







目录
1 写入流程概述
Elasticsearch的写入流程是一个 分布式事务处理过程,涉及多个组件的协同工作。整体流程可分为三个阶段:
- 客户端请求阶段:请求路由与预处理
- 主分片处理阶段:数据校验与本地写入
- 副本同步阶段:数据复制与一致性保证
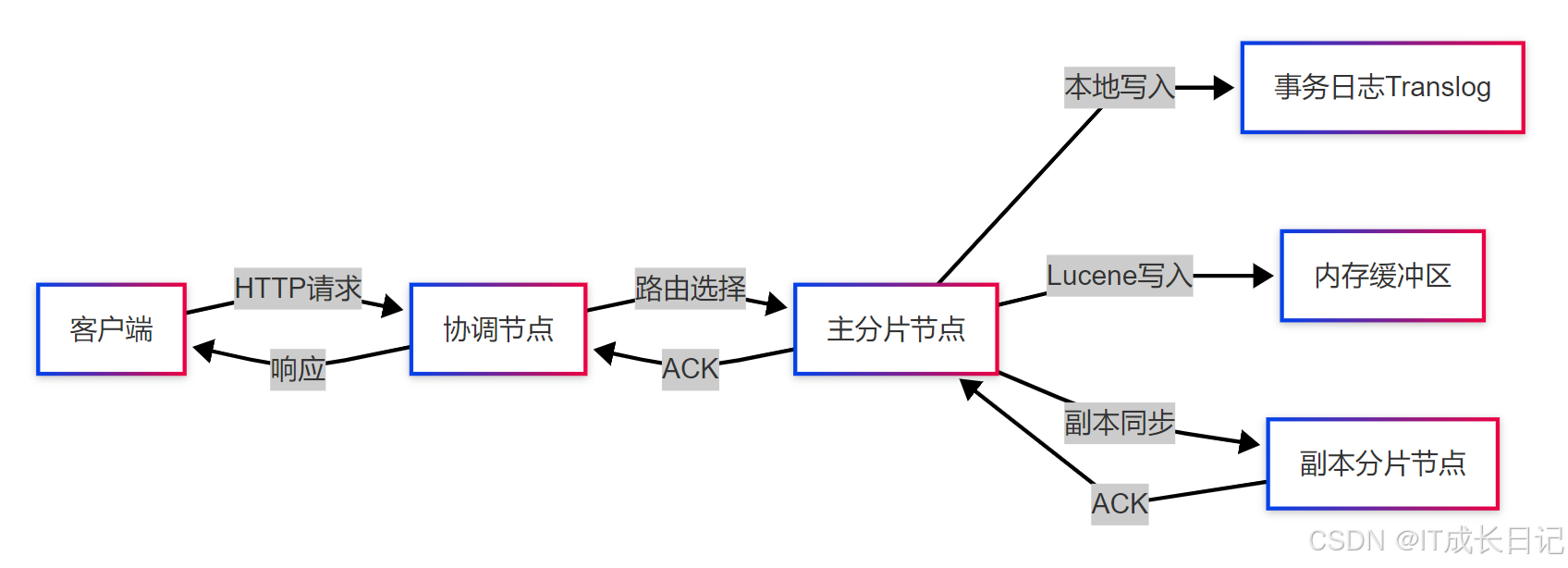
2 核心概念解析
2.1 相关组件
| 组件 | 作用 |
| 协调节点 | 接收客户端请求,路由到正确节点,聚合结果 |
| 主分片 | 负责处理所有写入请求,保证数据一致性 |
| 副本分片 | 主分片的完整拷贝,提供高可用性 |
| Translog | 事务日志,确保写入操作的可恢复性 |
| 内存缓冲区 | 存储尚未提交到磁盘的文档(refresh操作后变为可搜索) |
2.2 关键参数
# 写入一致性级别(默认quorum)
index.write_consistency: quorum
# 刷新间隔(默认1秒)
index.refresh_interval: 1s
# Translog刷盘策略
index.translog.durability: request3 详细写入流程
3.1 客户端请求阶段
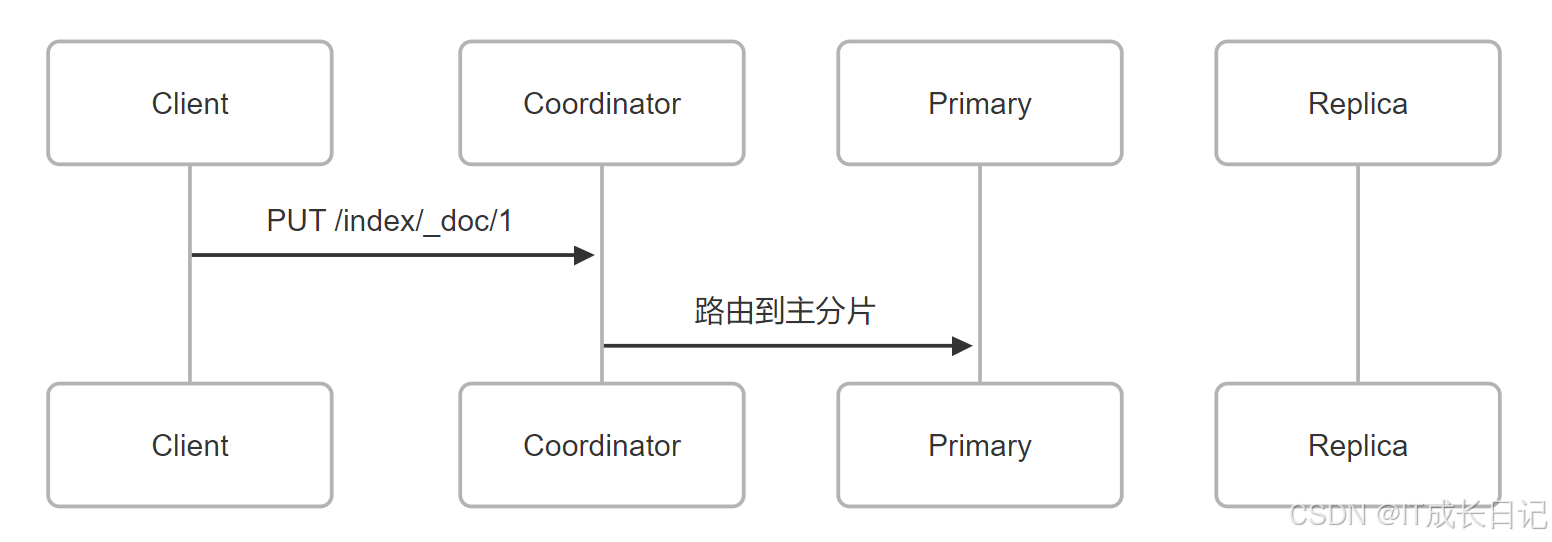
步骤说明:
- 客户端发送HTTP请求到任意节点(该节点自动成为协调节点)
- 协调节点通过文档ID哈希确定所属主分片
- 请求被转发到主分片所在节点
- 路由公式:
shard_num = hash(_routing) % num_primary_shards
# 默认_routing=文档ID3.2 主分片处理阶段

版本控制:检查_version字段,防止并发写入冲突
- 乐观锁机制(OCC)
- 可通过?version=1&version_type=external指定版本
内存写入:
- 文档加入Lucene的内存缓冲区
- 此时数据不可被搜索(需等待refresh)
Translog记录:
- 同步写入磁盘(确保宕机可恢复)
- 刷盘策略:
- request:每次请求后刷盘(更安全)
- async:异步刷盘(更高性能)
3.3 副本同步阶段
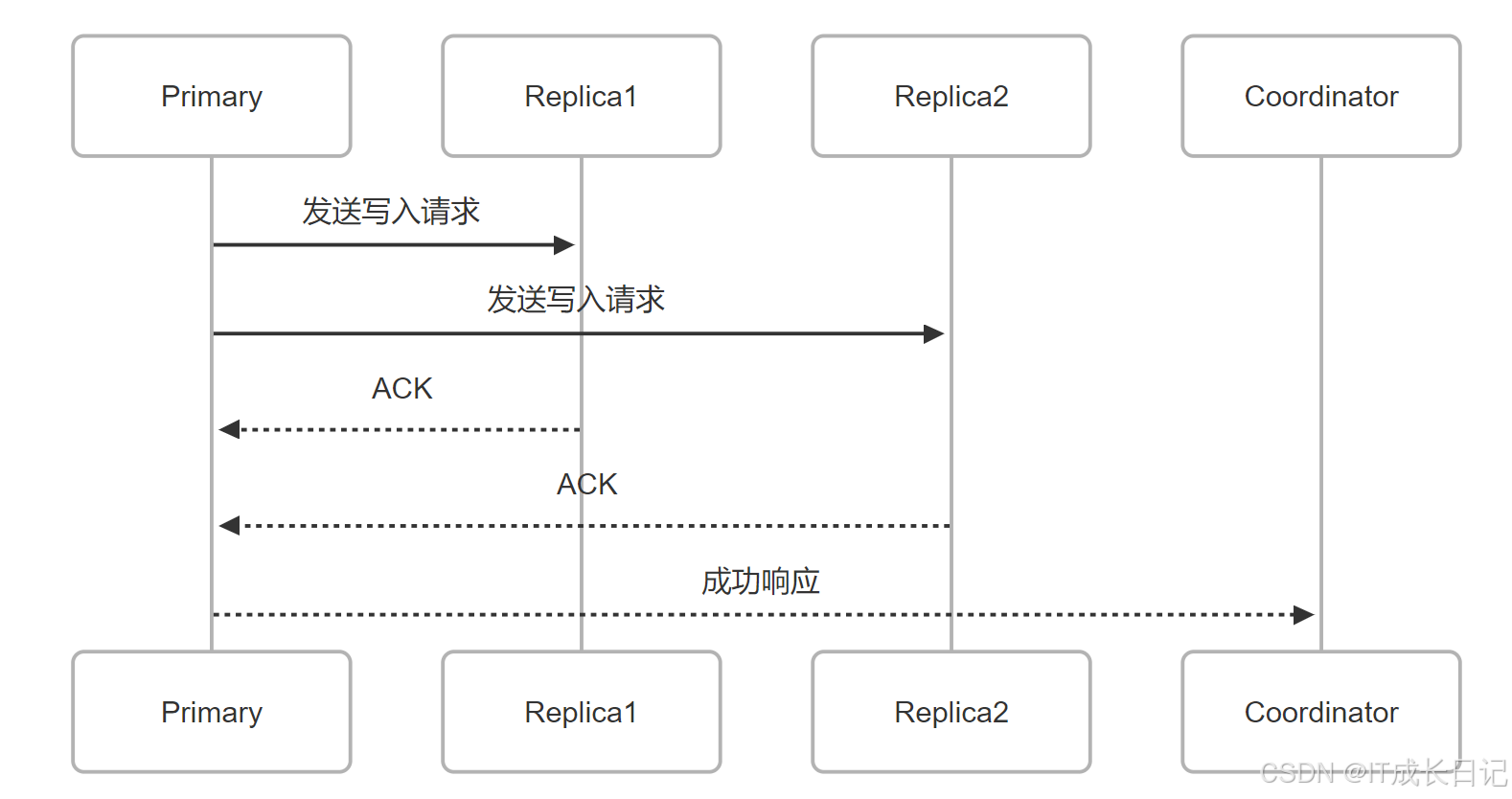
一致性保证:
- Quorum机制:必须成功写入(副本数+1)/2个分片
# 计算公式
int( (primary + number_of_replicas) / 2 ) + 1
- 超时处理:默认等待60秒(可通过timeout参数调整)
4 数据持久化流程
4.1 Refresh操作

特点:
- 默认每1秒自动执行(可通过refresh_interval调整)
- 生成新的不可变Lucene段文件
- 触发条件:
- 定时触发
- 手动调用/_refresh
- 索引设置index.refresh_interval
4.2 Flush操作
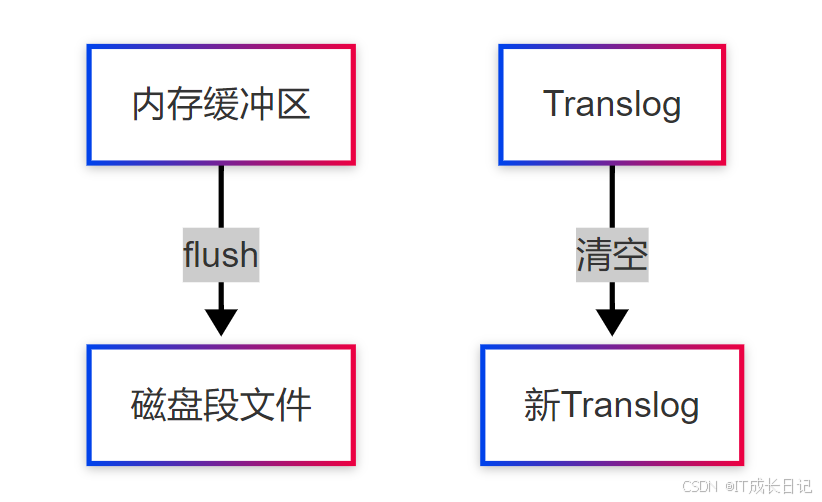
