







目录
1 DistCp概述与应用场景
DistCp(Distributed Copy)是Hadoop生态系统中的 分布式数据拷贝工具,专为大规模数据跨集群/跨目录迁移而设计。典型应用场景:
- 跨集群数据迁移(如Hadoop版本升级)
- 生产环境到测试环境的数据同步
- 冷热数据分离存储
- 数据备份与灾备
2 DistCp架构设计解析
2.1 系统架构图
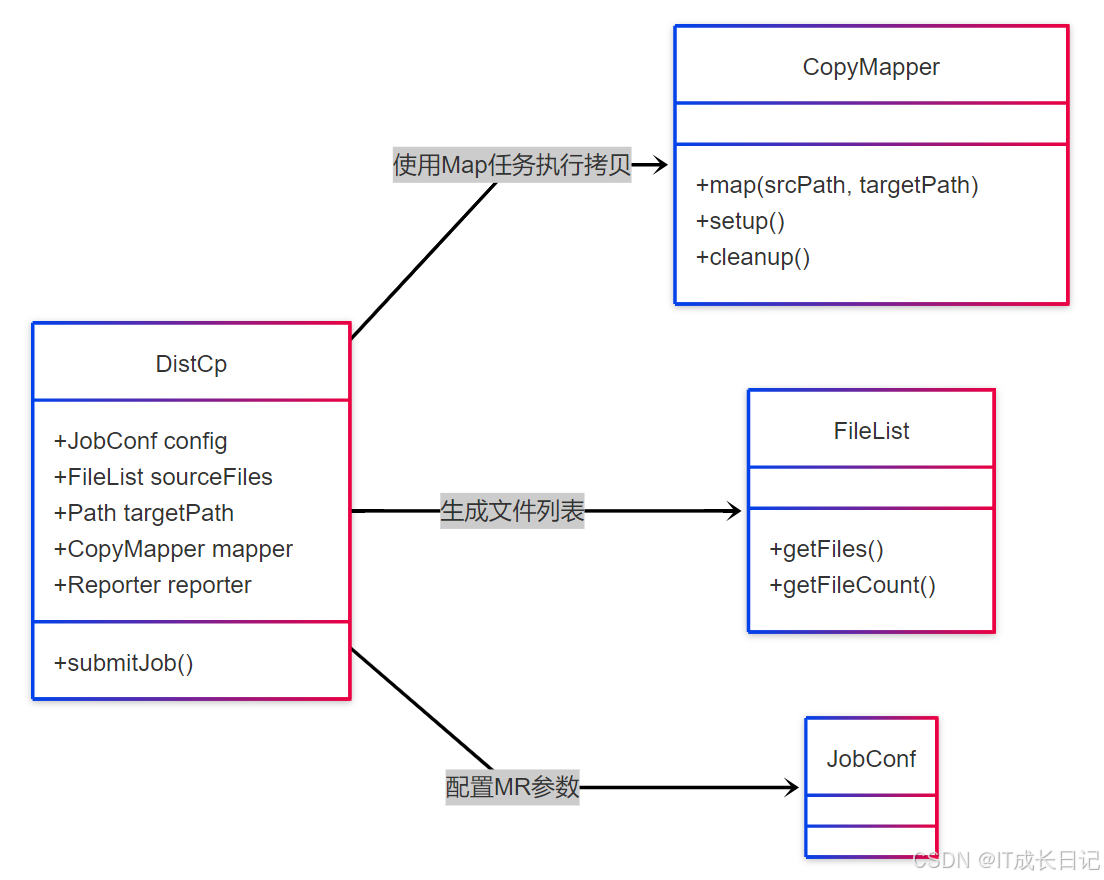
组件职责说明:
- DistCp:主控制类,负责参数解析和作业提交
- CopyMapper:实际执行文件拷贝的Map任务
- FileList:维护待拷贝文件的清单
