






文章目录
- 一、谈一下Elasticsearch的理解?
- 二、Elasticsearch索引文档(不是修改是建立)与搜索的过程
- 三、并发情况下,Elasticsearch 如果保证读写一致?
- 四、Elasticsearch 应用上的问题汇总
一、谈一下Elasticsearch的理解?
1、Elasticsearch的基本概念
-
基本概念表(对标MySQL)
概念 描述 index索引 等同于MySQL的数据库,存储数据 type类型 等同于MySQL的表结构 document文档 等同于MySQL中的一行数据 Filed字段 Field是Elasticsearch的最小单位,一个document里面有多个field shard 分片 单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能; replica 副本 任何一个服务器随时可能故障或宕机,此时 shard 可能会丢失,因此可以为每个 shard 创建多个 replica 副本
2、什么是倒排索引?
-
Elasticsearch是一个分布式全文检索引擎,底层基于Lucene的
倒排索引技术,在底层采用了分段的存储模式,使它在读写时几乎完全避免了锁的出现,大大提升了读写性能,能够实现比关系型数据库更快的过滤与检索,可以近乎实时的进行存储与检索数据;索引结构 原理 优缺点 正排索引 传统的正排索引(forward index):是以文档ID (key)作为关键字,正排表中记录文档中每个词项(term)的出现次数与位置信息(value);
当搜索时,扫描表中的每个文档中的词项(term)信息,直到找出所有包含了查询关键字的文档,然后返回搜索结果;优点: 索引结构简单易维护,删除或建立某个文档索引非常方便;
缺点: 检索某个关键词时,需要遍历全部的文档,以确保没有遗漏,使得检索时间大大延长,检索效率低;倒排索引 倒排索引(invert index):以词项(term)作为关键字(key)进行索引,倒排表中记录出现了该关键字的文档ID(包括关键字的位置情况); 总结来说:就是把文档ID对应到关键词的映射,转换为了关键词到文件ID的映射;
当搜索某个关键词key时,
① ES首先会将搜索关键词进行分词(规范化和去重),切分成多个词项(term);
② 然后对于每个词项(term),查询得到对应的倒排表(Posting List);再对每个词项的倒排表进行合并或者取交集等操作,获得查询结果;
③ 最后对查询结果进行相关性打分 ,进行排序后返回搜索结果;优点: 查询的时候能够一次性查询到关键字对应的全部文档,查询效率比正向索引高的多;虽然倒排表不易建立与维护,但是这个过程是在后台进行的,因此不会影响整个搜索引擎的查询效率;
缺点: 倒排表不易建立与维护; -
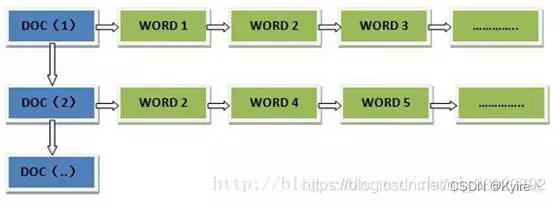
正排索引结构
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。
-
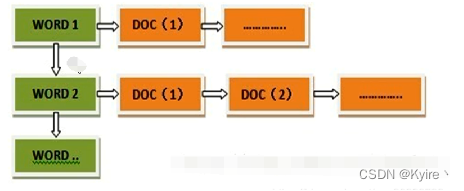
倒排索引结构
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。
3、什么是全文检索
-
全文检索与数据查询的区别
检索类型 定位 查询方式 相关度排序 数据结构 数据查询 数据查询侧重高效、安全的存储 普通的数据查询是SQL语句实现模糊查询(like),按照磁盘页的进行遍历查询,随机IO次数多,效率差; 有明确的查询边界条件,结果没有相关度排序 B+树 全文检索 全文检索侧重准确、方便的搜索 全文检索是直接定位关键词所在磁盘页的位置,然后直接读取; 全文检索对查询到的结果进行了相关性排序,没有明显的边界条件 FST(有限状态转移机),变种字典树,共享前缀也能共享后缀
4、为什么Elasticsearch/Lucene检索比MySQL快?
-
或者问为什么不用MySQL作为全文检索引擎?
