1 Sqoop架构演进与设计哲学
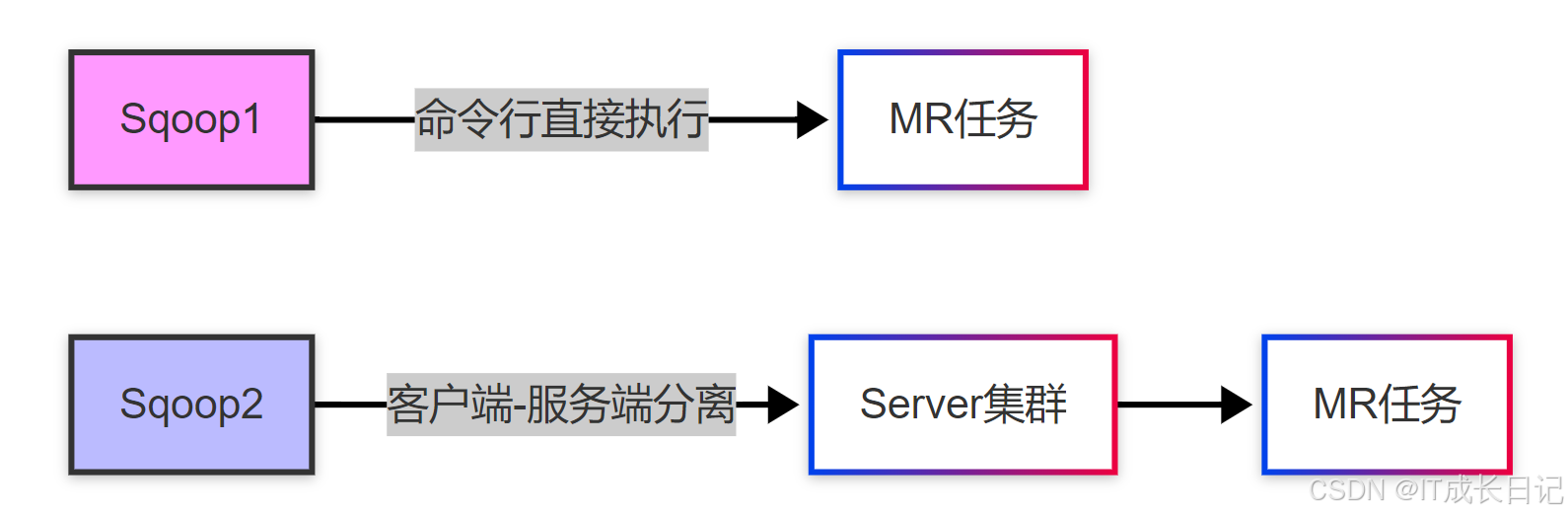
Sqoop作为Apache顶级项目,其架构设计经历了从简单到复杂的演进过程,体现了大数据工具设计的核心思想。最初版本的Sqoop(通常称为Sqoop 1)采用
直接命令行驱动的架构,而Sqoop 2则引入了
Client-Server模式,显著提升了系统的安全性和可管理性。
1.1 架构演进历程
- Sqoop1:轻量级但安全性差,客户端直接生成并提交MapReduce作业
- Sqoop2:引入中间服务层,实现权限集中管理、作业跟踪和资源隔离
- 权衡取舍:Sqoop2增加了部署复杂度但提升了企业级特性
1.2 设计核心原则
Sqoop架构设计遵循三个核心原则:
- 解耦原则:将用户接口与执行引擎分离
- 扩展性原则:通过连接器机制支持多种数据源
- 可靠性原则:内置故障恢复和重试机制
2 Client-Server模式深度剖析
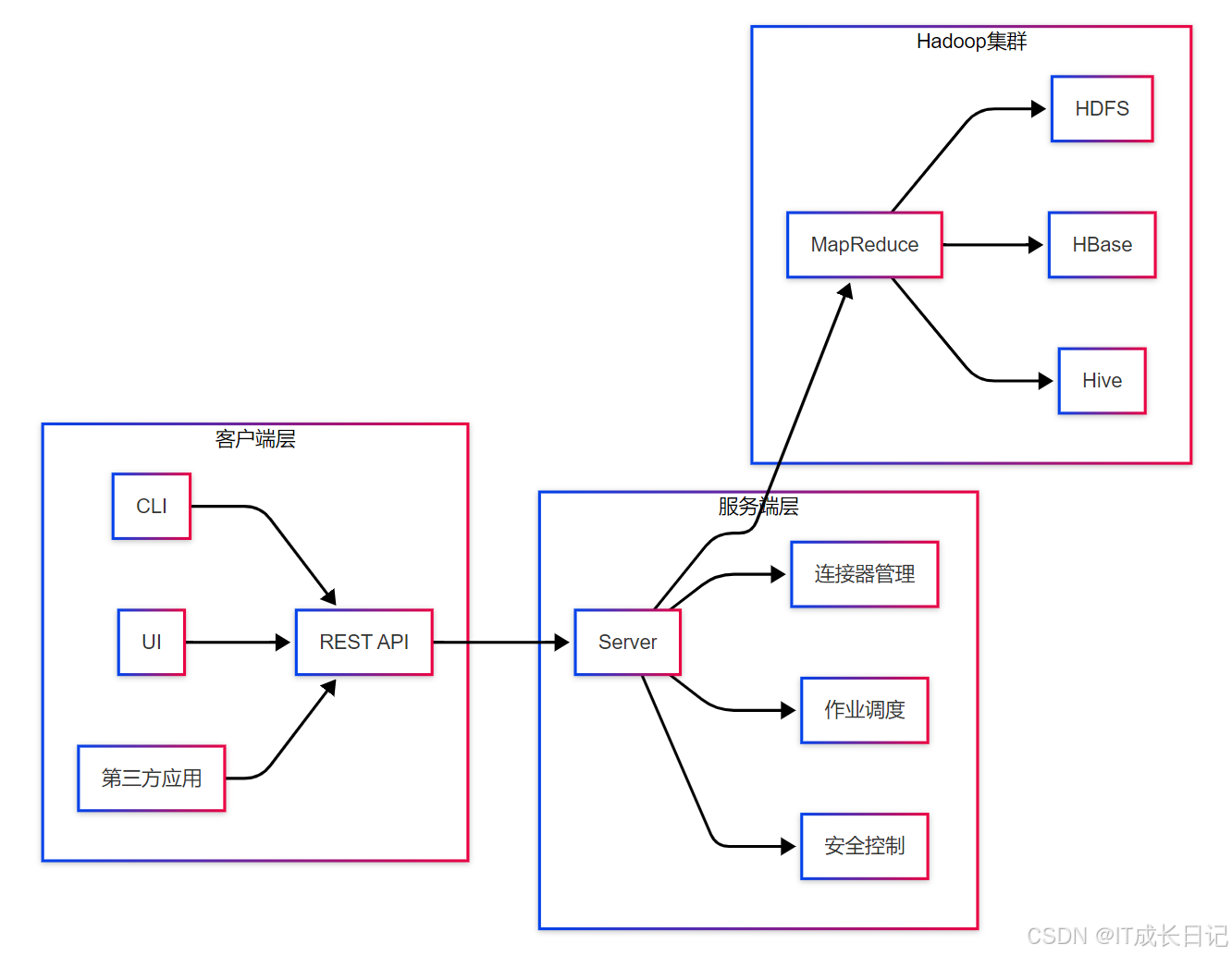
2.1 组件交互架构
客户端组件:
- CLI:命令行接口,用户主要交互方式
- Web UI:可视化操作界面(Sqoop2可选组件)
- REST API:标准化接口,支持第三方集成
服务端组件:
- 连接器管理:维护数据源连接器池
