







目录
2.1 指标聚合(Metrics Aggregations)
2.3 管道聚合(Pipeline Aggregations)
1 聚合概述
Elasticsearch 聚合(Aggregation)是 ES 提供的一种强大的数据分析功能,它允许你对数据进行分组、统计和提取摘要信息。聚合类似于 SQL 中的 GROUP BY 和聚合函数(如 COUNT, SUM, AVG 等),但功能更为强大和灵活。
1.1 什么是聚合
聚合是将数据汇总为度量、统计或其他分析的计算过程。在 Elasticsearch 中,聚合操作可以:
- 计算最小值、最大值、平均值、求和等
- 按字段值或自定义范围进行分组
- 执行复杂的统计分析
- 构建数据直方图或日期直方图
- 进行地理位置分析
1.2 聚合与查询的区别
| 特性 | 查询(Query) | 聚合(Aggregation) |
| 目的 | 查找匹配的文档 | 分析数据并提取统计信息 |
| 返回结果 | 文档列表 | 聚合结果(统计/分组数据) |
| 性能影响 | 影响相关性排序 | 影响资源使用(CPU/内存) |
| 使用场景 | 全文搜索、精确匹配 | 数据分析、报表生成 |
2 聚合类型
- Elasticsearch 提供了丰富的聚合类型,主要分为三类:
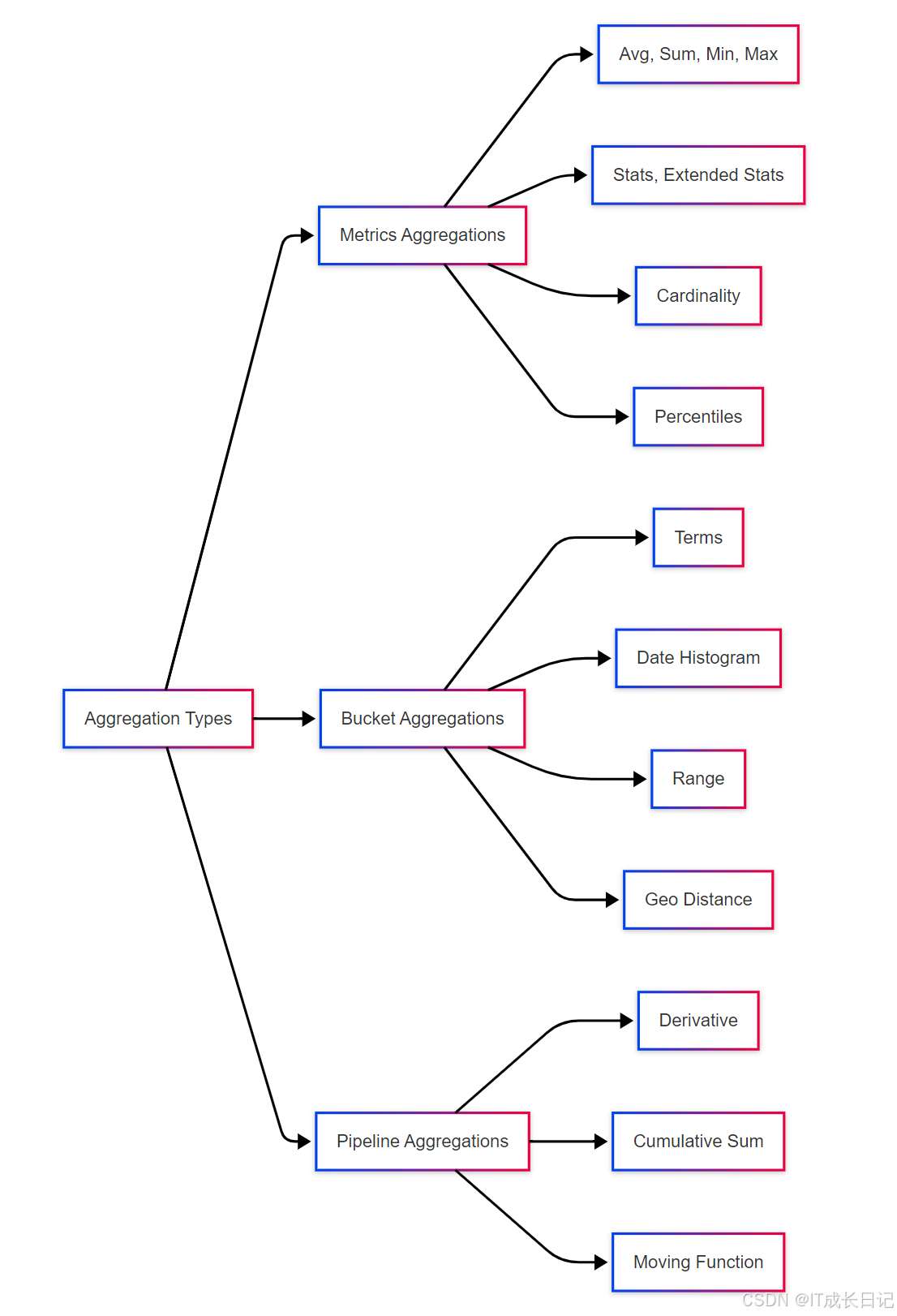
2.1 指标聚合(Metrics Aggregations)
指标聚合从文档中提取数值进行统计计算,常见的指标聚合包括:
- 基本统计:avg(平均值)、sum(求和)、min(最小值)、max(最大值)
- 高级统计:stats(基本统计汇总)、extended_stats(扩展统计)
- 基数统计:cardinality(类似SQL的COUNT DISTINCT)
- 百分位:percentiles(计算百分位数值)
- 地理统计:geo-centroid(计算地理坐标中心点)
2.2 桶聚合(Bucket Aggregations)
桶聚合将文档分配到不同的"桶"中,每个桶对应一个分组:
- Terms:按字段值分组,类似SQL的GROUP BY
- Date Histogram:按时间间隔分组
- Range:按数值范围分组
- Geo Distance:按地理距离分组
- Histogram:按数值间隔分组
2.3 管道聚合(Pipeline Aggregations)
管道聚合以其他聚合的结果作为输入进行再聚合:
- Derivative:计算派生值(如时间序列的导数)
- Cumulative Sum:计算累积和
