







简介:函数可以把我们经常使用的代码封装起来, 需要的时候直接调用即可。这样既 `提高了代码效率` ,又 `提高了可维护性` 。在 SQL 中我们也可以使用函数对检索出来的数据进行函数操作。使用这些函数,可以极大地提高用户对数据库的管理效率 。
函数分成` 内置函数 `和 `自定义函数` 。在 SQL 语言中,同样也包括了`内置函数`和`自定义函数`。内置函数是系统内置的通用函数,而自定义函数是我们根据自己的需要编写的
MySQL提供的内置函数从实现的功能角度可以分为数值函数、字符串函数、日期和时间函数、流程控制函数、聚合函数等。这些丰富的内置函数再分为两类:单行函数 、聚合函数 。
在 SQL 中,DUAL 是一个特殊的虚拟表,它只包含一行一列,通常用于不需要从实际数据表中选择数据的查询。SELECT 语句中的 FROM DUAL 子句是可选的,因为如果没有指定列,MySQL 会默认选择 DUAL 表。
单行函数:
数值函数:
| 函数名 | 作用 |
| abs(x) | 取x的绝对值 |
| sign(X) | 取X的符号。正数返回1,负数返回-1,0返回0 |
| PI() | 取圆周率的值 |
| rand() | 取0~1的随机值 |
| round(x) | 取一个对x的值进行四舍五入后,最接近于X的整数 |
| truncate(x,y) | 取数字x截断为y位小数的结果 |
SELECT
ABS(-321), ABS(456), SIGN(-10), SIGN(10),PI(), RAND(), ROUND(1.5), TRUNCATE(3.1415,2)
FROM DUAL;
字符串函数:
| 函数名 | 作用 |
| char_length(s) | 字符串 s 的字符数。 |
| length(s) | 返回字符串 s 的字节数( 1汉字=3字节 ) |
| concat(s1,s2,......,sn) | 连接 s1,s2,......,sn 为一个字符串 |
| concat_ws(z,s1,s2,......,sn) | 同 concat(s1,s2,...) 函数,但是每个字符串之间要加上z |
| replace(str, a, b) | 字符串 b 替换字符串 str 中所有出现的字符串a |
| upper(s) | 字符串 s 的所有字母转成大写字母 |
| lower(s) | 字符串 s 的所有字母转成小写字母 |
| left(str,n) | 返回字符串 str 最左边的n个字符 |
| right(str,n) | 返回字符串 str 最右边的n个字符 |
| lpad(str, len, pad) | 用字符串 pad 对 str 最左边进行填充,直到 str 的长度为 len 个字符 |
