






一、实验目的
爬取国家药监局(化妆品生产许可信息管理系统服务平台 (nmpa.gov.cn))化妆品生产明细(具体到每家企业的具体信息),当我们进入该网站首页时,发现其结构为每页15条的json类型数据。如图以下简称首页:
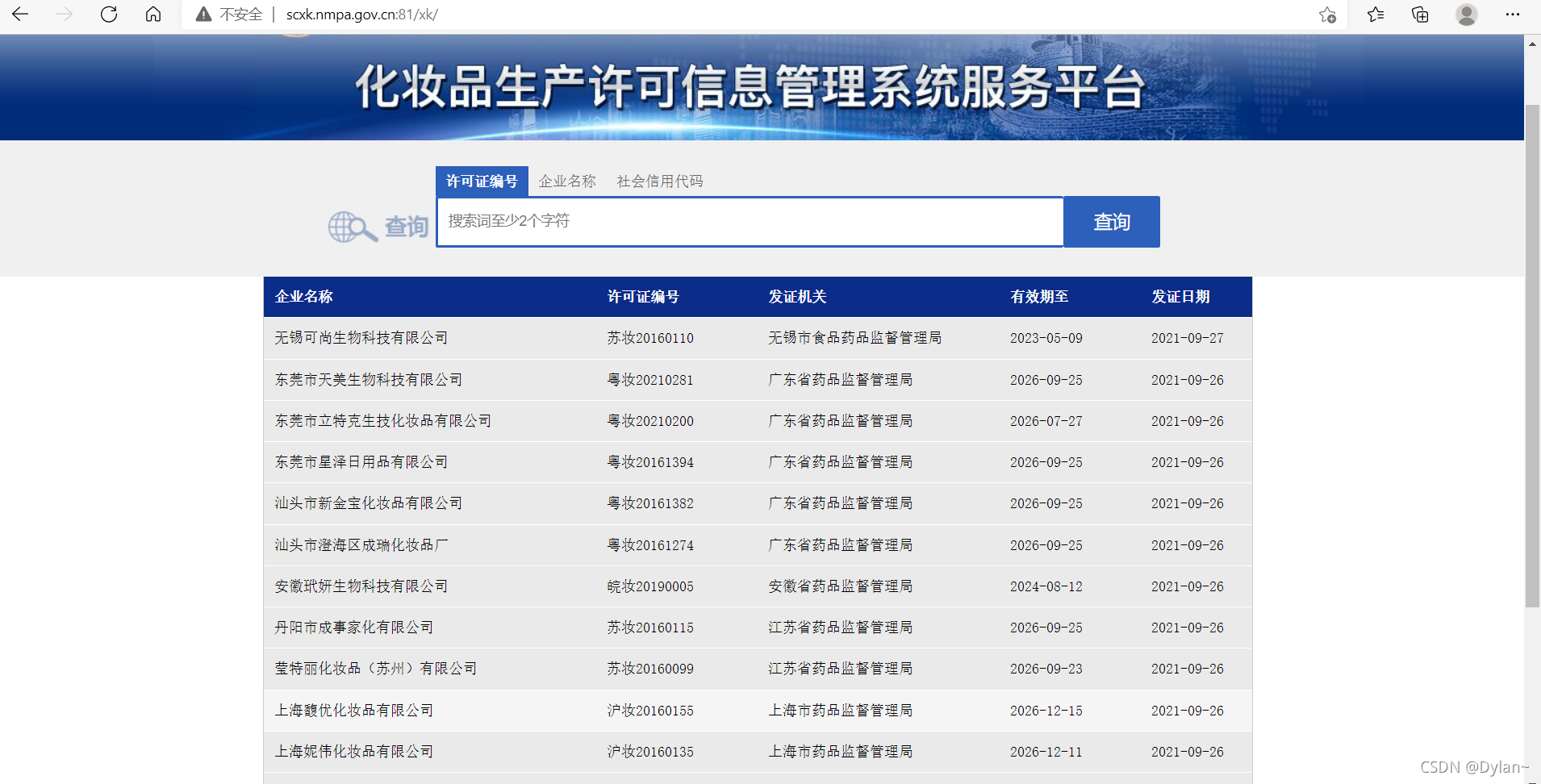
点开企业名称对应的超链接跳转到我们需要爬取的页面,以下简称详情页:

我们需要爬取详情页 上所有信息存为json格式到本地。
二、获取动态加载数据的URL
我们首先通过爬取首页信息验证是否可以通过爬取每条企业数据的超链接,再请求访问超链接数据来实现实验目的,打开开发者模式,找到首页url对应的页面:
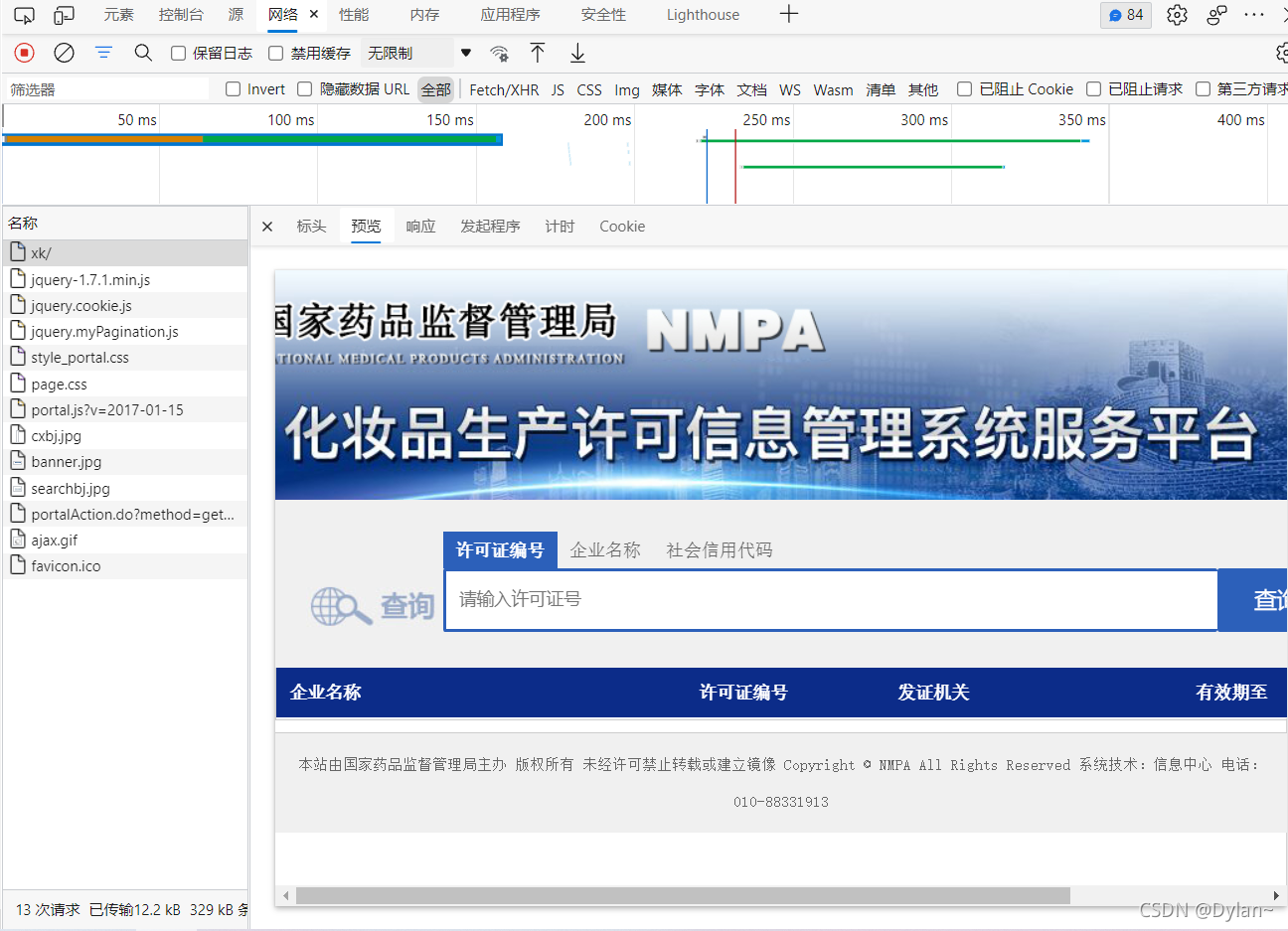
发现该页面并不存在企业超链接,说明该页面上的信息属于动态加载数据,即首页url与动态加载链接的url不同,需要找到动态加载数据对应的url。
通过抓包工具打开该动态加载数据的详情:
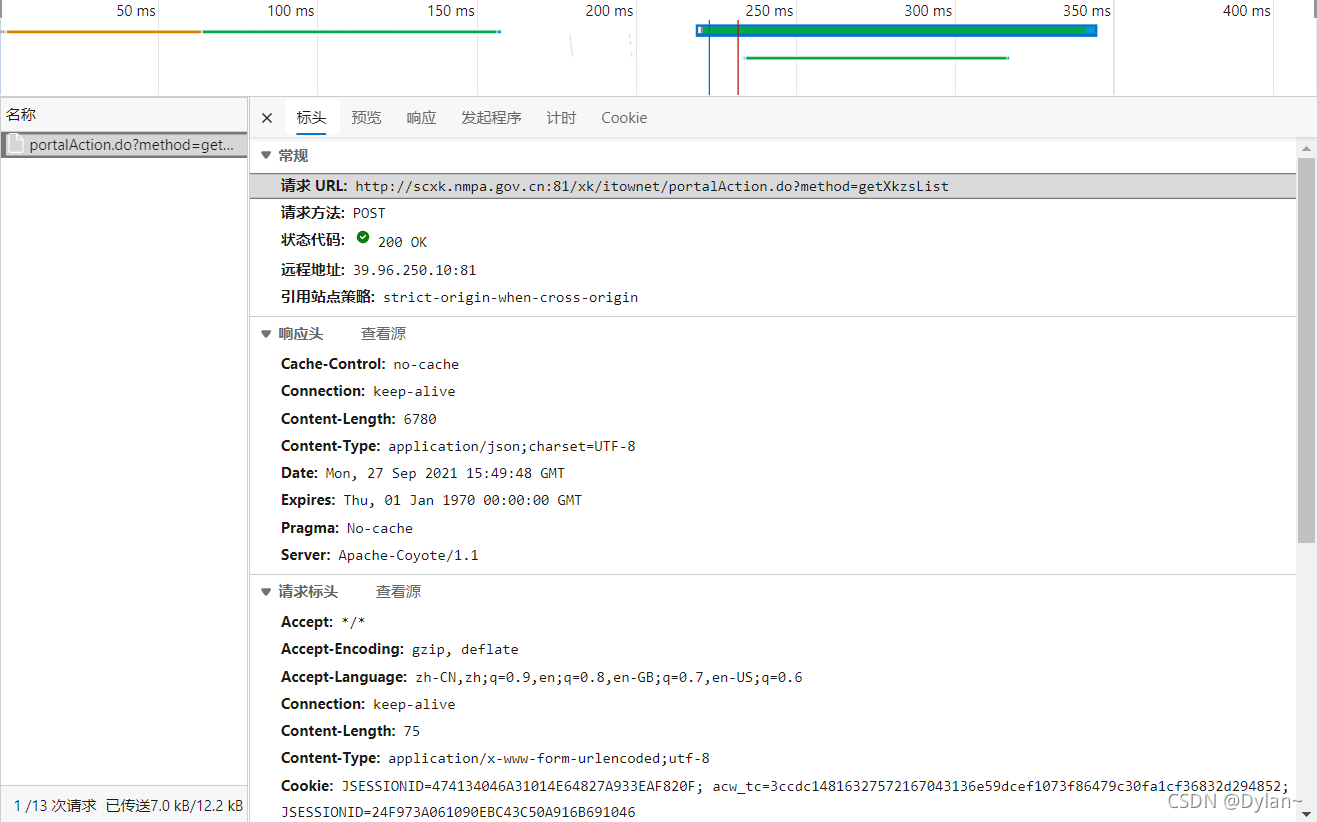
发现其对应的动态url为:http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList
数据格式为:json
请求方式为:post