MySQL Lucene 磁盘IO层面 Mysql只有term dictionary这一层,以B+树的数据结构存储在磁盘中,由于数据存储在B+树的叶子节点中,因此检索一个term词项需要若干次的随机磁盘IO,代价昂贵 Lucene底层基于倒排索引技术,在term dictionary的基础上添加了term index来加速检索,term index以树的形式(FST)缓存在内存中。首先在内存term index中查到对应的term dictionary的磁盘块block位置之后,再去磁盘上找term,大大减少了磁盘随机IO的次数; 数据结构层面 B+树(存储在磁盘) FST(存储在内存),一种变种字典树,不但能共享前缀还能共享后缀;不但能判断查找的key是否存在,还能给出响应的输出(posting list);他在时间复杂度与空间复杂度上都做到了最大程度的优化,使得Luence能够将term dictionary的信息完全加载到内存,以根据读内存快速的定位到term所在的磁盘block位置; 磁盘存储层面 磁盘页(16KB) 以磁盘块分block的形式进行存储,每个block内部利用公共前缀压缩,可以比b+tree更加节约磁盘空间 读写层面 多次随机磁盘IO 先读内存定位后,再去磁盘找,IO次数少 应用层面 ① 使用MySQL进行全文检索时,很容易因为左前缀原则等造成索引失效;
②使用MySQL进行全文检索的查询结果相关性差,并且无法与其它属性相关联;倒排索引技术,更快的查询,且能够通过倒排表posting list进行排序打分,能够给出相关性;
5、Elasticsearch/Lucene倒排索引技术?
-
倒排索引总结性回答
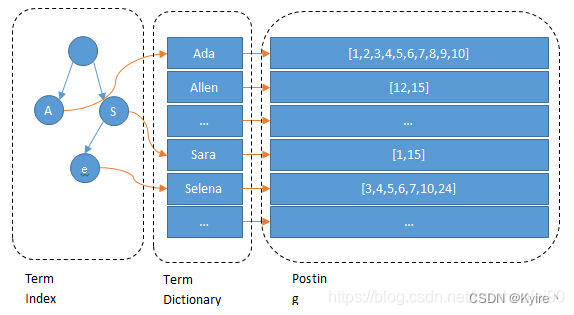
倒排索引结构 位置 优势 数据结构 Term Index
(词项索引)内存 作用: 提高检索速度,term index以变种字典树(FST)的数据结构在 内存中存储Term dictionary的信息;检索数据时,先从内存中读取Term在磁盘块中的位置,然后磁盘IO直接去读,大大减少磁盘IO次数FST(有限状态转移机),存储在内存中
① 一种变种字典树,不但能共享前缀还能共享后缀;不但能判断查找的key是否存在,还能给出响应的输出(posting list);
② 它在时间复杂度与空间复杂度上都做到了最大程度的优化,使得Luence能够将Term dictionary的信息完全加载到内存,以根据读内存快速的定位到Term所在的磁盘block位置;Term Dictionary
(词典)磁盘块(公共前缀压缩的block) 作用: 在磁盘中,以公共前缀压缩的block存储由字典序排序后的全部Term,可以用二分查找(logN)次磁盘查找得到目标Term,然后通过指针找到指向的Posting List; × Posting List
(倒排表)磁盘(FOR) / 内存(RBM) 作用: Posting List是一个int的数组,每个词项都对应着一个倒排表,其中存储着包含该词项的全部文档id集合
有了倒排表后,使得我们一次性能查得到包含该Term的全部文档id集合,无需像正排索引一样,遍历全部的文档,大大提高了检索的效率;1) 在磁盘中,Posting List 经过FOR压缩算法后,基于block(具体是比特位)存放的;
2) 若Posting List被缓存到了内存中,是以Roaring Bitmap的数据结构进行存储的;
① 当block中的元素(short)小于4096个时(即8kb = 65536个比特位)时,使用的数据结构是short[];
②当block中的元素个数小于4096个时,使用的数据结构是BitSet;
倒排索引结构:
6、具体介绍一下Posting List压缩算法?
-
1)为什么要压缩Posting List呢?
