







目录
1 Doris简介
Apache Doris(原百度Palo)是一个基于MPP架构的高性能、实时的分析型数据库,主要用于解决海量数据的实时分析问题。Doris融合了Google Mesa和Apache Impala的技术思想,具有以下显著特点:
- 实时分析:支持实时数据导入和实时查询
- 高并发:可支持数千QPS的高并发查询
- 易用性:兼容MySQL协议,支持标准SQL
- 分布式:支持水平扩展,可处理PB级数据
Doris的这些特性使其广泛应用于用户行为分析、日志分析、广告数据分析等场景。
2 Doris存储格式概述
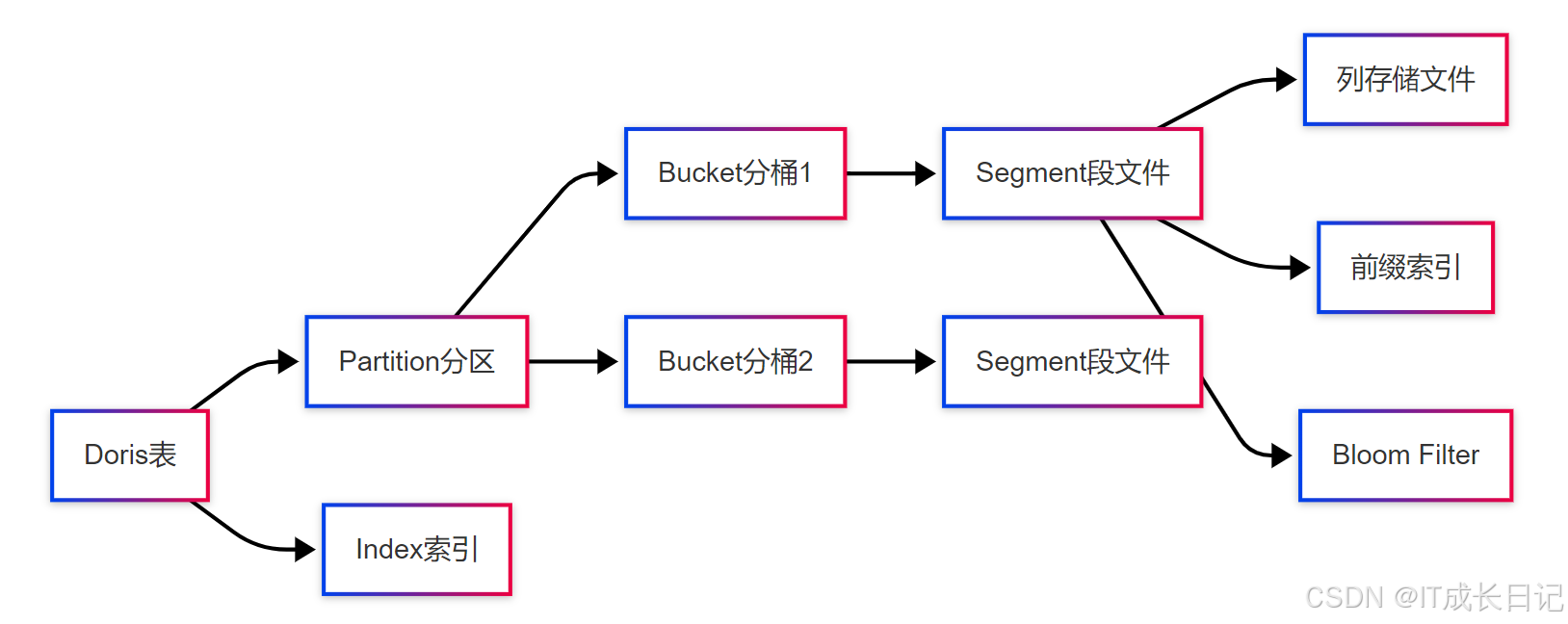
Doris的存储格式是其高性能的核心所在,它采用了列式存储、前缀索引、物化视图等多种优化技术。Doris的存储格式主要包含以下几个关键部分:
- 数据分区(Partition):表数据按照分区规则被水平划分
- 分桶(Bucket):每个分区内的数据进一步哈希分桶
- 列式存储(Column Storage):数据按列而非按行存储
- 索引结构(Index):包括前缀索引、Bloom Filter等
- 数据版本(Version):基于MVCC的多版本控制
3 数据分区(Partition)详解
3.1 分区概念
分区是Doris中最顶层的物理存储单元,一个表可以按照用户指定的分区规则划分为多个分区。分区的主要目的是:
- 数据管理:方便对数据进行生命周期管理
- 查询优化:通过分区裁剪减少扫描数据量
- 并行计算:不同分区可以并行处理
3.2 分区类型
Doris支持两种分区方式:
- Range分区:按照连续的区间范围划分,常用于时间维度
PARTITION BY RANGE(`dt`) (
PARTITION p202501 VALUES LESS THAN ('2025-02-01'),
PARTITION p202502 VALUES LESS THAN ('2025-03-01')
)- List分区:按照离散的值列表划分,常用于地区、类别等维度
PARTITION BY LIST(`city`) (
PARTITION pEast VALUES IN ('Shanghai', 'Beijing'),
PARTITION pWest VALUES IN ('Chengdu', 'Chongqing')
)3.3 分区管理
- Doris提供了丰富的分区管理操作:

- 添加分区:ALTER TABLE table ADD PARTITION p1 VALUES LESS THAN('2025-04-01')
- 删除分区:ALTER TABLE table DROP PARTITION p1
- 临时分区:用于数据修正的特殊分区
- 分区替换:通过临时分区实现原子替换
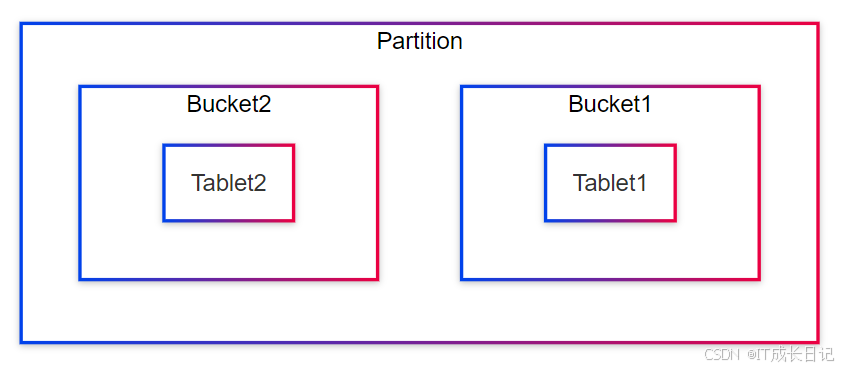
4 分桶(Bucket)机制
4.1 分桶概念
分桶是分区内的二次数据划分,通过哈希函数将数据均匀分布到各个桶中。分桶的主要作用:
- 数据均衡:保证数据均匀分布在各个节点
- 并行计算:分桶是并行计算的基本单位
- Join优化:相同分桶规则的表可进行Colocate Join
4.2 分桶配置
- 分桶配置示例:
DISTRIBUTED BY HASH(`user_id`) BUCKETS 104.3 分桶与并行查询

