方客户端,并推荐使 用,Curator 把我们平时常用的很多 ZooKeeper 服务开发功能做了封装,例如 Leader 选举、 分布式计数器、分布式锁。这就减少了技术人员在使用 ZooKeeper 时的大部分底层细节开发工作。在会话重新连接、Watch 反复注册、多种异常处理等使用场景中,用原生的 ZooKeeper 处理比较复杂。而在使用 Curator 时,由于其对这些功能都做了高度的封装,使用起来更加简单,不但减少了开发时间,而且增强了程序的可靠性。
Curator实战
这里我们以 Maven 工程为例,首先要引入Curator 框架相关的开发包,这里为了方便测试引入 了junit ,lombok,由于Zookeeper本身以来了 log4j 日志框架,所以这里可以创建对应的 log4j配置文件后直接使用。 如下面的代码所示,我们通过将 Curator 相关的引用包配置到 Maven 工程的 pom 文件中,将 Curaotr 框架引用到工程项目里,在配置文件中分别引用了两 个 Curator 相关的包,第一个是 curator-framework 包,该包是对 ZooKeeper 底层 API 的一 些封装。另一个是 curator-recipes 包,该包封装了一些 ZooKeeper 服务的高级特性,如: Cache 事件监听、选举、分布式锁、分布式 Barrier。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-x-discovery</artifactId>
<version>5.0.0</version>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
1.会话创建
静态工厂方式创建
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3)
CuratorFramework client = CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy);
client.start();
fluent 风格创建
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("192.168.128.129:2181")
.sessionTimeoutMs(5000) // 会话超时时间
.connectionTimeoutMs(5000) // 连接超时时间
.retryPolicy(retryPolicy)
.namespace("base") // 包含隔离名称
.build();
client.start();
这段代码的编码风格采用了流式方式,最核心的类是 CuratorFramework 类,该类的作用是定 义一个 ZooKeeper 客户端对象,并在之后的上下文中使用。在定义 CuratorFramework 对象 实例的时候,我们使用了 CuratorFrameworkFactory 工厂方法,并指定了 connectionString 服务器地址列表、retryPolicy 重试策略 、sessionTimeoutMs 会话超时时间、 connectionTimeoutMs 会话创建超时时间。下面我们分别对这几个参数进行讲解:
connectionString:服务器地址列表,在指定服务器地址列表的时候可以是一个地址,也可以 是多个地址。如果是多个地址,那么每个服务器地址列表用逗号分隔, 如 host1:port1,host2:port2,host3;port3 。
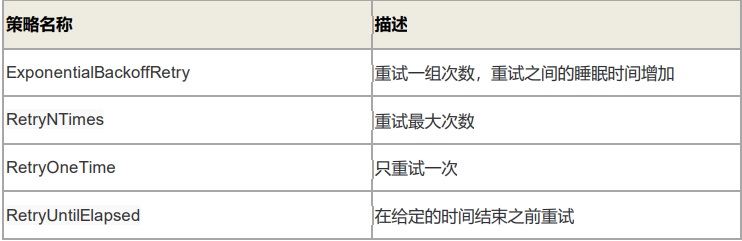
retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接 ZooKeeper 服务端。而 Curator 提供了 一次重试、多次重试等不同种类的实现方式。在 Curator 内部,可以通过判断服务器返回的keeperException 的状态代码来判断是否进行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR 表示系统或服务端错误。
超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。sessionTimeoutMs 作用在服务端,而 connectionTimeoutMs 作用在客户端
工具类编写
@Slf4j
public class ZookeeperCuratorTest {
private static final String CONNECT_STR = "192.168.109.200:2181";
private static final int sessionTimeoutMs = 60*1000;
private static final int connectionTimeoutMs = 5000;
private static CuratorFramework curatorFramework;
@Before
public void init() {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(5000, 30);
curatorFramework = CuratorFrameworkFactory.builder().connectString(getConnectStr())
.retryPolicy(retryPolicy)
.sessionTimeoutMs(sessionTimeoutMs)
.connectionTimeoutMs(connectionTimeoutMs)
.canBeReadOnly(true)
.build();
curatorFramework.getConnectionStateListenable().addListener((client, newState) -> {
if (newState == ConnectionState.CONNECTED) {
log.info("连接成功!");
}
});
log.info("连接中......");
curatorFramework.start();
}
public static CuratorFramework getCuratorFramework() {
return curatorFramework;
}
@After
public void test(){
try {
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
protected String getConnectStr(){
return CONNECT_STR;
}
}
创建节点
@Test
