






1.部署中需要的东西
1.Prometheus (数据监控)
Prometheus 是一款基于时序数据库的开源监控告警系统,非常适合Kubernetes集群的监控。Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。Promethus有以下特点:
- 支持多维数据模型:由度量名和键值对组成的时间序列数据
- 内置时间序列数据库TSDB
- 支持PromQL查询语言,可以完成非常复杂的查询分析,对图表展示和告警非常有意义
- 支持HTTP的Pull方式采集时间序列数据
- 支持PushGateway采集瞬时任务的数据
- 支持服务发现和静态配置两种方式发现目标
- 支持接入Grafana
2.数据采集
node-exporter、alertmanager_exporter、mysqld_exporter等,此类软件是开源的Prometheus数据采集软件。例: Node Exporter 是一个开源的 Prometheus 客户端软件,用于收集和导出 Linux 系统的各种指标数据。 它可以提供关于 CPU 使用率、内存占用、网络流量等方面的数据。 而在本文中,我们将重点关注磁盘 I/O 相关的指标。
3.grafana(数据展示)
Grafana是一个用Javascript写的开源的(Dashboard)可视化面板,能齐全的度量仪表盘和图形编辑器和漂亮的布局展示,并且支持Graphite、elasticsearch、zabbix等的数据可视化的实现,可以给你的数据换个皮肤,使你的数据展示更加直观和漂亮。
4.Alertmanager(告警推送)
Alertmanager是一个独立的告警模块,接收Prometheus等客户端发来的警报,之后通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;告警方式可以按照不同的规则发送给不同的模块负责人,Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
