






HashMap
链表什么时候转换成红黑树?
1.链表长度大于8
2.数组长度大于等于64
HashMap中的hash算法
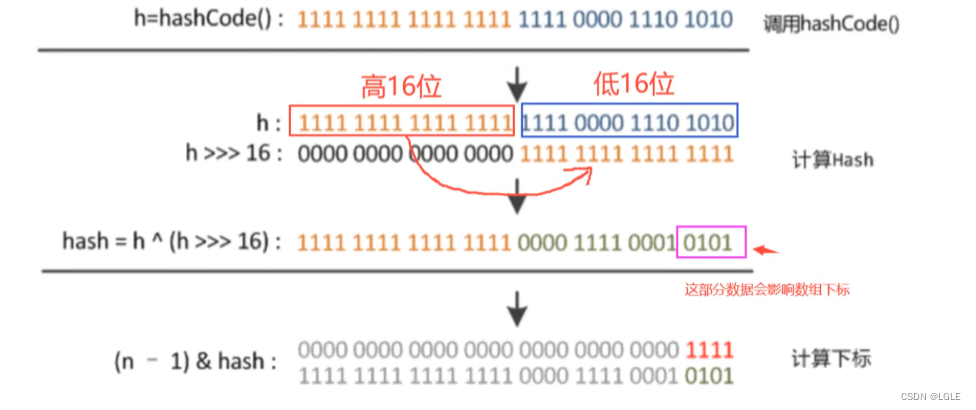
根据key算出hash值,先获取key的hashCode,在跟h无符号右移16位进行异或运算。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
再根据hash值计算出对应数组下标(n - 1) & hash,在n即数组长度为2的次方的条件下,(n - 1) & hash和hash%n是一样的,且效率更高。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
为什么HashMap要把hashcode做右移与运算改进:
如果不右移,hashCode的无法参与运算,那么运算结果只由低位决定,那么很多hashCode算出来的下标就会相同,加大了冲突的概率,可能造成某一下标下链表很长。
所以右移与运算让计算出来的数据下标更加分散,充分利用数组空间,减少冲突。
HashMap为什么是线程不安全的
1.多线程put可能会存在值覆盖的情况。
2.多线程扩容时可能会导致成环。
//1.7多线程扩容成环涉及代码
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
//获取链表的头节点e
while(null != e) {
//获取要转移的下一个节点next
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
//计算要转移的节点在新的Entry数组newTable中的位置
int i = indexFor(e.hash, newCapacity);
//使用头插法将要转移的节点插入到newTable原有的单链表中
e.next = newTable[i];
//将newTable的hash桶的指针指向要转移的节点
newTable[i] = e;
//转移下一个需要转移的节点e
e = next;
}
}
}
while(null != e) {
Entry<K,V> next = e.next; //线程1执行到这里被调度挂起了
e.next = newTable[i];
newTable[i] = e;
e = next;
}
JDK1.7用的是头插法,而JDK1.8及之后使用的都是尾插法,那么他们为什么要这样做呢?因为JDK1.7是用单链表进行的纵向延伸,当采用头插法时会容易出现逆序且环形链表死循环问题。但是在JDK1.8之后是因为加入了红黑树使用尾插法,能够避免出现逆序且链表死循环的问题。
ConcurrentMap为什么是线程安全的?
1.7版本在调用segment数据的put方法时会进行加锁