public void createNode() throws Exception {
//String path = curatorFramework.create().forPath("/curator‐node");
curatorFramework.create().withMode(CreateMode.PERSISTENT).forPath("/curator‐node","some‐data".getBytes());
log.debug("curator create node :{} successfully.",path);
}
在 Curator 中,可以使用 create 函数创建数据节点,并通过 withMode 函数指定节点类型 (持久化节点,临时节点,顺序节点,临时顺序节点,持久化顺序节点等),默认是持久化节点,之后调用 forPath 函数来指定节点的路径和数据信息。
创建多级节点
@Test
public void createNodeWithParent() throws Exception {
String pathWithParent="/node‐parent/sub‐node‐1";
String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent);
log.debug("curator create node :{} successfully.",path);
}
获取数据
@Test
public void getNodeData() throws Exception {
byte[] bytes = curatorFramework.getData().forPath("/curator‐node");
log.debug("get data from node :{} successfully.",new String(bytes));
}
更新节点
@Test
public void updateNode() throws Exception {
curatorFramework.setData().forPath("/curator‐node","changed!".getBytes());
byte[] bytes = curatorFramework.getData().forPath("/curator‐node");
log.debug("get data from node /curator‐node :{} successfully.",new String(bytes));
}
删除节点
@Test
public void deleteNode() throws Exception {
String pathWithParent="/node‐parent";
curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);
}
guaranteed:该函数的功能如字面意思一样,主要起到一个保障删除成功的作用,其底层工作方式是:只要该客户端的会话有效,就会在后台持续发起删除请求,直到该数据节点在 ZooKeeper 服务端被删除。 deletingChildrenIfNeeded:指定了该函数后,系统在删除该数据节点的时候会以递归的方式 直接删除其子节点,以及子节点的子节点。
异步接口
Curator 引入了BackgroundCallback 接口,用来处理服务器端返回来的信息,这个处理过程是在异步线程中调用,默认在 EventThread 中调用,也可以自定义线程池。
import org.apache.curator.framework.CuratorFramework;
/**
* Functor for an async background operation
*/
public interface BackgroundCallback
{
/**
* Called when the async background operation completes
*
* @param client the client
* @param event operation result details
* @throws Exception errors
*/
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception;
}
如上接口,主要参数为 client 客户端, 和服务端事件event,BackgroundCallback异步处理默认在EventThread中执行
@Test
public void getDataAsync() throws Exception {
curatorFramework.getData().inBackground((item1,item2)->{
log.debug(" background: {}", new String(item2.getData()));
}).forPath("/curator‐node");
log.debug("do other things");
}
指定线程池
@Test
public void getDataWithPool() throws Exception {
ExecutorService executorService = Executors.newSingleThreadExecutor();
curatorFramework.getData().inBackground((item1,item2)->{
log.debug(" background: {}", new String(item2.getData()));
},executorService).forPath("/curator‐node");
log.debug("do other things");
}
Curator监听器
import org.apache.curator.framework.CuratorFramework;
/**
* Receives notifications about errors and background events
*/
public interface CuratorListener
{
/**
* Called when a background task has completed or a watch has triggered
*
* @param client client
* @param event the event
* @throws Exception any errors
*/
public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception;
}
针对 background 通知和错误通知。使用此监听器之后,调用inBackground 方法会异步获得监听
