









18.11.15
这一次是专门讲链表合并成顺序链表的,是个人对链表合并的一些理解,比较片面,只能参考参考
合并链表的思路
首先,如果我们有两个给定的链表,而且都是乱序的,那么当要我们把它合并成一个顺序链表,我们一开始就想到的思路,便是先将两个链表合并起来,在对合并后的乱序链表进行排序,那就先这么办
在给出程序前先想想 合并&排序函数 该怎么写
合并:非常简单,只需要将第一个链表的最后一个结点的指针,指向第二个链表的第一个结点**(注意不是头结点)**的指针
排序:有点难,我们需要赋给这个函数一个新的链表的头结点地址,然后通过遍历这个乱序链表查找最小(大)值,同时找到的值插入新的链表中,并将找到最小(大)值的那个结点的值改成一个超大(小)值,使其不会再被找到,之后便是反复的遍历乱序列表,最终原来的乱序链表会变成全为超大(小)值的链表,而新的链表的着为排序后的顺序链表
最终代码实现如下:
pNode Find(pNode L,int k){//寻找链表中值为k的结点,将其值改为999
pNode H;
H=L->next;
while(H->data!=k){
H=H->next;
}
H->data=999;
return L;
}
//重点在这里
pNode Merge(pNode A,pNode B,pNode S){//传入A,B链表,合并为S链表
int i,k;
pNode H1=A;
pNode H;
while(H1->next!=NULL){
H1=H1->next;
}
H1->next=B->next;
//以上为A,B链表合并,思路是将定位指针H1不断向后指,
//直到指到链表尾部,再将B链表的第一个结点的地址赋给H1->next
//此时链表A就是合并后的链表
H=A;//定位指针H,用于查找最小值
while(ListLength(S)!=ListLength(A)){
k=999;
while(H->next!=NULL){//出了该循环以后,k应该是存有合并后链表A的最小值的
if(k>=(H->next->data)){
k=(H->next->data);
}
H=H->next;
}
printf(" k 在这时是 %d, ",k);
NewInsert(S,k);//将k插入到一个空的只有头结点的链表S
Print(S);
H=Find(A,k);//这一步很重要!!!
//将A链表中值为k的那个结点数值更改为一个超大数,这样后面就不会在把他算进去了
}
return S;
}
现在想想能不能进一步优化这个算法,首先,如果我们需要自己创造两个链表,然后进行排序,我们是否可以在链表创造的源头进行优化,即生成链表时就将数据顺序排列好,这一点是行的通的,会大大减小合并时的复杂度
插入函数(可直接形成顺序链表):
先来写插入函数,即每插一个数,就将其与链表中其他数进行比较,最终可直接生成一个顺序链表,经历了不断的失败后,写出代码如下
pNode Insert(pNode L,int elem){
int status=1;
pNode p=L;
pNode pNew=(pNode)malloc(sizeof(Node));
while(status){
if(p->next==NULL){//如果p的下一个结点为空,
//说明elem已经比前面的任何结点的数值都要大了,则在末尾插入elem
p->next=pNew;
pNew->data=elem;
pNew->next=NULL;
status=0;
}
else if((p->next->data)>=elem){//elem遇到比他大的结点就停下来,在他前面进行插入
pNew->next=p->next;
p->next=pNew;
pNew->data=elem;
status=0;
}
p=p->next;
}
return L;
}
上面的代码比较难处理的地方是要对插在末尾的结点进行单独处理(应该是我自己出了太多BUG简直要抓狂),现在假设我们得到了两个顺序链表,现在要将其合并
合并函数:
首先,我们已经有两个顺序链表,为了将其合并成一个从大到小排序的链表,我们比较两个链表的第一个结点,一个比较小,一个比较大,将小的结点数值存入S中,并将小的结点指向下一个结点,再将这下一个结点与刚才那个大的结点进行比较,以此往复,最终可以得到一个有序的链表S
代码实现如下
int FrontInsert(pNode L,int e){//前插算法,插入成功返回1,否则返回0
//这个前插函数是配套底下的合并函数使用的
pNode pNew;
pNew=(pNode)malloc(sizeof(Node));
if(pNew){
pNew->data=e;
pNew->next=L->next;
L->next=pNew;
return 1;
}
else
return 0;
}
pNode CompareMerge(pNode A,pNode B,pNode S){//合并函数
//通过比较大小来对两个链表进行合并,暂且称之为比较合并函数....