梳理一下流程:Prometheus监控来自----xxxx_Exporter采集到的数据----并展示到grafana形成看板-----同时Prometheus又把生产的告警推送给Alertmanager---再通过Alertmanager推送给我们的企业微信
2.开始部署
1.下载镜像
1.Prometheus镜像
# 数据监控 # docker search prometheus # docker pull bitnami/prometheus2.node-exporter镜像
# 主机数据采集 # docker search node-exporter # docker pull prom/node-exporter3.alertmanager镜像
# 告警推送 # docker search alertmanager # docker pull prom/alertmanager4.webhook-adapter镜像
# 开源镜像 # docker pull guyongquan/webhook-adapter5.grafana镜像
# 数据展示 # docker search grafana # docker pull grafana/grafana
2.部署Prometheus
1.创建配置文件目录
新建prometheus目录,编辑配置文件prometheus.yml
1.# mkdir /data/prometheus 2.# mkdir /data/prometheus/rules 3.# cd /data/prometheus/ 4.# vim prometheus.yml在prometheus.yml中编辑下面内容:
global: scrape_interval: 15s evaluation_interval: 15s alerting: alertmanagers: - static_configs: - targets: - 192.168.1.202:9093 # 配置alertmanagers的IP和端口 rule_files: - "rules/*.yml" # 文件夹rules需要和prometheus.yml在同级目录,这里存放告警触发规则文件 scrape_configs: - job_name: prometheus static_configs: - targets: ['localhost:9090'] labels: instance: prometheus # 配置Prometheus的主机地址,默认端口9090 # 云服务器部署ip填写内网ip - job_name: node-exporter # 此处添加了多台主机,每台主机都要安装node-exporter static_configs: - targets: ['192.168.1.202:9100'] labels: instance: localhost - targets: ['192.168.1.193:19100'] labels: instance: 192.168.1.193 - targets: ['192.168.1.181:9100'] labels: instance: 192.168.1.181 - targets: ['192.168.1.182:9100'] labels: instance: 192.168.1.182 - targets: ['192.168.1.203:9100'] labels: instance: 192.168.1.203 - job_name: 'alertmanager_exporter' static_configs: - targets: ['192.168.1.202:9093']
2.配置触发告警规则的yml文件,文件存放在/data/prometheus/rules
1.配置实例存活告警规则