Curator Caches
Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一个本地缓存视图与远程 Zookeeper 视图的对比过程。Cache 提供了反复注册的功能。Cache 分 为两类注册类型:节点监听和子节点监听。
节点监听:NodeCache
节点数据更新,监听就会感知到,调用回调方法。
@Test
public void testNodeCacheTest() throws Exception {
createIfNeed(NODE_CACHE);
NodeCache nodeCache = new NodeCache(curatorFramework, NODE_CACHE);
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
log.debug("{} path nodeChanged: ",NODE_CACHE);
printNodeData();
}
});
nodeCache.start();
}
public void printNodeData() throws Exception {
byte[] bytes = curatorFramework.getData().forPath(NODE_CACHE);
log.debug("data: {}",new String(bytes));
}
}
子节点监听:path cache
PathChildrenCache 会对子节点进行监听,但是不会对二级子节点进行监听
对设置路径的下的一级子节点进行监听
@Test
public void testPathCache() throws Exception {
createIfNeed(PATH);
PathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, PATH, true);
pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {
@Override
public void childEvent(CuratorFramework curatorFramework, PathChildrenCacheEvent pathChildrenCacheEvent) throws Exception {
log.debug("event: {}", pathChildrenCacheEvent);
}
});
// 如果设置为true则在首次启动时就会缓存节点内容到Cache中
pathChildrenCache.start(true);
}
}
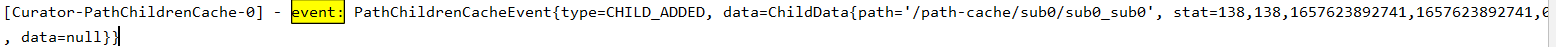
路径下所有节点监听:tree cache:
TreeCache 使用一个内部类TreeNode来维护这个一个树结构。并将这个树结构与ZK节点进行 了映射。所以TreeCache 可以监听当前节点下所有节点的事件。
@Test
public void testTreeCache() throws Exception {
createIfNeed(TREE_CACHE);
TreeCache treeCache = new TreeCache(curatorFramework, TREE_CACHE);
treeCache.getListenable().addListener(new TreeCacheListener(){
@Override
public void childEvent(CuratorFramework curatorFramework, TreeCacheEvent treeCacheEvent) throws Exception {
log.info(" tree cache: {}",treeCacheEvent);
}
});
treeCache.start();
}
四 集群模式
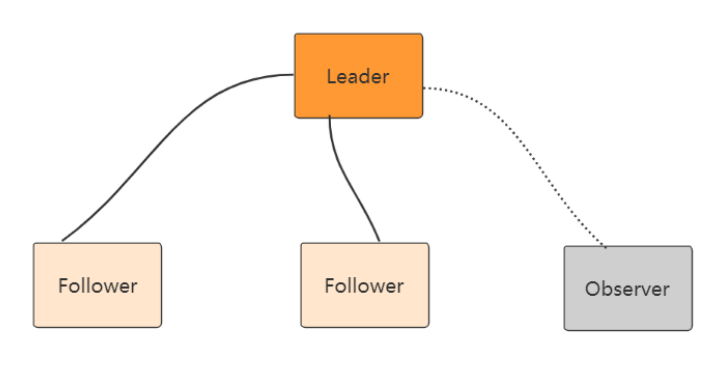
Zookeeper 集群模式一共有三种类型的角色
Leader: 处理所有的事务请求(写请求),可以处理读请求,集群中只能有一个Leader。
Follower:只能处理读请求,同时作为 Leader的候选节点,即如果Leader宕机,Follower节点 要参与到新的Leader选举中,有可能成为新的Leader节点。
Observer:只能处理读请求。不能参与选举
集群搭建
(1)创建数据目录
[root@lx clusterData]# mkdir zookeeper1 zookeeper2 zookeeper3 zookeeper4
(2)创建myid文件
[root@lx clusterData]# vim zookeeper1/myid
1
[root@lx clusterData]# vim zookeeper2/myid
2
[root@lx clusterData]# vim zookeeper3/myid
3
[root@lx clusterData]# vim zookeeper4/myid
4
(3)编写配置文件
先复制一份原始文件并重新命名
cp zoo_sample.cfg zoo_1.cfg
修改配置文件内容
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/environment/zookeeper/apache-zookeeper-3.5.8-bin/clusterData/zookeeper1 #数据文件目录
# the port at which the clients will connect
clientPort=2181
server.1=127.0.0.1:2001:3001:participant #participant可写可不写 默认就是participant
server.2=127.0.0.1:2002:3002:participant
server.3=127.0.0.1:2003:3003:participant
server.4=127.0.0.1:2004:3004:observer
(4)复制zoo_1.cfg 分别命名为zoo_2.cfg、zoo_3.cfg、zoo_4.cfg
[root@lx conf]# cp zoo_1.cfg zoo2.cfg
[root@lx conf]# cp zoo_1.cfg zoo3.cfg
[root@lx conf]# cp zoo_1.cfg zoo4.cfg
(5)修改数据目录和客户端端口号
[root@lx conf]# vim zoo_2.cfg
[root@lx conf]# vim zoo_3.cfg
[root@lx conf]# vim zoo_4.cfg
