







import pandas as pd
df = pd.read_csv("./xxx.csv", error_bad_lines=False, sep='\t', low_memory=False)
# error_bad_lines = False 跳过错误的行。不过这种写法将会被废弃,建议写成 on_bad_lines = 'skip'error_bad_lines 参数
使用场景:读取csv文件时,可能会出现这种错误:
ParserError:Error tokenizing data.C error:Expected 2 fields in line 407,saw 3.
# 在csv文件的第407行数据,期待2个字段,但在第407行实际发现了3个字段原因:header只有两个字段名,但数据的第407行却出现了3个字段(可能是该行数据包含了逗号,或者确实有三个部分),导致pandas不知道该如何处理
解决办法:把第407行多出的字段删除;或者通过在read_csv方法中设置error_bad_lines=False来忽略这种错误,效果如下:
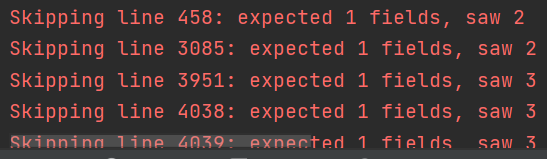
注意事项:
FutureWarning: The error_bad_lines argument has been deprecated and will be removed in a future version. Use on_bad_lines in the future.所以可以换成如下写法:
df = pd.read_csv(filepath, on_bad_lines = 'skip')low_memory 参数
使用场景:当出现如下报错时
DtypeWarning: Columns (8) have mixed types. Specify dtype option on import or set low_memory=False.原因:提示输入数据列有混合类型,而pandas默认要找到可以使所占用空间最小的类型来储存你的数据。low_memory设置为false之后,pandas就不进行寻找,直接采用较大的数据类型来储存
解决办法:将low_memory设置为false


















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