- JobConf:配置MapReduce作业参数
2.2 执行流程图

流程关键点:
- 列表构建阶段:递归扫描源路径生成文件清单
- 分片策略:默认每10个文件一个分片(可配置)
- 校验阶段:通过对比源和目标文件的CRC32确保一致性
3 DistCp核心技术原理
3.1 并行拷贝机制

并行化实现:
- 每个Map任务处理一个文件分片
- 默认并行度=min(文件数/10, 集群slot数)
- 支持通过-m参数手动设置Mapper数量
3.2 断点续传实现原理
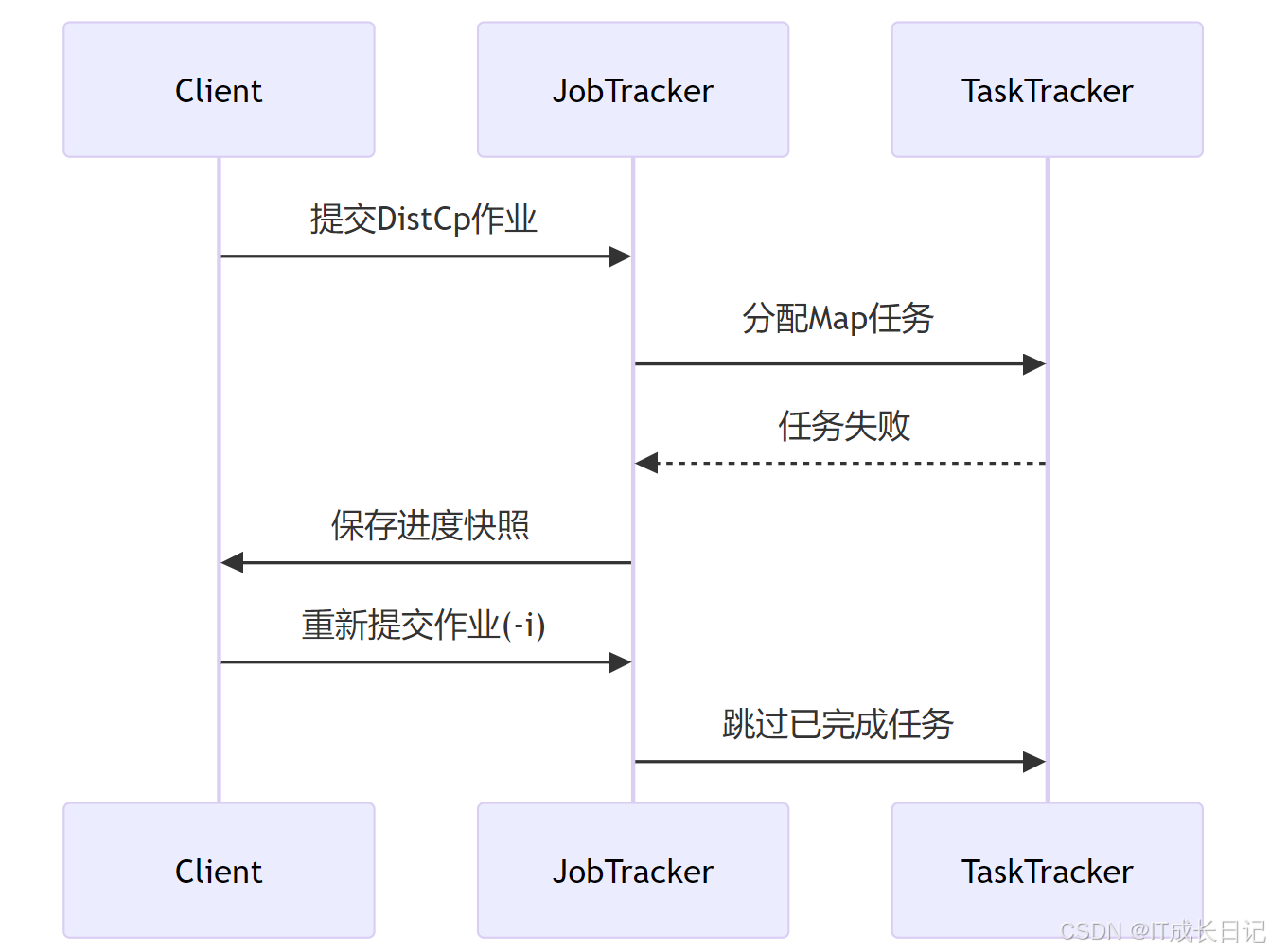
关键参数:
- -i:忽略失败任务
- -update:只拷贝新增/修改文件