- Moving Function:应用移动窗口函数
3 聚合语法结构
- Elasticsearch 聚合查询的基本语法结构如下:
{
"aggs": {
"aggregation_name": {
"aggregation_type": {
"aggregation_body"
},
"meta": {
"metadata"
}
}
}
}3.1 聚合请求流程
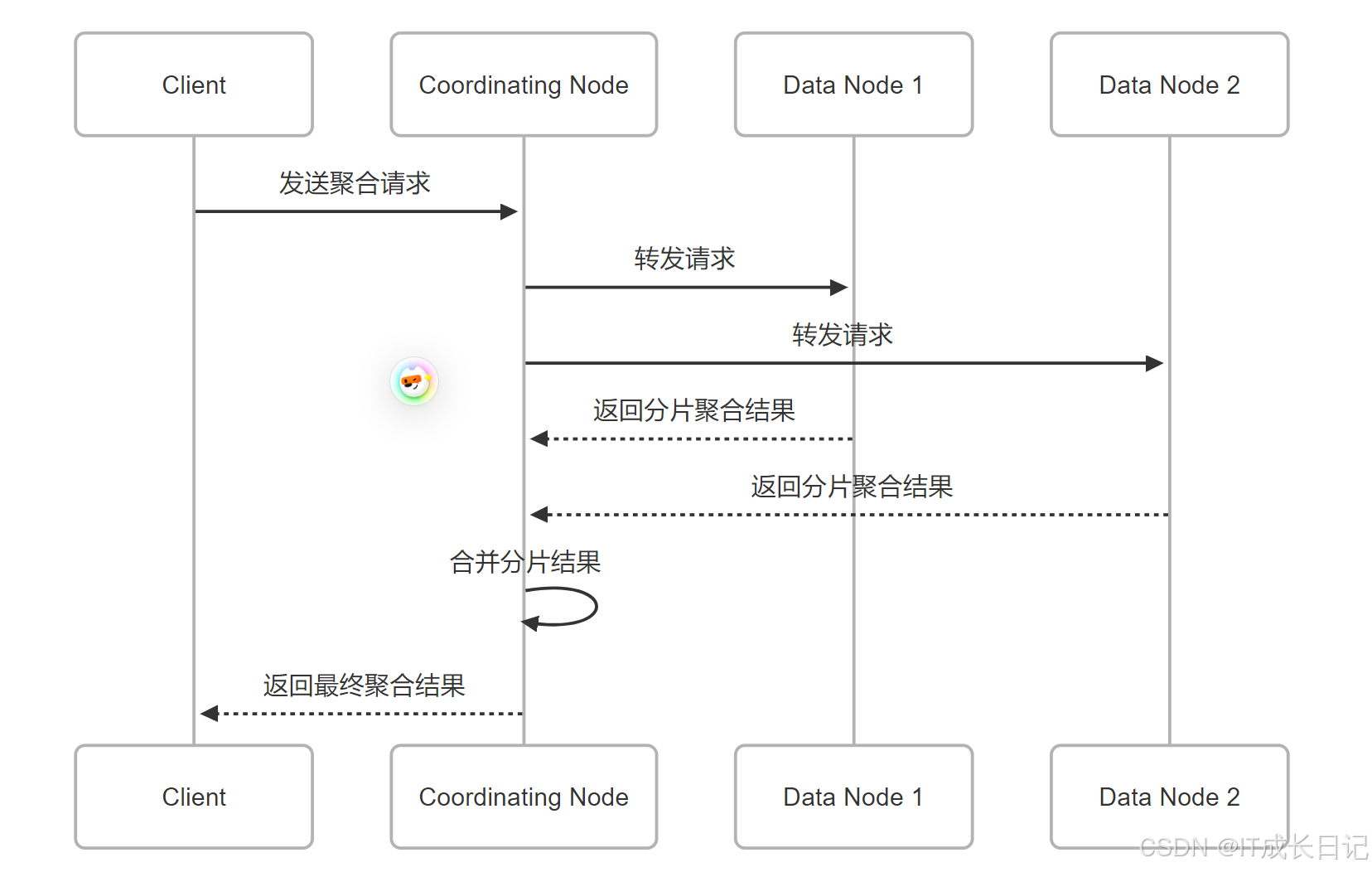
- 客户端发送聚合请求到协调节点
- 协调节点将请求转发到相关数据节点
- 各数据节点执行本地聚合
- 协调节点收集各分片结果并合并
- 将最终聚合结果返回给客户端
4 常用聚合详解
4.1 指标聚合示例
4.1.1 基本统计
{
"aggs": {
"avg_price": {
"avg": { "field": "price" }
},
"max_rating": {
"max": { "field": "rating" }
}
}
}4.1.2 扩展统计
{
"aggs": {
"price_stats": {
"extended_stats": {
"field": "price"
}
}
}
}4.2 桶聚合示例
4.2.1 Terms 聚合
{
"aggs": {
"genres": {
"terms": {
"field": "genre",
"size": 5
}
}
}
}4.2.2 Range 聚合
{
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 50 },
{ "from": 50, "to": 100 },
{ "from": 100 }
]
}
}
}
}4.2.3 Date Histogram聚合
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
}
}4.3 复合聚合示例
- 聚合可以嵌套使用,先分桶再计算指标:
{
"aggs": {
"genres": {
"terms": {
"field": "genre"
},
"aggs": {
"avg_price": {
"avg": { "field": "price" }
}
}
}
}
}5 聚合性能优化
5.1 聚合执行原理

- 查询阶段:确定哪些文档参与聚合
- 收集阶段:从Doc Values中收集字段数据
- 构建聚合:根据聚合类型构建中间结果
- 归约阶段:合并各分片结果
- 返回最终结果
5.2 优化建议
- 使用Doc Values:确保聚合字段启用了doc_values
- 合理设置size参数:避免返回过多桶
