







目录
1 搜索流程全景图
Elasticsearch的搜索流程是一个 分布式查询处理系统,涉及多阶段的协同工作。整体流程可分为五个关键阶段:

2 核心概念解析
2.1 搜索相关组件
| 组件 | 作用 |
| 协调节点 | 接收查询请求,路由到数据节点,聚合最终结果 |
| 数据节点 | 存储索引数据,执行本地搜索操作 |
| 倒排索引 | 核心数据结构,实现高效文本检索 |
| Doc Values | 列式存储结构,用于排序和聚合 |
| Query Cache | 缓存过滤查询结果,提升重复查询性能 |
2.2 搜索类型对比
| 类型 | 特点 | 适用场景 |
| Query Then Fetch | 两阶段查询,精度高但延迟较高 | 需要精确排序的查询 |
| DFS Query Then Fetch | 全局计算相关性,性能代价大 | 相关性要求极高的场景 |
| Scan | 无排序高效遍历 | 大数据量导出 |
3 详细搜索流程
3.1 请求分发阶段
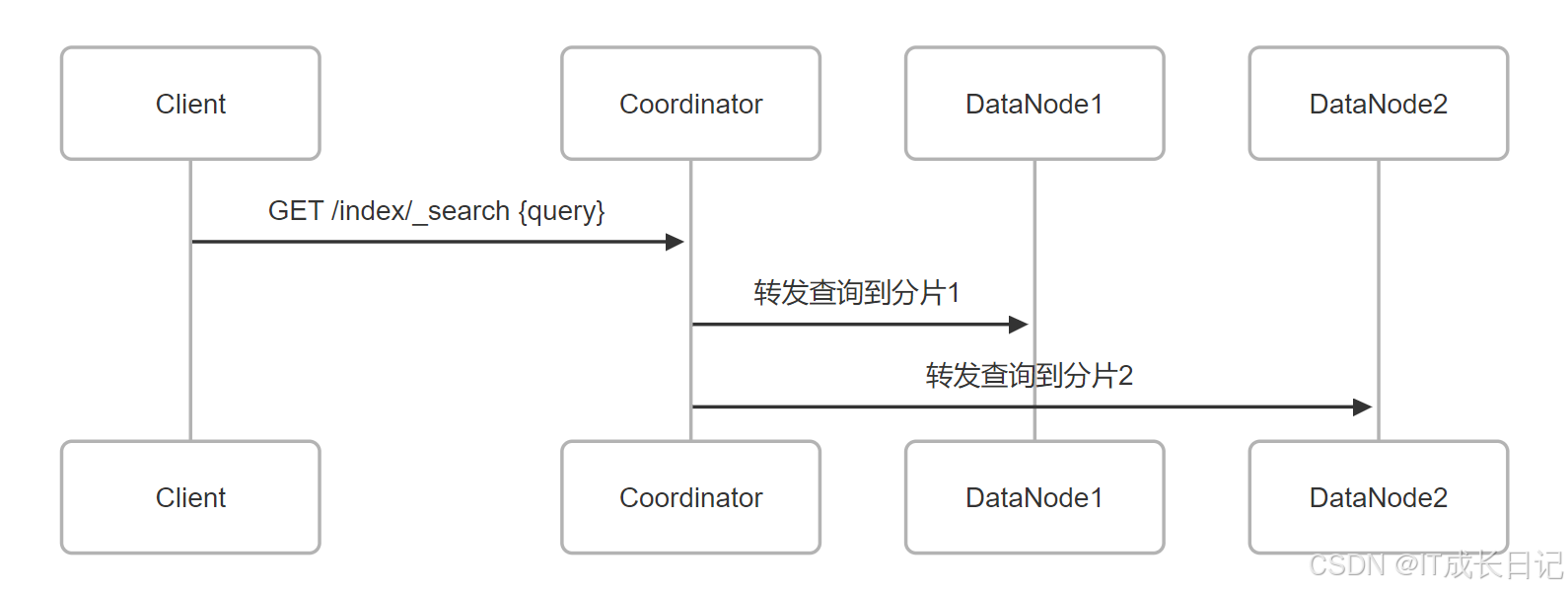
关键行为:
- 客户端发送请求到任意节点(成为协调节点)
- 协调节点确定涉及的所有分片(主分片或副本分片)
- 采用轮询策略选择副本分片(负载均衡)
3.2 分片级查询执行

