







一、Nacos&Ribbon&Feign核心微服务架构图

二、架构原理
1、微服务系统在启动时将自己注册到服务注册中心,同时外发布 Http 接口供其它系统调用(一般都是基于Spring MVC)
2、服务消费者基于 Feign 调用服务提供者对外发布的接口,先对调用的本地接口加上注解@FeignClient,Feign会针对加了该注解的接口生成动态代理,服务消费者针对 Feign 生成的动态代理去调用方法时,会在底层生成Http协议格式的请求,类似 /stock/deduct?productId=100
3、Feign 最终会调用Ribbon从本地的Nacos注册表的缓存里根据服务名取出服务提供在机器的列表,然后进行负载均衡并选择一台机器出来,对选出来的机器IP和端口拼接之前生成的url请求,生成调用的Http接口地址 http://192.168.0.60:9000/stock/deduct?productId=100,最后基于HTTPClient调用请求
三、Nacos架构图

四、Nacos核心功能点
服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接收到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性置为false(客户端服务发现时不会发现),如果某个实例超过30秒没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)。
服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面注册的服务清单,并且缓存在Nacos Client本地,同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存。
服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
五、Nacos核心功能源码架构图

Nacos服务注册表结构:Map<namespace, Map<group::serviceName, Service>>

举例说明:

NameSpace可以用来区分不同的环境,如dev、qa、prod等。所以说一套nacos可以支持多个环境的服务注册。
Group用来区分不同的微服务组,如交易微服务、仓储微服务组等。不同的微服务可以属于一个微服务组。
Service对应一个具体的服务,如订单服务、支付服务。而一个具体的服务中还可以进行区分:Cluster。Cluster可以用来描述一个服务的异地多机房部署。比如一个订单服务,可能在北京有部署,也可能在上海有部署。
六、Nacos服务端源码单机运行
gihub 地址:
https://github.com/alibaba/nacos/tree/1.4.1
选择Tag 1.4.1版本。

# 下载nacos源码
git clone https://github.com/alibaba/nacos.git
源码整体结构(注意,nacos源码导入要求maven 3.2.5以上版本):

源码单机运行:
直接运行console模块里的 com.alibaba.nacos.Nacos.java
# 增加启动vm参数
-Dnacos.standalone=true

Nacos源码启动报错找不到符号com.alibaba.nacos.consistency.entity
如果启动的时候报错com.alibaba.nacos.consistency.entity:

那我们需要执行mvn compile来生成他们:https://nacos.io/zh-cn/docs/faq.html#3.19


生成之后,再次启动即可。(可能IDEA还是会爆红,说在项目源代码中找不到这些类,但是是可以正常启动的。因为已经有了.class文件)

然后访问:http://localhost:8848/nacos/index.html#/login
使用nacos,nacos登录。
源码集群运行:
nacos集群需要配置mysql存储,需要先创建一个数据,名字随便取,然后执行 distribution/conf 目录下的 nacos-mysql.sql 脚本,然后修改 console\src\main\resources 目录下的 application.properties 文件里的mysql配置,如下所示
### If use MySQL as datasource:
spring.datasource.platform=mysql
### Count of DB:
db.num=1
### Connect URL of DB:
db.url.0=jdbc:mysql://127.0.0.1:3306/nacos?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=UTC
db.user.0=root
db.password.0=mysqladmin
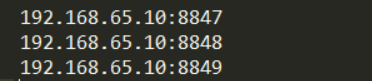
运行console模块里的 com.alibaba.nacos.Nacos.java,需要增加启动vm参数端口号和实例运行路径nacos.home(对应的目录需要自己提前创建好),每台server的nacos.home目录里需要创建一个conf文件夹,里面放一个cluster.conf文件,文件里需要把所有集群机器ip和端口写入进去,见下图:



面试题
Naocs注册表如何防止多节点读写并发冲突?
我们知道Nacos中的注册表是一个双map结构:Map<namespace, Map<group::serviceName, Service>>
那么在修改注册表的时候,是怎么保证并发的呢?因为一个修改操作我们要修改多个地方,可能要同时更新namespace、group、cluster等,那么如果保证同时修改成功呢?
思考:如果不给整个修改过程加锁的话,可能某个线程只执行了修改操作中的一部分,这时候另一个线程过来读取数据,结构可能会读取到脏数据或者命名有值但是是空的等问题。这么看来是要对整个操作加锁了?因为此时是有读写冲突!!!
但是这样加全局锁的话,读写会排队串行化,效率必然大大降低!
阿里做法:
阿里采用的是写时复制。
即写注册表数据的时候复制一份数据,然后对复制后的数据进行修改操作。而如果修改的过程中有其他线程来读取注册表,则去读取原始的那份注册表。这样就可以避免读取到脏数据,也实现了读写分离,读写就可以并发执行了,这无疑会大大提升性能。
这个思想在CopyOnWrite并发集合中也有写实复制的思想。
比如CopyOnWriteArrayList中,维护一个Object[] array来存储真实的数据:
private transient volatile Object[] array;
当读取数据的时候,就读取这个属性中的数据:
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
private E get(Object[] a, int index) {
return (E) a[index];
}
而当写数据的时候,就复制一份该数组,并使用reentrantLock加锁:
final transient ReentrantLock lock = new ReentrantLock();
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
写时复制优缺点
优点:读写分离,并发提高
缺点:读取到的数据不是最新的,降低了数据实时性
写时复制的时候要注意尽可能的让复制的数据结构的粒度小!减少内存消耗!
思考问题(还没完呢!):如果同时有多个线程来写呢?会出现什么场景?
注意: Nacos并不是复制整个注册表,而是只复制某个cluster下的服务列表。因为整个注册表是非常大的,会非常占用内存。
并且Nacos中只有一个单线程进行服务注册,所以写的时候只会复制一份,也不用考虑并发问题。
Nacos中保存数据的初始集合(分为临时和持久):
源码类:com.alibaba.nacos.naming.core.Cluster
@JsonIgnore
private Set<Instance> persistentInstances = new HashSet<>();
@JsonIgnore
private Set<Instance> ephemeralInstances = new HashSet<>();
public void updateIps(List<Instance> ips, boolean ephemeral) {
// 获取到初始数据(注意,此时并不是复制整个注册表,而是某个cluster下的服务列表)
Set<Instance> toUpdateInstances = ephemeral ? ephemeralInstances : persistentInstances;
// 复制一份数据到map中
HashMap<String, Instance> oldIpMap = new HashMap<>(toUpdateInstances.size());
// 将旧数据存储到这个oldIpMap中去
for (Instance ip : toUpdateInstances) {
oldIpMap.put(ip.getDatumKey(), ip);
}
// ====================================== 数据修改开始 ========================================================
List<Instance> updatedIps = updatedIps(ips, oldIpMap.values());
if (updatedIps.size() > 0) {
for (Instance ip : updatedIps) {
Instance oldIP = oldIpMap.get(ip.getDatumKey());
// do not update the ip validation status of updated ips
// because the checker has the most precise result
// Only when ip is not marked, don't we update the health status of IP:
if (!ip.isMarked()) {
ip.setHealthy(oldIP.isHealthy());
}
if (ip.isHealthy() != oldIP.isHealthy()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} IP-{} {}:{}@{}", getService().getName(),
(ip.isHealthy() ? "ENABLED" : "DISABLED"), ip.getIp(), ip.getPort(), getName());
}
if (ip.getWeight() != oldIP.getWeight()) {
// ip validation status updated
Loggers.EVT_LOG.info("{} {SYNC} {IP-UPDATED} {}->{}", getService().getName(), oldIP, ip);
}
}
}
List<Instance> newIPs = subtract(ips, oldIpMap.values());
if (newIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-NEW} cluster: {}, new ips size: {}, content: {}", getService().getName(),
getName(), newIPs.size(), newIPs);
for (Instance ip : newIPs) {
HealthCheckStatus.reset(ip);
}
}
List<Instance> deadIPs = subtract(oldIpMap.values(), ips);
if (deadIPs.size() > 0) {
Loggers.EVT_LOG
.info("{} {SYNC} {IP-DEAD} cluster: {}, dead ips size: {}, content: {}", getService().getName(),
getName(), deadIPs.size(), deadIPs);
for (Instance ip : deadIPs) {
HealthCheckStatus.remv(ip);
}
}
// ====================================== 数据修改结束 ========================================================
// 将修改后的数据复制给toUpdateInstances
toUpdateInstances = new HashSet<>(ips);
// 将上面做的执行修改操作后的数据集合赋值给初始数据集合
if (ephemeral) {
ephemeralInstances = toUpdateInstances;
} else {
persistentInstances = toUpdateInstances;
}
}















 1641
1641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









