






应用scrapy流程以及实现
本文章从下载scrapy脚本和创建scrapy爬虫项目开始,到采集电影网站基本数据,再到应用pymysql写入数据库流程的原理以及具体代码实现(内容有点多,别慌,跟着我的节奏慢慢来)
1.下载scrapy脚本以及创建scrapy爬虫项目框架
(1)下载脚本:(如果已经安装过,跳过此步骤)
先进入虚拟环境(找到你的虚拟环境目录venv,切换到Scripts目录下,单击其上方的路径栏输入cmd回车打开一个终端,此时的终端路径为Scripts的路径,然后输入activate,就进入虚拟环境了),然后输入pip install scrapy下载安装完成后,再输入pip install pywin32,下载安装完成即可(如果报错,通常为网络问题;安装pywin32的目的在于防止在本流程中系统报错)。
注意:由于本文章还用到了pymysql脚本,如果没有,根据上述描述进入虚拟环境,输入pip install pymysql下载安装即可。
(2)创建scrapy爬虫项目框架
1.在cmd终端虚拟机环境下,切换到想要创建的项目的目录
2.执行scrapy startproject spidermovieproject
其中:
(1) scrapy startproject(固定格式)
(2)spidermovieproject :本文章创建的项目名(可自定义)
3.切换到项目名里
4.执行scrapy genspider jobspider //dianying.2345.com/list/-------2.html?1
其中,//dianying.2345.com/list/-------2.html?1(这是我的目标链接,也可以是你想要爬取)注意:你选择的网站一定是无需登陆就能爬取的界面(不然白费力气,本文章不涉及伪装登陆爬取),最好是带分页的(因为本文章还涉及到分页采集的操作);
执行完成后,项目中,会有一个名叫jobspider.py的文件,你就在这里面写爬虫的主程序
备注:本文使用的2345电影网站只是用于学习交流,不涉及商业行为
上述代码执行完后,在没有报错的情况下,scrapy的框架就创建完成了。
2.采集网站数据(包括代码实现)
(1)首先,为了以后操作的方便,需要scrapy.cfg所在目录下创建一个startspider.py的文件作为启动爬虫程序的脚本,代码如下:
#启动爬虫的脚本
from scrapy.cmdline import execute #execute执行
execute(['scrapy','crawl','jobspider']) #前两个为固定格式;
#需要注意的是jobspider为上述描述中的主程序名,即要执行的文件名
在之后的执行操作中,直接运行此脚本即可。
(2)配置项目中的settings.py文件
如下代码都是settings.py中存在的,但是被默认注释掉了,所以需要去掉注释符号 # 即可(注意:是删除#号,不是删除代码),代码如下(自行核对):
ROBOTSTXT_OBEY = False #注意,去掉注释符号#后,将原来的值改为False
DOWNLOAD_DELAY = 5 #注意,去掉注释符号#后,将原来的3改为5