Lucene查询流程:
- 词项查询:通过倒排索引定位文档
- 过滤条件:使用bitset快速过滤
- 评分计算:BM25/向量相似度等算法
- 结果收集:Top-N结果存入优先级队列
3.3 结果聚合阶段
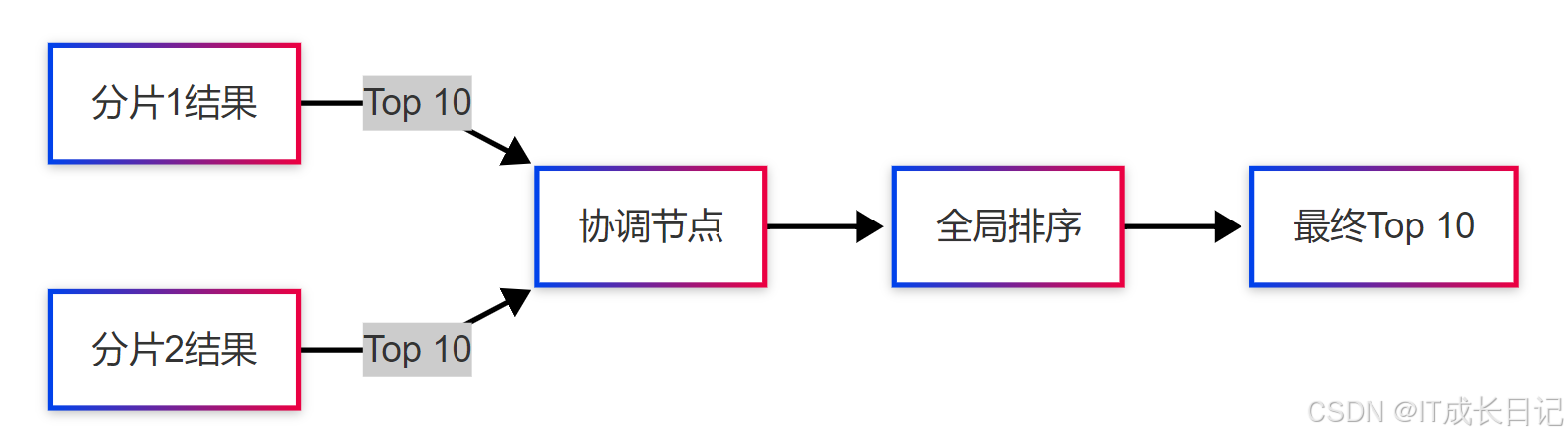
合并算法:
- N-way归并:对多个分片的结果队列合并排序
- 评分修正:当使用DFS模式时重新计算全局评分
4 特殊查询处理
4.1 聚合(Aggregation)流程

