







若你发现博客内容有误,请及时在评论中指出
在我们的程序中,通常都是通过池化技术来创建、管理比较昂贵的资源,比如线程池、连接池、内存池。一般都是预先存入,使用的时候直接取出,用完归还,是很方便的技术。
线程池的声明要手动声明
可能有部分的小伙伴在进入公司后,公司都会要求在 idea 装上《阿里巴巴开发手册的插件》,这里面就提到线程池的声明必须要手动声明,不能通过 Java 提供的 Executors 提供的 api 生成。一条规则的背后,是一件件血淋淋的生产事故。
我们先来看一下,newFixedThreadPool 的 OOM 问题。
我们写一段测试代码,我们来初始化一个单线程的 FixedThreadPool,循环 1 亿次向线程池提交任务,每个任务都会创建一个比较大的字符串然后休眠一小时:
// 这是多次用到的方法
private void printStats(ThreadPoolExecutor threadPool) {
Executors.newSingleThreadScheduledExecutor().scheduleAtFixedRate(() -> {
log.info("=========================");
log.info("Pool Size: {}", threadPool.getPoolSize());
log.info("Active Threads: {}", threadPool.getActiveCount());
log.info("Number of Tasks Completed: {}", threadPool.getCompletedTaskCount());
log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
log.info("=========================");
}, 0, 1, TimeUnit.SECONDS);
}
@Test
public void oom1() {
ThreadPoolExecutor threadPool = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
printStats(threadPool);
for (int i = 0; i < 100000000; i++) {
threadPool.execute(() -> {
String payload = IntStream.rangeClosed(1, 1000000)
.mapToObj(__ -> "a")
.collect(Collectors.joining("")) + UUID.randomUUID().toString();
try {
TimeUnit.HOURS.sleep(1);
} catch (InterruptedException e) {
}
log.info(payload);
});
}
}
这段代码执行一段时间后就会报错 OOM ,究其原因 newFixedThreadPool 方法中每次都 new 了一个新的 LinkedBlockingQueue,LinkedBlockingQueue 是一个 Integer.MAX_VALUE 长度的队列,可以认为是无界的
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
...
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}.
*/
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
...
}
虽然 newFixedThreadPool 可以将工作线程固定在一个数上,但是工作队列是无界的,如果线程任务又执行较慢的话,就会慢慢在工作队列中积压,最终撑爆内存的。
现在我们把方法换成 newCachedThreadPool,也会发生 OOM。
[11:30:30.487] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: unable to create new native thread] with root cause
java.lang.OutOfMemoryError: unable to create new native thread
newCachedThreadPool 的源码里线程数又是 Integer.MAX_VALUE, 而它的工作队列又是无界的,可以理解为每次来一个任务,都会创建一个线程。 所以当线程执行任务较长,一个线程为 1MB 的话就会导致内存再次被撑爆。
其实大部分的小伙伴都是知道这些 api 的特性的,只不过大部分都是抱有侥幸心理,“这里只是很简单的业务,随意配置一个线程池就好了”,但是每次出现线程池的问题基本上都是出现异常之后,也就是业务已经出现问题,线程池也没有什么良好的监控手段,所以大家还是尽量按照业务去配置自己的线程池。
线程池的配置策略
接下来,我们就利用这个方法来观察一下线程池的基本特性吧。
首先,自定义一个线程池。这个线程池具有 2 个核心线程、5 个最大线程、使用容量为 10 的 ArrayBlockingQueue 阻塞队列作为工作队列,使用默认的 AbortPolicy 拒绝策略,也就是任务添加到线程池失败会抛出 RejectedExecutionException。此外,我们借助了 Jodd 类库的 ThreadFactoryBuilder 方法来构造一个线程工厂,实现线程池线程的自定义命名。
然后每次间隔 1 秒向线程池提交任务,循环 20 次,每个任务需要 10 秒才能执行完成,代码如下:
@Test
public void watch() throws InterruptedException {
// 使用计数器跟踪任务完成数
AtomicInteger atomicInteger = new AtomicInteger();
// 创建线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
