






JAVA操作Hbase数据库
使用IDEA连接hbase数据库
最近学习了hbase,想做下记录后面忘了再来看,也可以分享给各位小伙伴们。
新建一个Maven项目
奥,首先你的有一个ieda,哈哈哈哈
- 打开ieda,如下图操作

按顺序操作即可
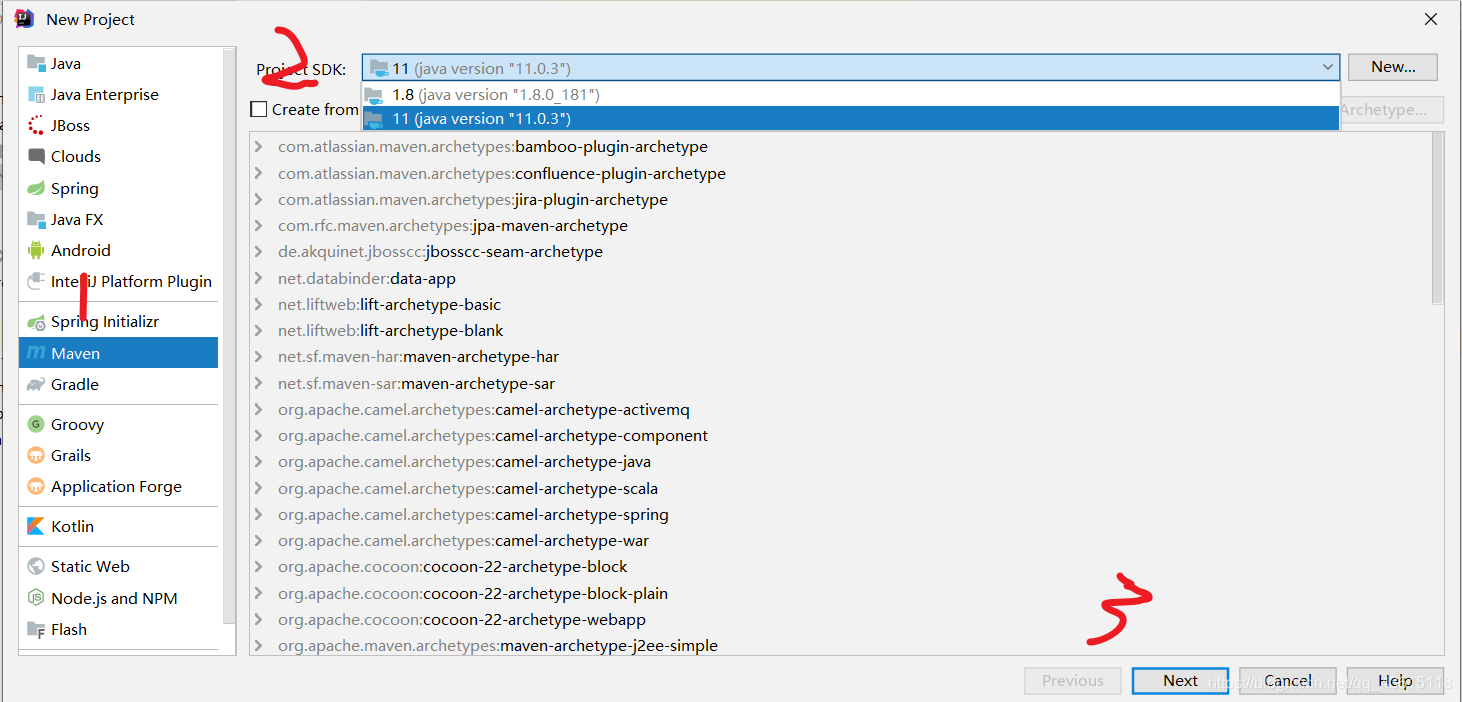
在下划线的位置输入自己项目的名字,点击next。
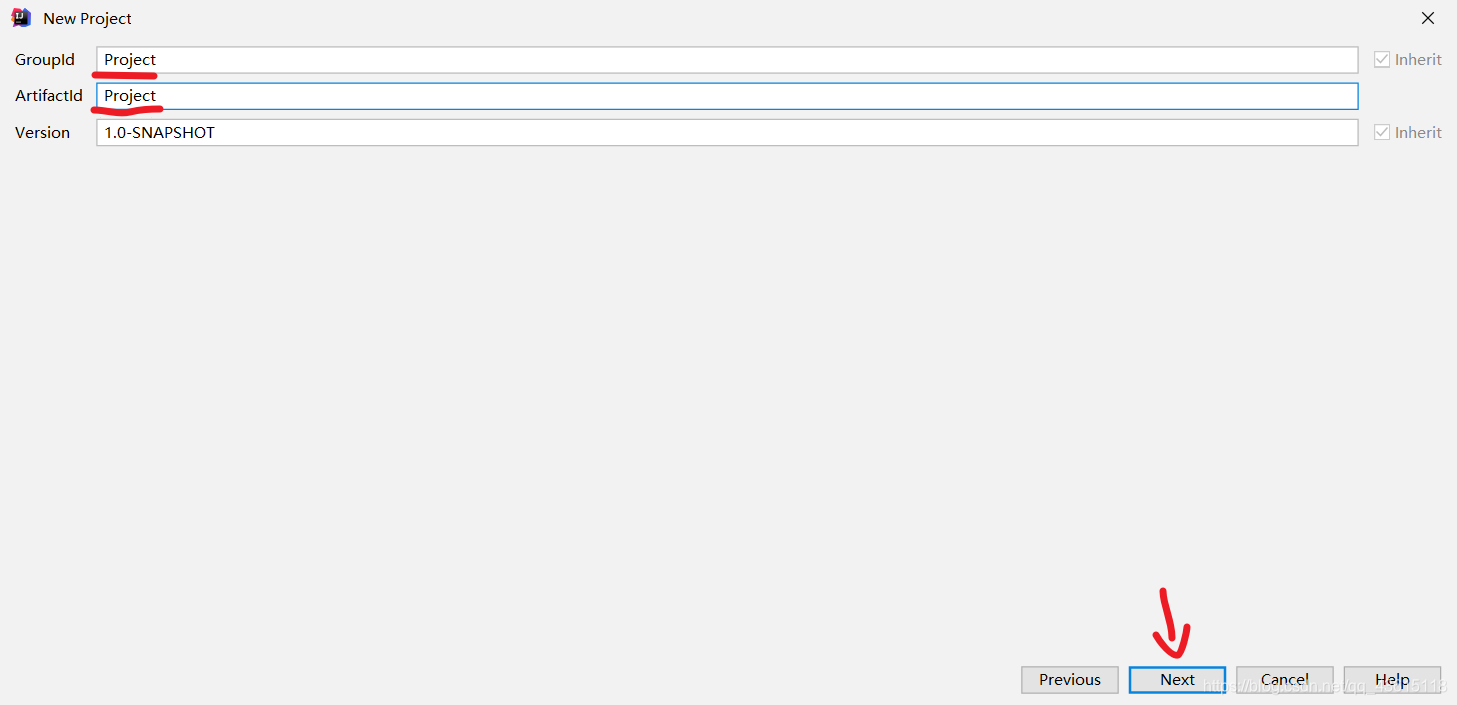
在下划线的位置可以选择自己的项目保存的位置;最后点击Finish确定,弹出选项框点击ok。
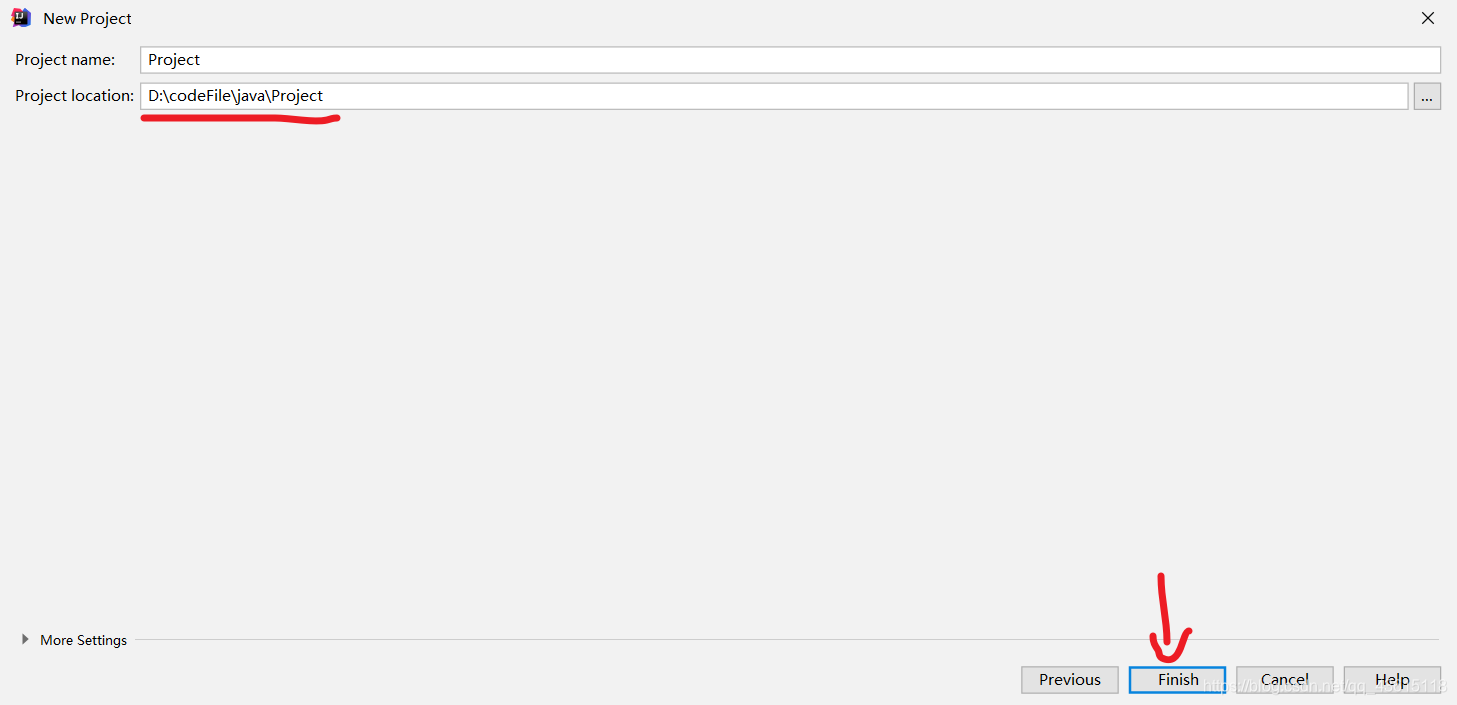
连接hbase数据库
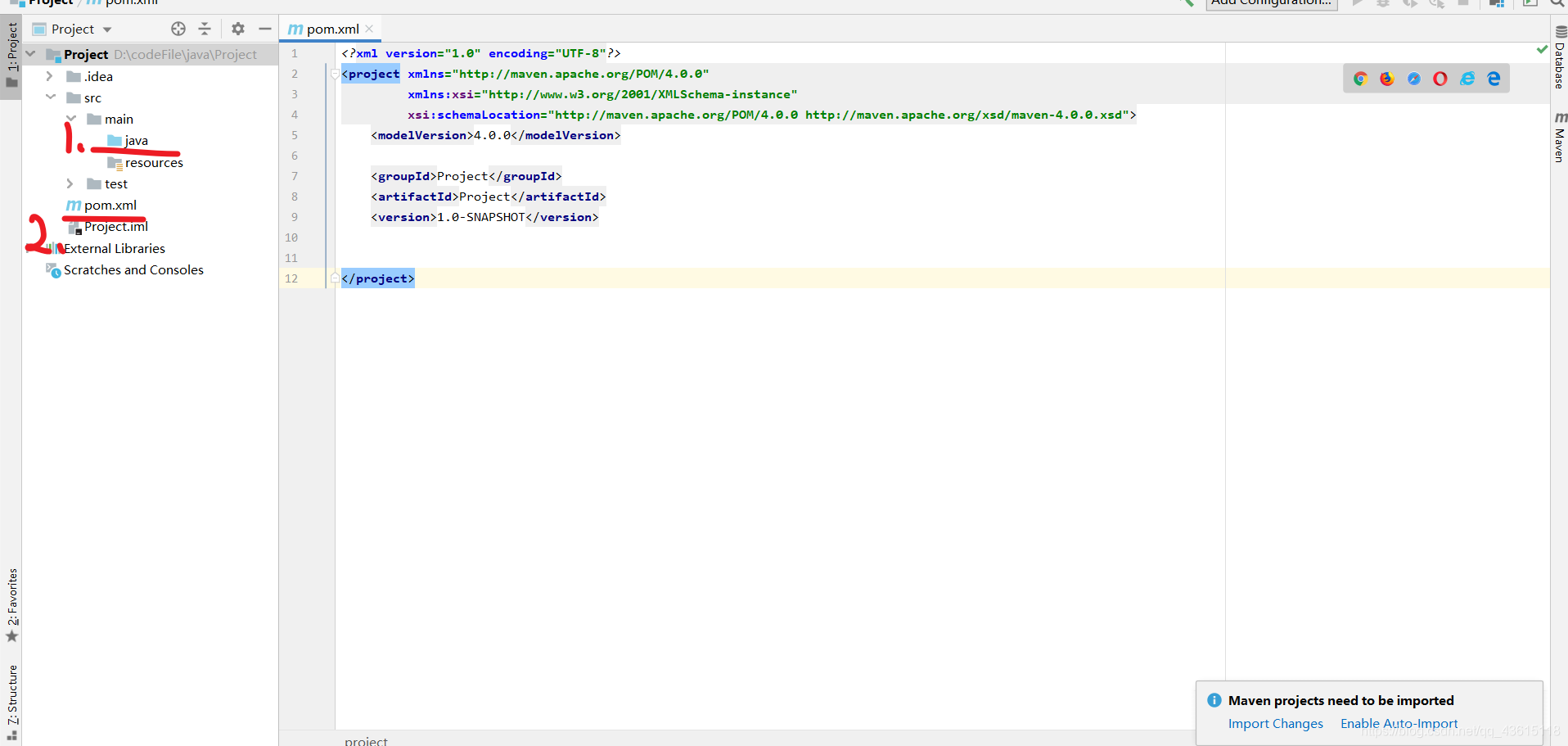
一个Maven项目就创建好了,如下图;数字1处的java文件夹是我们连接hbase数据库代码的存放位置;数字2是我们的配置文件下载一些包。
pom.xml文件的配置:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>hbase01</groupId>
<artifactId>hbase01</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.2.0-cdh5.14.0</version>
</dependency>
</dependencies>
在 <version>2.6.0</version>标签中的一些版本号要和自己的对应。弄好后在右下角会出现如下图所示的的提醒,点击划红线的选项,下载对应的包。
PS:可能需要点时间,等到右下角不再有加载条即可。
编写java操作hbase的代码
- 获取配置对象,配置参数使用zookeeper集群
写好后在本地电脑的C:\Windows\System32\drivers\etc路径下往hosts文件中添加你虚拟机的ip地址和主机名。Configuration config = HBaseConfiguration.create(); // node01等需要在本地电脑的hosts文件中配置 ,node01等是zookeeper集群配置的主机名。 config.set("hbase.zookeeper.quorum","node01,node02,node03");