- 使用近似聚合:如cardinality使用HyperLogLog++
- 使用filter查询:减少参与聚合的文档数量
- 使用partition参数:大数据集时分区计算
- 避免深度分页:使用composite聚合替代
6 高级聚合技巧
6.1 嵌套聚合与子聚合
{
"aggs": {
"countries": {
"terms": { "field": "country" },
"aggs": {
"cities": {
"terms": { "field": "city" },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}
}
}6.2 过滤聚合
{
"aggs": {
"high_ratings": {
"filter": { "range": { "rating": { "gte": 4 } } },
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}6.3 全局聚合
{
"query": { "match": { "genre": "comedy" } },
"aggs": {
"all_products": {
"global": {},
"aggs": {
"avg_price": { "avg": { "field": "price" } }
}
}
}
}6.4 矩阵聚合
{
"aggs": {
"matrix_stats": {
"matrix_stats": {
"fields": ["price", "rating", "duration"]
}
}
}
}7 常见问题与解决方案
7.1 聚合精度问题
问题:基数统计(cardinality)不精确解决方案:调整precision_threshold参数,值越大精度越高但内存消耗越大
7.2 内存限制问题
问题:聚合导致内存不足解决方案:
- 增加indices.breaker.request.limit设置
- 使用更小的size参数
- 考虑使用composite聚合分批获取
7.3 性能优化问题
问题:聚合查询响应慢解决方案:
- 使用filter减少文档范围
- 避免在text字段上聚合
- 使用eager_global_ordinals优化高基数字段
8 总结
Elasticsearch 聚合提供了强大的数据分析能力,合理使用聚合功能可以极大地提升数据分析和洞察能力,是 Elasticsearch 作为搜索和分析引擎的核心价值之一。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