其动态数据的结构为: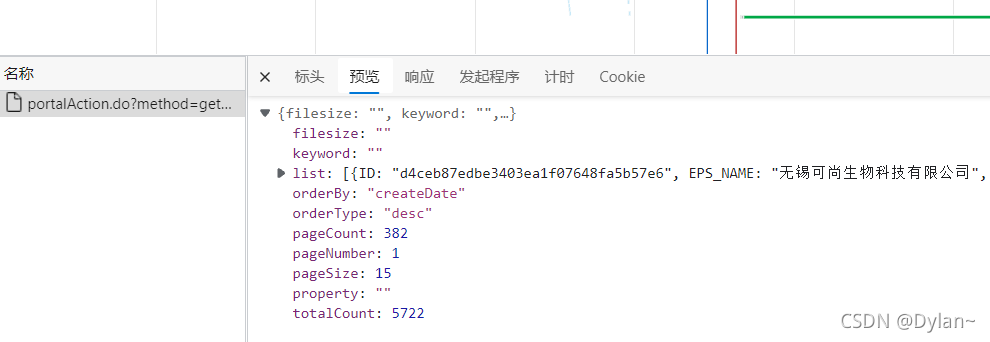
一个页面为一个大字典,其值为一个列表,列表中包含了15个小字典,每一个小字典对应每一页的15条企业信息,当我们打开详情页利用之前的验证方法,发现详情页中的信息也是动态加载数据,不可以直接爬取,所以利用抓包工具找出其第一家企业的动态加载信息所对应的url:
中华人民共和国化妆品生产许可证 (nmpa.gov.cn),其结构为动态url加每个企业的唯一标识符企业id。所以我们的实验思路转化为将首页的企业id爬取后再拼接到详情页的动态url上再进行遍历请求新url对应的具体信息,而企业id就被嵌套在首页结构中的字典中:

三、代码实现
在明确爬取思路之后,我们开始代码实践 ,附上注释:
#项目目的爬取国家药监局中关于化妆品生产许可相关数据
#该网页相关数据包括:企业名称、许可证编号、有效期等。。#最终需要爬取每家企业的详细信息(详情页)---动态加载出的数据(不可直接由当前页面的url解析出来)
#爬取思路:先爬取主页数据再定位到主页各企业名称对应的超链接(通过首页爬取每家企业对应的超链接url) 再对每个详情页超链接发请求
# 验证:用XHR来捕获动态数据包查看动态数据的数据结构与类型
import requests
import json
