







目录
1 Hive架构全景图
Hive作为Hadoop生态系统中最重要的数据仓库工具,其架构设计完美体现了"SQL on Hadoop"的核心思想。

- 用户接口:用户通过Hive CLI、Beeline、JDBC或ODBC等接口与Hive进行交互,提交SQL查询
- Hive编译器:接收用户提交的SQL查询,进行解析和编译,生成初步的执行计划
- 优化器:对初步的执行计划进行优化,生成更高效的物理执行计划
- 执行引擎:根据优化后的执行计划,提交任务到Hadoop集群进行执行
- Hadoop集群:
- 使用MapReduce、Tez或Spark等计算框架执行任务
- 任务执行过程中,会读取和写入HDFS、HBase等存储系统中的数据。
- 元数据存储(Metastore):
- 存储Hive的元数据,包括表结构、分区信息、存储位置等
- 元数据存储是Hive与Hadoop生态系统其他组件之间的桥梁,确保数据的一致性和可访问性
- 存储系统:
- HDFS是Hive默认的数据存储系统,提供高吞吐量的数据访问
2 核心组件深度解析
2.1 组件分工协作图

- 核心组件职责:
| 组件 | 核心职责 | 关键特性 |
| CLI | 用户交互界面 | 支持命令历史、脚本执行 |
| Driver | 查询生命周期管理 | 会话管理、执行跟踪 |
| Compiler | SQL解析和任务生成 | 语法分析、语义验证 |
| Metastore | 元数据持久化存储 | 支持多种数据库后端 |
| Executor | 任务提交与监控 | 容错处理、进度汇报 |
2.2 Metastore的独特地位
Metastore作为Hive的"大脑",存储着所有表结构定义和分区信息:
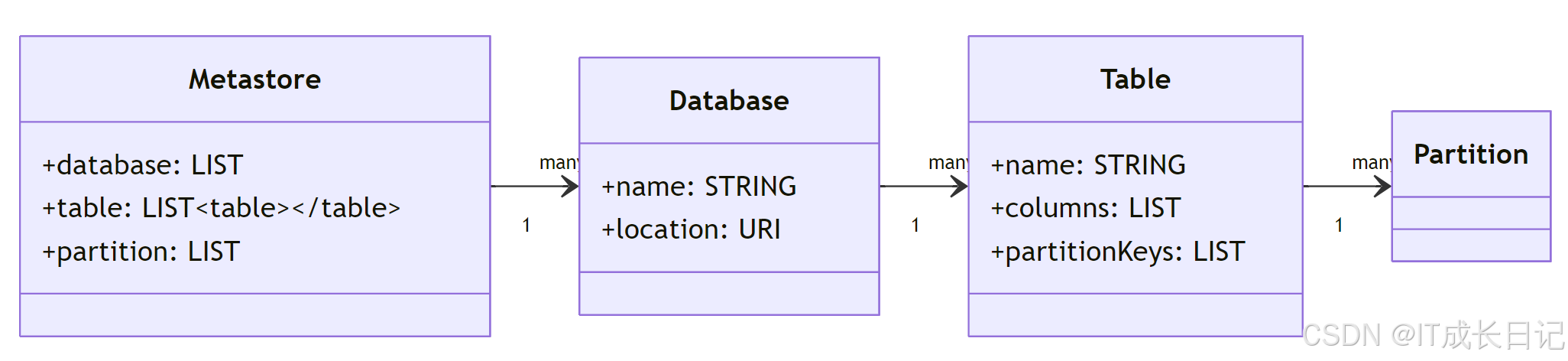
元数据关键内容:
- 数据库/表/视图的定义
- 列数据类型和统计信息
- 分区信息及存储位置
- 表属性(如文件格式、压缩方式)
3 SQL执行全流程剖析
3.1 完整执行流程图