(6)启动四个节点
[root@lx bin]# ./zkServer.sh start ../conf/zoo_1.cfg
[root@lx bin]# ./zkServer.sh start ../conf/zoo_2.cfg
[root@lx bin]# ./zkServer.sh start ../conf/zoo_3.cfg
[root@lx bin]# ./zkServer.sh start ../conf/zoo_4.cfg
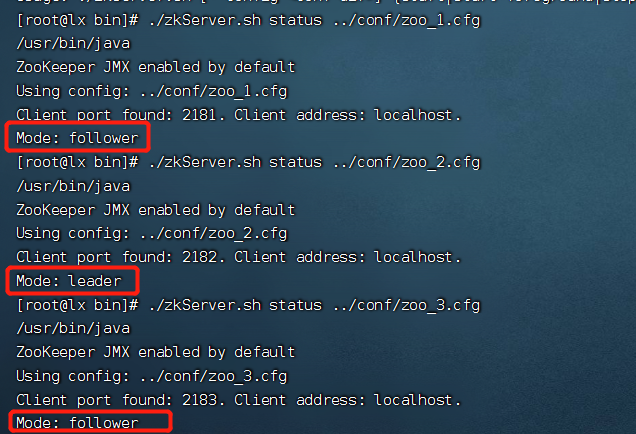
(7)查看集群状态
[root@lx bin]# ./zkServer.sh status ../conf/zoo_1.cfg
[root@lx bin]# ./zkServer.sh status ../conf/zoo_2.cfg
[root@lx bin]# ./zkServer.sh status ../conf/zoo_3.cfg
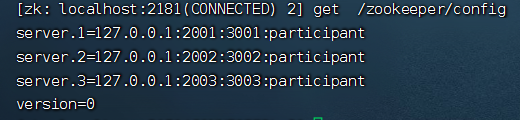
(8)通过/zookeeper/config 节点数据来查看集群配置
get /zookeeper/config
配置文件参数说明:
tickTime:用于配置Zookeeper中最小时间单位的长度,很多运行时的时间间隔都是 使用tickTime的倍数来表示的
initLimit:该参数用于配置Leader服务器等待Follower启动,并完成数据同步的时间。Follower服务器在启动过程中,会与Leader建立连接并完成数据的同步,从而确定自己对外提供服务的起始状态。Leader服务器允许Follower在initLimit 时间内完成这个工作。
syncLimit:Leader 与Follower心跳检测的最大延时时间
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将 写数据的日志文件也保存在这个目录里。
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
server.A=B:C:D:E 其中 A 是一个数字,表示这个是第几号服务器;B 是这个服 务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新 的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配 置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给 它们分配不同的端口号。如果需要通过添加不参与集群选举以及事务请求的过半机制的 Observer节点,可以在E的位置,添加observer标识。
五 Zookeeper使用场景
1 锁场景
通过Zookeeper的节点特性,我们可以实现分布式锁,非公平锁/公平锁/共享锁
加锁原理
1.Zookeeper分布式-非公平锁原理
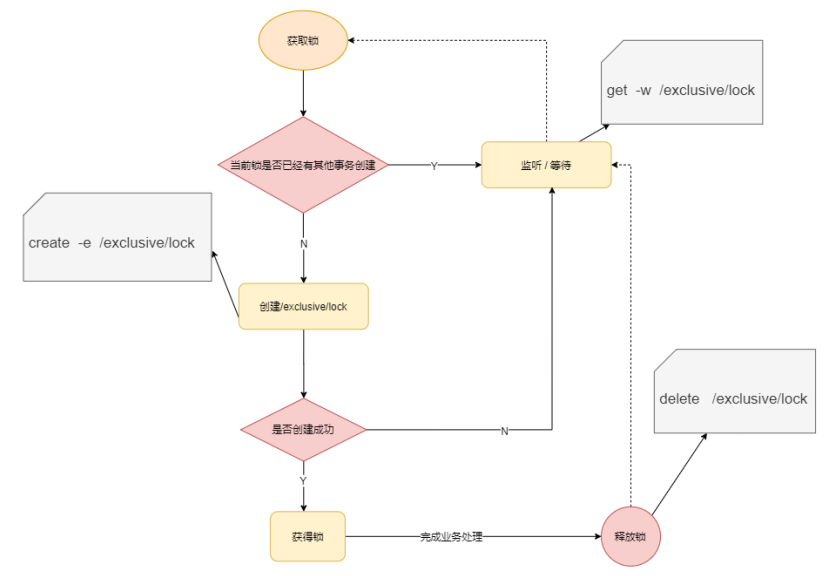
如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知所有的连接,所有的连接同时收到事件,再次并发竞争,这就是羊群效应。这种加锁方式是非公平锁的具体实现。
2.Zookeeper分布式锁-公平锁原理
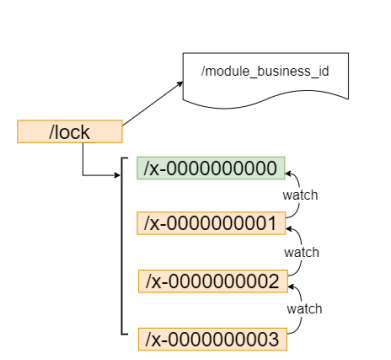
1.请求进来,直接在/lock节点下创建一个临时顺序节点
2.判断自己是否在/lock节点下最小的节点
a.如果是最小的节点,获得锁
b.如果不是,监听前一个节点
3.获得锁的请求处理完业务之后,立即释放锁(删除当前节点),然后后边的节点会收到通知,继续第二步的判断。
如上借助于临时顺序节点,可以避免同时多个节点的并发竞争锁,缓解了服务端压力。这种实现方式所有加锁请求都进行排队加锁,是公平锁的具体实现。
3.Zookeeper 分布式锁-共享锁原理
前面这两种加锁方式有一个共同的特质,就是都是互斥锁,同一时间只能有一个请求占用,如果是大量的并发上来,性能是会急剧下降的,所有的请求都得加锁,那是不是真的所有的请求都需要加锁呢?答案是否定的,比如如果数据没有进行任何修改的话,是不需要加锁的,但是如果读数据的请求还没读完,这个时候来了一个写请求,怎么办呢?有人已经在读数据了,这个时候是不能写数据的,不然数据就不正确了。直到前面读锁全部释放掉以后,写请求才能执行,所以需要给这个读请求加一个标识(读锁),让写请求知道,这个时候是不能修改数据的。不然数据就 不一致了。如果已经有人在写数据了,再来一个请求写数据,也是不允许的,这样也会导致数据的不一致,所以所有的写请求,都需要加一个写锁,是为了避免同时对共享数据进行写操作。
分下以下场景:
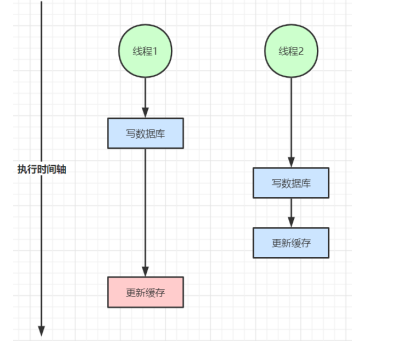
1、读写不一致
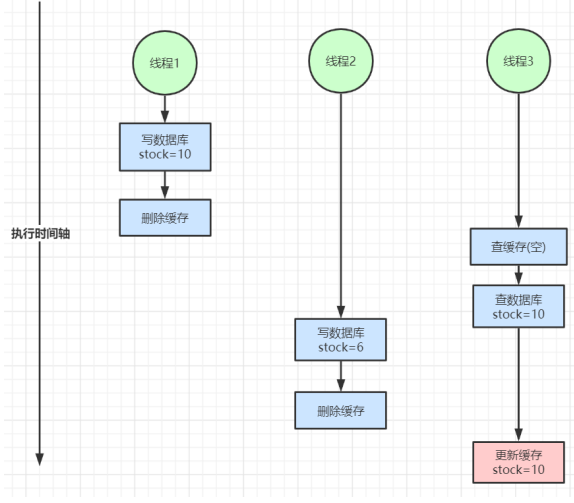
2、双写不一致
此时缓存和数据库的数据都是不一致的。可以使用Zookeeper实现共享锁
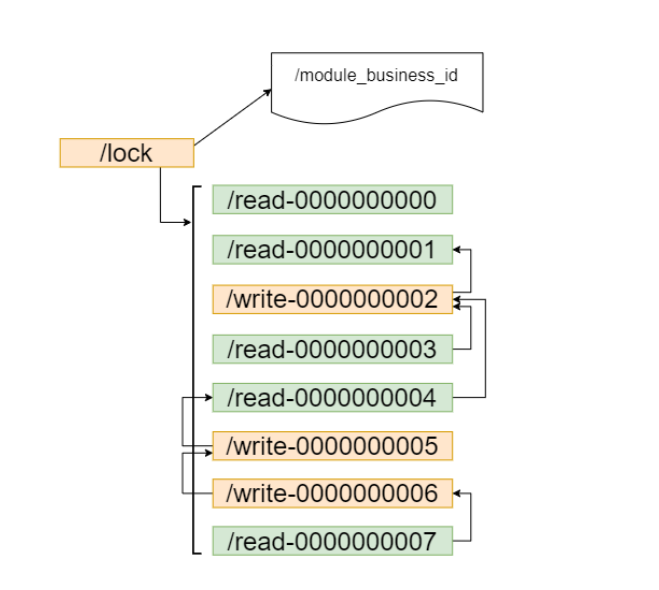
1.read请求,如果前边的节点都是读锁,直接获取锁,如果read请求前面有写请求,则该读请求阻塞等待获取锁,需要对前面的最近的写节点进行监听。
2.write请求,只需要对前面的节点进行监听,和非公平锁的原理一样
Curator分布式锁实现
1.不使用分布式锁做扣减库存业务
这里模拟网络延迟,从数据库中查询库存信息后,延迟0.5s扣库存
@PostMapping("/stock/deduct")
public Object reduceStock(Integer id) throws Exception {
try {
orderService.reduceStock(id);
} catch (Exception e) {
if (e instanceof RuntimeException) {
throw e;
}
}finally {
}
return "ok:" + port;
}
开启两个服务本地配置nginx代理两个服务进行扣减库存
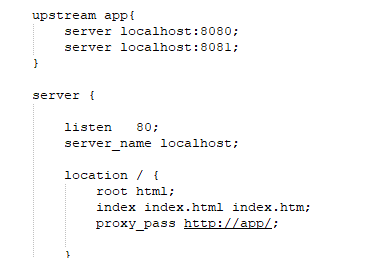
使用jmter模拟10个线程扣库存数据库结果如下 出现超卖问题

2.添加zookeeper的分布式公平锁
@PostMapping("/stock/deduct")
public Object reduceStock(Integer id) throws Exception {
InterProcessMutex interProcessMutex = new InterProcessMutex(curatorFramework, "/product_" + id);
try {
// ...