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
} #反反爬机制:伪装成用户通过浏览器登陆
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
#参数的封装
for page in range(1,6):
page = str(page)
data = {
'on': 'true',
'page': page, #当点第几页
'pageSize': '15', #该页有15条数据
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':'',
}
# 将发请求与获取响应数据合并起来 获取到的是带有企业id的字典类型的json数据
json_ids = requests.post(url=url,headers=headers,data=data).json()#对url发起访问请求;通过post()方法获取请求页面信息,以.json的数据形式。
print(json_ids)
id_list = [] # 存储企业的id
all_data_list = [] # 存储所有的企业详情数据(存入15个字典)
# 批量获取不同企业的id值(企业详情页url=原url+企业id)统一的url+不同的参数
#该字典的值是一个列表(列表中的每一个小字典对应一个企业)
for dic in json_ids['list']: #遍历列表中的每一个字典并取出id数据
id_list.append(dic['ID'])
#获取企业详情数据
post_url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in id_list:
data = {
'id':id
}
detail_json = requests.post(url=post_url,headers=headers,data=data).json()
all_data_list.append(detail_json)
#print(detail_json)
#持久化存储all_data_list
fp = open('./Outcome.json','w',encoding='utf-8') #写入并保存数据
json.dump(all_data_list,fp=fp,ensure_ascii=False)
print('保存成功')此时爬取的json数据已经存储在当前路径下的Outcome.json 中,输出结果查看:



















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