原因 解释 如何实现 节省磁盘空间与CPU ① 节省磁盘空间: 全文检索动辄亿万级别的数据,倒排表需要非常大的磁盘空间存储,利用FOR压缩算法可以大幅度的优化磁盘空间;
② 节省CPU: 由于block是根据公共前缀压缩的,因此有压缩成本,之前没有FOR算法压缩磁盘空间是,使用的block磁盘块多,压缩成本也就高;现在有了FOR磁盘压缩算法,使用的block就少了,压缩成本也就降低了,而且此时若结合跳表skip list的方法进行Posting List的合并与交集操作,不仅跳过了遍历的成本,也跳过了压缩这些block的成本,从而节省了CPUFOR压缩算法 内存缓存 考虑将经常被访问的热点Term对应的倒排表(Posting List)利用合适的数据结构(RoaringBitMap)缓存到内存中,直接读内存不读磁盘,加快全文检索效率 RoaringBitMap数据结构
-
2)Posting List压缩算法
层面 压缩方式 步骤 磁盘 FOR
(压缩算法)① 差值计算: 将Posting List按照升序排序后,相邻两个文档ID进行差值(delta)计算;
② 划分block: 将delta数字中的差值结果拆分为多个block,每个block有256个Doc Id;
③ bit编码存储: 计算每个block中最大的delta数字需要多少bit位进行存储;并且将最大bit位数放入block头部,使用该bit数来编码所有block内所有delta数字;内存 RoaringBitMap
(数据结构)核心压缩思想: 与其保存100个0,占用100个bit。还不如保存0一次,然后声明这个0重复了100遍;
① 将Postting List按照升序排序;
② 解压每个数字表示为(N / 65536,N % 65536);
③ 按照 N / 65536(高位) 进行划分block磁盘块,相同结果的划分到一个磁盘块中;
④ 将每个block进行编码:
1) 若block中元素个数小于4096个(稀疏),则用short[]进行保存(随着数据的增加占用的空间也增加);
2) 若block中元素大于4096个(稠密),则用bitSet(固定占8kb的空间,不随数据的增加而增加)进行保存;
-
2.1)FOR压缩算法(磁盘压缩)
本压缩算法是完全基于磁盘的,不需要任何内存。
为了高效对posting list 计算
交集和并集,需要posting list有序。排序后,我们就能利用有序性进行delta-encoding即差值压缩。其压缩方式叫做Frame Of Reference(FOR)编码。示例如下:
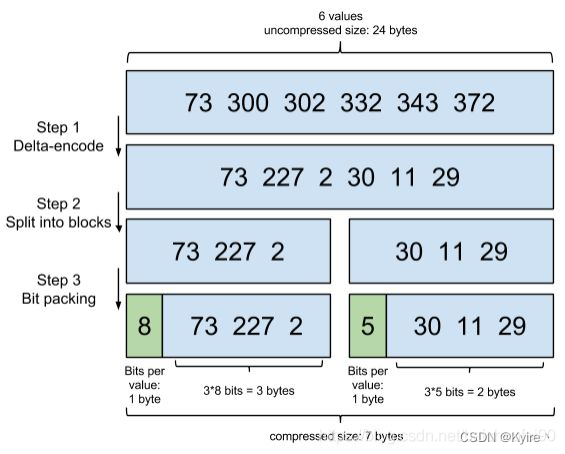
1、差值计算: 将数字计算差值存放2、划分 block: 将1中结果拆分为多个block,每个Block有256个Doc Id(示意图只画了3个方便展示),以便按各个Block最大值分别按不同bit数表示从而有效压缩
3、bit位编码: 根据最大值,比如第一个block最大值是227,则需要8个bit存放(2^8 = 256足够存放最大值227),所以每个值都用8bit存放就肯定够了;第二个block最大值30,需要5个bit存放(2^5 = 32足够存放最大值30),所以每个值都用5bit存放就肯定够了。将最大bit位数放入Block头部,然后使用该bit数来编码所有Block内所有delta数字。这就是所谓Frame Of Reference (FOR)。
-
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的posting list里就会有50万个int值。
用Frame of Reference编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。当然mysql b-tree里也有一个类似的posting list的东西,但是未经过这样压缩的。 -
举例说明FOR压缩: 对于73、300、302这3个数,原来73需要占用7个bit位(即128),300和302需要占用9个bit位(即512),分别存储他们一共需要25个bit位(4个Byte);经过FOR压缩后,先计算差值,得到0、227、2,他们被分到同一个block中,227是最大差值,那么227占用8个bit位(即256),那么就将8标记在该block磁盘头部,73和2都用8个bit位存储,只需要24bit位(3个Byte),数越大,压缩节省的空间越明显;
-
因为这个Frame of Reference的编码是有解压缩成本的。所以如果利用
skip list,除了跳过了遍历的成本,也跳过了解压缩这些压缩过的block的过程,从而节省了cpu。
-
为什么需要内存压缩?如何选择数据结构?