| rpad(str ,len, pad) | 用字符串 pad 对 str 最右边进行填充,直到 str 的长度为 len 个字符 |
| ltrim(s) | 去掉字符串 s 左侧的空格 |
| rtrim(s) | 去掉字符串 s 右侧的空格 |
select
char_length("abcdefg"),length("你好"),concat("aa","bb","cc"),concat_ws("&","aa","bb","cc"),replace("azzzzZZbbb","z","c")
from dual;
select
upper("hello,world"),lower("hello,WORLD"),left("hello,world",5),right("hello,world",5),lpad("_aabb_",10,"hello"),rpad("_aabb_",10,"hello")
from dual;
select ltrim(" hello"),rtrim("world ") from dual;
日期和时间函数:
| 函数名 | 作用 |
| curdate() ,current_date() | 当前日期,只包含年、 月、日 |
| curtime() , current_time() | 当前时间,只包含时、 分、秒 |
| now() / sysdate() / current_timestamp/ localtime() / localtimestamp() | 当前系统日期和时间 |
| utc_date() | UTC(世界标准时间) 日期 |
| utc_time() | UTC(世界标准时间) 时间 |
| unix_timestamp()。单位为毫秒 | UNIX 时间戳的形式返回当前时间。 |
| unix_timestamp(date) | 将时间 date 以 UNIX 时间戳的形式返回。 |
| from_unixtime(timestamp) | 将 UNIX 时间戳的时间转换为普通格式的时间 |
select
curdate(),curtime(),now(),utc_date(),utc_time()
from dual;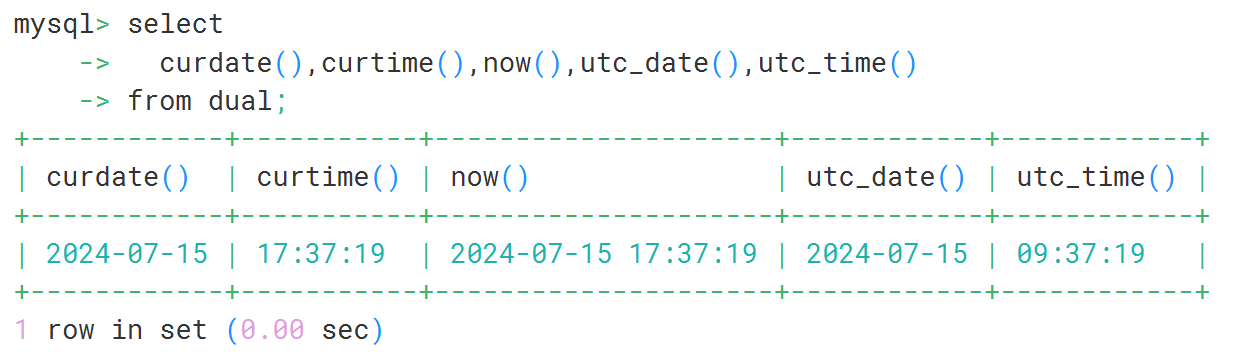
select
unix_timestamp(),from_unixtime(unix_timestamp()),unix_timestamp(now()),from_unixtime(unix_timestamp())
from dual;
#
select