2, 5,
5, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10),
new ThreadFactoryBuilder().setNameFormat("demo-threadpool-%d").get(),
new ThreadPoolExecutor.AbortPolicy()
);
printStats(threadPool);
IntStream.rangeClosed(1, 20).forEach(i -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
int id = atomicInteger.incrementAndGet();
try {
threadPool.submit(() -> {
log.info("{} started", id);
// 每个任务耗时10s
try {
TimeUnit.SECONDS.sleep(10);
} catch (Exception e) {
}
log.info("{} finished", id);
});
} catch (Exception ex) {
//提交出现异常的话,打印出错信息并为计数器减一
log.error("error submitting task {}", id, ex);
atomicInteger.decrementAndGet();
}
});
TimeUnit.SECONDS.sleep(60);
log.info(String.valueOf(atomicInteger.intValue()));
}
最后看到输出:
15:54:03.852 [main] INFO com.xl.free.JavaApiTest - 17
并且日志也出现了3次的异常:
15:53:02.839 [main] ERROR com.xl.free.JavaApiTest - error submitting task 18
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@b684286 rejected from java.util.concurrent.ThreadPoolExecutor@5594a1b5[Running, pool size = 5, active threads = 5, queued tasks = 10, completed tasks = 2]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:112)
at com.xl.free.JavaApiTest.lambda$watch$4(JavaApiTest.java:78)
at java.util.stream.Streams$RangeIntSpliterator.forEachRemaining(Streams.java:110)
at java.util.stream.IntPipeline$Head.forEach(IntPipeline.java:559)
at com.xl.free.JavaApiTest.watch(JavaApiTest.java:70)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68)
at com.intellij.rt.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:33)
at com.intellij.rt.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:230)
at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:58)
我们把 printStats 方法打印出的日志绘制成图表,得出如下曲线:
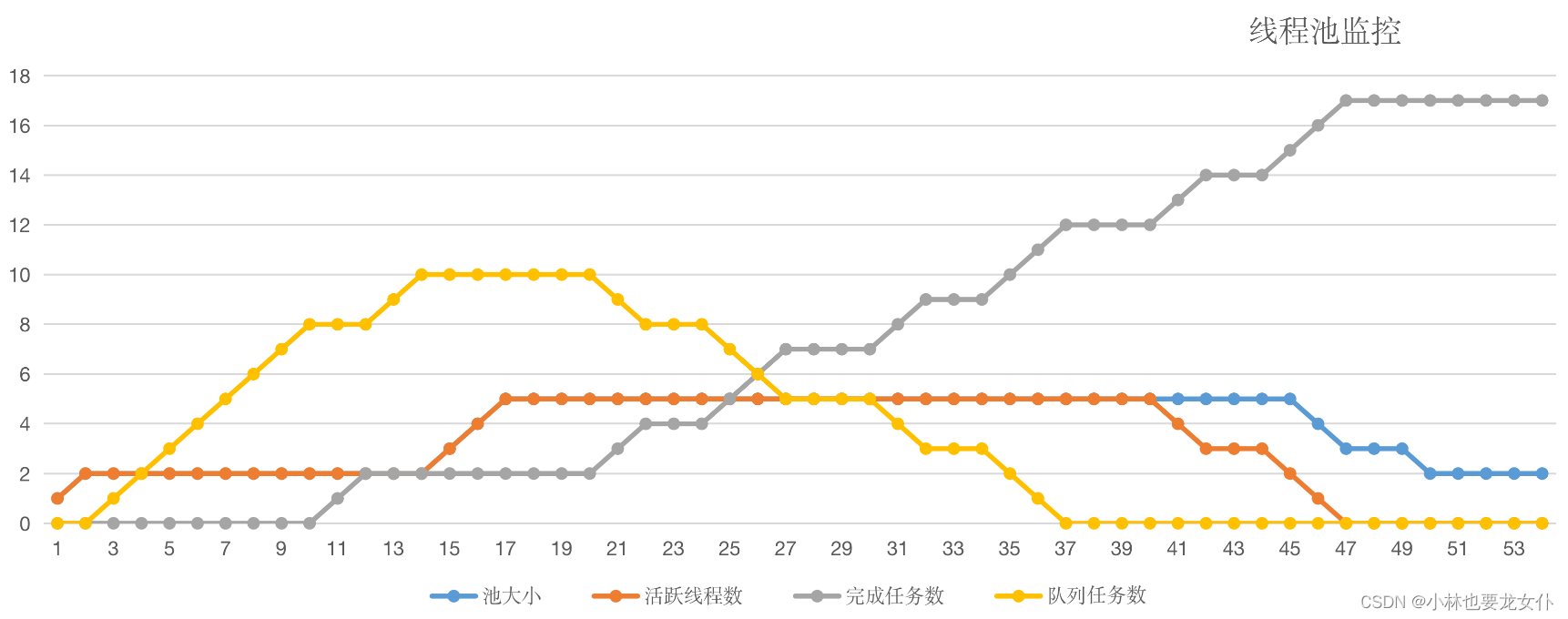
至此,我们可以总结出线程池的默认行为了:
- 不会初始化核心线程池数,也是有任务来了才会创建线程
- 当核心线程数满了之后不会立即扩容到最大线程数,而是将任务递交给任务队列
- 任务队列满了之后才会创建额外线程数,直到线程数达到最大线程数量
- 如果队列已满且达到了最大线程后还有任务进来,按照拒绝策略处理
- 当线程数大于核心线程数时,线程等待 keepAliveTime 后还是没有任务需要处理的话,收缩线程到核心线程数
了解线程池的行动后,有助于我们根据实际的容量规划需求,为线程池设置合适的初始化参数。当然,我们也可以通过一些手段来改变这些默认工作行为,比如:
- 声明线程池后立即调用 prestartAllCoreThreads 方法,来启动所有核心线程;
- 传入 true 给 allowCoreThreadTimeOut 方法,来让线程池在空闲的时候同样回收核心线程。
需要斟酌线程池的混用策略
通过前面的学习我们知道,要根据任务的“轻重缓急”来指定线程池的核心参数,包括线程数、回收策略和任务队列:
- 对于执行比较慢、数量不大的 IO 任务,或许要考虑更多的线程数,而不需要太大的队列。
- 而对于吞吐量较大的计算型任务,线程数量不宜过多,可以是 CPU 核数或核数 *2(理由是,线程一定调度到某个 CPU 进行执行,如果任务本身是 CPU 绑定的任务,那么过多的线程只会增加线程切换的开销,并不能提升吞吐量),但可能需要较长的队列来做缓冲。
题外话
你有没有想过,Java 线程池是先用工作队列来存放来不及处理的任务,满了之后再扩容线程池,那我们可不可以更加激进一些,先创建线程,直到达到最大线程数,再丢到任务队列内呢?
这是 stackoverflow 上一个国外友人提出的一个想法,如果你有兴趣的话可以看看:答案














 1513
1513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