SPIDER_MIDDLEWARES = {
'spidermovieproject.middlewares.SpidermovieprojectSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES = {
'spidermovieproject.middlewares.SpidermovieprojectDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'spidermovieproject.pipelines.SpidermovieprojectPipeline': 300,
}
AUTOTHROTTLE_DEBUG = False
改完这6处配置后此步骤完成。
(3)分析网站
分析网站的目的在于书写主程序中的xpath方法,以截取想要得到的文本(此步骤在爬虫项目中至关重要)
如下图所示是网站的原始界面:
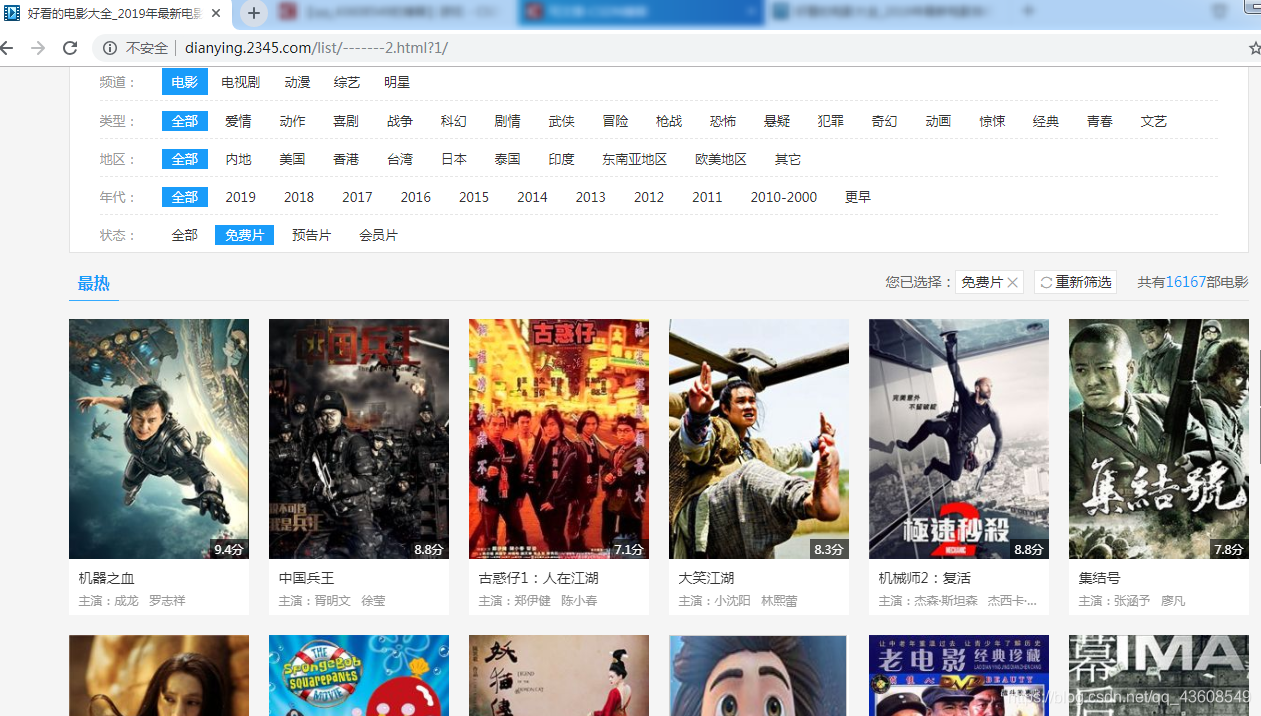
如图下图所示,每部电影的信息都存储在各个标签 li 中,且内部标签结构相同(下图的标签li中,有一个属性为class的,但无需担心,因为它不满足我们接下来的xpath规则,因此,它不会被爬取下来)
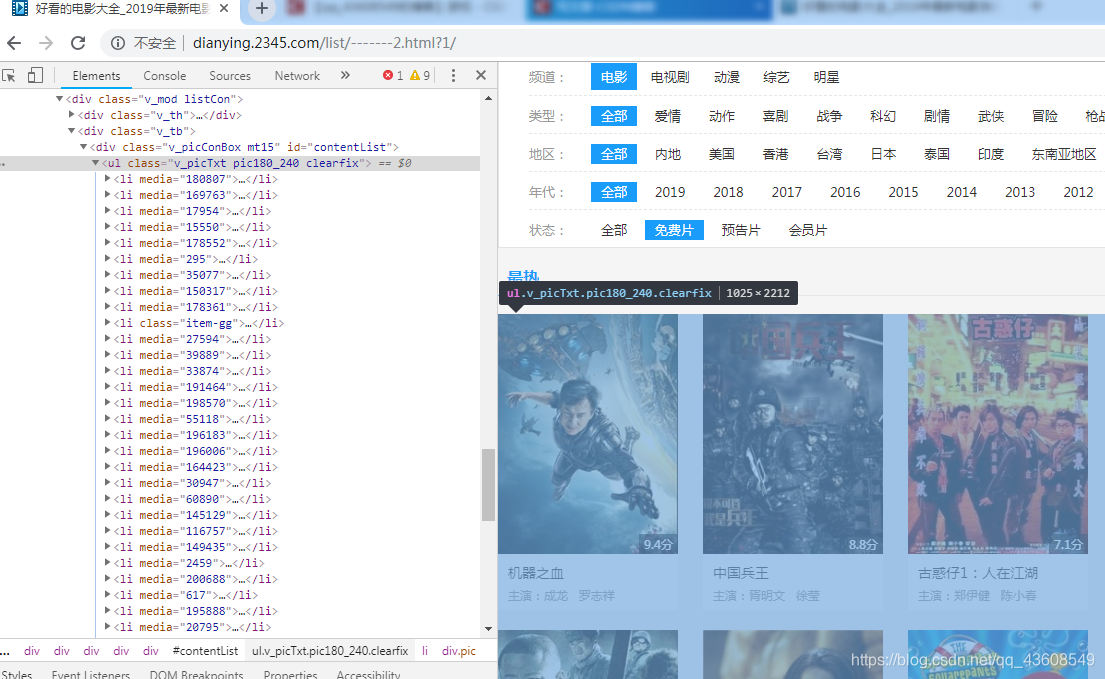
想要采集每部电影的名称、主演、评分、以及 每部电影的播放地址
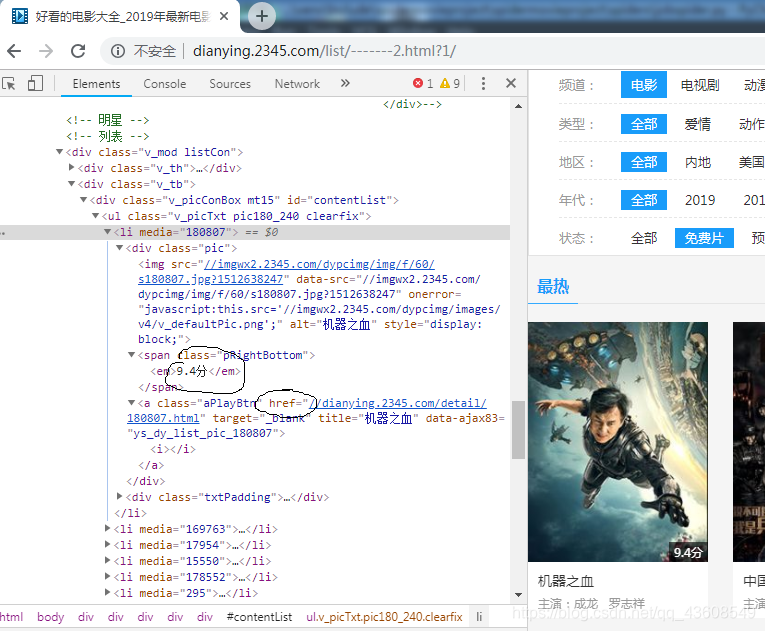
如图下图所示,该界面的评分和播放地址处于同一个div下
如图下图所示,该界面的电影名和主演处于同一个div下
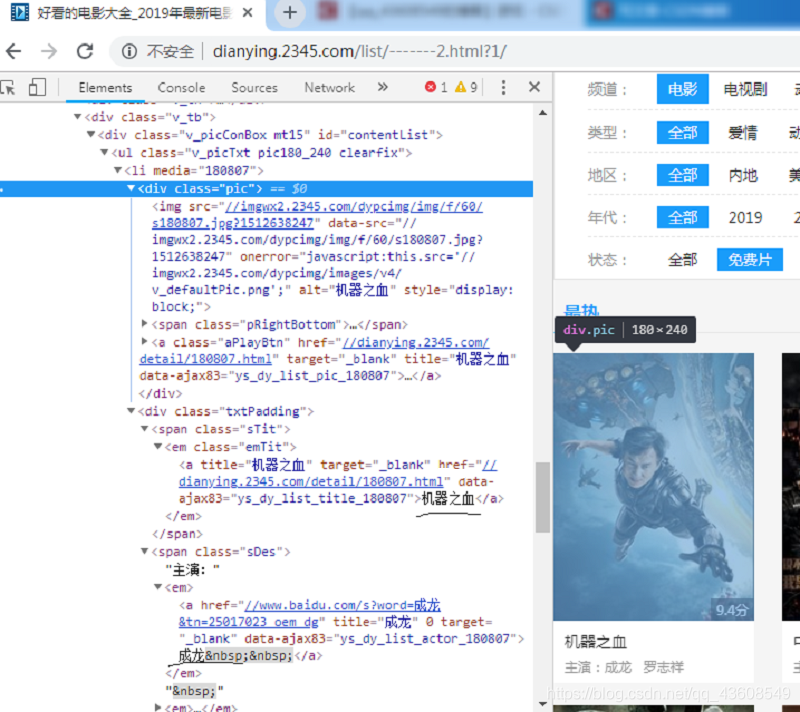
思路:由于这两个div的父标签都是li,所以,先通过xpath找到父标签,即//ul[@class=‘v_picTxt pic180_240 clearfix’]/li"(此xpath表达式回找出该页所有在标签ul且 class名为’v_picTxt pic180_240 clearfix’下所有li),然后通过循环遍历每一个li标签里要采集的元素,这些元素同样采用xpath表达式获取,详细请见(4)中的代码。
(4)根据上述分析采集数据
jobspiders.py的具体代码如下:
# -*- coding: utf-8 -*-
import scrapy #开始爬取的时候先单页爬取,无误后再进行多页爬取
from ..items import SpidermovieprojectItem #从items.py中导入SpidermovieprojectItem
#items.py中的具体代码在下一部分代码区
class JobspiderSpider(scrapy.Spider):
name = 'jobspider'
#allowed_domains = ['http://dianying.2345.com/list/-------2.html?1']
start_urls = ['http://dianying.2345.com/list/-------2.html?1/']
def parse(self, response): #这个函数里面是需要编写的爬虫主程序