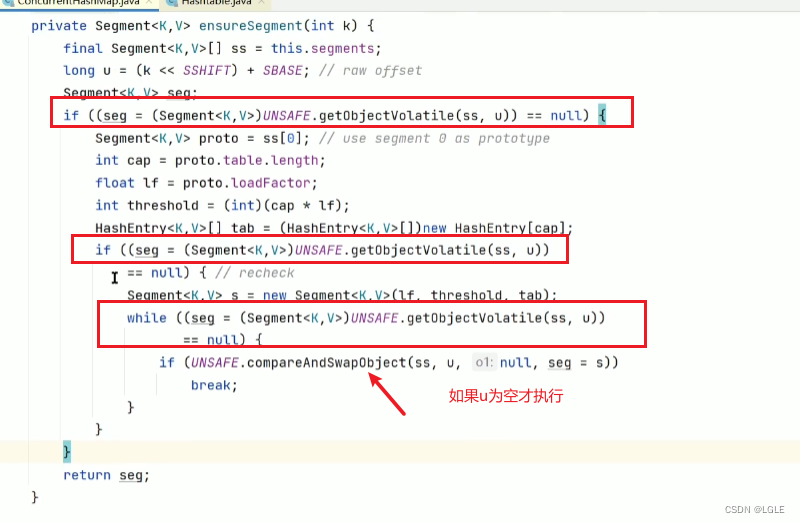
使用CAS保证多线程创建Segment
1.7版本新建HashEntry节点使用到了自旋锁
1.8版本使用了Node节点数组取代了segment数组
Node节点中的val和next使用了volatile 修饰
volatile V val;//带有同步锁的value
volatile Node<K,V> next;//带有同步锁的next指针
1.8版本通过什么保证线程安全
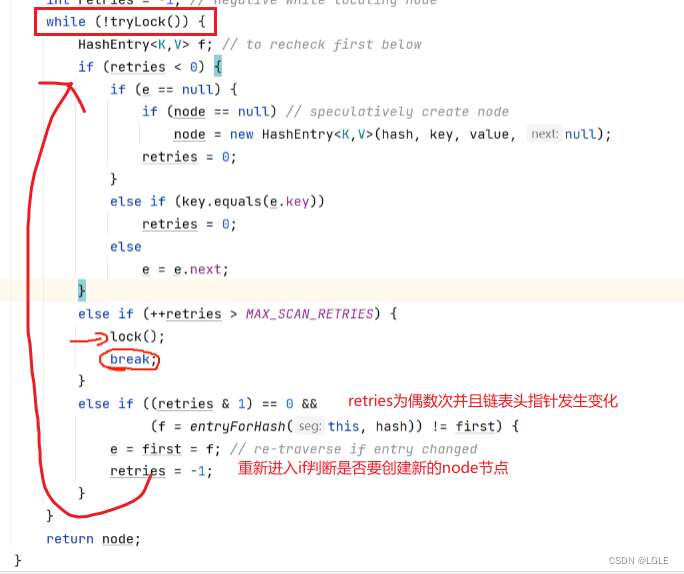
通过使用Synchroized关键字来同步代码块,而且只是在put方法中加锁,在get方法中没有加锁
在加锁时是使用头结点作为同步锁对象。,并且定义了三个原子操作方法。
/ 获取tab数组的第i个node<br>
@SuppressWarnings("unchecked")
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
// 利用CAS算法设置i位置上的node节点。csa(你叫私有空间的值和内存中的值是否相等),即这个操作有可能不成功。
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
// 利用volatile方法设置第i个节点的值,这个操作一定是成功的。
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}
ConcurrentHashMap(JDK1.8)为什么要使用synchronized而不是可重入锁?
我想从下面几个角度讨论这个问题:
锁的粒度
首先锁的粒度并没有变粗,甚至变得更细了。每当扩容一次,ConcurrentHashMap的并发度就扩大一倍。
Hash冲突
JDK1.7中,ConcurrentHashMap从过二次hash的方式(Segment -> HashEntry)能够快速的找到查找的元素。在1.8中通过链表加红黑树的形式弥补了put、get时的性能差距。
扩容
JDK1.8中,在ConcurrentHashmap进行扩容时,其他线程可以通过检测数组中的节点决定是否对这条链表(红黑树)进行扩容,减小了扩容的粒度,提高了扩容的效率。
下面是我对面试中的那个问题的一下看法:
为什么是synchronized,而不是可重入锁
- 减少内存开销
假设使用可重入锁来获得同步支持,那么每个节点都需要通过继承AQS来获得同步支持。但并不是每个节点都需要获得同步支持的,只有链表的头节点(红黑树的根节点)需要同步,这无疑带来了巨大内存浪费。 - 获得JVM的支持
可重入锁毕竟是API这个级别的,后续的性能优化空间很小。
synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。这就使得synchronized能够随着JDK版本的升级而不改动代码的前提下获得性能上的提升。 来自https://www.bbsmax.com/














 5074
5074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