- -append:追加写入目标文件
4 DistCp实战指南
4.1 常用命令示例
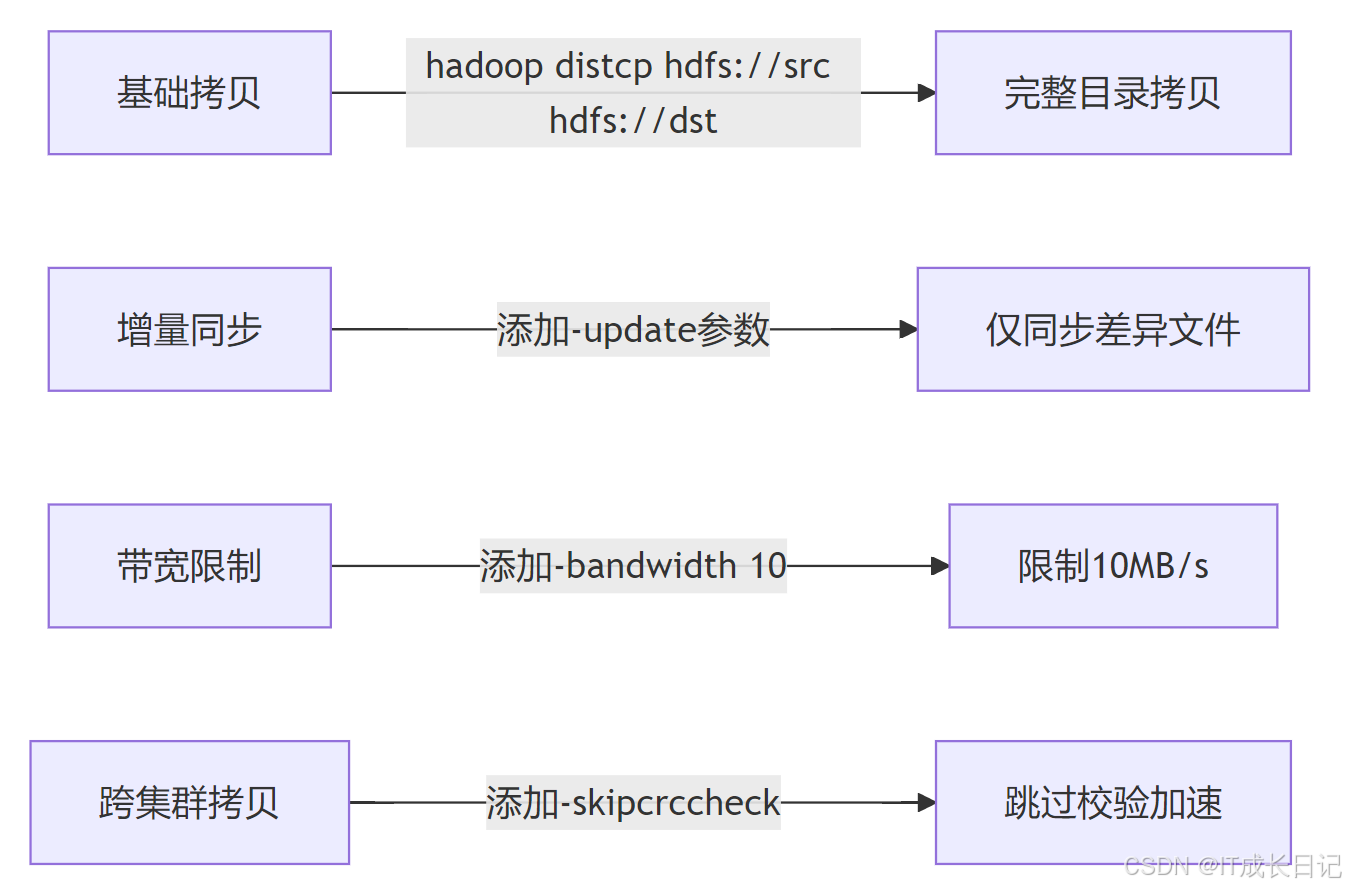
- 参数优化建议
# 示例
hadoop distcp \
-Ddfs.client.socket-timeout=240000 \
-Ddfs.datanode.socket.write.timeout=720000 \
-bandwidth 50 \ # 限制带宽50MB/s
-m 100 \ # 设置100个Mapper
-update \ # 增量模式
-strategy dynamic \ # 动态分片
hdfs://cluster1/data \