interProcessMutex.acquire();
orderService.reduceStock(id);
} catch (Exception e) {
if (e instanceof RuntimeException) {
throw e;
}
}finally {
interProcessMutex.release();
}
return "ok:" + port;
}
重新使用jmter模拟10个线程减库存,查看数据库结果

源码分析:
加锁主逻辑代码:
private boolean internalLock(long time, TimeUnit unit) throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn't necessary
*/
Thread currentThread = Thread.currentThread();
//从缓存中获取
LockData lockData = threadData.get(currentThread);
//表示可重入
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
//加锁
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if ( lockPath != null )
{
//加锁成功 存放数据 k为线程 v为节点路径
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
加锁具体实现:attemptLock
attemptLock是具体的加锁方法
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception
{
final long startMillis = System.currentTimeMillis();
final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
int retryCount = 0;
String ourPath = null;
boolean hasTheLock = false;
boolean isDone = false;
while ( !isDone )
{
isDone = true;
try
{
// 调用driver创建锁:创建一个容器节点,并添加临时顺序子节点
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
// 查询出临时顺序节点的最小子节点
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}
catch ( KeeperException.NoNodeException e )
{
// gets thrown by StandardLockInternalsDriver when it can't find the lock node
// this can happen when the session expires, etc. So, if the retry allows, just try it all again
if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) )
{
isDone = false;
}
else
{
throw e;
}
}
}
if ( hasTheLock )
{
return ourPath;
}
return null;
}
//创建容器父节点和临时顺序子节点(保证公平性) 当子节点不存在的时候会自动清理
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception
{
String ourPath;
if ( lockNodeBytes != null )
{
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path, lockNodeBytes);
}
else
{
ourPath = client.create().creatingParentContainersIfNeeded().withProtection().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath(path);
}
return ourPath;
}
//查询临时顺序节点最小的节点
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try
{
if ( revocable.get() != null )
{
// 获取数据并添加监听(感知是否锁被释放),这个监听会唤醒synchronized中等待获取锁的线程
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock )
{
// 顺序获取子节点
List<String> children = getSortedChildren();
// 截取子节点序号
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 找出序号最小的子节点(具体实现思路是判断最小节点的索引号位置是不是小于1)
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
// 已经找到最小节点并获取到了锁
if ( predicateResults.getsTheLock() )
{
haveTheLock = true;
}
// 如果没有获取到锁,会返回第二小的节点数据的路径,下面准备去监听这个路径
else
{
// 拼接全路径,准备添加监听
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this)
{
try
{
// use getData() instead of exists() to avoid leaving unneeded watchers which is a type of resource leak
// 获取数据并添加监听
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
// 如果使用的是有超时时间的acquire(time, TimeUnit)方法
if ( millisToWait != null )
{
// 判断已经执行的时间 - 要等待的时间的差值
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 )
{
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}
else
// 如果没有添加超时时间,则一直等待
{
wait();
}
}
catch ( KeeperException.NoNodeException e )
{
// it has been deleted (i.e. lock released). Try to acquire again
}
}
}
}
}
catch ( Exception e )
{
ThreadUtils.checkInterrupted(e);
doDelete = true;
throw e;
}
finally
{
if ( doDelete )
{
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
@Override
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
{
// 获取到子节点中第一次出现sequenceNodeName的索引位置
int ourIndex = children.indexOf(sequenceNodeName);
validateOurIndex(sequenceNodeName, ourIndex);
// 如果这个索引位置小于1,则是0,即是否为第一个元素
boolean getsTheLock = ourIndex < maxLeases;
// 如果是第一个元素,pathToWatch 设置为null,即不需要加锁了;否则,设置下一次自节点去加锁
String pathToWatch = getsTheLock ? null : children.get(ourIndex - maxLeases);
return new PredicateResults(pathToWatch, getsTheLock);
}
// ============== 获取数据并添加监听(感知是否锁被释放),这个监听会唤醒synchronized中等待获取锁的线程 =====
private final Watcher watcher = new Watcher()
{
@Override
public void process(WatchedEvent event)
{
client.postSafeNotify(LockInternals.this);
}
};
default CompletableFuture<Void> postSafeNotify(Object monitorHolder)
{
return runSafe(() -> {
synchronized(monitorHolder) {
monitorHolder.notifyAll();
}
});
}
3.使用Zookeeper的共享锁
InterProcessReadWriteLock readWriteLock = new InterProcessReadWriteLock(curatorFramework, "/product_" + id);