# vim node_alived.yml
#后面备注,可以自行去掉 groups: #规则组定义开始标志 - name: 实例存活告警规则 #组名,规则组名称定义 rules: #规则定义的开始标志 - alert: 实例存活告警 #告警规则名称 expr: up == 0 #表达式,告警触发条件表达式,表示如果实例的up指标等于0,即不可达或不存活,则触发告警 for: 1m #持续时间。表示持续1分钟获取不到信息,则触发警报。0表示不使用持续时间。 labels: #告警级别和用户等信息标签定义 user: prometheus #创建告警规则的用户标签的定义,这个告警规则是Prometheus创建的 severity: warning #告警级别标签的定义,此处告警级别定义为警告 annotations: #告警摘要和详细描述的定义 summary: "主机宕机 !!!" #告警摘要定义 description: "该实例主机已经宕机超过一分钟了。" #告警详细描述定义2.配置内存报警规则
# vim memory_over.yml
groups: - name: 内存报警规则 rules: - alert: 内存使用率告警 expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 90 for: 1m labels: severity: warning annotations: summary: "服务器可用内存不足。" description: "内存使用率已超过90%(当前值:{{ $value }}%)"3.配置cpu报警规则
# vim cpu_over.yml
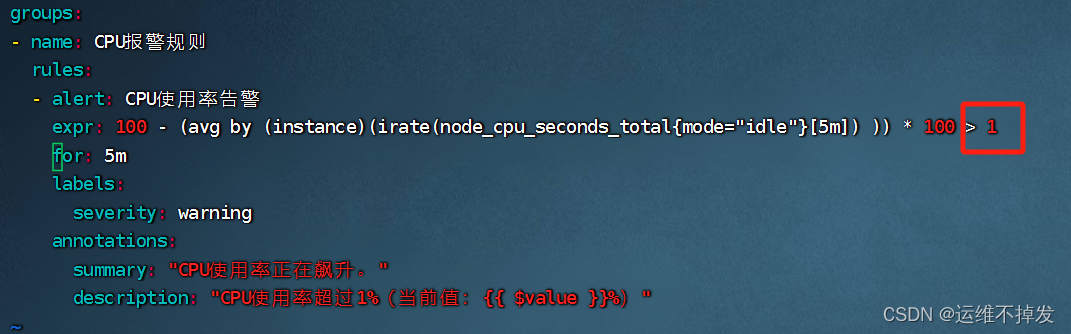