两级聚合机制:
- Shard Aggregation:各分片本地计算
- Reduce Phase:协调节点合并中间结果
4.2 高亮(Highlight)处理
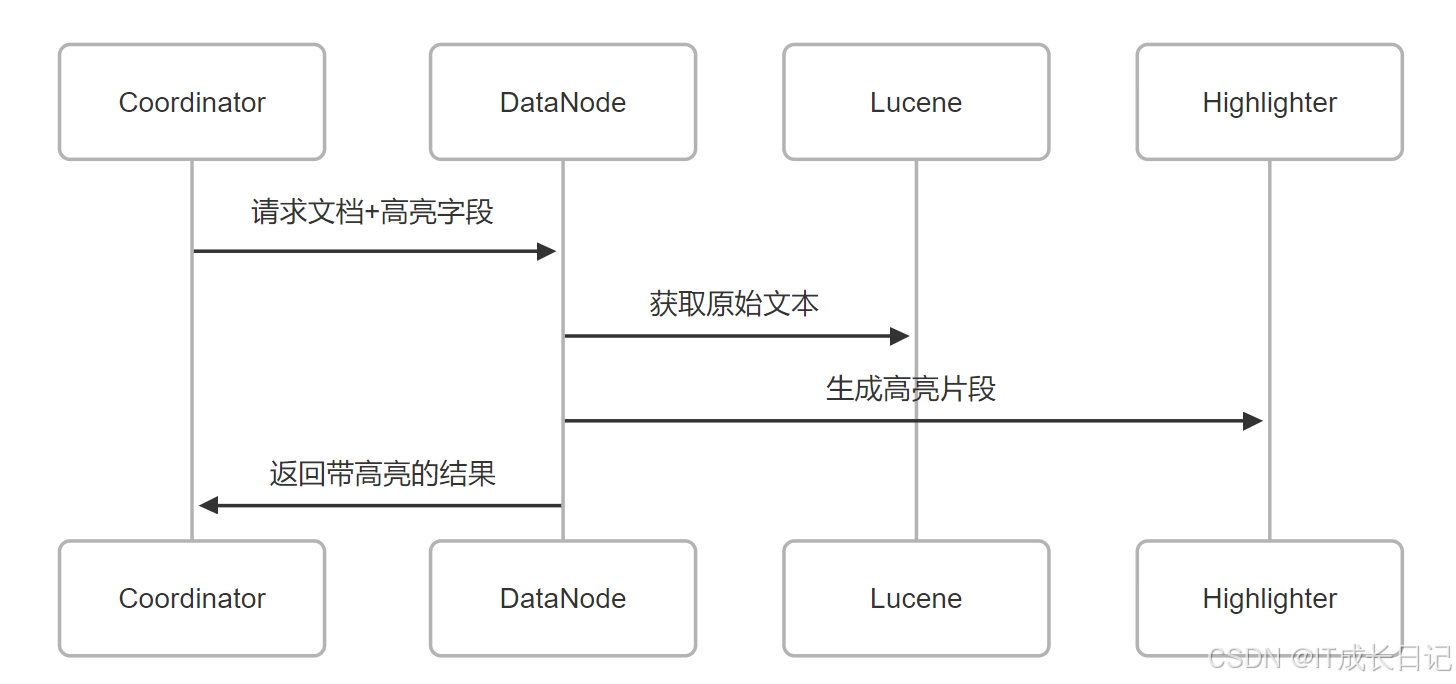
性能优化点:
- 使用"matched_fields": ["title", "content"]减少处理字段
- 设置no_match_size控制无匹配时的返回文本
5 性能优化策略
5.1 查询优化技巧
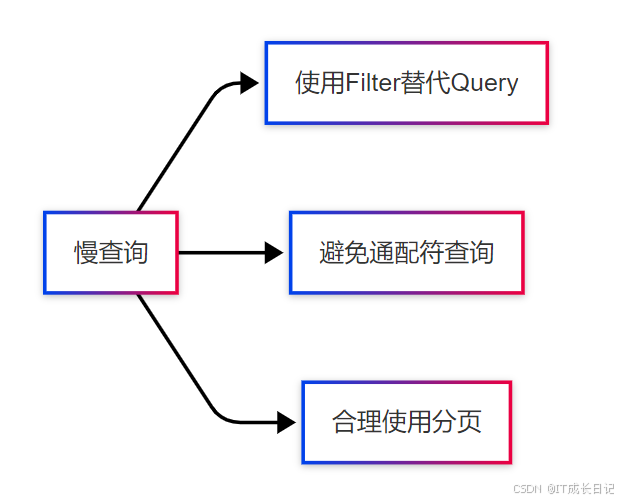
具体建议:
- Filter缓存:对不参与评分的条件使用filter上下文
- 分页优化:
{
"from": 10000,
"size": 10,
"sort": ["_doc"] // 避免深度分页性能陷阱
}5.2 硬件与参数调优
| 瓶颈类型 | 优化方案 |
| CPU | 增加数据节点分散查询负载 |
| 内存 | 为文件系统缓存预留50%内存 |
| 磁盘IO | 使用SSD并独立部署协调节点 |
- 关键参数:
# 调整查询线程池
thread_pool.search.size: 16
thread_pool.search.queue_size: 1000
# 控制单个查询资源
indices.query.bool.max_clause_count: 81926 监控与问题排查
6.1 慢查询分析

- 诊断命令:
GET /_search
{
"profile": true,
"query": {...}
}6.2 常见问题处理
问题1:结果不准确
- 检查分片状态:GET _cat/shards?v
- 验证副本同步:GET _stats?filter_path=**.verified_before_close
问题2:查询超时
POST /_search?timeout=10s
{
"timeout": "10s"
}7 总结
7.1 核心流程要点
- 分布式执行:查询并行发送到所有相关分片
- 两阶段聚合:先分片本地处理,再全局归并
- 智能路由:协调节点自动选择最优副本
7.2 生产建议
- 冷热分离:热数据使用SSD存储
- 查询熔断:设置max_result_window防止内存溢出
- 定期维护:通过_forcemerge减少段文件数量
理解Elasticsearch的搜索机制,才能针对不同场景设计最优查询方案。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