5 列式存储结构
5.1 列存优势
Doris采用列式存储,相比行存具有以下优势:
- 高压缩率:同类型数据压缩效率高
- 查询高效:只读取需要的列
- 向量化:支持SIMD指令优化
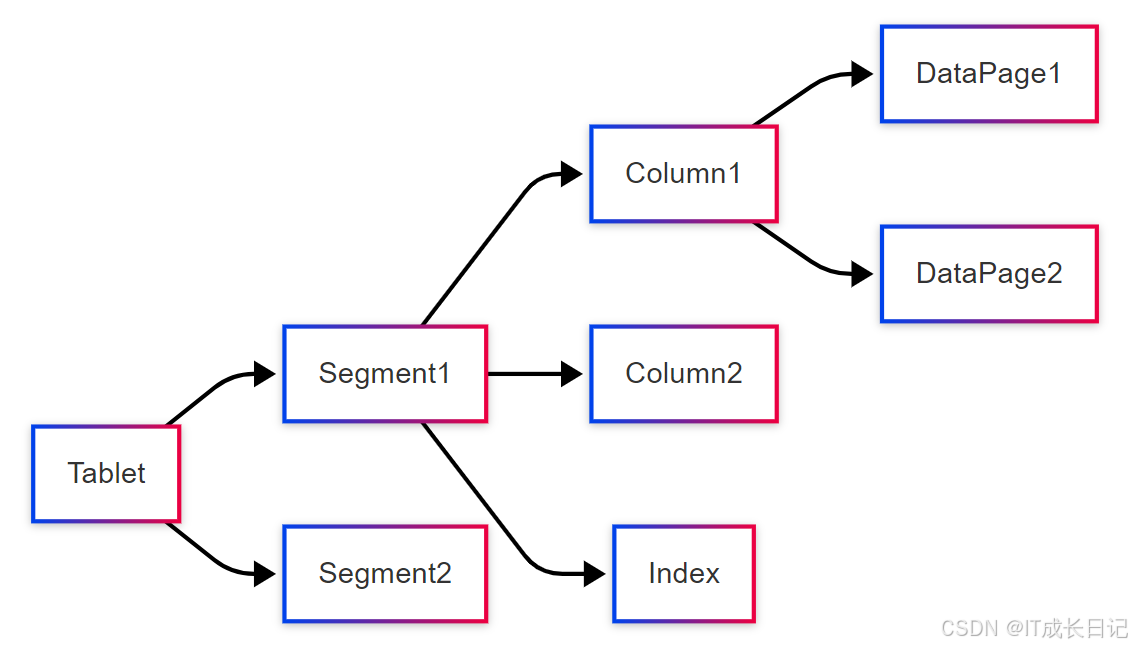
5.2 存储文件结构
- 每个Tablet的存储结构如下:
5.3 数据文件格式
Doris的数据文件采用自研格式,主要包含:
- 数据区:存储实际的列数据
- 元数据区:存储数据类型、压缩方式等信息
- 索引区:存储每列的索引信息
6 索引结构
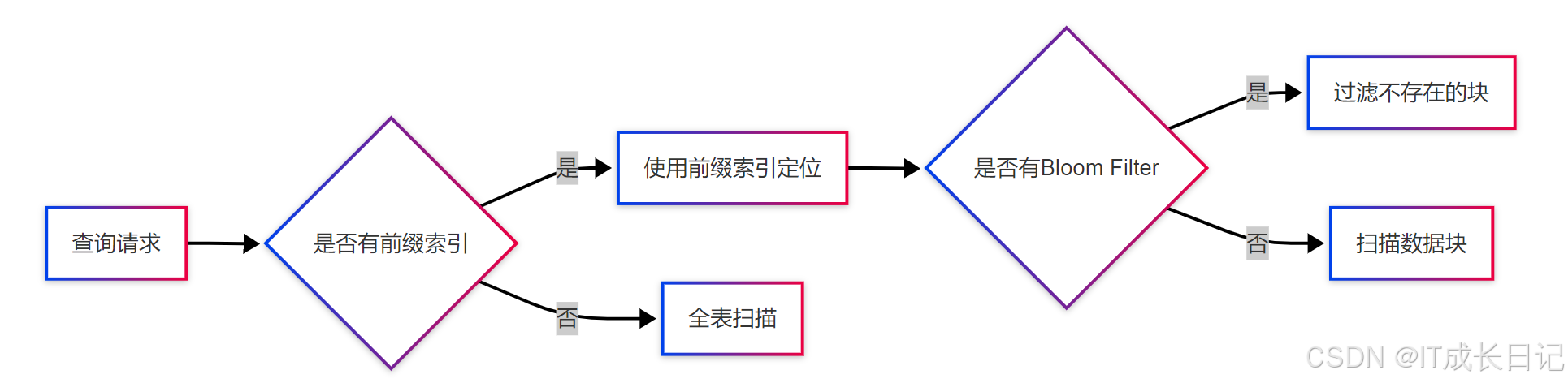
6.1 前缀索引
前缀索引是Doris特有的索引结构:
- 实现原理:对每行数据的前36字节建立稀疏索引
- 索引定位:通过二分查找快速定位数据位置
- 适用场景:适合点查询和高选择性查询
6.2 Bloom Filter
Doris为每个数据块创建Bloom Filter:
- 原理:概率型数据结构,判断"元素一定不存在"或"可能存在"
- 配置:可在建表时指定列创建Bloom Filter
PROPERTIES ("bloom_filter_columns"="user_name,email")6.3 索引使用流程
7 数据版本管理
7.1 版本概念
Doris采用多版本并发控制(MVCC)机制:
- 版本号:每次导入都会生成新版本
- 版本合并:定期将小版本合并为大版本
- 查询隔离:查询只能看到已提交的版本
7.2 版本文件结构

7.3 版本合并策略
Doris有两种合并策略:
- 小版本合并:自动将多个小版本合并为一个较大版本
- 全量合并:将所有版本完全合并为一个基准版本
8 压缩与编码
8.1 压缩算法
Doris支持多种压缩算法:
- LZ4:默认算法,平衡压缩率和速度
- ZSTD:高压缩率算法
- SNAPPY:快速压缩算法
8.2 编码方式
针对不同数据类型采用不同编码:
- 字典编码:低基数列
- 位图编码:布尔类型
- RLE:连续重复值
- 直接编码:无法优化的列
9 总结
Doris的存储格式经过精心设计,融合了多种先进技术:
- 分层存储:分区+分桶实现数据高效管理
- 列式存储:提高压缩率和查询效率
- 智能索引:前缀索引+Bloom Filter加速查询
- 版本控制:MVCC实现并发控制
这些设计使得Doris能够同时支持高并发点查询和复杂分析查询,成为实时分析场景的理想选择。通过合理配置分区、分桶和索引策略,可以充分发挥Doris的存储性能,满足不同业务场景的需求。


















 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