在全文检索中,存在很多关键词term对应的posting List是超级热点的,比如:“个”、“的”这种,因此Luence全文检索引擎
考虑将这个热点词汇在磁盘中对应的Posting List缓存到内存中,以加快检索效率;但是由于全文检索的数据是亿万级别的,可能对应的Posting List超级大,因此我们需要找到一个合适的数据结构来压缩这些数据,使得将Posting List缓存到内存这件事情变得可能。同时,考虑到联合查询,比如:查询
TremA and TermB或者TremA or TermB,因此如何高效的对Posting List进行取交集与取并集操作,也成为了一个需要考虑的问题。综上分析,我们需要
找到一个内存结构,具有以下两个特点:①
能够大幅度压缩Posting List的内存占用;
②能够高效的对Posting List进行取交集与取并集操作; -
根据以上分析,我们选择三种数据结构进行讨论:
数据结构 原理 优缺点 使用场景 BitMap BitMap底层是int(32bit),一个int就能放32个数 优点:
① 查询速度快,O(1)的查询复杂度;
② 节约空间,能够用少量空间存储大量的非重复数字;
缺点:
BitMap不适合存储稀疏数据,会超级浪费空间;比如,一个Posting List ={1,9999},为了表示这两个数,BitMap就需要用9999个bit位表示这两个数;与BitSet一致 BitSet BitSet底层是long(64bit),它实现了一个按需增长的位向量,位 set 的每个组件都有一个boolean值;两个BitSet之间可进行位运算(逻辑与、逻辑或、逻辑异或)等操作; 给BitSet1个GB的空间,能够大约存储85亿个数
优缺点:
与BitMap相比,能够快速的进行逻辑运算操作;其它的优缺点一样;① 海量数据的统计工作,比如日志分析、用户数统计等;
② Bloom Filter(布隆过滤器);
③ 快速去重 + 快速查询O(1);RoaringBitMap
(压缩位图索引)RoaringBitMap底层结构:
① short[] keys:key = N / 65536
② Container[] values:value = N % 65536