readWriteLock.readLock();
readWriteLock.writeLock();
在初始化的时候。curator就已经将读锁和写锁进行了初始化。而我们真正在使用的时候也就是直接使用。
public InterProcessReadWriteLock(CuratorFramework client, String basePath)
{
this(client, basePath, null);
}
public InterProcessReadWriteLock(CuratorFramework client, String basePath, byte[] lockData)
{
lockData = (lockData == null) ? null : Arrays.copyOf(lockData, lockData.length);
//初始化写锁
writeMutex = new InternalInterProcessMutex
(
client,
basePath,
WRITE_LOCK_NAME,
lockData,
1, //注意 写锁这里是1
new SortingLockInternalsDriver()
{
@Override
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
{
return super.getsTheLock(client, children, sequenceNodeName, maxLeases);
}
}
);
//初始化读锁
readMutex = new InternalInterProcessMutex
(
client,
basePath,
READ_LOCK_NAME,
lockData,
Integer.MAX_VALUE, //读锁这里是整型最大值
new SortingLockInternalsDriver()
{
@Override
public PredicateResults getsTheLock(CuratorFramework client, List<String> children, String sequenceNodeName, int maxLeases) throws Exception
{
return readLockPredicate(children, sequenceNodeName);
}
}
);
}
写锁的获取锁逻辑和公平锁一样,我们看下读锁的获取锁的逻辑readLockPredicate
private PredicateResults readLockPredicate(List<String> children, String sequenceNodeName) throws Exception
{
// 如果写锁已经获取到了锁,直接返回
if ( writeMutex.isOwnedByCurrentThread() )
{
return new PredicateResults(null, true);
}
int index = 0;
int firstWriteIndex = Integer.MAX_VALUE;
int ourIndex = -1;
// 遍历所有的子节点
for ( String node : children )
{ // 如果子节点中存在write节点
if ( node.contains(WRITE_LOCK_NAME) )
{ // 记录写锁的位置,此时index是当前遍历node的索引位置(找到离自己最新的写锁位置)
firstWriteIndex = Math.min(index, firstWriteIndex);
} // 找到当前读锁节点的名称,并记录其索引位置
else if ( node.startsWith(sequenceNodeName) )
{
ourIndex = index;
break;
}
++index;
}
StandardLockInternalsDriver.validateOurIndex(sequenceNodeName, ourIndex);
// 判断当前读锁索引位置是否小于第一个写锁的索引位置,从而决定是否获取到了锁
boolean getsTheLock = (ourIndex < firstWriteIndex);
// 如果小于,说明写锁在该读锁的后面,不用加锁,因为此时是读请求
// 如果不小于,得到第一个写锁的路径,然后添加监听。因为要等待这次写锁释放之后,再进行读取
String pathToWatch = getsTheLock ? null : children.get(firstWriteIndex);
return new PredicateResults(pathToWatch, getsTheLock);
}
Redis分布式锁和Zk分布式锁的对比
Redis中不管是使用主从、哨兵还是cluster集群,从节点都需要从主节点上去定时的拉取数据。即表明主从节点上的数据有可能不同步,如果我们使用Redis实现分布式锁,就很有可能带来一个问题:setnx设置的值刚保存到主节点上,还没来得及同步到从节点上,主节点却挂了。这时候如果选举出新的主节点,这个锁就会丢失。从而导致其他请求竞争到锁资源,导致分布式锁失效。
与Redis不同的是,ZK使用的并不是主从模式,而是leader和follower模式。ZK中判断一个数据是否保存成功,并不是单单的判断该数据是否已经写到了leader节点上,而是需要遵从过半原则,只有超过半数的机器上都保存了这个数据,才会认为数据是保存成功的。这样,即使leader节点挂掉了,其他的follower节点中仍然保存有新的值。未拥有最新数据的follower节点此时会从新选举出的leader节点中同步数据。
所以说,ZK的可靠性要强于Redis,但是Redis效率要高于ZK,因为Redis只写一台机器。
2 Leader选举
这里的选举不是对Zookeeper集群的leader选举,而是在微服务集群中,比如缓存预热场景,我们只选择一台服务器进行缓存预热即可,而不需要每个节点都进行一遍预热的操作。
代码
public class LeaderSelectorDemo {
private static final String CONNECT_STR="192.168.122.111:2181";
private static RetryPolicy retryPolicy=new ExponentialBackoffRetry( 5*1000, 10 );
private static CuratorFramework curatorFramework;
private static CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws InterruptedException {
String appName = System.getProperty("appName");
CuratorFramework curatorFramework = CuratorFrameworkFactory.newClient(CONNECT_STR, retryPolicy);
LeaderSelectorDemo.curatorFramework = curatorFramework;
curatorFramework.start();
LeaderSelectorListener listener = new LeaderSelectorListenerAdapter()
{
public void takeLeadership(CuratorFramework client) throws Exception
{
System.out.println(" I' m leader now . i'm , "+appName);
TimeUnit.SECONDS.sleep(15);
}
};
LeaderSelector selector = new LeaderSelector(curatorFramework, "/cachePreHeat_leader", listener);
selector.autoRequeue(); // not required, but this is behavior that you will probably expect
selector.start();
countDownLatch.await();
}
}
启动三个服务:每个服务给自己起一个名字 Appx
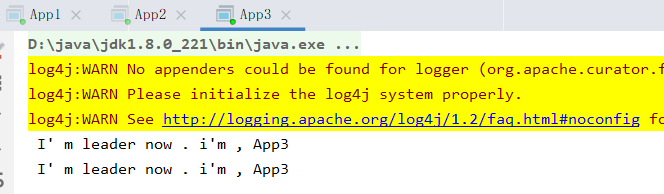

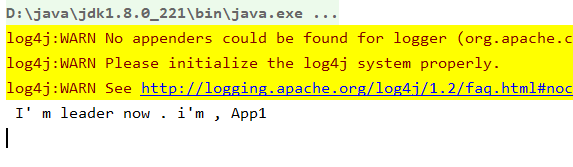
从结果来看,每过15s都会进行一次重新选举。
3 注册中心
场景分析
1.在分布式服务体系结构比较简单的场景下,我们的服务可能是这样的
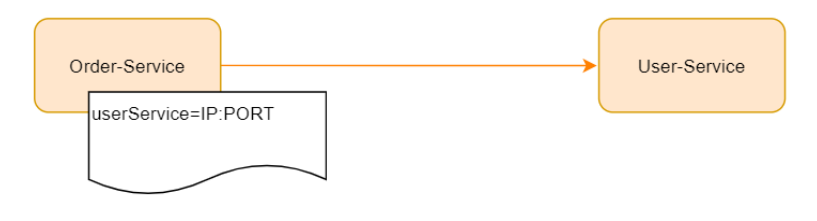
现在 Order-Service 需要调用外部服务的 User-Service ,对于外部的服务依赖,我们直接配置在 我们的服务配置文件中,在服务调用关系比较简单的场景,是完全OK的。随着服务的扩张, User-Service 可能需要进行集群部署,如下:
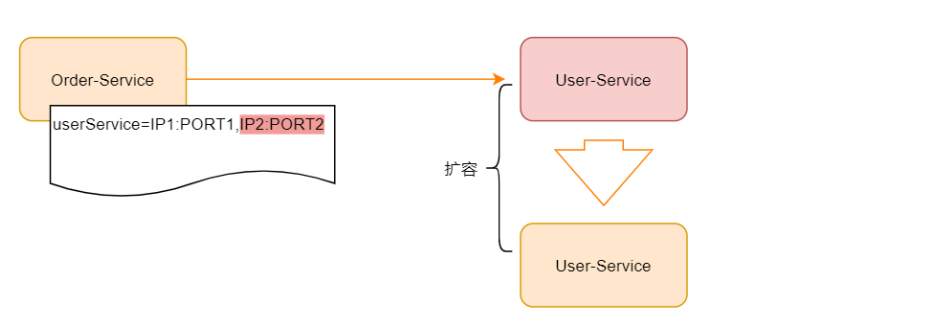
如果系统的调用不是很复杂,可以通过配置管理,然后实现一个简单的客户端负载均衡也是OK 的,但是随着业务的发展,服务模块进行更加细粒度的划分,业务也变得更加复杂,再使用简单 的配置文件管理,将变得难以维护。当然我们可以再前面加一个服务代理,比如nginx做反向代 理, 如下
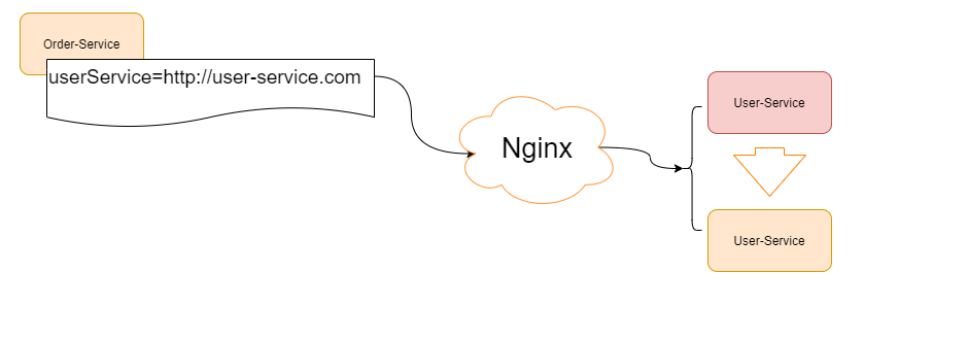
如果我们是如下场景呢?
