






puppeteer实现文件下载
puppeteer版本:
"puppeteer": "^20.7.3",
脚本需要的其他依赖
const axios = require('axios');
const FormData = require('form-data');
const fs = require('fs');
本脚本测试数据网站:https://unsplash.com/photos/GcBuJkuiCpU

1、设置文件存放地址
const downloadPath = "C:\\Users\\Administrator\\Desktop\\图片下载\\";
const client = await page.target().createCDPSession();
await client.send('Page.setDownloadBehavior', {
behavior: 'allow',
downloadPath: downloadPath
});
2、点击下载按钮(我这里测试使用的是免费图片网站)
await page.goto("https://unsplash.com/photos/GcBuJkuiCpU", {timeout: 60000})
const downloadBtn = await page.waitForSelector("#app > div > div:nth-child(3) > div > div:nth-child(1) > div.KeJv5.voTTC > header > div.EdCFo > div > div > a")
console.log("downloadBtn:", downloadBtn)
await downloadBtn.click()
如果不需要把下载的文件上传的话,到这一步就算完成了
3、获取文件名(监听所有的请求,如果文件名固定则不需要这个)
// 监听所有的请求
page.on('response', async (response) => {
const request = response.request();
const url = request.url();
const status = response.status();
const headers = response.headers();
// 在这里可以根据需要进行进一步处理
if (url.startsWith("https://images.unsplash.com")) {
console.log("找到符合预期的url")
console.log('url = ', url)
if (status === 200) {
const contentDisposition = headers['content-disposition'];
const fileNameMatch = contentDisposition && contentDisposition.match(/filename=["']?([^'"\s]+)["']?/i);
const fileName = fileNameMatch && fileNameMatch[1];
if (fileName) {
console.log('文件名:', fileName);
// 判断文件是否下载完成
const filePath = downloadPath + fileName;
let isFinish = false;
const now = Date.now();
while (!isFinish) {
await waitOneSecond();
// 如果有文件,且后缀满足我们的要求
if (fs.existsSync(filePath)) {
console.log('文件下载完成')
isFinish = true;
await closePage(page);
} else {
console.log('文件下载进行中')
}
// 如果文件超过10min还没下载成功,就抛出错误
if (!isFinish && Date.now() - now >= 10 * 60 * 1000) {
throw new Error('download file timeout');
}
}
// 记录一下耗时
console.log(`time spend: time=${Date.now() - now}`);
} else {
// await closePage(page);
console.log('无法获取文件名');
}
} else {
console.log('请求出错:', status);
}
}
});
4、测试
日志如下:
url = https://images.unsplash.com/photo-1495573925654-ebcb91667e78?ixlib=rb-4.0.3&q=85&fm=jpg&crop=entropy&cs=srgb&dl=craig-whitehead-GcBuJkuiCpU-unsplash.jpg
文件名: craig-whitehead-GcBuJkuiCpU-unsplash.jpg
文件下载完成
桌面上目录里面也有了
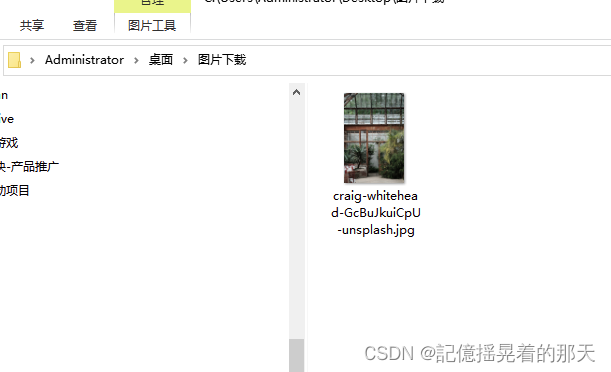
5、文件上传
function fileUpload(filePath) {
if (fs.existsSync(filePath)) {
console.log('文件下载完成');
const file = fs.createReadStream(filePath);
const formData = new FormData();
formData.append('file', file);
// 发起文件上传请求
axios.post('http://localhost:9091/crawleNPTO/upload', formData, {
headers: {
...formData.getHeaders(),
},
})
.then((response) => {
console.log('文件上传成功');
// 进一步处理上传成功的响应
})
.catch((error) => {
console.error('文件上传失败:', error);
// 处理上传失败的情况
});
} else {
console.log('文件不存在');
}
}
文件下载完成之后,在上传这个文件
// 如果有文件,且后缀满足我们的要求
const filePath = downloadPath + fileName;
if (fs.existsSync(filePath)) {
console.log('文件下载完成')
isFinish = true;
await closePage(page);
fileUpload(filePath)
} else {
console.log('文件下载进行中')
}
后端代码:
@PostMapping("upload")
public void upload(MultipartFile file) {
System.out.println(file);
if (file != null) {
System.out.println(file.getOriginalFilename());
System.out.println(file.getSize());
}
}
后端注意:MultipartFile默认文件最大为1MB,下面配置文件最大为100MB
spring:
servlet:
multipart:
max-file-size: 100MB
max-request-size: 100MB
测试日志:
org.springframework.web.multipart.support.StandardMultipartHttpServletRequest$StandardMultipartFile@173fcdc1
craig-whitehead-GcBuJkuiCpU-unsplash.jpg
5104533















 4280
4280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