触发条件:
- Translog大小超过512MB(index.translog.flush_threshold_size)
- 定时30分钟(index.translog.sync_interval)
- 手动调用/_flush
4.3 Merge操作
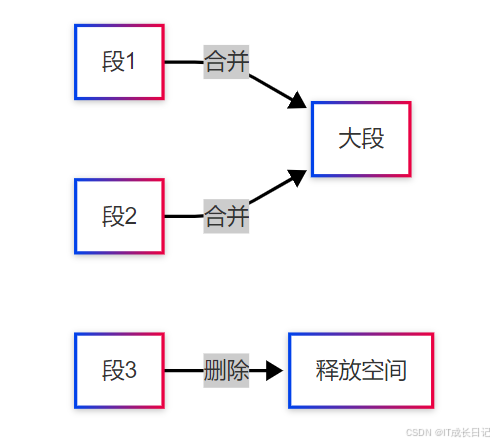
优化建议:
- 调整合并策略:
PUT /index/_settings
{
"index.merge.policy": {
"max_merged_segment": "5gb"
}
}- 避免频繁更新导致大量小段
5 写入优化策略
5.1 批量写入(Bulk API)

最佳实践:
- 每批次5-15MB数据
- 并行发送多个bulk请求
- 客户端示例:
from elasticsearch import helpers
actions = [{'_index':'test', '_source':{'foo':i}} for i in range(10000)]
helpers.bulk(es, actions)5.2 硬件优化建议
| 瓶颈类型 | 优化方案 |
| CPU | 使用更多分片分散写入负载 |
| 磁盘IO | 使用SSD,单独部署数据节点 |
| 网络带宽 | 启用压缩(http.compression: true) |
5.3 参数调优
# 减少refresh频率(日志场景适用)
index.refresh_interval: 30s