groups: - name: CPU报警规则 rules: - alert: CPU使用率告警 expr: 100 - (avg by (instance)(irate(node_cpu_seconds_total{mode="idle"}[5m]) )) * 100 > 90 for: 1m labels: severity: warning annotations: summary: "CPU使用率正在飙升。" description: "CPU使用率超过90%(当前值:{{ $value }}%)"4.配置磁盘使用率告警规则
vim disk_over.yml
groups: - name: 磁盘使用率报警规则 rules: - alert: 磁盘使用率告警 expr: 100 - node_filesystem_free_bytes{fstype=~"xfs|ext4"} / node_filesystem_size_bytes{fstype=~"xfs|ext4"} * 100 > 90 for: 20m labels: severity: warning annotations: summary: "硬盘分区使用率过高" description: "分区使用大于90%(当前值:{{ $value }}%)"注:告警规则可以按照上面的代码进行修改
3.在docker中运行Prometheus
docker run -d --name prometheus --restart=always -p 9090:9090 -v /data/prometheus:/etc/prometheus bitnami/prometheus-d 表示后台运行。
--name 给这个运行的容器命名。
--restart 重启。
-p 开放端口,宿主机端口:容器端口。
-v 挂载点 宿主机路径:容器路径。
1.查看容器是否启动成功
# docker ps | grep prometheus # netstat -nltp | grep 9090
2.网页访问一下
出现这个界面说明prometheus已经成功运行

2.部署node-exporter