hdfs://cluster2/data4.2 性能优化策略
调优策略:
- Mapper数量:建议为集群slot数的2-3倍
- 带宽限制:避免影响生产业务
- 分片策略:小文件多用动态分片
5 异常处理与监控
5.1 常见错误处理流程
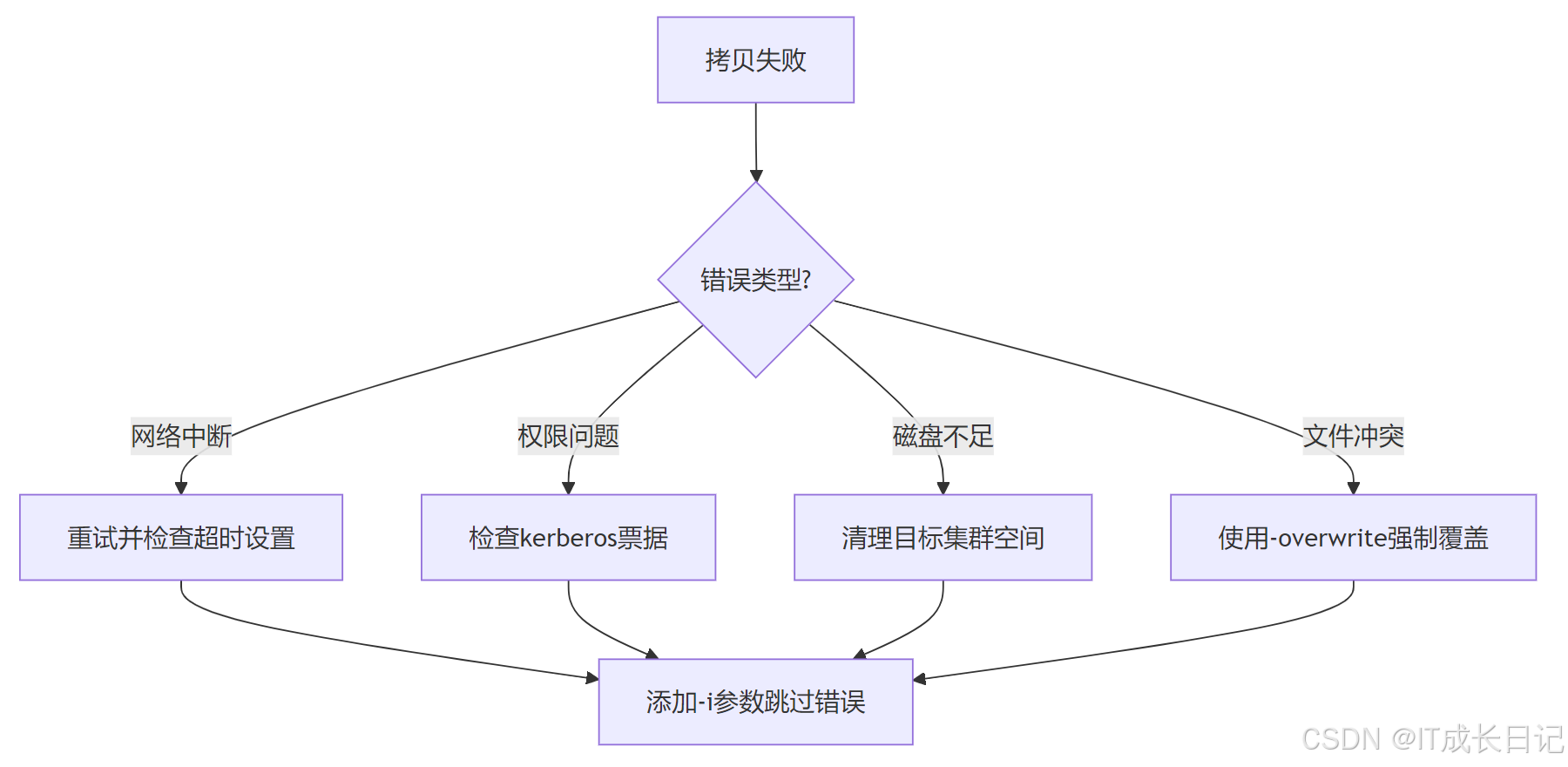
5.2 监控指标建议
监控建议:
- 通过hadoop job -history查看历史作业
- 监控HDFS写入速率和集群负载
- 记录每次拷贝的吞吐量和文件数
6 与替代方案对比
6.1 技术选型决策树
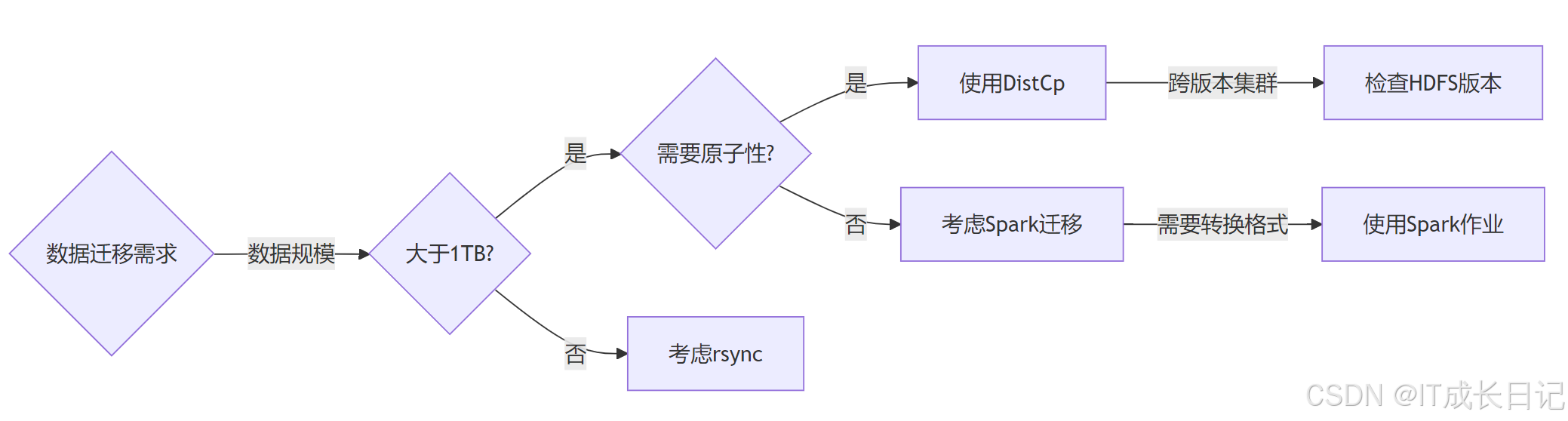
- 方案对比表
| 工具 | 优势 | 局限性 |
| DistCp | 原生支持、处理海量数据 | 缺乏实时同步能力 |
| Spark | 支持数据转换 | 需要开发代码 |
| Rsync | 增量同步精确 | 单节点瓶颈 |
| HDFS NFS | 挂载即用 | 性能较差 |
7 总结
在实际生产环境中,建议先在小规模数据上验证参数配置,再执行全量迁移。对于PB级数据迁移,可采用分批次执行的策略,同时密切关注集群负载情况。


















 1980
1980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