# 增大索引缓冲区
indices.memory.index_buffer_size: 30%
# 调整Translog设置
index.translog.durability: async
index.translog.sync_interval: 120s6 故障处理与监控
6.1 写入拒绝(Rejection)
常见原因:
- 线程池队列满
- 磁盘空间不足
- 分片未分配
- 解决方案:
PUT _cluster/settings
{
"persistent": {
"thread_pool.write.queue_size": 1000
}
}6.2 监控关键指标
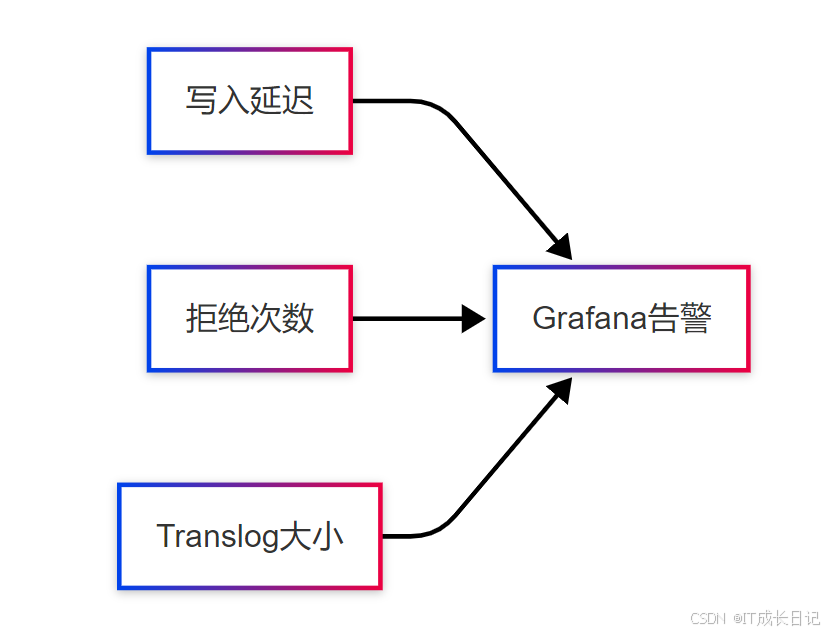
- 监控API:
GET _nodes/stats/indices/indexing
GET _cat/thread_pool/write?v7 总结
7.1 写入流程核心要点
- 两阶段提交:先写主分片,再同步副本
- 最终可搜索:refresh后数据才可见
- 持久化保证:Translog确保数据不丢失
7.2 生产环境建议
- 批量写入:始终使用Bulk API
- 合理分片:每个分片30-50GB为宜
- 监控Translog:防止磁盘空间耗尽
理解Elasticsearch的写入机制,才能根据业务场景做出最佳调优选择!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











