







目录
1 Hive索引核心概念
1.1 索引的本质与价值
Hive索引是一种数据结构优化技术,通过创建额外的元数据来加速数据检索过程。与关系型数据库类似,Hive索引能够显著减少查询时需要扫描的数据量,但实现机制有所不同。
索引的核心价值:
- 查询加速:减少数据扫描范围,提升查询性能
- 资源节约:降低CPU和I/O消耗
- 成本优化:减少集群计算资源使用
- 交互式分析:使Hive更适合即席查询场景
1.2 Hive索引与RDBMS索引对比
| 特性 | Hive索引 | 传统RDBMS索引 |
| 数据结构 | 多样化(位图、紧凑等) | 通常B树/B+树 |
| 更新机制 | 手动/半自动维护 | 自动实时维护 |
| 存储位置 | 独立表或文件 | 与数据一体存储 |
| 事务支持 | 有限支持 | 完整支持 |
| 适用场景 | 大数据批处理 | 事务处理和OLTP |
| 创建开销 | 较高(需MR作业) | 相对较低 |
2 Hive索引类型详解
2.1 紧凑索引(Compact Index)
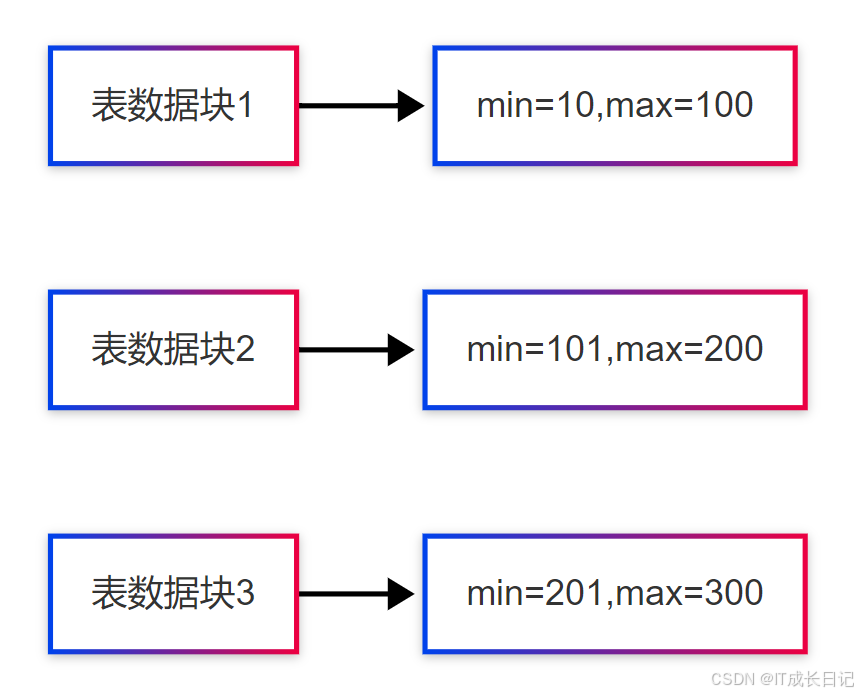
数据结构:
- 存储索引列的值范围而非精确值
- 记录每个HDFS块的极值(min/max)
适用场景:
- 数值范围查询(WHERE age BETWEEN 20 AND 30)
- 有序数据的高效过滤
- 低基数(low-cardinality)列查询
- 创建示例:
CREATE INDEX sales_amt_idx ON TABLE sales(amount)
AS 'COMPACT' WITH DEFERRED REBUILD;2.2 位图索引(Bitmap Index)
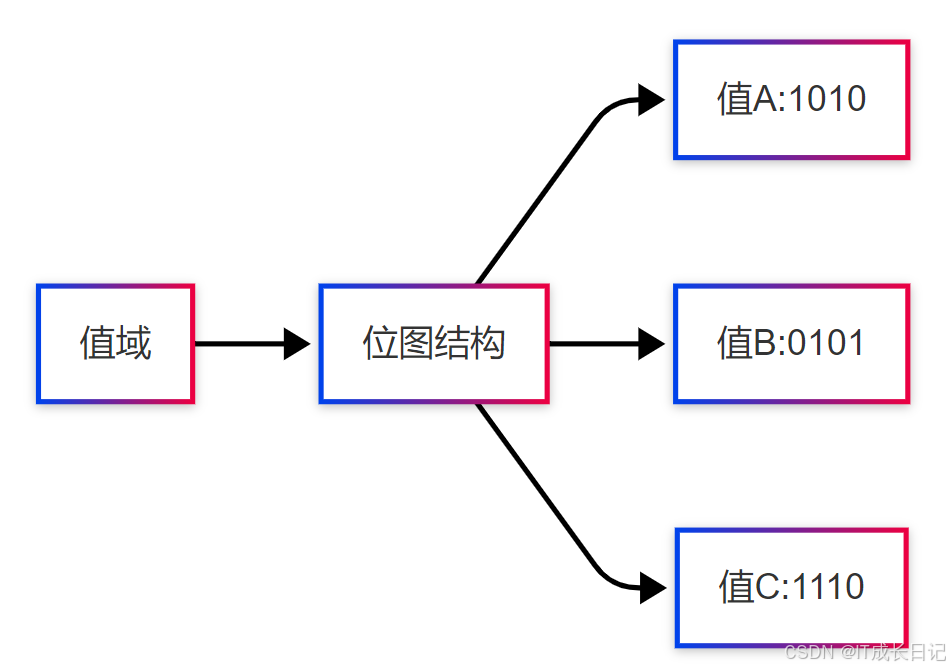
数据结构:
- 为每个唯一值创建位向量
- 使用位运算快速过滤
适用场景:
- 低基数枚举类型(性别、状态等)
- 多列组合条件查询
- 高选择性(high-selectivity)过滤
- 创建示例:
CREATE INDEX user_gender_idx ON TABLE users(gender)
AS 'BITMAP' WITH DEFERRED REBUILD;2.3 物化视图索引
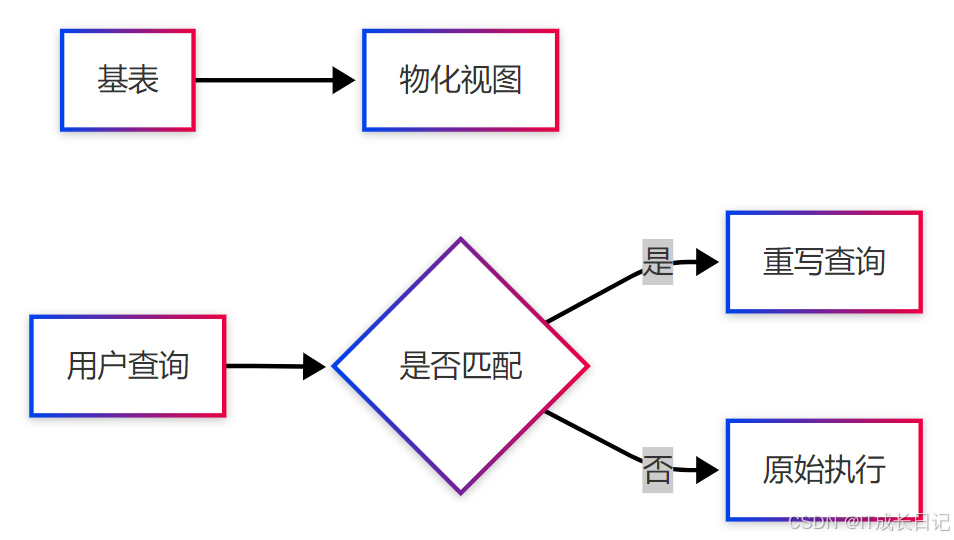
特殊性质:
- 实质上是预计算的查询结果集
- 自动匹配查询重写
适用场景:
- 频繁的聚合查询
- 固定模式的报表生成
- 复杂计算结果的复用
- 创建示例:
CREATE MATERIALIZED VIEW sales_summary_mv
AS SELECT region, SUM(amount) FROM sales
GROUP BY region;3 索引创建与管理全流程
3.1 创建流程