- 创建连接对象
// 此处有异常需要捕捉或者抛出
Connection conn = ConnectionFactory.createConnection(config);
// 从连接对象获取admin对象
Admin admin = conn.getAdmin();
- 操作hbase数据库
使用scan查询表
Table table=conn.getTable(TableName.valueOf(hbase表名));
Scan scan=new Scan();
ResultScanner rs=table.getScanner(scan);
for(Result re:rs){
// re是一个Result对象,是cell对象集合;可以讲是一行数据
for(Cell c:re.rawCells()){
// c是Cell对象,可以理解为把一行数据循环取出每一列的值
// 例如:rk0002/info:age/1577953942894/Put/vlen=2/seqid=0
// 上面的cell对象就只包含age的信息;比如rowkey,列族,列名,age值
String rowk = new String(CellUtil.cloneRow(c));
String cf = new String(CellUtil.cloneFamily(c));
String cn = new String(CellUtil.cloneQualifier(c));
String val = new String(CellUtil.cloneValue(c));
}
}
全部代码
package com.ty.centosHbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class Testh {
public static Configuration config;
public static Connection conn;
public static Admin admin;
static{
config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum","centos01,centos02,centos03");
try {
conn = ConnectionFactory.createConnection(config);
admin = conn.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void showData(Table table, Scan scan) throws IOException {
// 使用表对象获取扫描数据
ResultScanner rs = table.getScanner(scan);
// 循环遍历rs ;rs是存储了一行一行数据的Result对象
for(Result re:rs){
System.out.println(re);
for(Cell c:re.rawCells()){
String rowk = new String(CellUtil.cloneRow(c));
String cf = new String(CellUtil.cloneFamily(c));
String cn = new String(CellUtil.cloneQualifier(c));
String val = new String(CellUtil.cloneValue(c));
System.out.println("rk:"+rowk+" cf:"+cf+" cn:"+cn+" va1ue:"+val);
}
}
}
/**
* @param tableName 表名
* @param cn 列名
* @param value 列值
*/
public static void queryByCV(String tableName,String cn,String value){
try {
Table table = conn.getTable(TableName.valueOf(tableName));
Scan scan = new Scan();
// 创建一个过滤器对象
// 当某一行,没有过滤的列名时会默认显示
SingleColumnValueExcludeFilter filter = new SingleColumnValueExcludeFilter("info".getBytes(), cn.getBytes(),
CompareFilter.CompareOp.EQUAL, value.getBytes());
//将过滤器封装到scan中
scan.setFilter(filter);
showData(table,scan);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void queryByRk(String tname,String rk){
try {
// 获取表对象
Table table = conn.getTable(TableName.valueOf(tname));
// 创建Scan对象
Scan scan = new Scan();
// 创建一个正则比较器对象,并指定正则表达式
RegexStringComparator cp = new RegexStringComparator(rk);
// 创建一个RowFilter对象
RowFilter filter = new RowFilter(CompareFilter.CompareOp.EQUAL, cp);
// 将过滤器设置到scan对象中
scan.setFilter(filter);
// 调用自己写的显示数据函数
showData(table, scan);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
//queryByCV("stu","age","18");
// queryByRk("stu","^rk.*(2|3)$");
}
}
总结
以上就是我这几天的学习内容,另外还有一些对表操作的代码都是大同小异的。第一次写博客,写的不好还请见谅。















 3448
3448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