③ int size:包含了有效key和values中有效数据对的数量;解决了BitMap与BitSet存储稀疏数组时浪费空间的弊端; 压缩思想:与其重复写100遍0,不如声明0重复了100遍;RBM是BitSet和BitMap的进阶版,集万千优点于一身;
-
2.2)Roaring Bitmap(内存压缩)
1)Roaring Bitmap的底层数据结构
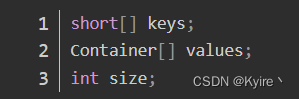
数据结构 计算 作用 short[] keys key = N / 65536表示N这个值放在第key个Container中 Container[] values value = N % 65536表示N这个值放在第key个文档中的第value个位置上
有两种类型:① 若元素个数 < 4096:Array Container;② 若元素个数 > 4096:int size size = keys.length = values.length表示keys和values的长度 2)Container的类型有两种:
容器类型 底层 描述 数据的插入与查找 Array Container 最多占用4096个short(8kb) 用于 存放稀疏数据,因为元素少于4096个时,存多少个数据,就占用多少个short;比如存10个数据,就只占10个short,即160个bit;而BitmapContainer的固定长度为1024个long(8kb),所以当数据少于4096个(8kb)时,默认用Array Container;二分查找(Array Container 是有序的) BitmapContainer 固定占用1024个long(8kb) 用于 存放稠密数据,当元素个数大于4096时,Array Container自动转移为BitmapContainer,改为用位图索引存储;直接根据(N%65536)的计算结果定位插入与查询的索引
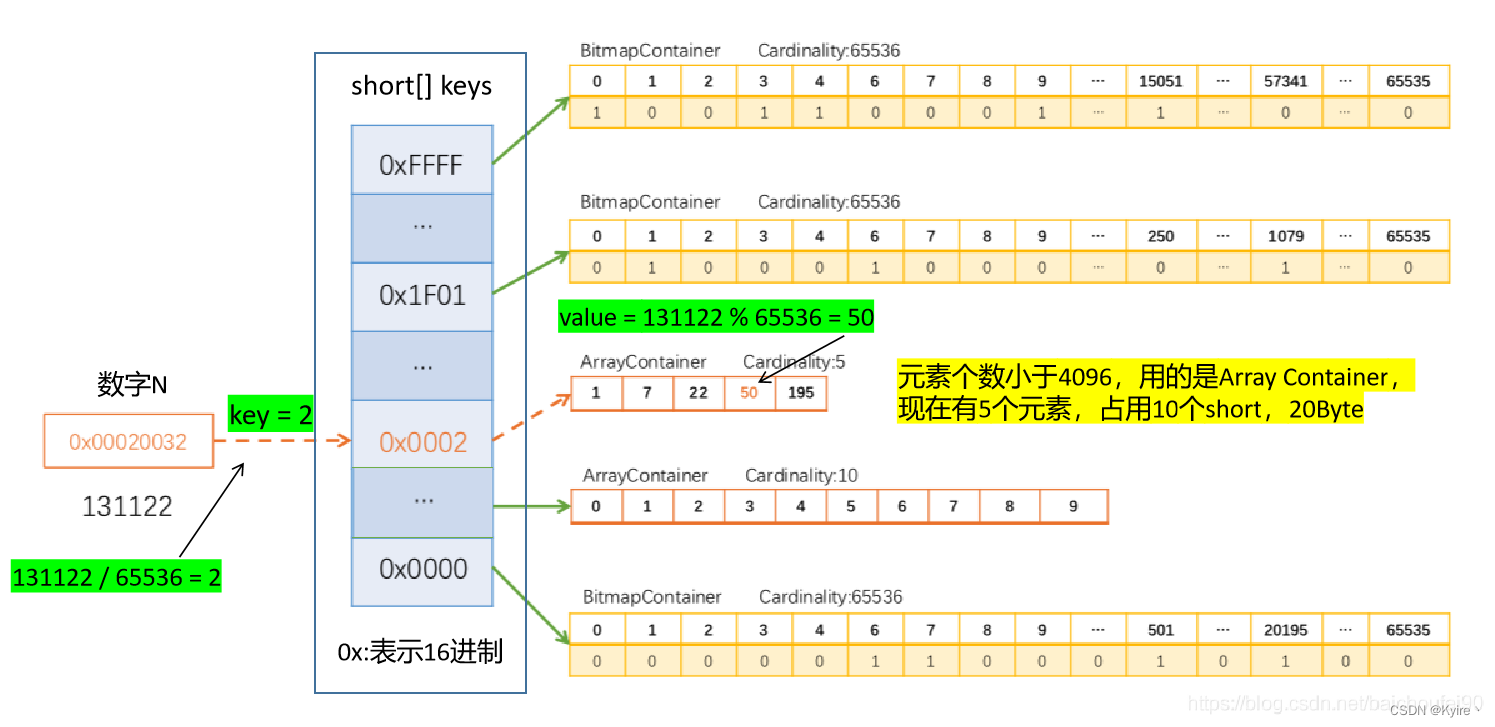
3)⭐Array Container插入例子
下面我们具体看一下Array Container中数据如何被存储的,例如,0x00020032(十进制131122)放入一个 RBM 的过程如下图所示:
Step1: 计算 key = 131122 / 65536 = 2,应该插入到2号区域;