pNode H1=A;
pNode H2=B;
int tmp;//这是一个中间变量,可有可无的,为了看着方便
while(H1->next&&H2->next){
if((H1->next->data)<(H2->next->data)){//如果A链表结点比B链表结点数值小,
//将A链表节点数值存入S中
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
}
else if((H1->next->data)>(H2->next->data)){
//如果B链表结点比A链表结点数值小,
//将B链表节点数值存入S中
tmp=H2->next->data;
FrontInsert(S,tmp);
H2=H2->next;
}
else if((H1->next->data)==(H2->next->data)){//如果相等就存A
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
}
printf("此时链表S为: ");
Print(S);
}
//这里已经退出了上面的循环
if(H1->next==NULL){//如果A链表的结点已经存完了,那就把B的全部存进去
//反正已经排好序了
do{
tmp=H2->next->data;
FrontInsert(S,tmp);
H2=H2->next;
printf("此时链表S为: ");
Print(S);
}while(H2->next!=NULL);
}
else if(H2->next==NULL){//如果B链表的结点已经存完了,那就把A的全部存进去
//反正已经排好序了
do{
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
printf("此时链表S为: ");
Print(S);
}while(H1->next!=NULL);
}
return S;
}
效率比较:
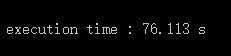
上面的比较合并函数,虽然很长,但是效率怎么样呢,通过测试,当两个有30000个结点的链表进行合并时
这是最开始的合并函数花的时间:
这是后面的比较合并函数花的时间:
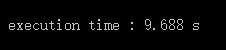
相比之下,采用第二种方案,快了不止是一点啊,所以第二种算法是花空间换时间的一种算法
源程序:
下面给出两种函数的调试程序
第一种:
#include <stdio.h>
#include<stdlib.h>
#include<malloc.h>//包含malloc()和exit()等函数
typedef int Elemtype;//int是Elemtype
typedef struct node{
Elemtype data;
struct node *next;
}Node,*pNode;
pNode CLH(void){//创建链表头结点
pNode L=(pNode)malloc(sizeof(Node));
if(!L)
exit(-1);
L->next=NULL;
return L;
}
//一个很简单的前插函数
int Insert(pNode L,int e){//前插算法,插入成功返回1,否则返回0
pNode pNew;
pNew=(pNode)malloc(sizeof(Node));
if(pNew){
pNew->data=e;
pNew->next=L->next;
L->next=pNew;
return 1;
}
else
return 0;
}
int ListLength(pNode L){//求链表函数长度
//需要定位指针p,以及计数器i
pNode p=L->next;//设置定位指针
int i=0;//设置计数器
while(p){//如果L不为空
p=p->next;
i++;
}
return i;
}
void Print(pNode L){
pNode p=L->next;
while(p){//只要p不为空,我就可以打印
printf("%d, ",p->data);
p=p->next;//完事以后不要忘记指向下一个结点
}
printf("\n");
}
pNode Find(pNode L,int k){//寻找链表中值为k的结点,将其值改为999
pNode H;
H=L->next;
while(H->data!=k){
H=H->next;
}
H->data=999;
return L;
}
//重点在这里
pNode Merge(pNode A,pNode B,pNode S){//传入A,B链表,合并为S链表
int i,k;
pNode H1=A;
pNode H;
while(H1->next!=NULL){
H1=H1->next;
}
H1->next=B->next;
//以上为A,B链表合并,思路是将定位指针H1不断向后指,
//直到指到链表尾部,再将B链表的第一个结点的地址赋给H1->next
//此时链表A就是合并后的链表
H=A;//定位指针H,用于查找最小值
while(ListLength(S)!=ListLength(A)){
k=999;
while(H->next!=NULL){//出了该循环以后,k应该是存有合并后链表A的最小值的
if(k>=(H->next->data)){
k=(H->next->data);
}
H=H->next;
}
printf(" k 在这时是 %d, ",k);
Insert(S,k);//将k插入到一个空的只有头结点的链表S
Print(S);
H=Find(A,k);//这一步很重要!!!