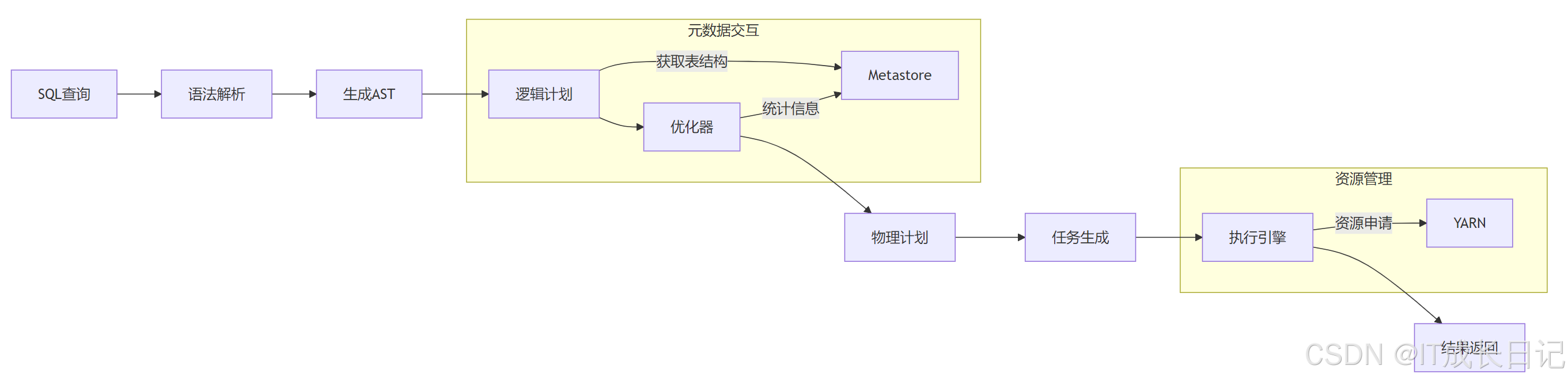
3.2 关键阶段详解
3.2.1 阶段1:SQL解析与AST生成
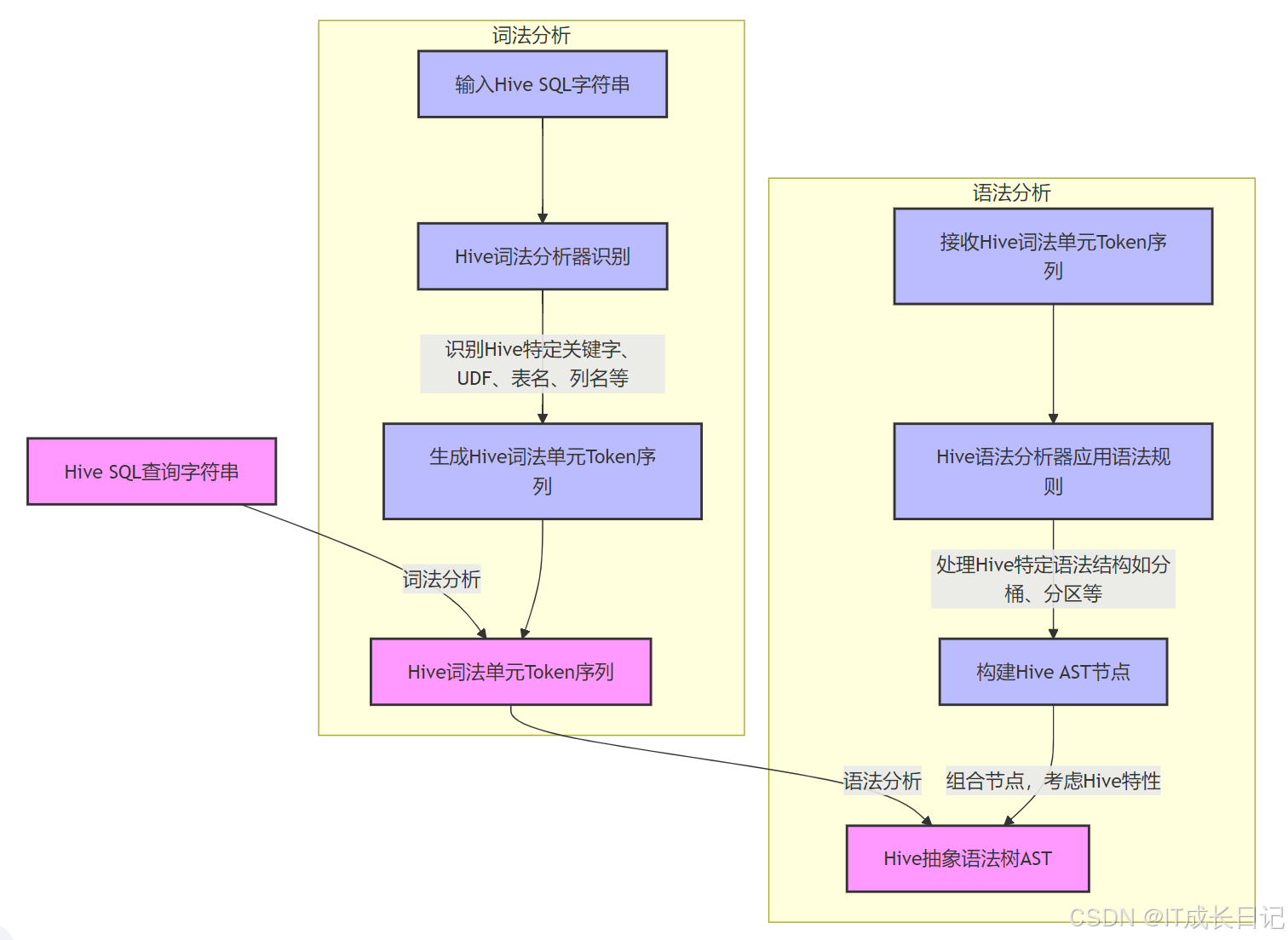
- 过程解析
输入处理阶段
- 接收用户输入的Hive SQL字符串
- 快速预处理:去除注释、标准化格式
词法分析优化
- 使用预编译的正则表达式模式匹配
- 建立Hive关键字快速查找表
- 并行识别基础词素(标识符、字面量、运算符)
语法分析改进
- 基于ANTLR等解析器生成器的优化语法规则
- 增量式语法检查而非全量检查
- Hive特有语法结构专用解析路径
AST构建增强
- 采用内存池技术减少节点创建开销
- AST节点轻量化设计(压缩存储关键属性)
- 分区/分桶等Hive特性采用标记位而非复杂结构
3.2.2 阶段2:逻辑计划生成
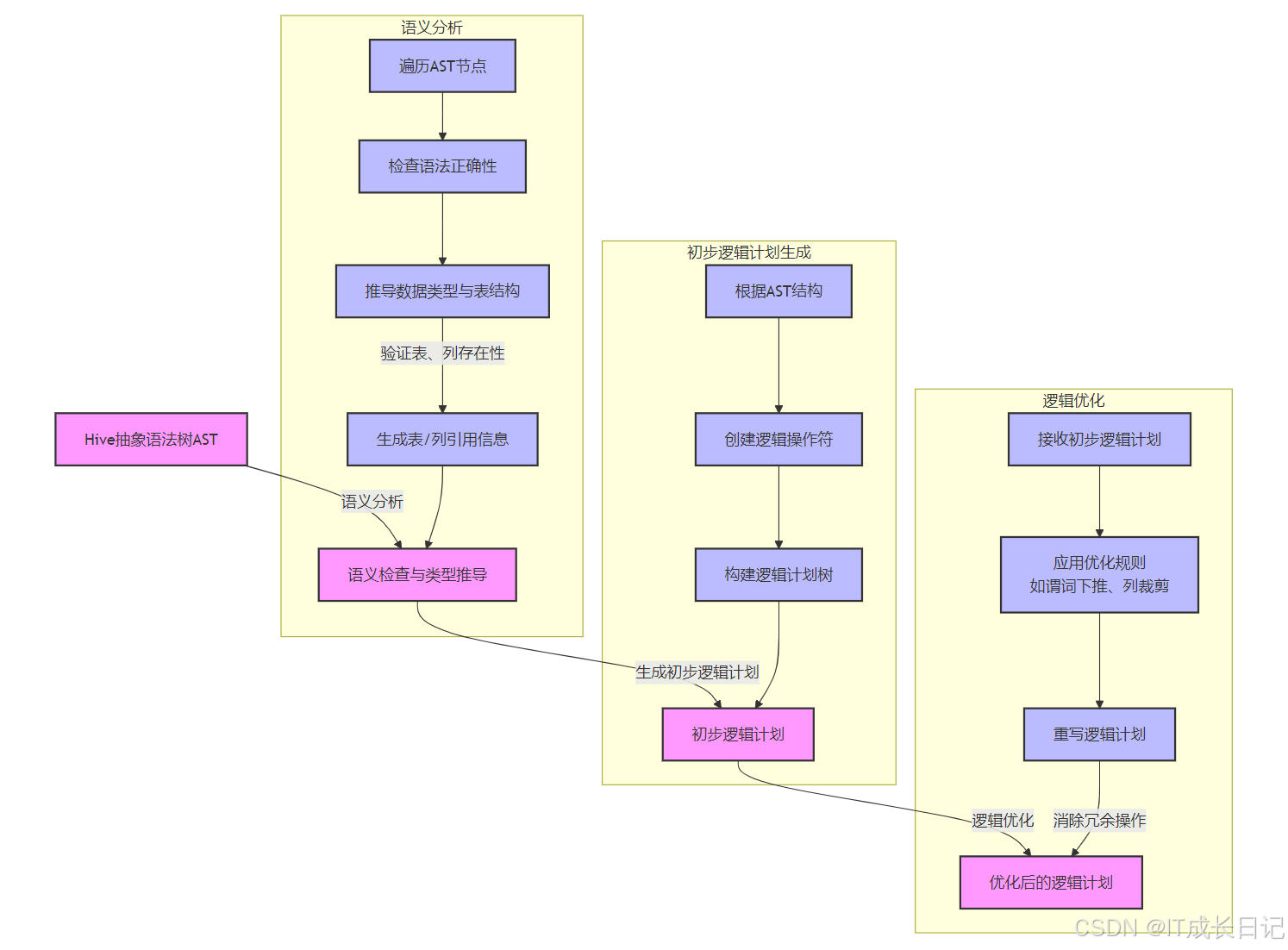
- 处理流程
AST语义分析阶段
- 深度遍历AST节点结构