Step2: 计算 value = 131122 % 65536 = 50,此时判断容器内部元素的个数是否大于4096个;
Step3: 发现2号区域的Container元素只有4个,插入完才5个,那么直接插入到Array Container中;
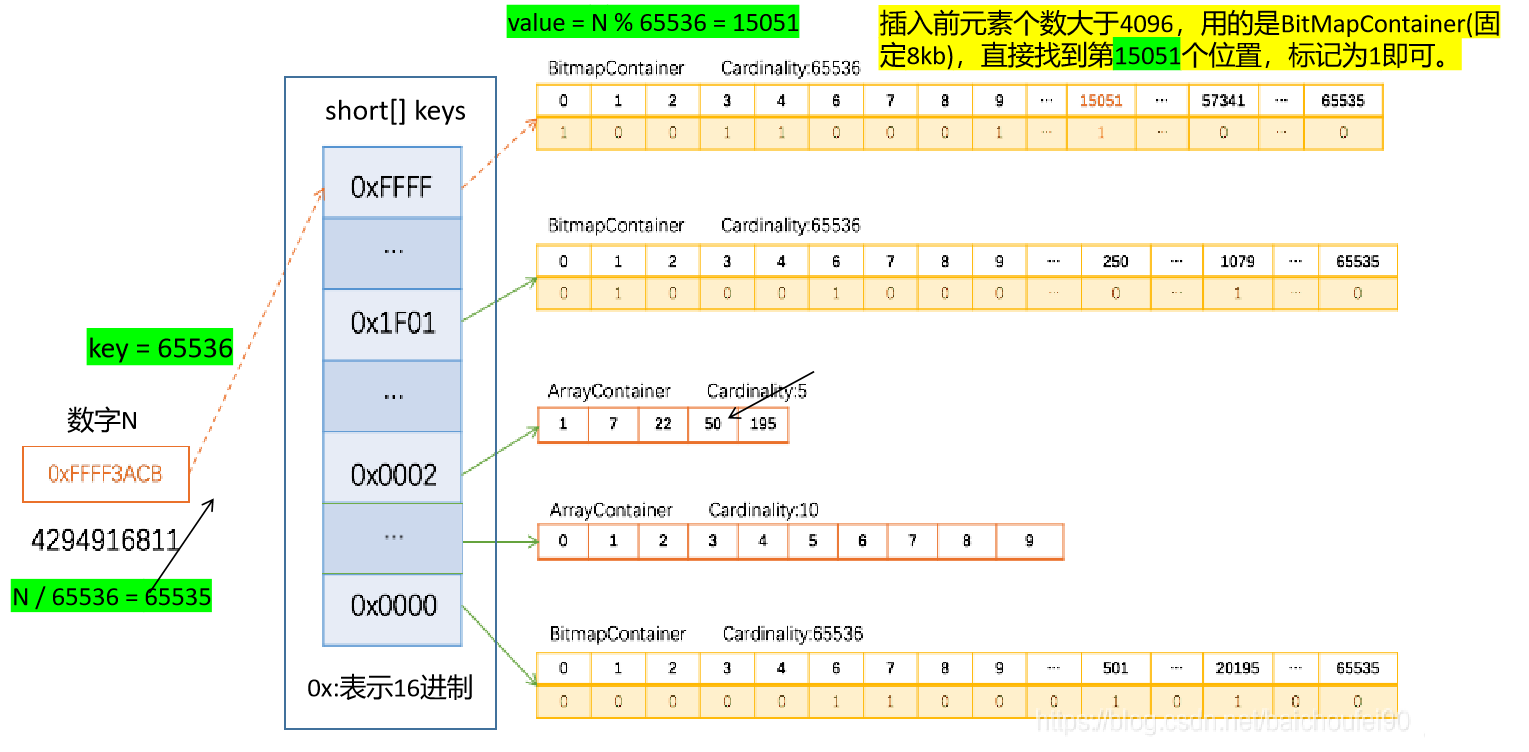
4)⭐BitMapContainer插入例子
下面我们具体看一下BitMapContainer中数据如何被存储的,例如,0xFFFF3ACB(十进制4294916811)放入一个 RBM 的过程如下图所示:
Step1: 计算 key = 4294916811 / 65536 = 2,应该插入到65536号区域;
Step2: 计算 value = 4294916811 % 65536 = 15051,此时判断容器内部元素的个数是否大于4096个;
Step3: 发现2号区域的Container已经是位图了(大于4096),那么直接标记15051索引处为1,即表示插入成功;
7、具体介绍一下Term Index?
-
1)为什么需要Term Index?
由于term dictiona存储在磁盘中,但是磁盘的随机IO操作仍然是非常昂贵,所以应该尽量少读磁盘,有必要把一些数据缓存到内存里。但是整个term dictionary本身又太大了,无法完整地放到内存里。而且就算term字典里我们可以按照term进行排序,用一个二分查找就可以定为这个term所在的地址,但这样的复杂度是logN,在term很多,内存放不下的时候,效率还是需要进一步提升。于是就有了term index,具体的底层数据结构是
FST(有限状态转移机); -
2)FST(有限状态转移机)
FST 描述 特点 不但能共享前缀也能共享后缀,能够判断某个key存不存在,同时能够给出响应(Posting List) 优点 在范围查询、前缀搜索以及压缩率超级nb,使得我们能够最大程度的优化时间与空间复杂度,将term dictionary以term index的形式缓存到内存中 缺点 在单term的查询上可能相比hashMap没有明显优势
8、全文检索如何联合索引查询?—Posting List 如何取并集与交集?