//将A链表中值为k的那个结点数值更改为一个超大数,这样后面就不会在把他算进去了
}
return S;
}
int main(){
pNode L1,L2,S;//S为合并链表,这里只是S的头结点
int i;
L1=CLH();
for(i=1;i<10;i++){
Insert(L1,i);//在L1中依次插入i
}
printf("表一为:\n");
Print(L1);
L2=CLH();
for(i=1;i<10;i++){
Insert(L2,3*i);//在L2中依次插入3*i
}
printf("表二为;\n");
Print(L2);
S=CLH();
printf("开始合并:\n");
Merge(L1,L2,S);
printf("\n最终合并成的顺序链表如下:\n");
Print(S);
}
运行展示:

第二种:
#include <stdio.h>
#include<stdlib.h>
#include<malloc.h>//包含malloc()和exit()等函数
typedef int Elemtype;//int是Elemtype
typedef struct node{
Elemtype data;
struct node *next;
}Node,*pNode;
pNode CLH(void){//创建链表头结点
pNode L=(pNode)malloc(sizeof(Node));
if(!L)
exit(-1);
L->next=NULL;
return L;
}
void Print(pNode L){
pNode p=L->next;
while(p){//只要p不为空,我就可以打印
printf("%d, ",p->data);
p=p->next;//完事以后不要忘记指向下一个结点
}
printf("\n");
}
pNode Insert(pNode L,int elem){
int status=1;
pNode p=L;
pNode pNew=(pNode)malloc(sizeof(Node));
while(status){
if(p->next==NULL){//如果p的下一个结点为空,
//说明elem已经比前面的任何结点的数值都要大了,则在末尾插入elem
p->next=pNew;
pNew->data=elem;
pNew->next=NULL;
status=0;
}
else if((p->next->data)>=elem){//elem遇到比他大的结点就停下来,在他前面进行插入
pNew->next=p->next;
p->next=pNew;
pNew->data=elem;
status=0;
}
p=p->next;
}
return L;
}
int FrontInsert(pNode L,int e){//前插算法,插入成功返回1,否则返回0
//这个前插函数是配套底下的合并函数使用的
pNode pNew;
pNew=(pNode)malloc(sizeof(Node));
if(pNew){
pNew->data=e;
pNew->next=L->next;
L->next=pNew;
return 1;
}
else
return 0;
}
pNode CompareMerge(pNode A,pNode B,pNode S){
//通过比较大小来对两个链表进行合并,暂且称之为比较合并函数....
pNode H1=A;
pNode H2=B;
int tmp;
while(H1->next&&H2->next){
if((H1->next->data)<(H2->next->data)){//如果A链表结点比B链表结点数值小,
//将A链表节点数值存入S中
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
}
else if((H1->next->data)>(H2->next->data)){
//如果B链表结点比A链表结点数值小,
//将B链表节点数值存入S中
tmp=H2->next->data;
FrontInsert(S,tmp);
H2=H2->next;
}
else if((H1->next->data)==(H2->next->data)){//如果相等就存A
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
}
printf("此时链表S为: ");
Print(S);
}
//这里已经退出了上面的循环
if(H1->next==NULL){//如果A链表的结点已经存完了,那就把B的全部存进去
//反正已经排好序了
do{
tmp=H2->next->data;
FrontInsert(S,tmp);
H2=H2->next;
printf("此时链表S为: ");
Print(S);
}while(H2->next!=NULL);
}
else if(H2->next==NULL){//如果B链表的结点已经存完了,那就把A的全部存进去
//反正已经排好序了
do{
tmp=H1->next->data;
FrontInsert(S,tmp);
H1=H1->next;
printf("此时链表S为: ");
Print(S);
}while(H1->next!=NULL);
}
return S;
}
int main(){
int i;
pNode L1,L2,S;
L1=CLH();
L2=CLH();
S=CLH();
printf("表一为:\n");
for(i=1;i<10;i++){
Insert(L1,i);//在L2中依次插入3*i
}
Print(L1);
printf("表二为:\n");
for(i=1;i<10;i++){
Insert(L2,3*i);//在L2中依次插入3*i
}
Print(L2);
CompareMerge(L1,L2,S);
Print(S);
}
运行展示:

以上均为个人关于线性链表合并的片面的理解














 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