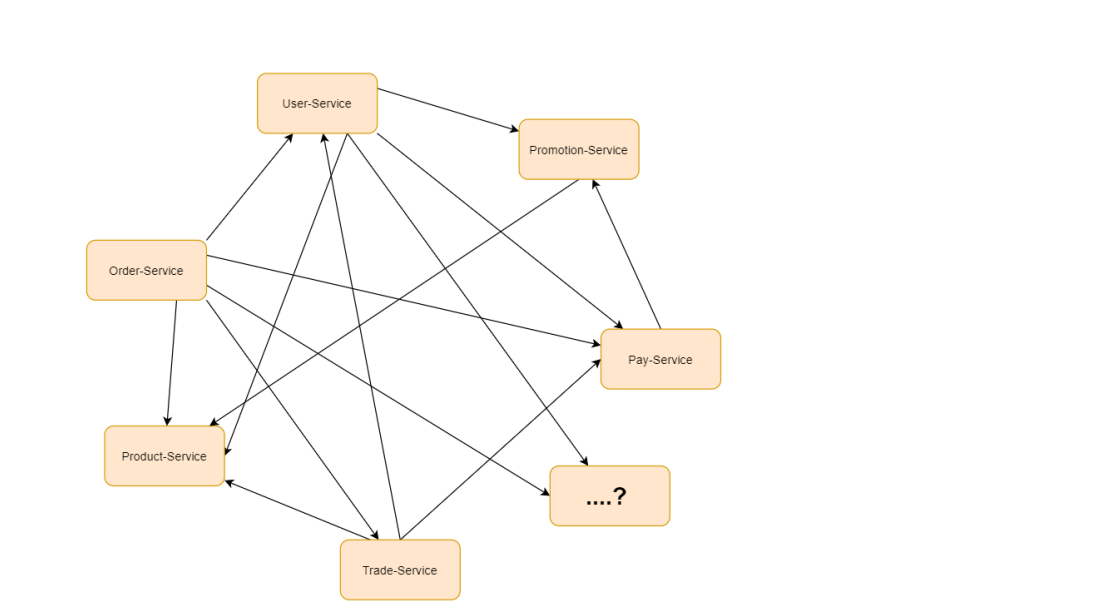
服务不再是A-B,B-C 那么简单,而是错综复杂的微小服务的调用
这个时候我们可以借助于Zookeeper的基本特性来实现一个注册中心,什么是注册中心,顾名思 义,就是让众多的服务,都在Zookeeper中进行注册,啥是注册,注册就是把自己的一些服务信 息,比如IP,端口,还有一些更加具体的服务信息,都写到 Zookeeper节点上, 这样有需要的服务就可以直接从zookeeper上面去拿,怎么拿呢? 这时我们可以定义统一的名称,比如, User-Service, 那所有的用户服务在启动的时候,都在User-Service 这个节点下面创建一个子节点(临时节点),这个子节点保持唯一就好,代表了每个服务实例的唯一标识,有依赖用户服务 的比如Order-Service 就可以通过User-Service 这个父节点,就能获取所有的User-Service 子 节点,并且获取所有的子节点信息(IP,端口等信息),拿到子节点的数据后Order-Service可 以对其进行缓存,然后实现一个客户端的负载均衡,同时还可以对这个User-Service 目录进行 监听, 这样有新的节点加入,或者退出,Order-Service都能收到通知,这样Order-Service重 新获取所有子节点,且进行数据更新。这个用户服务的子节点的类型为临时节点。Zookeeper中临时节点生命周期是和SESSION绑定的,如果SESSION超时了,对应的节点会被删除,被删除时,Zookeeper 会通知对该节点父节点进行监听的客户端, 这样对应的客户端又可以刷新本地缓存了。当有新服务加入时,同样也会通知对应的客户端,刷新本地缓存,要达到这个目标需要客户端重复的注册对父节点的监听。这样就实现了服务的自动注册和自动退出.