movieItems = response.xpath("//ul[@class='v_picTxt pic180_240 clearfix']/li") #找到父标签li
for movieItem in movieItems: #遍历其中的元素
sItem = SpidermovieprojectItem() #实例化items.py中的方法文件
#extract()解析 strip()去掉多余空格 根据上图分析写出xpath表达式
#解析电影名
movieName = movieItem.xpath("div[@class='txtPadding']/span/em[@class='emTit']/a/text()")
if movieName:
sItem['movieName']=movieName.extract()[0].strip()
#解析主演
movieActor = movieItem.xpath("div[@class='txtPadding']/span[@class='sDes']/em/a/text()")
if movieActor:
sItem['movieActor']=movieActor.extract()[0].strip()
#解析电影评分
movieGrade = movieItem.xpath("div[@class='pic']/span/em/text()")
if movieGrade:
sItem['movieGrade']=movieGrade.extract()[0].strip()
#解析电影链接
movieUrl = movieItem.xpath("div[@class='txtPadding']/span/em/a/@href")
if movieUrl:
sItem['movieUrl']=movieUrl.extract()[0].strip()
#如果这四个数据同时得到的情况下,进行逐条记载
if movieName and movieActor and movieGrade and movieUrl:
yield sItem
pass
items.py(是创建scrapy框架时自动生成的,只有一个空类,须向其中添加要采集的数据名称;注意:要和jobspider.py中的数据名一致)的具体代码如下:
import scrapy
class SpidermovieprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() 根据系统给的实例规则书写
movieName = scrapy.Field()
movieActor = scrapy.Field()
movieGrade = scrapy.Field()
movieUrl = scrapy.Field()
pass
middlewares.py(与items.py在同一目录下 ,需要注意的是,此文章对这个文件从始至终都不做任何操作。)
pipelines.py与items.py在同一目录下,它是管道文件,主程序jobspiders.py通过管道进行输出打印数据。(pipelines.py是创建scrapy框架时自动生成的,只有一个空类,须向其中添加要打印输出的数据名称;注意:要和jobspider.py中的数据名一致),具体代码如下:
class SpidermovieprojectPipeline(object):
def process_item(self, item, spider):
print("通过管道输出电影数据:")
print(item['movieName'])
print(item['movieActor'])
print(item['movieGrade'])
print(item['movieUrl'])
return item
(注意:pipelines.py在执行时自动被框架内部机制调用,无需人为调用)
至此,右键运行startspiders.py即可在控制台看到爬取下来的数据
注意:此时得到的数据是单页的,且没有写入到mysql数据库的 临时数据
(5)实现分页爬取
思路:点击下一页时注意url的变化,其次分析按钮的标签,通过xpath获取按钮标签里的url数据,如下图所示,此网站可以利用urljoin(nextURL[-1])的方式,拼接新的下一页url。然后通过框架模拟get请求采集下一页数据。
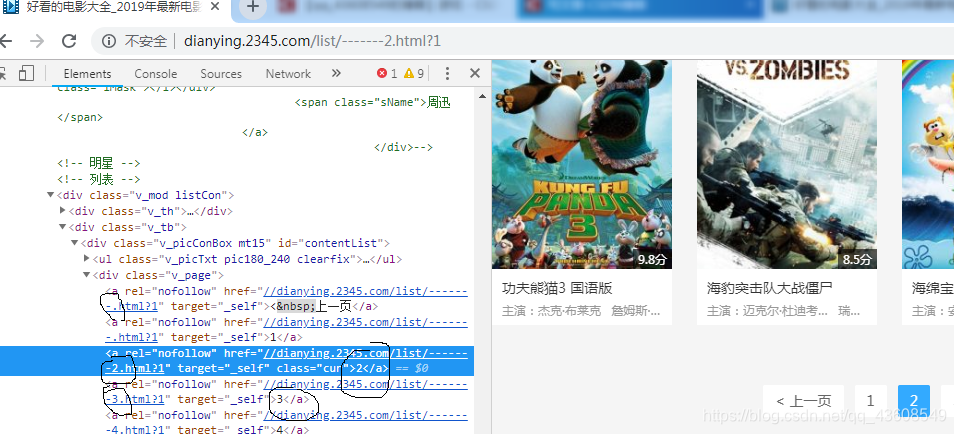
在jobspiders.py的最下方插入五行代码即可实现,如下:
#实现分页操作
nextURL = response.xpath("//div[@class='v_page']/a/@href").extract()
if nextURL:
url = response.urljoin(nextURL[-1])
print("url",url) #打印的目的是更直观的观察分页时的url变化
yield scrapy.Request(url,self.parse,dont_filter=False)
注意:此时得到的数据是多页的(几乎可以采集这个网站里的所有电影的电影名,主演,评分,播放地址),但此数据还是没有写入到mysql数据库的 临时的数据
至此,采集数据以及分页爬取完成,接下来是将数据写入数据库
3.写入mysql数据库
(1)创建mysql数据库
数据表结构如图所示:
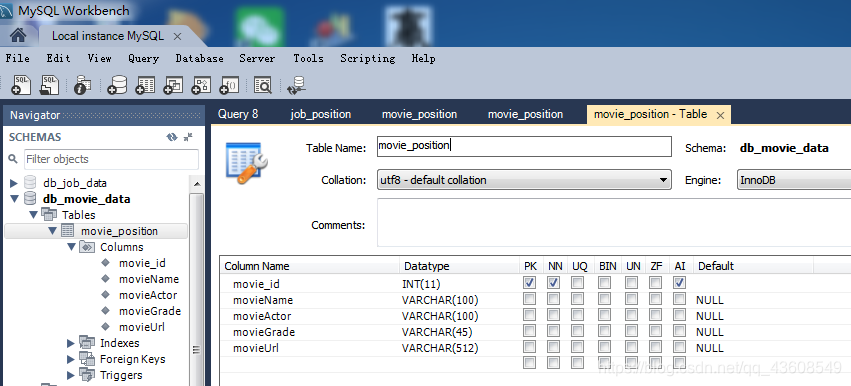
注意:除了自增的movie_id以外,尽量保证名称一致。以免发生错误。
(2)pymysql连接mysql数据库
[1]首先在items.py的同一目录下创建一个dao包,在包中创建两个.py文件和一个pymysql.json文件(pymysql.json中存放的是连接数据库的JSON字符串)
pymysql.json具体代码如下:
{"host":"127.0.0.1","user":"你的数据库的用户名","password":"你的数据库的密码", "database" :"db_movie_data","port":3306}
然后在dao包中创建basedao.py文件,此文件主要用pymysql连接数据库的操作,它所连接的数据库就是pymysql.json文件中的数据库。
basedao.py具体代码如下:
import pymysql #导入必须的模块