- 定义索引结构:
CREATE INDEX idx_name ON TABLE tbl_name(col_list)
AS 'index_type'
WITH DEFERRED REBUILD;- 构建索引数据:
ALTER INDEX idx_name ON tbl_name REBUILD;- 验证索引状态:
SHOW FORMATTED INDEX ON tbl_name;- 自动查询优化:Hive优化器自动选择是否使用索引
3.2 索引维护命令
- 查看索引信息:
-- 查看表的所有索引
SHOW INDEX ON table_name;
-- 查看索引详细信息
DESCRIBE FORMATTED INDEX idx_name ON table_name;- 更新索引:
-- 全量重建
ALTER INDEX idx_name ON table_name REBUILD;
-- 增量更新(Hive 3.0+)
ALTER INDEX idx_name ON table_name
SET PARTITION (dt='2023-01-01') REBUILD;- 删除索引:
DROP INDEX IF EXISTS idx_name ON table_name;3.3 分区表索引特殊处理
- 分区级索引管理:
-- 创建分区索引
CREATE INDEX idx_name ON TABLE tbl_name(col_name)
AS 'COMPACT'
PARTITIONED BY (dt STRING);
-- 为特定分区构建索引
ALTER INDEX idx_name ON tbl_name
PARTITION (dt='2023-01-01') REBUILD;- 动态分区索引:
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
ALTER INDEX idx_name ON tbl_name
PARTITION (dt) REBUILD;4 索引使用场景与优化
4.1 最佳适用场景
- 点查询优化:
-- 使用索引的理想场景
SELECT * FROM users WHERE user_id = 10086;- 范围查询加速:
-- 紧凑索引特别有效
SELECT * FROM sales WHERE amount BETWEEN 1000 AND 2000;- 低基数过滤:
-- 位图索引高效处理
SELECT * FROM orders WHERE status IN ('SHIPPED','COMPLETED');- 连接查询优化:
-- 索引加速连接字段
SELECT a.*, b.*
FROM transactions a JOIN accounts b
ON a.account_id = b.account_id;4.2 性能优化策略
| 查询类型 | 推荐索引类型 | 示例场景 |
| 精确匹配(=) | 紧凑/位图 | user_id = 123 |
| 范围查询(>, | 紧凑 | age BETWEEN 20 AND 30 |
| 多值IN查询 | 位图 | status IN (1,3,5) |
| IS NULL查询 | 位图 | phone IS NULL |
| 聚合查询 | 物化视图 | GROUP BY region |
- 配置参数调优:
-- 启用自动索引选择
SET hive.optimize.index.filter=true;
SET hive.optimize.index.groupby=true;
-- 设置索引缓存
SET hive.index.compact.cache.size=5000;
-- 并行索引重建
SET hive.exec.parallel=true;
SET hive.exec.parallel.thread.number=8;4.3 使用限制与注意事项
不适用场景:
- 频繁更新的表(每次更新需重建索引)
- 极高基数(high-cardinality)列
- 全表扫描操作(索引无优势)
- 维护成本考量:

- 存储空间开销:
- 紧凑索引:额外5-10%存储
- 位图索引:基数决定大小
- 物化视图:可能超过原表大小
5 高级索引技术
5.1 复合索引设计
- 多列索引创建:
CREATE INDEX comp_idx ON TABLE orders(customer_id, order_date)
AS 'COMPACT' WITH DEFERRED REBUILD;- 最左前缀原则:
-- 能使用索引的查询
SELECT * FROM orders
WHERE customer_id=123 AND order_date>'2025-05-15';
-- 不能使用索引的查询
SELECT * FROM orders WHERE order_date>'2025-05-15';5.2 索引分区策略
- 两级分区索引:
CREATE INDEX part_idx ON TABLE logs(severity)
PARTITIONED BY (year INT, month INT)
AS 'BITMAP';- 动态维护示例:
-- 按月自动维护
SET hive.exec.dynamic.partition=true;
ALTER INDEX part_idx ON logs
PARTITION(year, month) REBUILD;5.3 索引生命周期管理
- 自动化脚本示例:
#!/bin/bash
# 自动重建过期分区索引
for partition in $(hive -e "SHOW PARTITIONS sales"); do
if [ $(date -d "now - 7 days" +%s) -gt $(date -d "${partition#dt=}" +%s) ]; then
hive -e "ALTER INDEX sales_idx ON sales
PARTITION(${partition}) REBUILD;"
fi
done6 性能监控与诊断
6.1 索引效果评估
- 关键性能指标:

- 评估命令:
-- 分析查询执行计划
EXPLAIN EXTENDED SELECT * FROM users WHERE age > 30;
-- 查看索引使用统计
ANALYZE TABLE users COMPUTE STATISTICS FOR COLUMNS age;6.2 常见问题排查
索引未生效的可能原因:
- 统计信息过期
ANALYZE TABLE table_name COMPUTE STATISTICS;- 查询条件不符合最左前缀
- 数据类型不匹配
- 索引已失效但未重建
- 自动索引优化被禁用
诊断流程:

7 结语:索引使用黄金法则
- 适度原则:索引不是越多越好,维护成本需权衡
- 场景匹配:根据查询模式选择合适索引类型
- 持续监控:定期评估索引效果,及时调整
- 分层设计:结合分区、分桶等优化手段
- 与时俱进:关注Hive新版本索引增强特性
通过合理设计和维护索引,可以在Hive大数据环境中实现查询性能提升成倍的效果,使Hive在交互式分析场景中也能表现出色。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