-
选择哪种方式,主要看是Posting List 有没有从磁盘缓存到内存中;
Posting List 位置 方式 磁盘 用 skip list(跳表)的方式进行并集或交集运算,由于磁盘中的FOR算法,使用skip list 不仅跳过了遍历的成本,还跳过了解压block的成本,节省了cpu;内存 就用 BitSet的逻辑运算实现多个Posting List的并集与交集运算
二、Elasticsearch索引文档(不是修改是建立)与搜索的过程
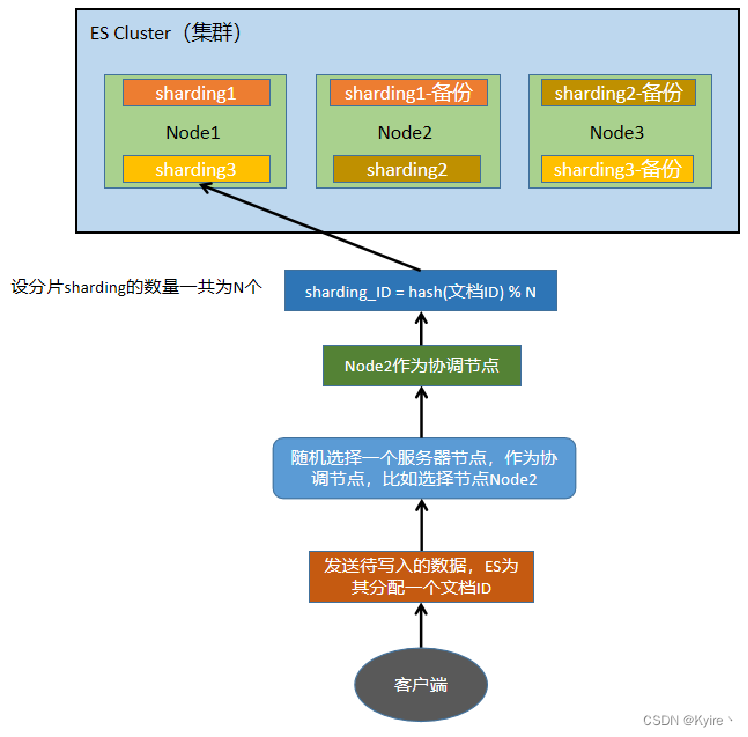
1、Elasticsearch索引文档流程
-
Elasticsearch写入文档,建立一个新索引的流程
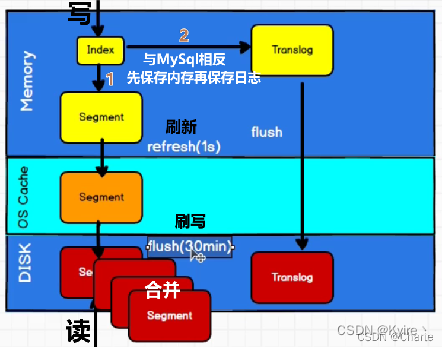
步骤 描述 Step1 客户端发送写数据的请求,ES为数据分配一个文档ID;请求可以随机发往任意节点,该节点成为协调节点; Step2 计算文档要写入哪个分片(sharding),默认为 shard_ID = hash(文档_ID) % 分片的总数; ES也支持轮询法指定分片;Step3 协调节点进行路由,将写数据请求转发给shard_ID所在的ES节点; Step4 (先写内存)在内存中建立一个索引 (Index),该Index在内存中会形成一个分段对象 (Segment);Step5 (再写日志)然后将索引数据写到日志 (Translog) 与 sharding-备份分片;
① 在这个过程中,每隔1s,会将内存中的Segment刷新到系统文件缓存区,方便让用户快速的进行查询(因为用户查询直接访问内存或者磁盘,速度会变慢);
② 当过了30min或者Translog日志中的数据超过了512M,那么系统文件缓存区中的Segment就会将数据刷写 (flush) 到磁盘中,刷写后内存的Segment将会被清除;如果磁盘中的Segment多了后,磁盘就会将这些Segment进行合并;Step6 协调节点确保上述步骤都完成后,返回客户端写入成功的响应;
- Step5:【数据保存的过程】:
先内存Segment,再日志,然后刷到系统缓存区,达到写磁盘条件则写入磁盘,清除内存缓存;达到磁盘Segment合并阈值,则合并;
2、Elasticsearch搜索流程
-
ES搜索过程:
Query then Fetch(查询后取回)步骤 描述 Step1 客户端发送查询请求(关键词key),可以发给任意节点,该节点成为协调节点; Step2 协调节点将查询请求的key广播到每一个ES节点,这些节点的分片sharding就会各自处理查询请求; Step3 每个分片根据key进行数据查询,具体步骤如下:
① 首先,根据ES指定的分词器,将查询关键词key进行分词 (规范化、去重),分成多个词项term;
② 对于每一个词项term,分别根据内存中的term index (FST) 查询该包含了该term的文档在磁盘块block中的位置,同时输出倒排表Posting List;
③ 再对每个词项的倒排表进行合并或者取交集等操作,获得合并后的倒排表,进行打分排序(参考的是本分片中的信息);Step4 【① Query阶段 (轻量级),每个分片通过查询倒排索引,返回的是文档ID集合,并不是数据】 待到全部分片的查询全部结束后,将符合条件的查询结果数据放入一个队列中,并将这些数据的文档ID、节点信息、分片信息全部返回给协调节点;Step5 【② Scroll分析 (经过轻量级的Query阶段后,免去了繁重的全局排序过程)】, 由协调节点将所有的查询结果进行筛选 + 汇总 + 排序,丢弃一些数据;Step6 【③ Fetch阶段 (重量级),将筛选后的数据 (所有信息) 全部取回】, 协调节点处理完毕后,向包含剩余文档ID的分片发送 get() 请求,对应的分片将数据返回给协调节点;待取回全部分片的数据后,协调节点将查询结果数据整合起来,返回给客户端;注意: Query Then Fetch 的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch 增加了一个预查询的处理,询问 Term 和 Document的出现频率,这个评分更准确,但是性能会变差。