unix_timestamp(),from_unixtime(1721036649),unix_timestamp('2024-07-15 17:44:09'),from_unixtime(1721036649)
from dual;
| 函数名 | 作用 |
| year(date) / month(date) / day(date) | 返回具体的日期值 |
| hour(time) / minute(time) / second(time) | 返回具体的时间值 |
| monthname(date) | 返回月份 |
| dayname(date) | 返回星期几 |
| weekday(date) | 返回周几,注意,周1是0,周2是1,周日是6 |
| quarter(date) | 返回日期对应的季度,范围为1~4 |
| week(date) , weekofyear(date) | 返回一年中的第几周 |
| dayofyear(date) | 返回日期是一年中的第几天 |
| dayofmonth(date) | 返回日期位于所在月份的第几天 |
| dayofweek(date) | 返回周几,注意:周日是1,周一是2,周六是 7 |
select year(curdate()),month(curdate()),day(curdate()) from dual;
select year(now()),month('2024-07-15'),day('2024-07-15') from dual;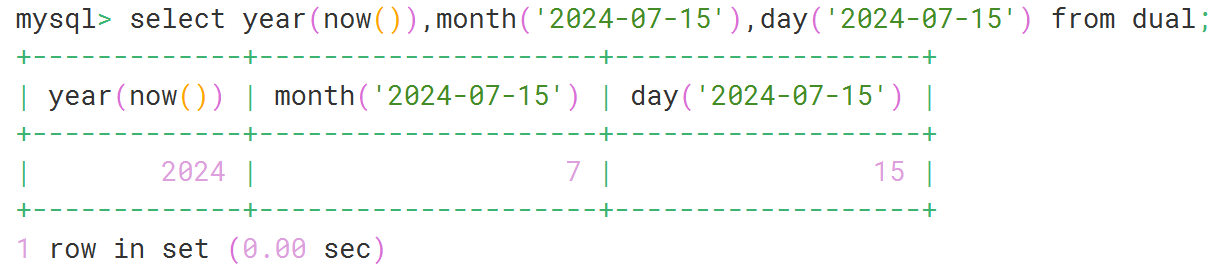

select
monthname('2024-7-13'),dayname('2024-7-13'),weekday('2024-7-13'),quarter(curdate()),
week(curdate()),dayofyear(now()),dayofmonth(now()),dayofweek(now())
from dual;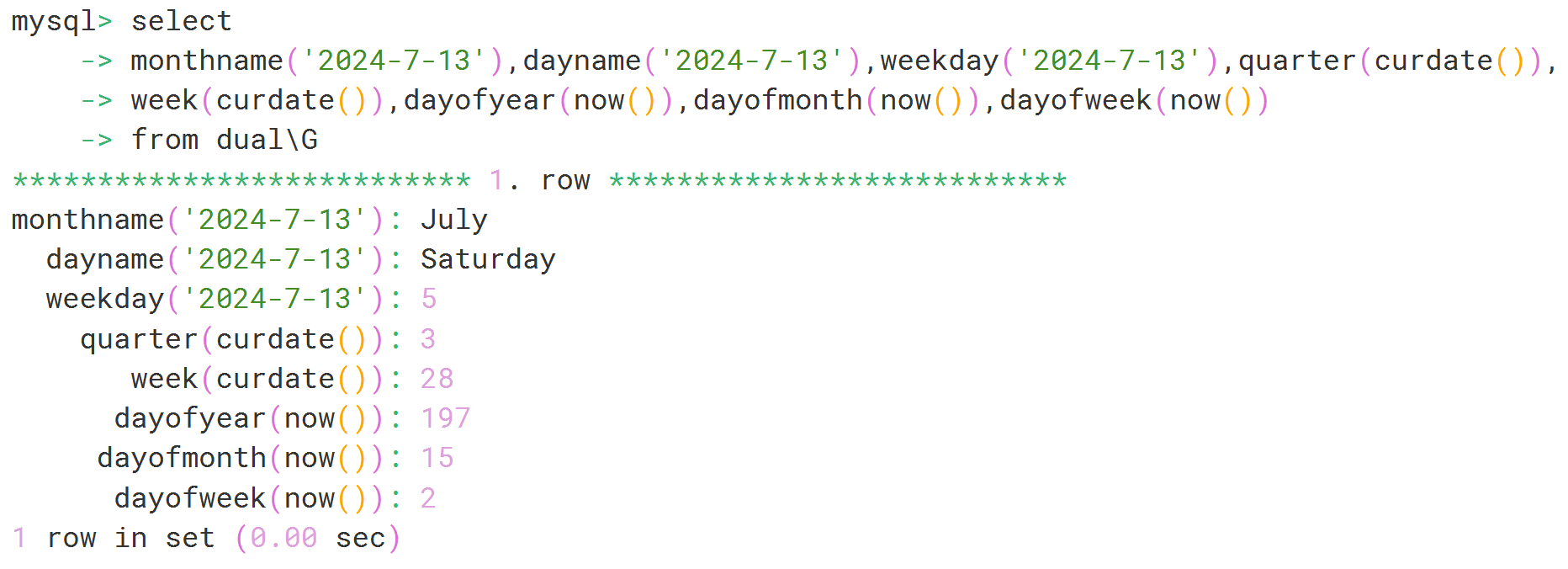
流程控制函数:
流程处理函数可以根据不同的条件,执行不同的处理流程,可以在SQL语句中实现不同的条件选择。
| 函数名 | 作用 |
| IF(value, value1,value2) | 如果value的值为TRUE,返回value1, 否则返回value2 |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2THEN 结果2 .... [ELSE resultn] END | 相当于shell的if...else if...else... |
#工资大于6000的返回值:工资略高;反之,返回值:工资一般