- 执行语法正确性验证(表/列存在性、数据类型匹配)
- 解析元数据生成表/列引用关系
- 推导表达式数据类型和返回结构
逻辑计划生成阶段
- 将AST节点转换为逻辑操作符(Projection、Filter等)
- 构建初始逻辑计划树(保留原始查询语义)
- 建立操作符间的数据流依赖关系
逻辑优化阶段
- 应用启发式优化规则(谓词下推、列裁剪等)
- 消除冗余计算和无效操作
- 重写计划结构提升执行效率
- 保持语义等价性的转换
3.2.3 阶段3:物理计划生成
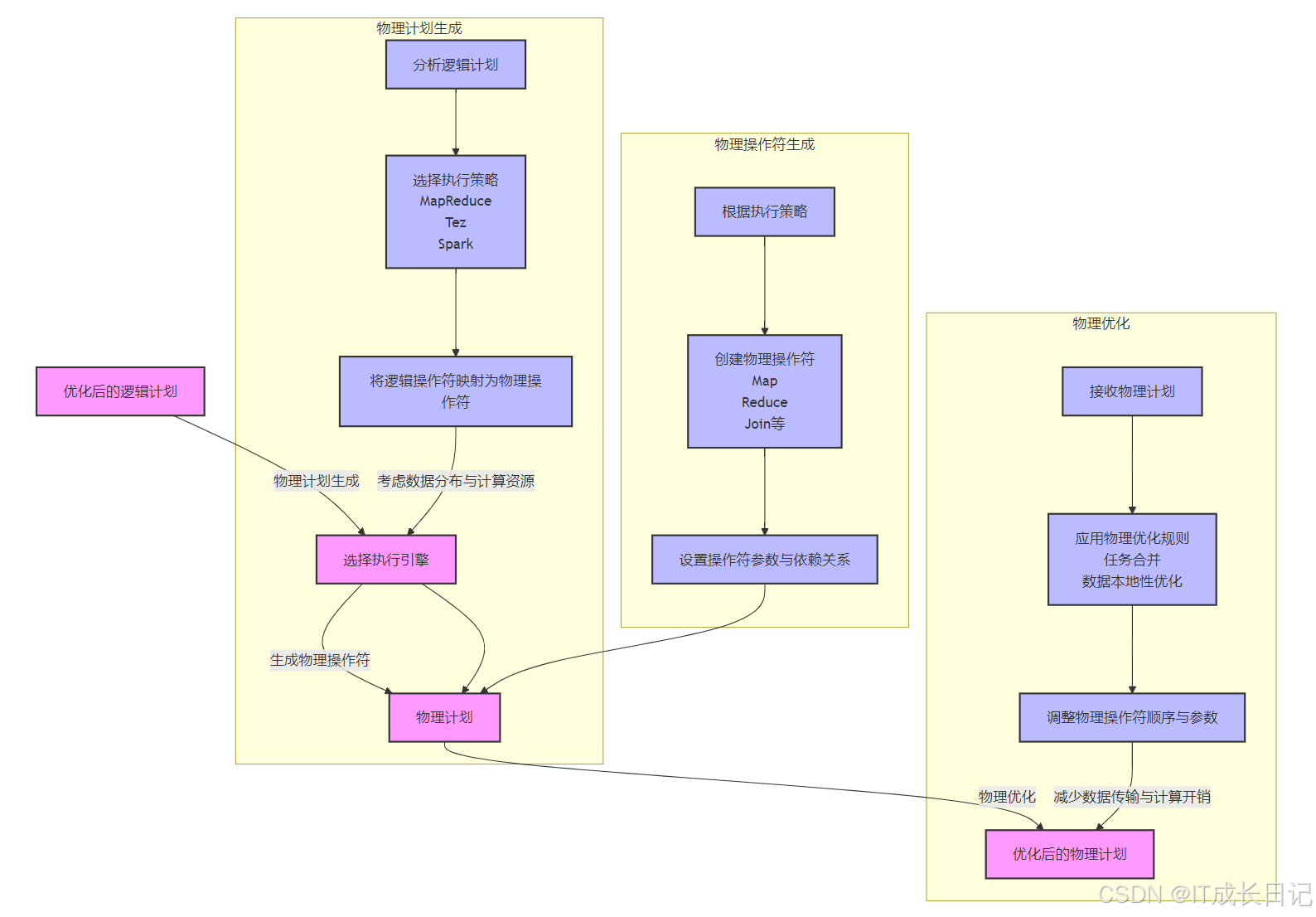
- 核心处理流程
物理计划生成阶段
- 接收优化后的逻辑计划作为输入
- 分析查询结构和执行需求
- 根据执行引擎(MapReduce/Tez/Spark)选择最佳执行策略
- 将逻辑操作符映射为特定引擎的物理操作符
物理操作符生成阶段
- 创建与执行引擎匹配的物理操作符(Map/Reduce/Join等)
- 配置操作符参数(内存分配、并行度等)