- 作业调度:协调任务执行顺序和资源分配
- 安全控制:Kerberos认证、权限管理等
执行引擎:
- MapReduce:默认执行引擎
- YARN:资源调度和管理
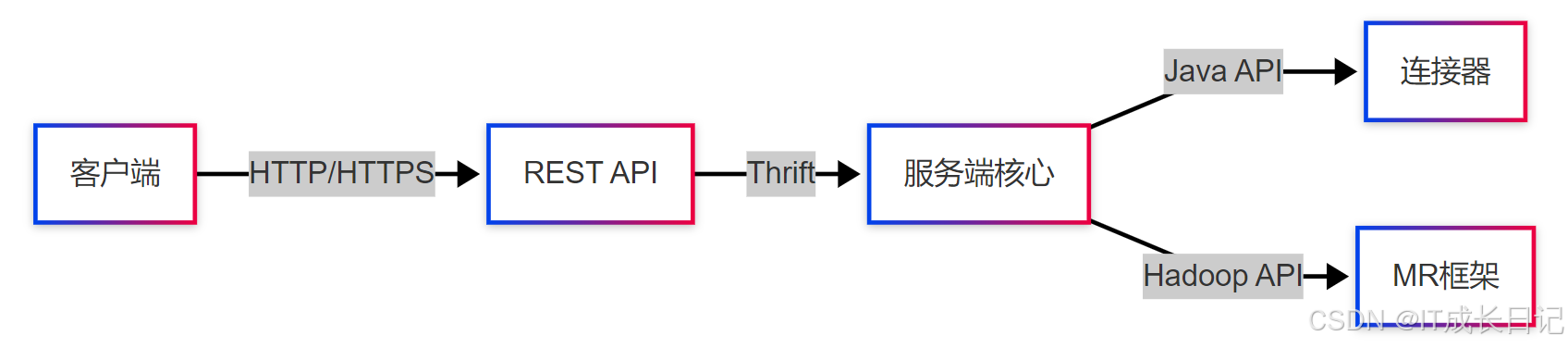
2.2 通信协议栈
协议选择考量:
- REST API用于前端通信,保证跨平台兼容性
- Thrift用于内部高性能RPC调用
- Hadoop原生API用于作业提交和监控
3 MapReduce任务执行全流程
3.1 执行流程
配置生成阶段:
- 合并默认配置和用户参数
- 验证必要参数完整性
- 准备连接器所需资源
分片策略阶段:
- 根据--split-by选择分片列
- 查询获取列的最小最大值
- 计算每个Mapper处理的数据范围
Mapper执行阶段:
- 每个Mapper建立独立数据库连接
- 执行分片查询(如id BETWEEN 1000 AND 2000)
- 将ResultSet转换为Hadoop兼容格式
3.2 分片策略详解
Sqoop的并行导入能力很大程度上依赖于其智能分片策略:
分片算法:
- 边界查询:执行SELECT MIN(split_col), MAX(split_col) FROM table
- 范围计算:根据mapper数量n,计算每个分片跨度:(max-min)/n