select id,name,salary,if(salary>6000,"工资略高","工资一般") from emp;
#佣金比率不为空,返回佣金比率;反之,返回值0
select id,name,salary,commission_pct,ifnull(commission_pct,0) from emp;
#
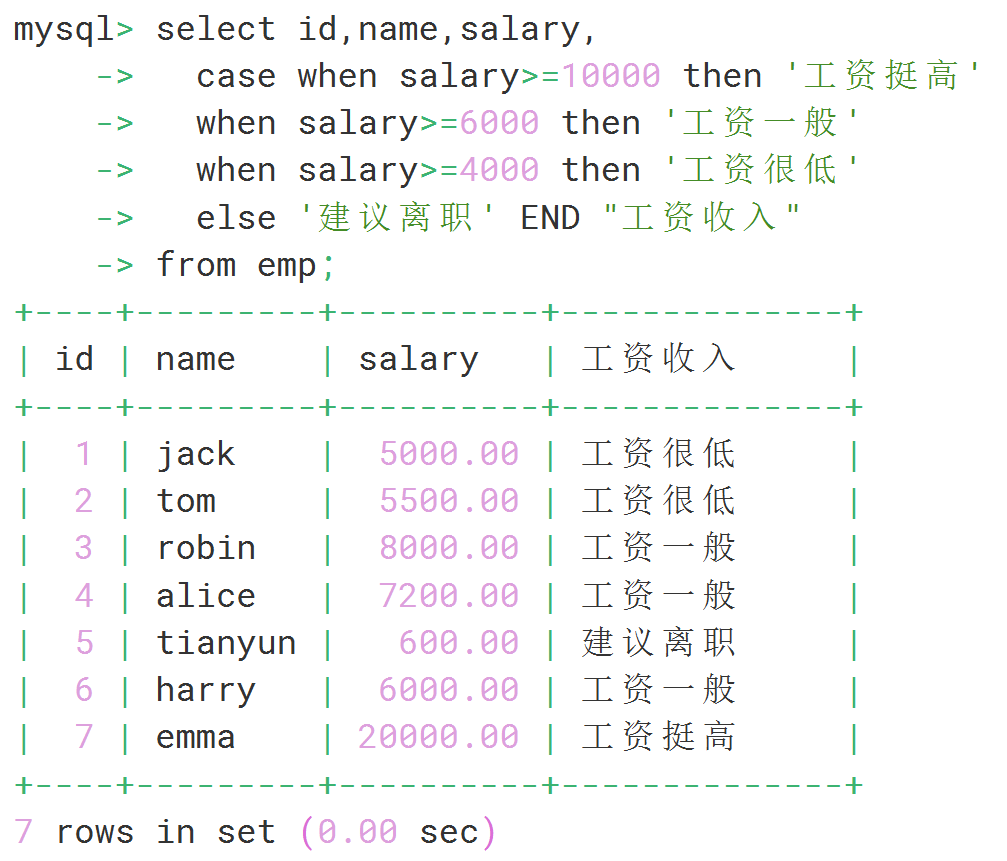
select id,name,salary,
case when salary>=10000 then '工资挺高'
when salary>=6000 then '工资一般'
when salary>=4000 then '工资很低'
else '建议离职' END "工资收入"
from emp;
聚合函数【重点】
对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。聚合函数作用于一组数据,并对一组数据返回一个值。
| 函数名 | 作用 |
| avg() | 平均值 |
| sum() | 总和 |
| max() | 最大值 |
| min() | 最小值 |
| count() | 个数 |
max() 最大值
select max(字段) from 表名;
select max(salary) from emp;
#查询薪水最高的人的详细信息:
select * from emp where salary = (select max(salary) from emp);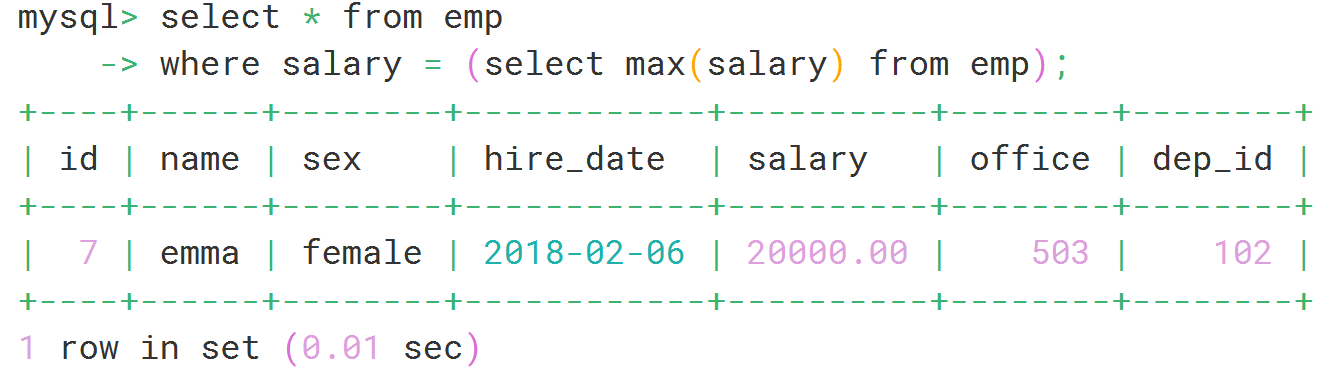
min() 最小值
select min(字段) from 表名;
select min(salary) from emp;avg() 平均值
select avg(字段) from 表名;
select avg(salary) from emp;sum() 计算和
select sum(字段) from 表名 where 字段='元素';
select sum(salary) from emp;
select sum(salary) from emp where dep_id='100';
#查看员工12个月的工资总和
select sum(salary * 12) from employees;count() 数量
conut函数在统计默认情况不包含空值
select count(字段) from 表;
#
select count(employee_id) from employees;
#查看表中总记录数
select count(*) from employees;
#函数嵌套使用:
select count(commission_pct) / count(employee_id) from employees;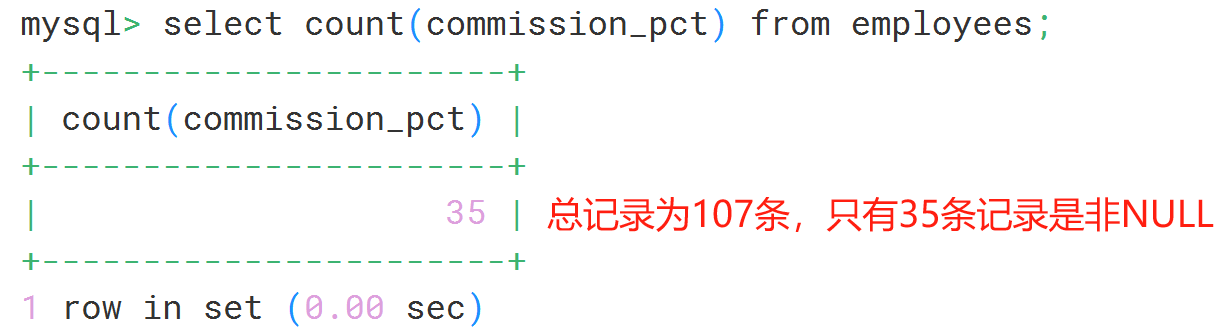
group_concat() 函数
group_concat()是一个聚合函数,用于将多个行的值合并为一个字符串。它特别适用于将分组的结果合并为一个单独的列值。
限制group_concat()结果长度:默认情况下是1024字符
set group_concat_max_len = 2048;1.使用group_concat()将 group by内的所有元素 合并为一个字符串:
select 字段1, group_concat(字段2)
from 表名
group by 字段1;
2.指定一个分隔符,用于分隔合并的字符串值:
select 字段1, group_concat(字段2 separator '指定的分隔符')
from 表名
group by 字段1;
select sex, group_concat(name) from emp group by sex;
#
select sex, group_concat(name separator '; ') from emp group by sex;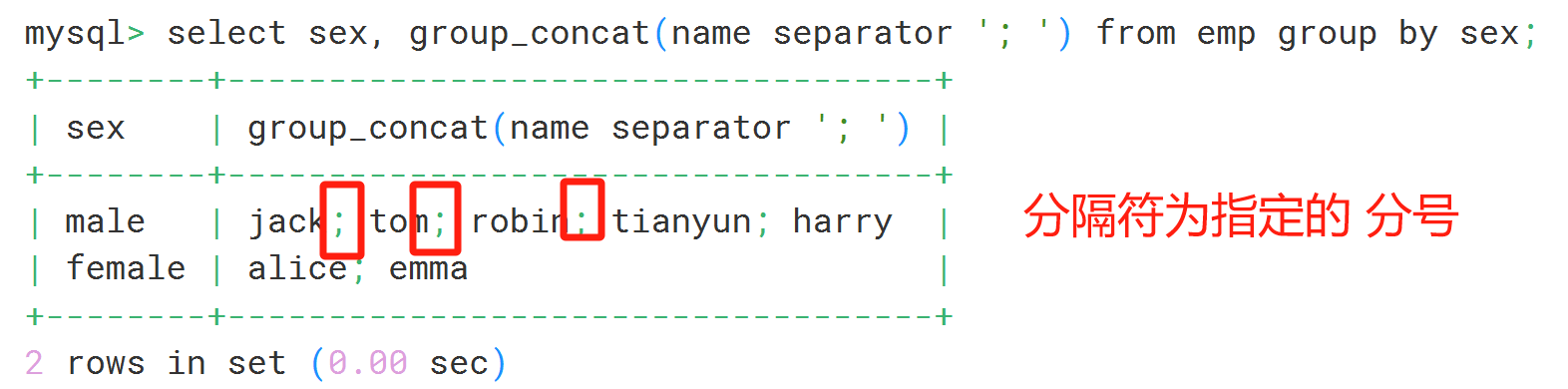
3.使用 order by 对合并的值进行排序:
select 字段1, group_concat(字段2 order by 字段2 separator ', ')
from 表名
group by 字段1;
4.合并多个列的值,但需要为每个列指定一个序号
select 字段1,
group_concat(字段2 ORDER BY 字段2 SEPARATOR '# ') AS 字段2的值,
group_concat(字段3 ORDER BY 字段3 SEPARATOR ' | ') AS 字段3的值
from 表名
group by 字段1;
select dep_id, group_concat(salary order by salary separator ', ')
from emp
group by dep_id;
#
select sex,
group_concat(name ORDER BY name SEPARATOR ' # ') AS 字段2的值,
group_concat(id ORDER BY id SEPARATOR ' | ') AS 字段3的值
from emp
group by sex;
















 4100
4100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