import json
import logging
import sys
import os
class BaseDao():
def __init__(self,configPath = 'pymysql.json'):
self.__connection =None
self.__cursor = None
self.__config = json.load(open(os.path.dirname(__file__) + os.sep + configPath,'r')) #通过json配置获得数据的连接配置信息
print(self.__config)
pass
def getConnection(self):
#当有连接对象时,直接返回连接对象
if self.__connection:
return self.__connection
#否则通过建立新的连接对象
try:
self.__connection = pymysql.connect(**self.__config)
return self.__connection
except pymysql.MySQLError as e:
print("Exception"+str(e))
pass
pass
#用于执行Sql语句的通用方法
def execute(self,sql,params):
try:
self.__cursor = self.getConnection().cursor()
#execute:返回的是修改数据的条数
result = self.__cursor.execute(sql,params)
return result
except (pymysql.MySQLError,pymysql.DatabaseError,Exception) as e:#捕获多个异常
print("出现数据库访问异常:"+str(e))
self.rollback()
pass
pass
pass
def fetch(self):
if self.__cursor: #提高代码健壮性
return self.__cursor.fetchall()
pass
def commit(self):
if self.__connection:
self.__connection.commit() #回滚问题
pass
def rollback(self):
if self.__connection:
self.__connection.rollback()
pass
def close(self): #应用完数据库之后,必须关闭与其连接,否则会导致数据库连接端口被占用,使其他业务无法连接数据库,导致系统停机
if self.__cursor:
self.__cursor.close()
if self.__connection:
self.__connection.close()
pass
if __name__=="__main__":
ms = BaseDao()
然后在dao包中创建jobpositiondao.py文件,此文件主要用于连接数据库后,向数据库插入movie信息的操作。
jobpositiondao.py具体实现代码如下:
from .basedao import BaseDao # . 代表当前目录
#定义一个movie数据操作的数据库访问类
class JobPositionDao(BaseDao):
def __init__(self):
super().__init__()
#向数据库插入movie信息
def create(self,params):
result = 0
try:
sql = "insert into movie_position (movieName,movieActor,movieGrade,movieUrl) values(%s,%s,%s,%s)"
result = self.execute(sql,params)
self.commit()
except Exception as e:
print(e)
finally:
self.close()
return result
pass
pass
这样dao包里的文件信息就配置完成了。
接下来,就是在items.py目录下创建mysqlpipelines.py管道文件,以及配置settings.py里的管道数据信息的操作,scrapy框架通过此管道将爬取的movie数据写入到之前连接好的mysql数据库中。
mysqlpipelines.py的具体代码实现:
from .dao.jobpositiondao import JobPositionDao
class SpidermoviemysqlPipeline(object):
def process_item(self, item, spider):
jobpositiondao = JobPositionDao()
#创建向mysql数据库写入的movie信息
jobpositiondao.create((item['movieName'],item['movieActor'],item['movieGrade'],item['movieUrl']))
return item
在settings.py的ITEM_PIPELINES中,添加一条信息:
ITEM_PIPELINES = {
'spidermovieproject.pipelines.SpidermovieprojectPipeline': 300,
'spidermovieproject.mysqlpipelines.SpidermoviemysqlPipeline': 302,#此行数据为后插入的信息,即配置向mysql数据库写入数据的管道信息。
}
至此,运行startspider.py后,打开数据库,查询即可看到已经采集下来的数据(如果在不报错的情况下,刷新数据库没看到相关数据,可能是你的xpath表达式书写的有问题,须进行debug查看,看data=[ ]中是否有数据,如果为空,则说明xpath表达式有问题)
下图是本文章最终采集的数据结果(并进行了按评分排序操作):
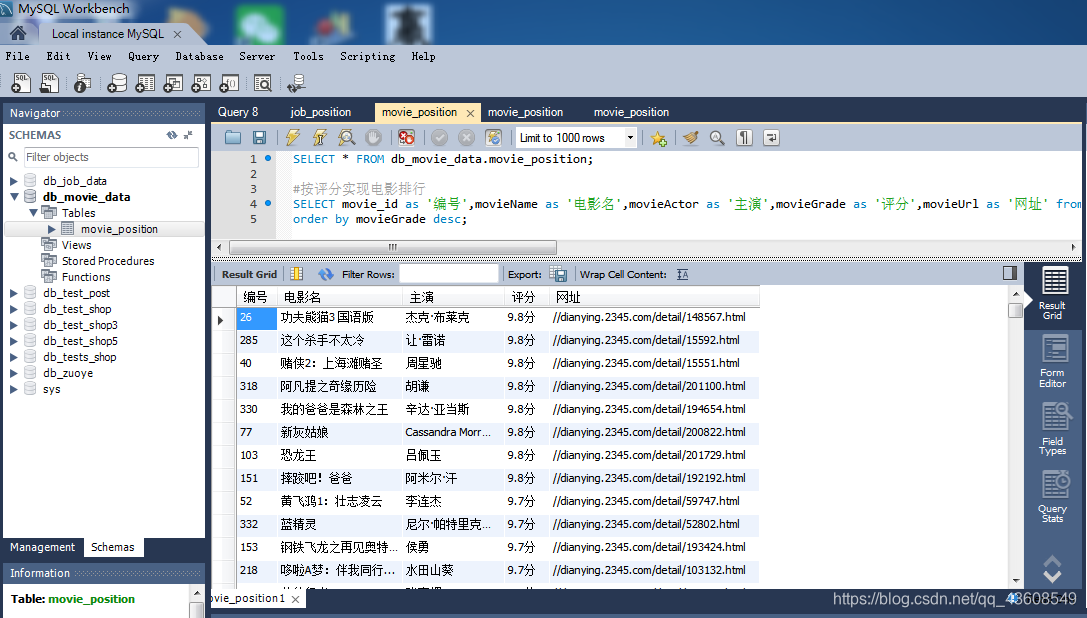
美好的时光总是短暂,不拼尽全力,怎能享受沧海桑田!!!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









