






一、表分类
业务数据库里面的数据每天需要同步到我们的数据仓库里面。根据数据量的大小,数据的变化情况,可以分成以下几类:
1、全量表:存储完整的数据
2、增量表:存储新增加的数据
3、新增及变化表:存储新增加的数据和变化的数据
4、特殊表:只需要存储一次的数据
二、同步策略
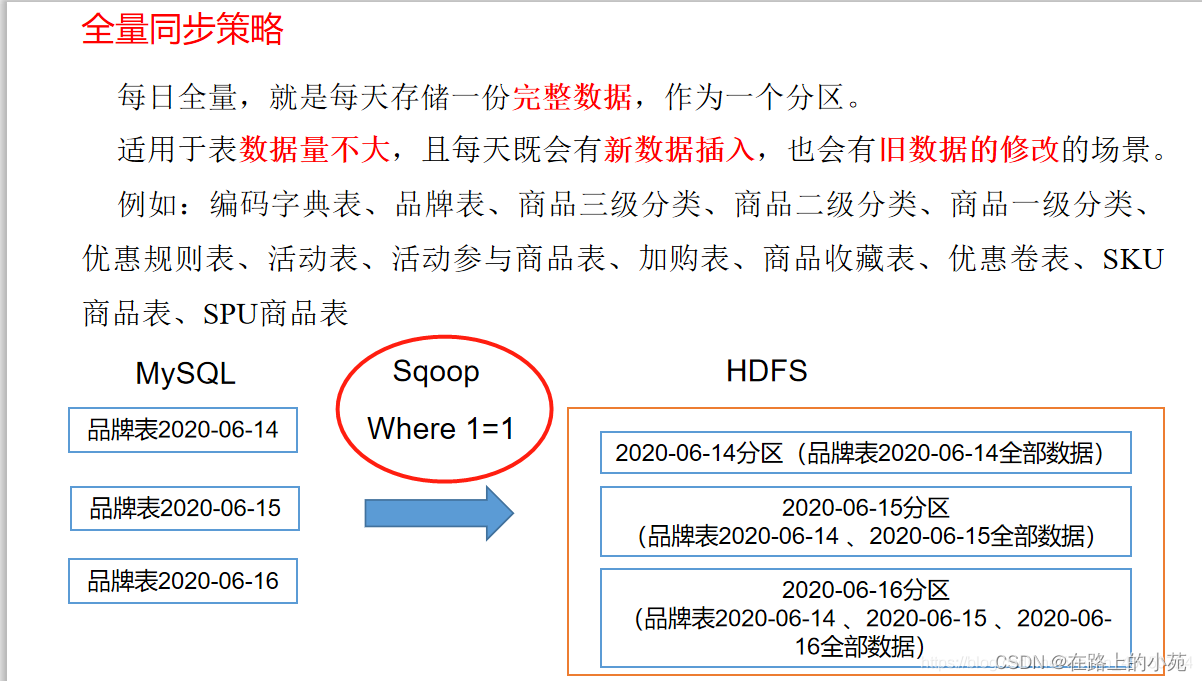
全量同步策略:
每日全量,就是每天存储一份完整的数据,作为一个分区
适用于表中数据量很小,每天可能会有数据新增或者数据修改的情形。
增量同步策略:
每日增量,就是每天存储一份增量数据,,作为一个分区
适用于数据量大,每天都会向表中新增数据的场景(支付流水表)
新增和变化同步策略:
每日新增及变化,就是基于创建时间和操作时间都是今天的数据
适用于数据量大,每天不仅会新增数据,还会有历史数据发生变化(订单表,用户表)
该种情况最经常采用的是拉链表来解决,拉链表会有dp和dt两个分区,dp的值有ACTIVE和EXPIRED两个分区,ACTIVE代表当前这条数据是有效的,而EXPIRED代表的是当前这条数据是过期的。dt分区每天存储的也是历史到现在的全量数据,每个dt分区里面的数据都包含新增和修改的数据。
拉链表有一篇比较好的文章,需要复习的时候可以翻出来看一看:拉链表详解
特殊策略:
某些特殊的维度表,可不必遵循上述同步策略
例如:地区表,省份表,日期表,可以只导入一次即可
有时候在想,数仓中的表有同步策略,这个同步策略在哪里看呢?是建表语句吗?显然不是。是在sqoop中看参数。
全量同步: 查询最新的分区,就是所有的数据。
缺点就是:hdfs越来越大。


打个比方:
1月1号的数据,存到hdfs之后。
1月2号的数据,以及1月1号中发生变化的数据,存到对应1月2号的分区。
导数据的时候,导入分时候条件就是创建时间是1月1号的,或者是operate的时间是1月2的(1月1日或者更早的数据在1月2号修改了,那么这个时间就是1月2号)。
这样的话,就是导入的是新增得数据,以及和变化的数据。
具体的就是,业务数据从MySQL中导入hdfs的脚本里面,进行的指定条件。
这里面就是全量同步,从MySQL中,因为后面的条件是where 1=1,也就是无条件的导入,也就是全量的导入。
import_sku_info(){
import_data sku_info "select
id,
spu_id,
price,
sku_name,
sku_desc,
weight,
tm_id,
category3_id,
create_time
from sku_info where 1=1"
}















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