- 查询构造:生成n个形式为split_col >= x AND split_col < y的条件
示例:对于表employees,id范围1-1000,4个mapper:
- Mapper1:id BETWEEN 1 AND 250
- Mapper2:id BETWEEN 251 AND 500
- Mapper3:id BETWEEN 501 AND 750
- Mapper4:id BETWEEN 751 AND 1000
3.3 类型映射过程
典型映射示例:
- MySQL INT → java.sql.Types.INTEGER → IntegerWritable → Hive INT
- Oracle DATE → java.sql.Types.DATE → Text(ISO格式) → HBase String
4 连接器机制与扩展设计
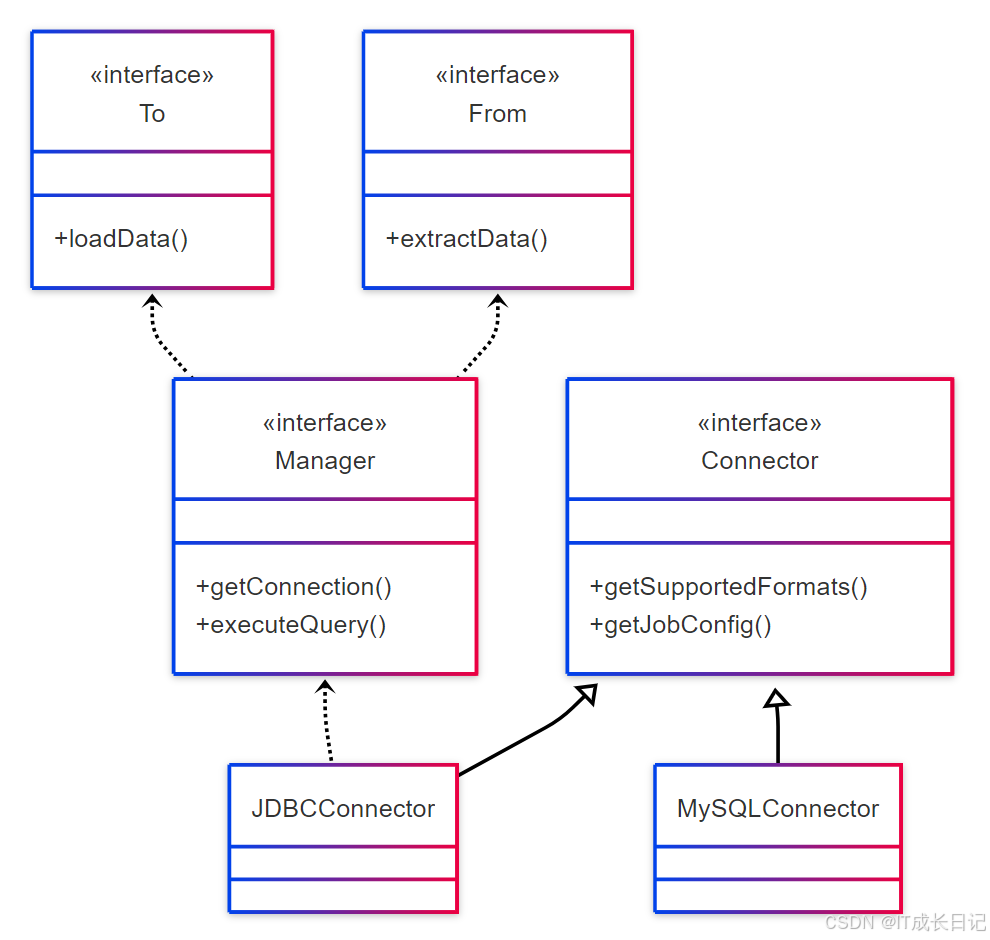
4.1 连接器类结构
核心接口职责:
- Connector:声明支持的数据格式和配置参数
- Manager:管理数据库连接和执行查询
- From:定义数据抽取逻辑
- To:定义数据加载逻辑
4.2 自定义连接器开发步骤
- 继承org.apache.sqoop.connector.spi.Connector基类
