







一、缓存预热
-
概念: 缓存预热就是在系统启动前,提前将相关的缓存数据加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询实现被预热的缓存数据!
-
解决方案:

二、缓存雪崩
- 概念:缓存雪崩可以理解为原有缓存失效,新缓存还未到期间(例如:我们设置的缓存过期时间相同,统一时间大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库和CPU和内存产生巨大压力,严重的造成宕机影响。从而造成一连锁的反应,致使整个系统崩溃。
正常缓存的获取图:
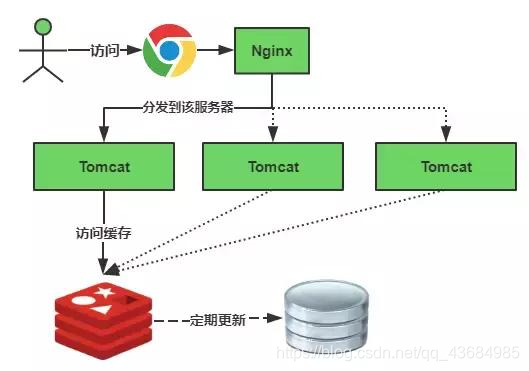
缓存失效瞬间:
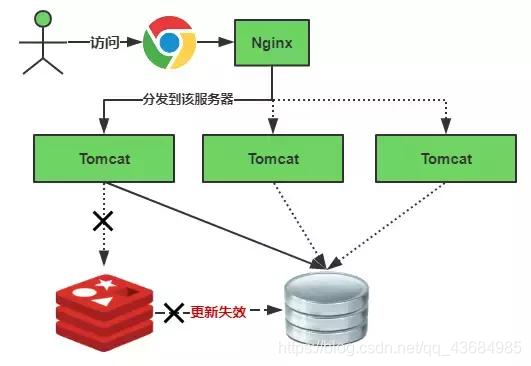
-
解决方案:



-
加锁方法详解:
(1)一般并发量不是特别高的时候可以通过 加锁排队 的方式来解决高访问量问题:
//伪代码
int cacheTime = 30; //缓存过期时间
String cacheKey = "product"; //缓存key
String lockKey = cahceKey;
public Object getProduct(){
String cacheValue = CacheHelper.get(cacheKey);
if(cacheValue!=null)
return cacheValue;
else{
synchronized(lockKey){
cacheValue = CacheHelper.get(cacheKey);
if(cacheValue!=null)
return cacheValue;
else{
//从数据库查询数据
cacheValue = GetDataFromDB();
//查询出的结果存入缓存
CacheHelper.AddCacheData(cacheKey,cacheValue,cacheTime);
}
}
return cacheValue;
}
}
注意:
- 加锁排队的方法只是为了减轻数据库压力,没有提高系统的访问量。假设此时有1000个用户请求访问但999个请求都被阻塞了,会导致用户请求访问超时。
- 加锁排队的解决方式分布式环境的并发问题,有可能还要解决分布式锁的问题;线程还会被阻塞,用户体验很差!因此,在真正的高并发场景下很少使用!
(2)给每一缓存数据设置缓存标记,用于记录缓存是否失效,如果缓存标记时效则后台开启线程刷新缓存:
int cacheTime = 30;
String cacheKey = "product";
//缓存标记
String cacheSign = cacheKey + "-sign";
public Object getProduct(){
String signValue = CacheHelper.get(cacheSign);
String cacheValue = CacheHelper.get(cacheKey);
if(signValue!=null) //未过期
return cacheValue;
else{
CacheHelper.AddCacheData(cacheSign,"1",cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//数据查询
cacheValue = GetDataFromDB();
//设置数据缓存过期时间为缓存标记过期时间的二倍
CacheHelper.AddCacheData(cacheKey,cacheValue,2 * cacheTime);
});
return cacheValue;
}
}
注意:
- 缓存标记用于记录缓存数据是否过期,当缓存标记失效时需要触发其余线程到后台更新数据缓存;
- 缓存数据过期时间设置为缓存标记的2倍,这样能够保证当标记过期后数据仍然能用,直到线程重新从数据库获取新的缓存值进行更新。
三、缓存穿透
-
概念:缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空(相当于进行了两次无用的查询)。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。黑客可以使用这个来攻击网络。
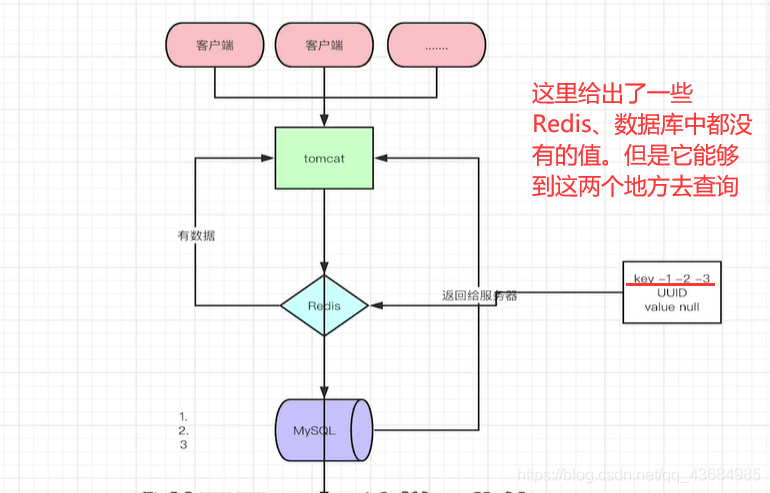
-
解决方案:

- Bloom filter(布隆过滤器)
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
原理:
当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在(之所以说“可能”是误差的存在)。
Bloom 过滤器操作流程:
- 首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
- 初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
- 某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中对应的比特位置为 1;
- 判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
我们知道Redis之所以快除了单线程避免了CPU上下文切换,采用了epoll机制,还有一个重要的问题是他的存储结构,时间复杂度是o(1),但是redis的存储空间是很珍贵的,过多的key对于redis来说是一件麻烦的事情,比如你有几亿个key,这种一股脑的丢到Redis,很不合理.Bloom Filter或许就是一种改善的解决方案,极大的减小了存储空间.布隆过滤器是一个位向量或者说是位数组。
但是对于布隆过滤器的使用一定要谨慎,Bloom过滤器比较鸡肋的地方是它存在一定的概率的误判,我们在学术上称他为假阳性,而且随着元素的增加,这种误判的机率会随着增加,但是误判的概率几乎可以忽略,影响不到,一般key不多的情况,用散列表就可以了,唯一的好处就是节省空间.目前它只支持add和isExist操作,不支持delete操作,这个理解它的原理的很容易明白,因为你删除更新那一位1,正好可能也是别的key的entry.
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>28.1-jre</version>
</dependenc>
- 如果一个数据返回为空,我们仍然将这个空值进行缓存,但是将它的过期时间设置很短,这样第二次访问时缓存中就有值了,不会继续访问数据库。
int cacheTime = 30;
String cacheKey = "product";
public Object getProduct(){
String cacheValue = CacheHelper.get(cacheKey);
if(cacheValue == null)
return cacheValue;
else{
//查询数据库
cacheValue = GetDataFromDB();
if(cacheValue == null)
cacheValue = string.Empty; //设置为默认值也缓存起来
CacheHelper.AddCacheData(cacheKey,cacheValue,cacheTime);
return cacheValue;
}
}
四、缓存击穿
- 概念:Redis中某个高热数据过期的瞬间,但是该数据的访问量巨大,多个数据请求压到Redis后均未命中,Redis在短时间内发起大量对数据库中同一数据的访问。
- 解决方案:

常用解决方案:
- 暂时设置热点数据永不过期;
- 加互斥锁,互斥锁代码参考如下(双重检查锁,参考单例模式):
public String getData(String key){
//从缓存中读取数据
String result = getDataFromRedis(key);
if(result == null){
//加锁
synchorized(this){
String result = getDataFromRedis(key);
if(result != null){
return result;
}
//从数据库获取数据
String result = getDataFromDB(key);
if(result != null){
//保存数据到Redis
saveDataToRedis(key,result);
return result;
}
}
}
}
五、缓存更新
-
概念:除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
(1)定期去清理过期的缓存;
(2)当有用户请求过来时,先判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到数据并进行数据更新;
六、缓存降级
- 概念:当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
- 降级的最终目的是为了保证核心业务功能可用,即使是有损的。有些服务是无法降级的(例如购物车、结算)。
(1)一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
(2)警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
(3)错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
(4)严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
五、性能指标监控
- 需要监控的指标
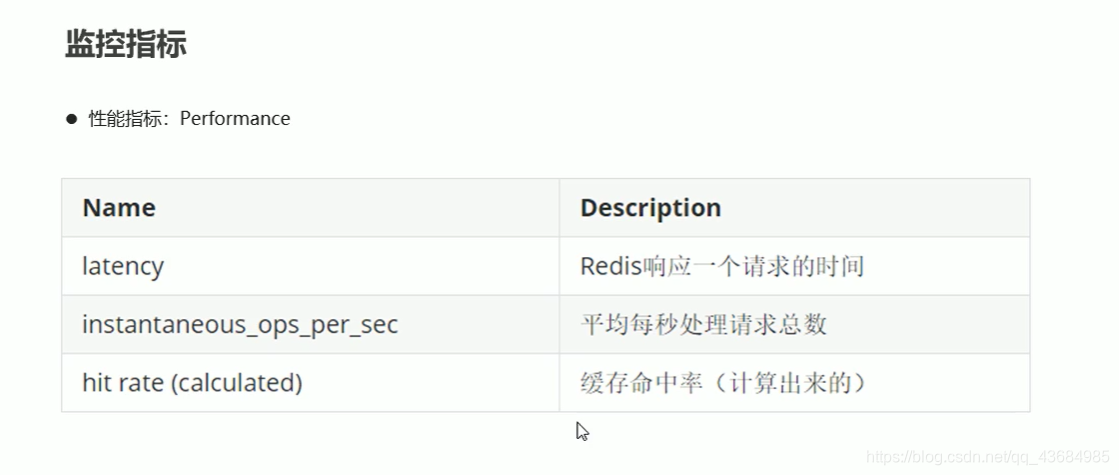
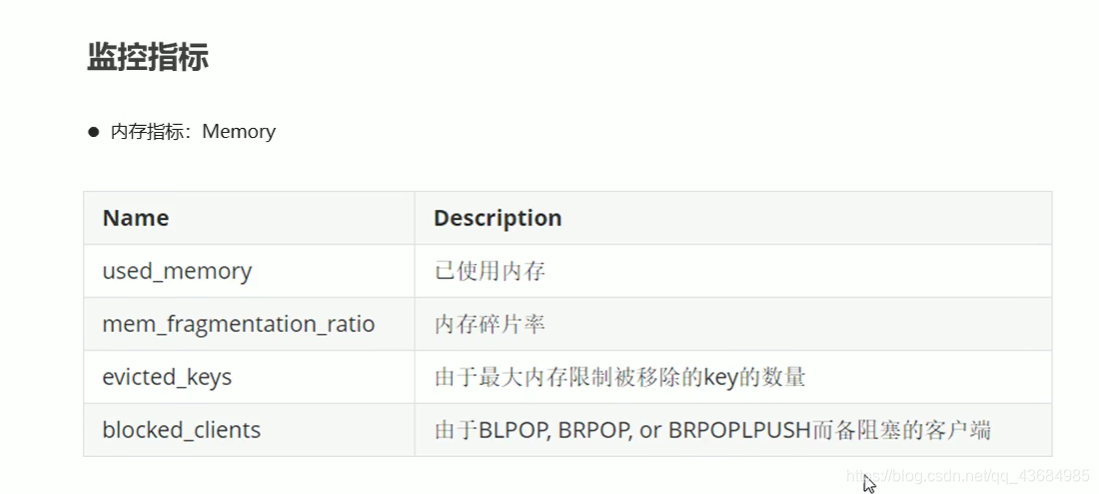
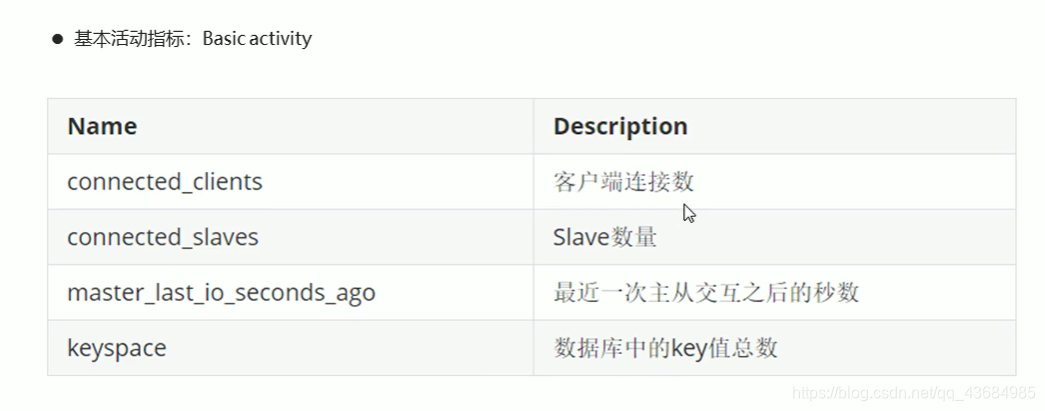

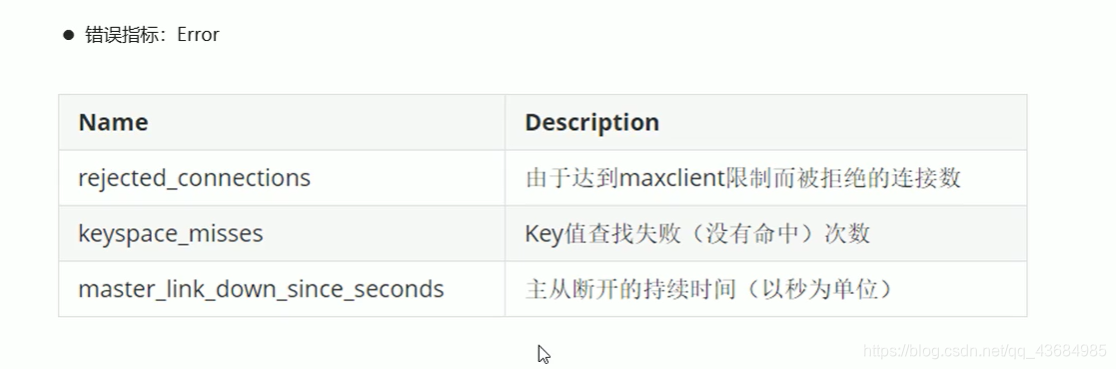
- 性能指标监控方法:















 836
836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