1.安装node-exporter
docker run -d --name node-exporter --restart=always -p 9100:9100 -v "/proc:/host/proc:ro" -v "/sys:/host/sys:ro" -v "/:/rootfs:ro" prom/node-exporter2.查看端口
netstat -nltp | grep 9100
3.网页访问测试
这样就可以确认运行成功了
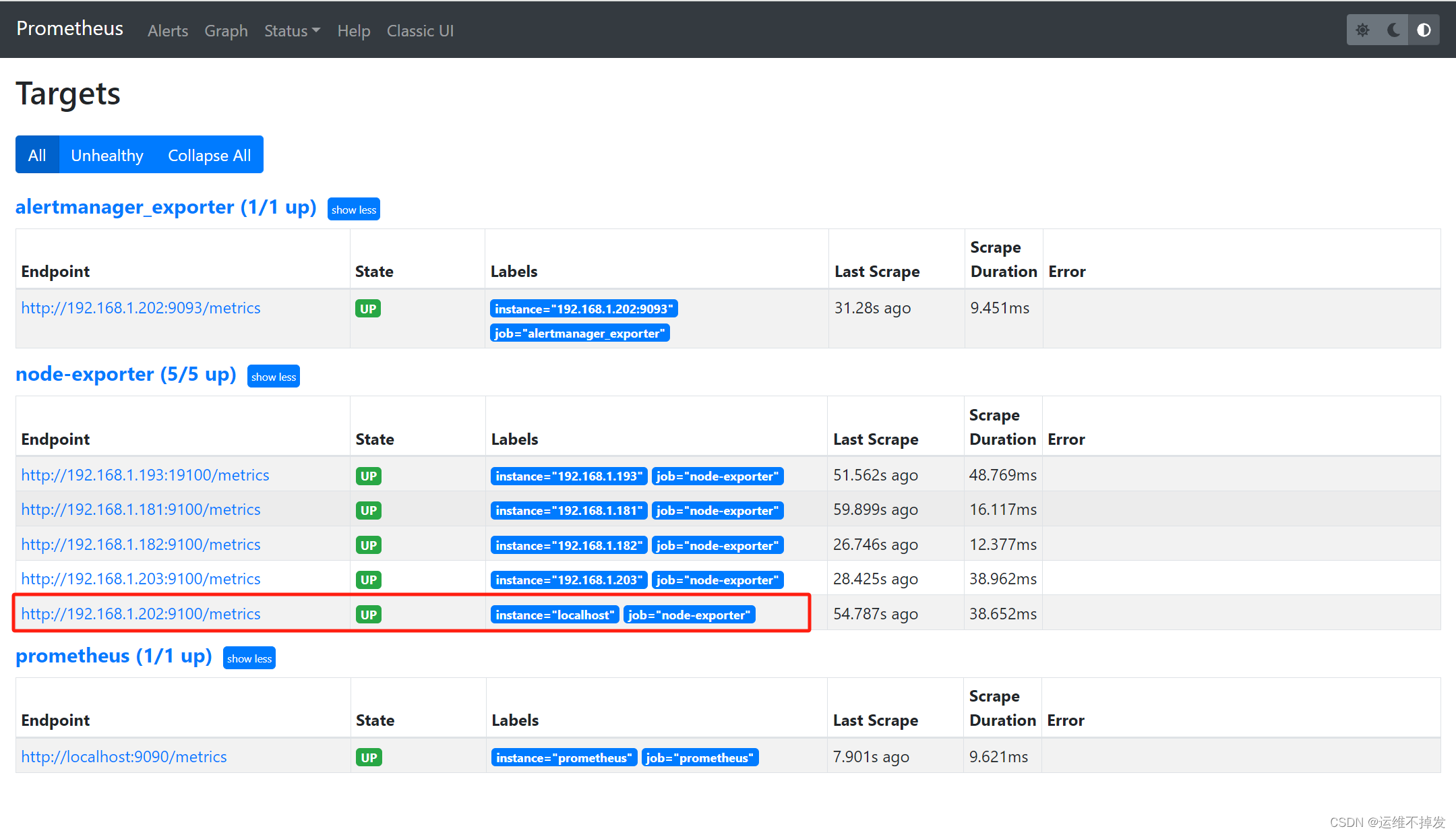
4.查看Prometheus
注:可以看到主机已经添加成功,如果需要添加多个主机,在需要监控的主机中安装node-exporter,并修改Prometheus的配置文件(/data/prometheus/prometheus.yml),添加新加的主机ip和node-exporter端口。

3.部署Grafana
1.安装grafana
docker run -d --name grafana --restart=always -p 3000:3000 --name=grafana -v /data/grafana:/var/lib/grafana grafana/grafana2.查看端口
netstat -nltp | grep 30003.页面配置
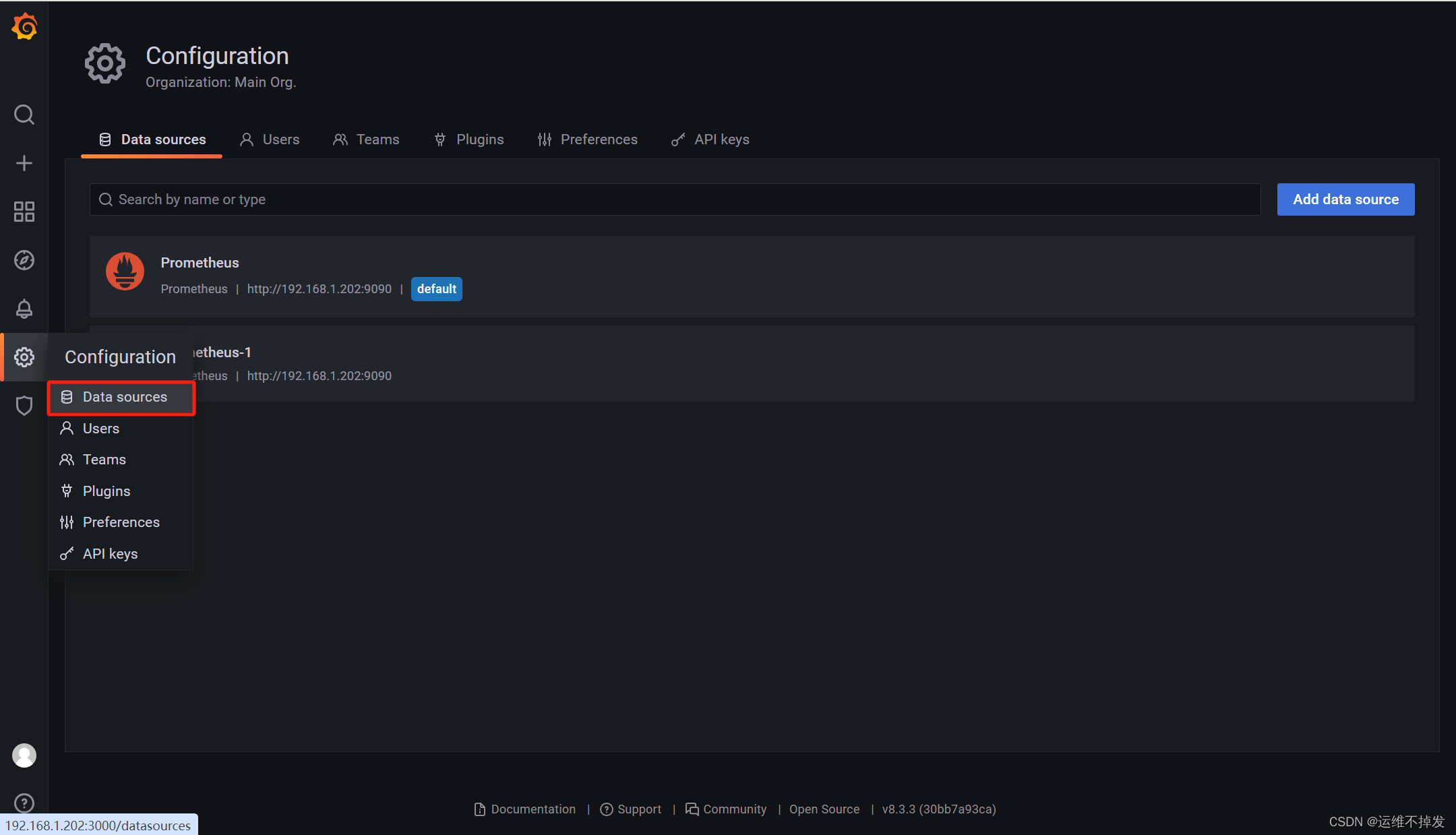
可以访问一下界面说明grafana运行成功了,找到Configuration-- Data sources--Add data source,选择Prometheus
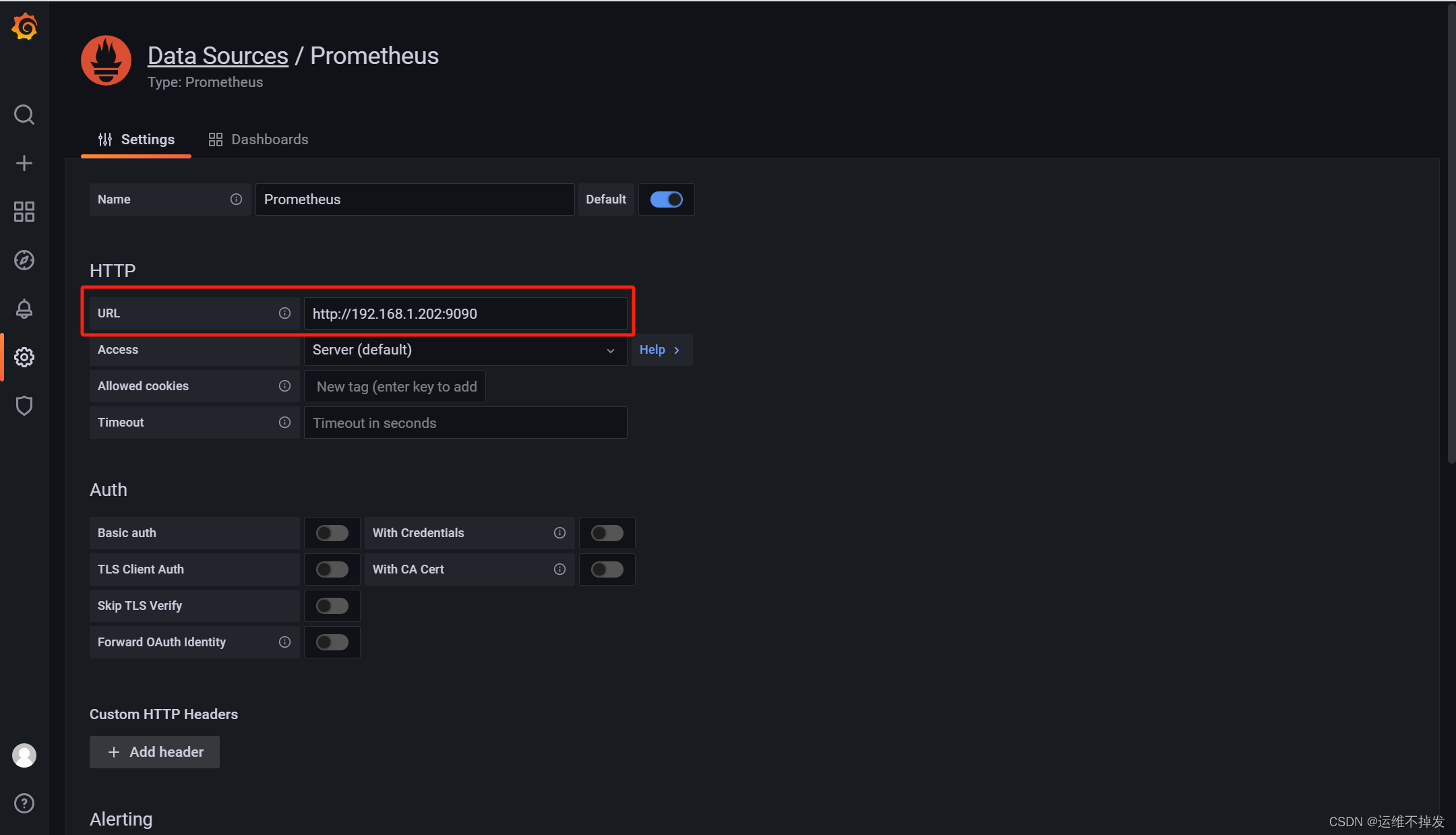
配置Prometheus的地址,其他不用改动,配置好直接save&test
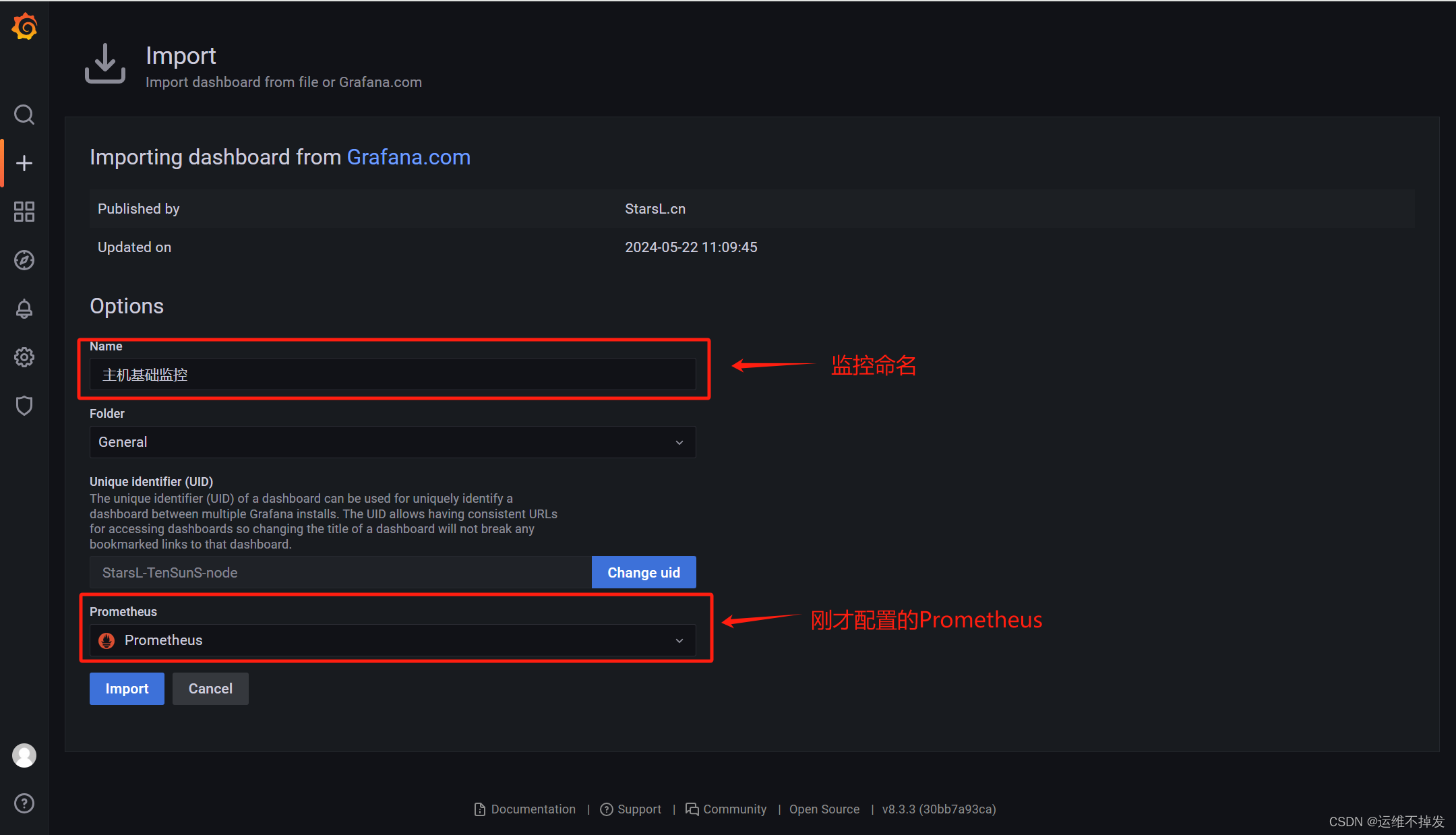
添加监控模板,这里使用的是8919,其他模板可以去官网找。