- 实现Partitioner接口支持并行抽取
- 在META-INF/services中注册SPI实现
- 遵循配置注解规范声明参数
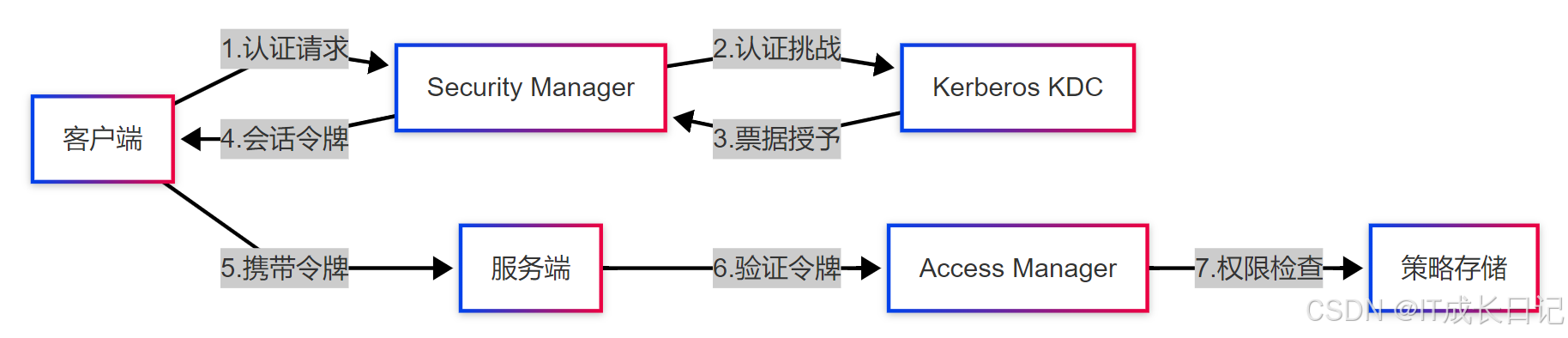
5 安全控制体系
5.1 认证授权架构
- 客户端发起认证请求,携带principal和keytab
- 服务端通过Kerberos KDC验证身份
- 建立加密会话通道
- 每个操作请求都进行RBAC权限检查
5.2 数据传输安全
加密策略:
- 数据库连接:SSL/TLS加密(需配置--ssl参数)
- 中间存储:HDFS透明加密(需配置加密Zone)
- 网络传输:SASL加密RPC通信
6 总结
Sqoop架构设计的核心要点:
- 分层设计:清晰的客户端-服务端分离,各司其职
- 扩展性:连接器机制支持多种数据源集成
- 可靠性:完善的错误处理和重试机制
- 安全性:企业级认证授权体系
Sqoop的架构设计充分体现了
关注点分离和
可扩展性的软件工程原则,理解这些设计思想不仅有助于更好地使用Sqoop,也能为开发类似的大数据工具提供宝贵参考。
































 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