3、Elasticsearch更新与删除流程
-
删除和更新都是写操作,但是由于 Elasticsearch 中的文档(
底层是段Segment)是不可变的,因此不能被删除或者改动以展示其变更;所以 ES 利用 .del 文件 标记文档是否被删除,磁盘上的每个段都有一个相应的.del 文件操作 描述 更新 将旧的文档标记为deleted状态,然后创建一个新的文档; 删除 文档其实并没有真的被删除,而是在 .del 文件中被标记为 deleted 状态。该文档依然能匹配查询,但是会在结果中被过滤掉; -
在内存缓存区中,
每隔1s就产生一个Segment文件,当Segment文件达到一定阈值时,就会定期的执行merge操作,每次 merge 的时候,会将多个 segment 文件合并成一个,同时这里会将标识为 deleted 的 doc 给物理删除掉,不写入到新的 segment 中,然后将新的 segment 文件写入磁盘,这里会写一个commit point,标识所有新的 segment 文件,然后打开 segment 文件供搜索使用,同时删除内存中旧的 segment 文件;
三、并发情况下,Elasticsearch 如果保证读写一致?
-
三种解决方案
方案 描述 版本号机制 读写冲突不是很大时,可以通过版本号机制,在应用层解决,只有当携带的版本号 > 当前实际版本号时,才能修改; 针对写操作 ES支持三种一致性级别:
① quorum: 只有当一半以上的分片可用时,才允许写操作(保证写操作能够同时写入、备份成功),这样用户查询备份分片节点时也能查询到一致的数据;
② one: 只要主分片数据保存成功,那么客户端就可以进行查询操作;
③ all: 最高的一致性级别,要求所有的分片数据全部写入成功后,用户才能进行查询操作;以确保用户一定能查询到刚写入的数据;针对读操作 ① 设置ES同步,阻塞直到主分片与备份分片都执行完写操作后才返回查询的数据;
② 设置搜索请求,强制客户端取主分片查询,确保是最新结果;
四、Elasticsearch 应用上的问题汇总
1、DocValues的作用:
-
倒排索引也是有缺陷的,假如我们需要对数据做一些聚合操作,比如排序/分组时,lucene内部会遍历提取所有出现在文档集合的排序字段,然后再次构建一个最终的排好序的文档集合list,这个步骤的过程全部维持在内存中操作,而且如果排序数据量巨大的话,非常容易就造成solr内存溢出和性能缓慢。
-
DocValues 就是 ES 在构建倒排索引的同时,构建了正排索引,保存了docId到各个字段值的映射,可以看作是以文档为维度,从而实现根据指定字段进行排序和聚合的功能; -
另外doc Values 保存在操作系统的磁盘中,当docValues大于节点的可用内存,ES可以从操作系统页缓存中加载或弹出,从而避免发生内存溢出的异常,docValues远小于节点的可用内存,操作系统自然将所有Doc Values存于内存中(堆外内存),有助于快速访问。
2、text 和 keyword类型的区别?
-
类型 区别 text类型 分词,建立倒排索引;keyword类型 不分词,只能通过精确值搜索到;
3、query 和 filter 的区别?
-
类型 区别 query 计算分值与相关度filter 只判断是否满足查询条件,不会计算分值与相关度,且经过filter查询的结果可以被缓存到内存中,提高检索性能















 1576
1576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