模板地址:Dashboards | Grafana Labs
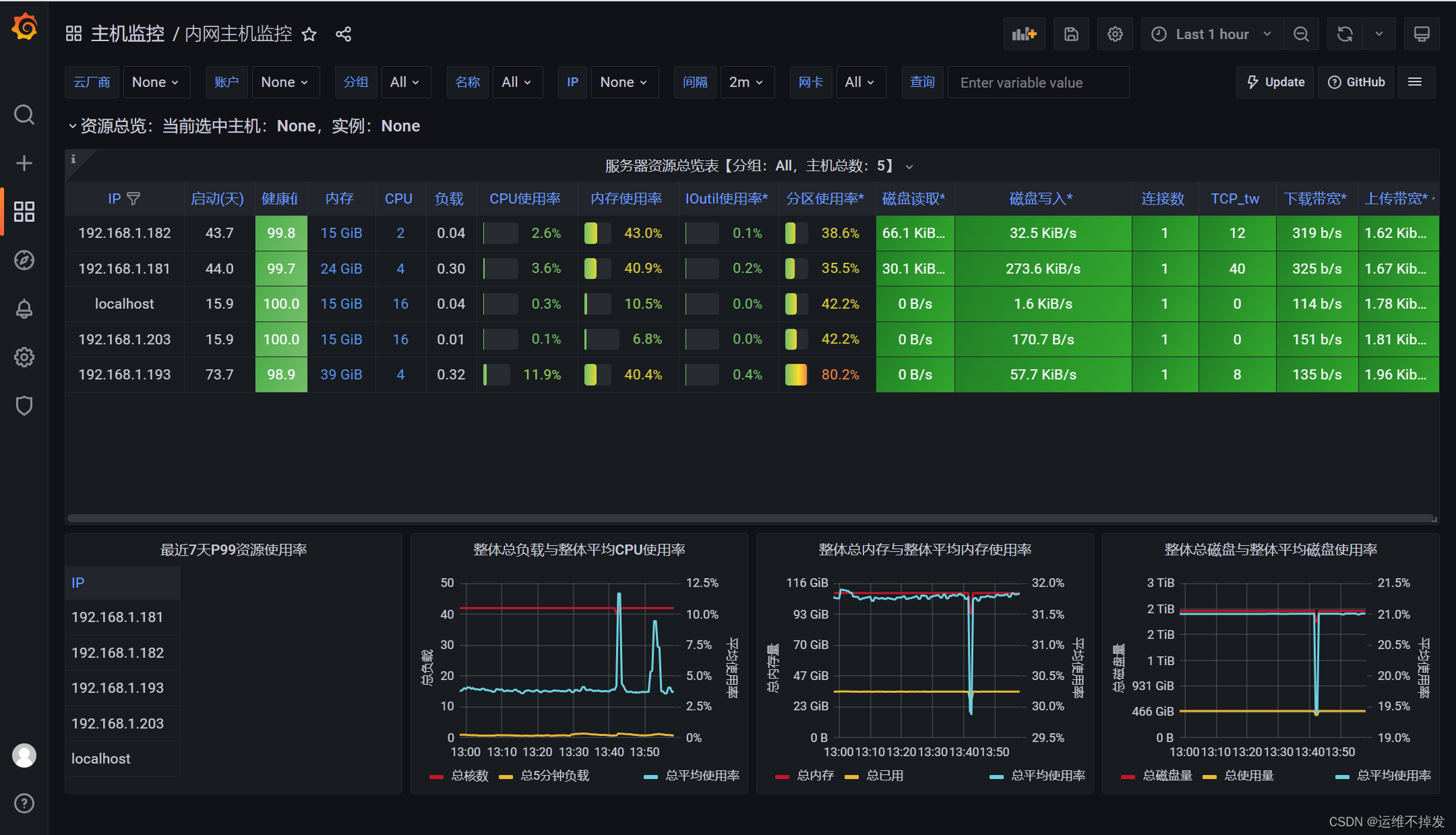
在home页面就可以看到你多配置的监控了
4.配置企业微信告警
1.编辑Alertmanager配置文件
新建alertmanager目录,编辑配置文件alertmanager.yml文件
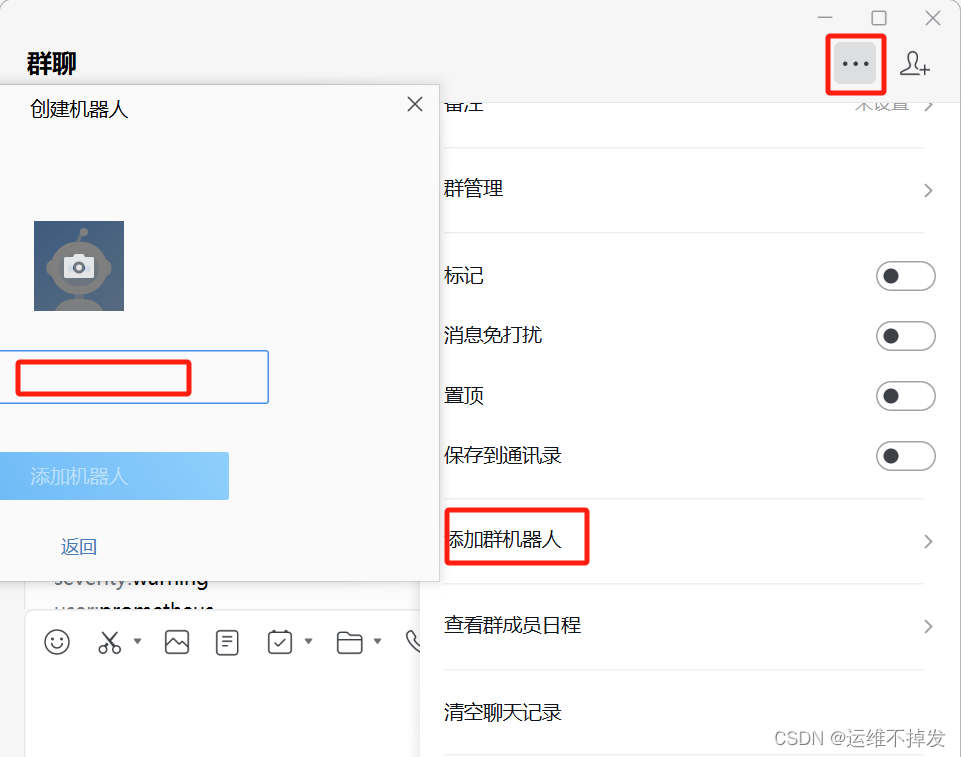
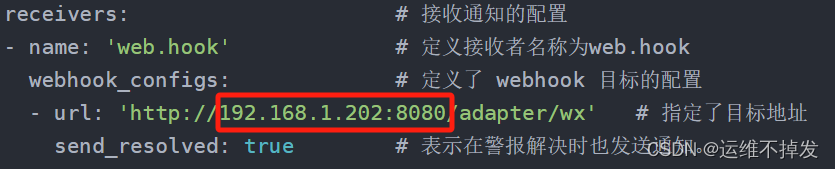
# vim /data/alertmanager/alertmanager.yml # 添加以下内容 global: # 指定了全局配置 resolve_timeout: 5m # 表示在警报解决之前等待的最长时间为5分钟 route: # 定义告警发送规则 group_by: ['alertname'] # 按照alertname进行分组,也就是相同警报名称的警报将会被分到一组。 group_wait: 10s # 表示在同一组内等待来自不同实例的所有警报。 group_interval: 10s # 表示在发送多个通知之间等待的时间。 repeat_interval: 5m # 表示对于未解决的警报,重复发送通知的间隔。 receiver: 'web.hook' # 表示接收到的警报将会被发送到名为web.hook的接收者 receivers: # 接收通知的配置 - name: 'web.hook' # 定义接收者名称为web.hook webhook_configs: # 定义了 webhook 目标的配置 - url: 'http://192.168.1.202:8080/adapter/wx' # 指定了目标地址 send_resolved: true # 表示在警报解决时也发送通知。 inhibit_rules: # 降低告警收敛,减少报警,发送关键报警。 - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']2.创建企业微信机器人
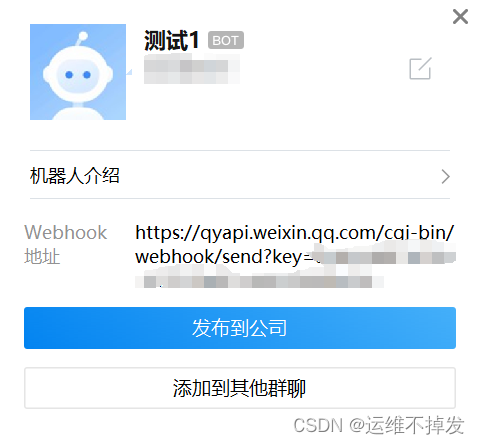