- 建立操作符间数据依赖关系
- 考虑数据分布特性(分区、分桶)和集群资源状况
物理优化阶段
- 应用运行时优化规则(任务合并、本地化调度等)
- 动态调整操作符执行顺序
- 优化Shuffle和数据传输机制
- 减少跨节点数据传输和重复计算
4 执行引擎协作机制

Hive查询处理阶段:
- 用户提交SQL查询:通过CLI/JDBC等接口提交查询请求。
- SQL解析与优化:
- 解析器:将SQL转换为抽象语法树(AST)
- 逻辑优化器:优化AST,生成高效的逻辑执行计划
- 物理优化器:转换为物理计划,确定执行引擎(如MapReduce)
MapReduce作业生成与提交:
- 物理计划分解:
- 明确Map/Reduce任务及其依赖关系
- 生成作业配置(输入/输出格式、Mapper/Reducer类等)
- 提交至Hadoop集群:
- 由JobTracker(或YARN ResourceManager)接收作业
- 任务调度:分配给可用的TaskTracker(或NodeManager)
Hadoop任务执行:
- Map阶段:
- TaskTracker执行Map任务,读取HDFS输入数据
- 处理数据并生成中间键值对(Key-Value)
- Reduce阶段:
- 对Map输出进行Shuffle & Sort
- Reduce任务聚合结果,写入HDFS
结果返回:
- 输出存储:最终结果保存至HDFS指定路径
- Hive获取结果:读取HDFS文件并返回给用户
5 性能优化关键点
5.1 执行计划可视化分析

- 优化方向:
- 增加Map并行度(减少长尾任务)
- 优化Shuffle参数(减少网络传输)
- 合理设置Reduce数量(避免数据倾斜)
5.2 配置参数建议
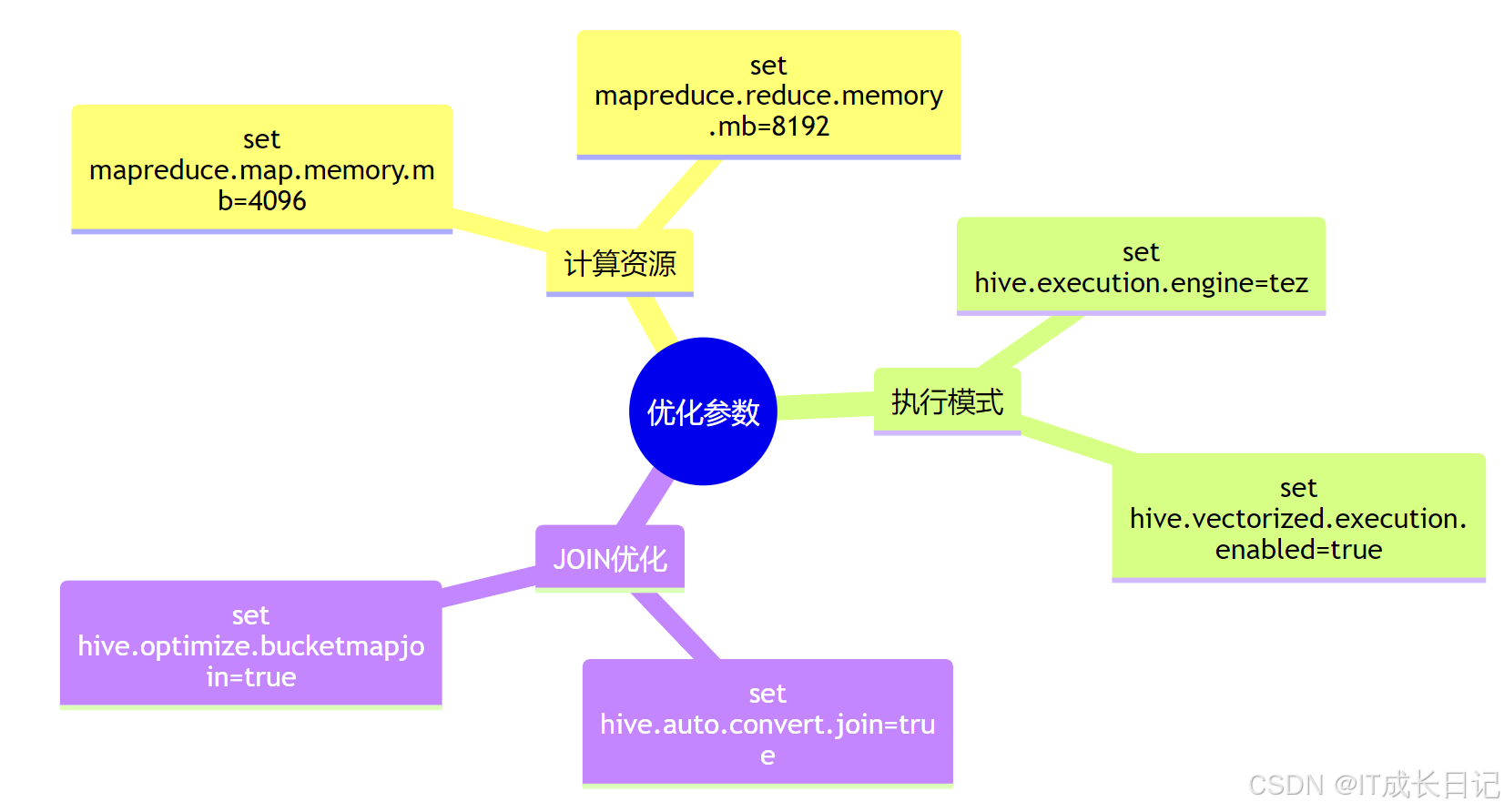


















 5011
5011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