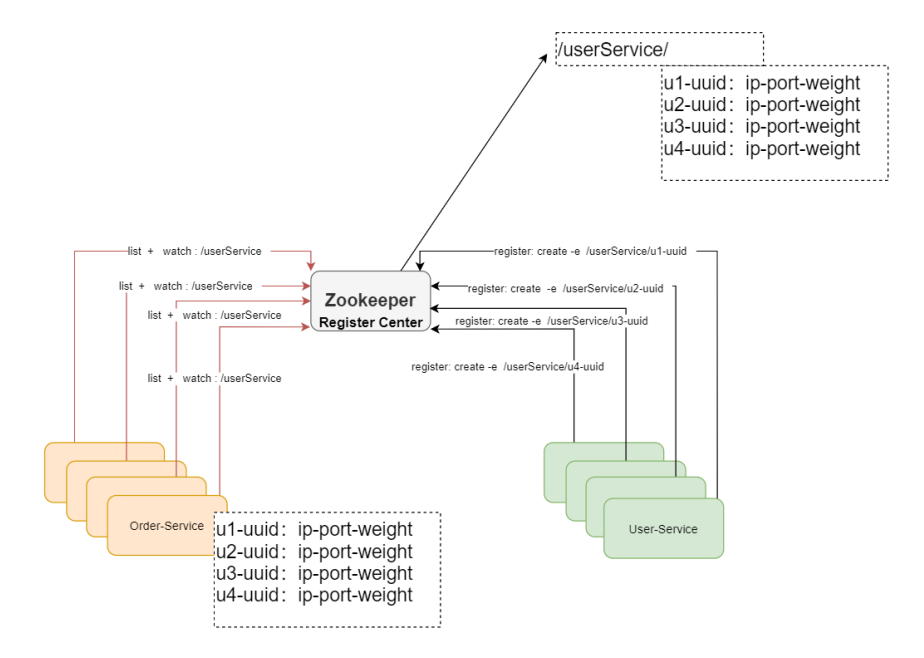
注册中心实战
Spring Cloud 生态也提供了Zookeeper注册中心的实现,这个项目叫 Spring Cloud Zookeeper 下面我们来进行实战。
项目说明:
为了简化需求,我们以两个服务来进行讲解实际使用时可以举一反三
user-center : 用户服务
product-center: 产品服务
用户调用产品服务,且实现客户端的负载均衡,产品服务自动加入集群,自动退出服务。
1.创建user-center 项目
pom
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency>
<!--<dependency>-->
<!--<groupId>org.springframework.cloud</groupId>-->
<!--<artifactId>spring-cloud-starter-openfeign</artifactId>-->
<!--</dependency>-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
配置文件
spring.application.name=user-center
#zookeeper 连接地址
spring.cloud.zookeeper.connect-string=192.168.123.123:2181
3.编写代码
配置RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
return restTemplate;
}
配置测试类
Spring Cloud 支持 Feign, Spring RestTemplate,WebClient 以 逻辑名称, 替代具体url的形式访问
@RestController
public class TestController {
@Autowired
private RestTemplate restTemplate;
@Autowired
private LoadBalancerClient loadBalancerClient;
@GetMapping("/test")
public String test() {
return this.restTemplate.getForObject("http://product-center/getInfo", String.class);
}
@GetMapping("/lb")
public String getLb(){
ServiceInstance choose = loadBalancerClient.choose("product-center");
String serviceId = choose.getServiceId();
int port = choose.getPort();
return serviceId + " : "+port;
}
}
2.1.创建product-center项目
pom
<properties>
<java.version>1.8</java.version>
<spring-cloud.version>Hoxton.SR8</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
配置文件
spring.application.name=product-center
#zookeeper 连接地址
spring.cloud.zookeeper.connect-string=192.168.123.123:2181
#将本服务注册到zookeeper
spring.cloud.zookeeper.discovery.register=true
spring.cloud.zookeeper.session-timeout=30000
编写代码
业务类
@Value("${server.port}")
private String port;
@Value( "${spring.application.name}" )
private String name;
@GetMapping("/getInfo")
public String getServerPortAndName(){
return this.name +" : "+ this.port;
}
用不同的端口启动两个product-center实例
启动user-center实例
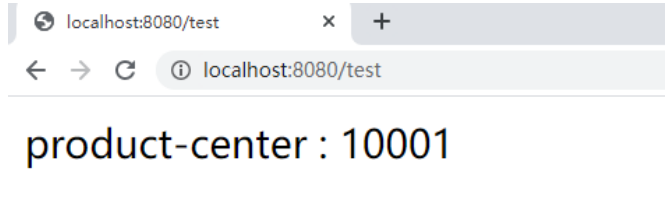
启动服务 :访问 http://localhost:8080/test

通过zookeeper客户端查看节点

查看services内的具体信息

获得某一个实例的具体信息
get /services/product-center/d86177cd-27a2-4298-8704-ec2d12a17ab9

当我们停掉10002服务,再次访问
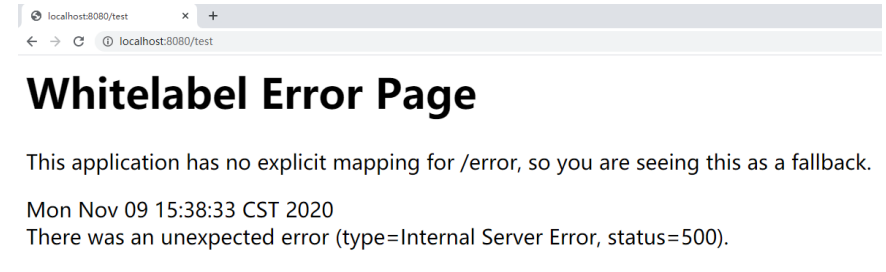
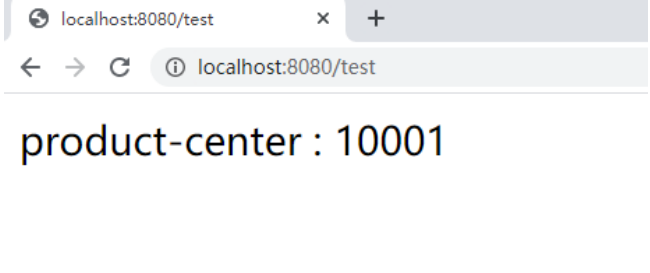
一定的超时时间过去之后,product-center: 10002 会从zookeeper中剔除,zookeeper会通知 客户端,进行本地缓存刷新,再次访问, 已经实现了失效节点的自动退出。














 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