注意:机器人的webhook地址要复制保存下来
3.部署webhook
docker run -d --name wechat \ --restart always -p 8080:80 \ guyongquan/webhook-adapter \ --adapter=/app/prometheusalert/wx.js=/wx=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxxxxxxxxx #自己企业微信机器人的key4.部署Alertmanager
此处修改为webhook服务IP和端口
在Docker容器中运行Alertmanager
docker run -d --restart=always \ --name=alertmanager \ -p 9093:9093 \ -v /data/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml \ prom/alertmanager访问ip:9093出现下面页面就说明成功了
然后把所部署的服务都重启一遍
# docker restart #容器id5.告警测试
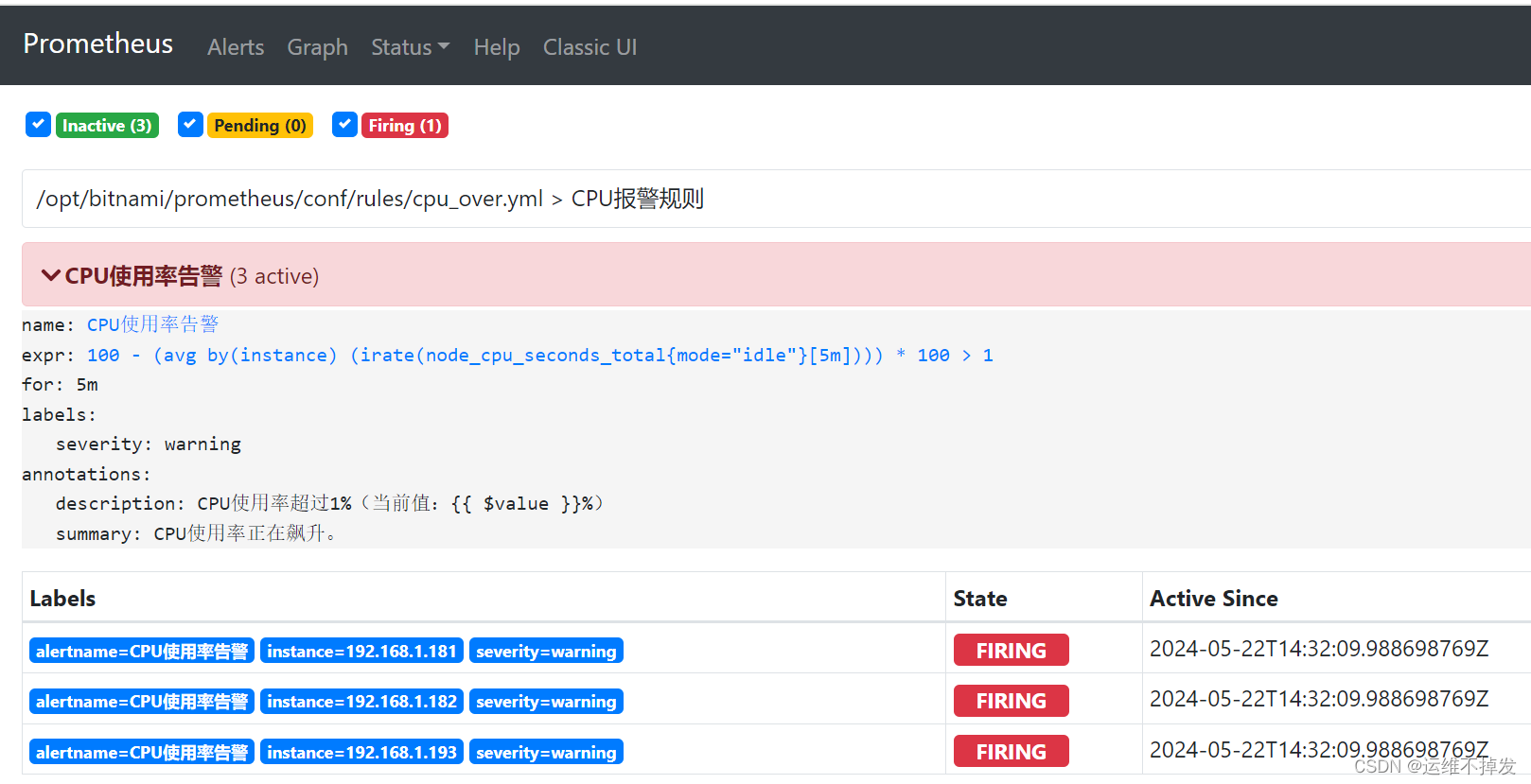
修改告警触发规则文件,调小阈值
修改配置后,重启Prometheus容器
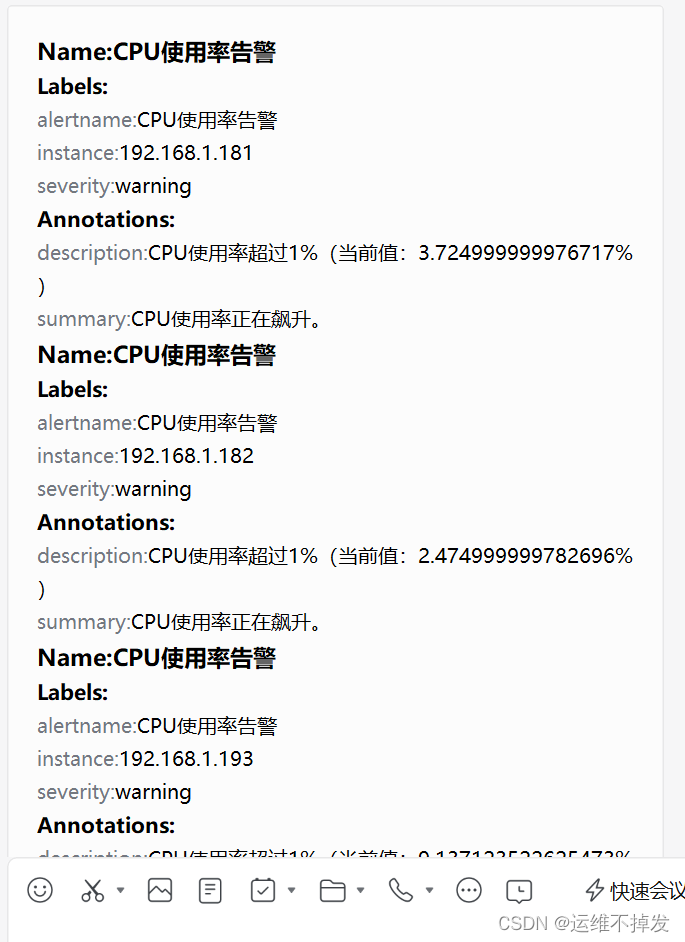
告警已经发送到企业微信















 4007
4007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









