







1. 集群节点介绍
| 节点名称 | ip | myid |
|---|---|---|
| Z1 | 192.168.127.201 | 1 |
| Z2 | 192.168.127.202 | 2 |
| Z3 | 192.168.127.203 | 3 |
| Z4 | 192.168.127.204 | 4 |
| Z5 | 192.168.127.205 | 5 |
2. 选举和数据同步
投票相关属性
- state: 当前服务器的状态(LOOKING,FOLLOWING ,LEADING,OBSERVING)
- logicClock: 每个服务器会维护一个自增的整数,名为logicClock,它表示这是该服务器发起的第多少轮投票
- self_sid: 投票服务器的myid,dataDir下的myid文件配置
- self_zxid:投票服务器的最大事务id
- vote_sid: 被推举方服务器myid
- vote_zxid: 被推举方服务器事务id,集群产生一个事务时,就会为该事务分配一个标识符,也就是 zxid。zxid 是一个 long 型(64位)整数, 低32代表一个单调递增的计数器,高32位代表Leader周期。
- recvset: 收到投票集合即票箱,Map<Long,Vote>其中key记录sid,vote存放选票实体数据即被推举方服务器数据
- zxid:事务id,long类型,长度为64位。每次对zookeeper集群节点的写操作都会生成一个zxid,高32位为当前leader节点的epoch,选取新的leader时,高32位会递增+1。低32位为当前leader下集群节点写操作的顺序编码,数值递增+1,如果更换leader,高32位会+1,低32位会初始化为0,保证了事务id都是递增的属性。
2.1 集群首次启动
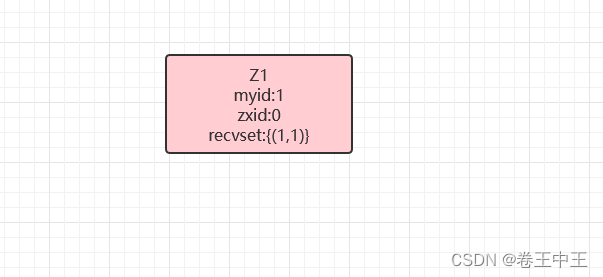
2.1.1 启动Z1节点,Z1节点首先初始化logicClock为1,清空自己的投票箱(recvset),然后会把票投给自己(1,1),由于当前集群只有Z1节点,不足集群半数以上节点,所以此时Z1节点状态为LOOKING,集群无法提供服务。
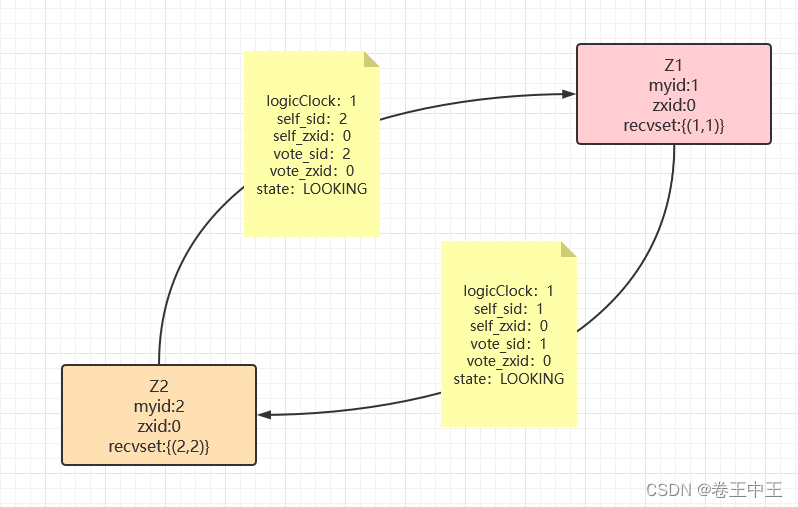
2.1.2 启动Z2节点,Z2节点首先会初始化logicClock为1,清空自己的投票箱(recvset),然后投票給自己(2,2)。此时集群中存在Z1和Z2两个节点,这两个节点会进行广播自己的投票信息。Z1节点收到Z2节点的投票信息,首先判断logicClock是否相同,判断是否是统一论投票,如果相同会进行选票pk。由于集群刚刚启动事务id(zxid)都为0,所以会进行pk-myid,会投给myid最大的节点。由于Z2节点myid大于Z1节点myid,所以Z1会修改自身投票,投票給Z2。有Z2大于Z1,Z2的投票不会修改。此时节点都为LOOKING,服务仍不可用
选票PK: 用自己的选票跟接收到的外部选票信息比较pk核心方法totalOrderPredicate,依次比较peerEpoch/logicClock(选票轮次)、zxid(被推举服务器事务id)、leader/vote_id(被推举服务器myid);如果接收到的外部选票信息能够胜出则把自己的选票改为对方的投票,并把自己接收的选票信息和自己更新后的选票记录入票箱
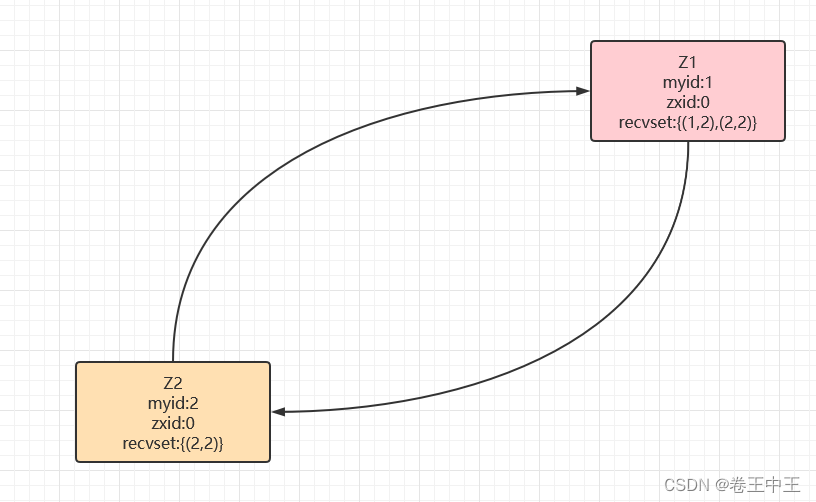
2.1.3 启动Z3节点 ,Z2节点首先会初始化logicClock为1,清空自己的投票箱(recvset),然后投票給自己(3,3)。此时集群节点为Z1,Z2,Z3,分别广播自己的投票信息。
Z1节点会收到Z2和Z3节点的投票信息,由于logicClock相同和事务id相同,会进行myid比较,Z3的myid最大,此时Z1节点会更改自己的投票,此时Z1的投票箱为(1,3)(3,3)。
Z2节点会收到Z1和Z3的投票信息,由于Z3的myid较大,Z2节点会修改自己的投票为Z3,此时Z2节点的投票箱为(2,3)(3,3)。
Z3节点收到Z1和Z2的投票信息,由于Z3节点的myid最大,所以Z3节点不会修改自己的投票,Z3节点的投票箱为(3,3)
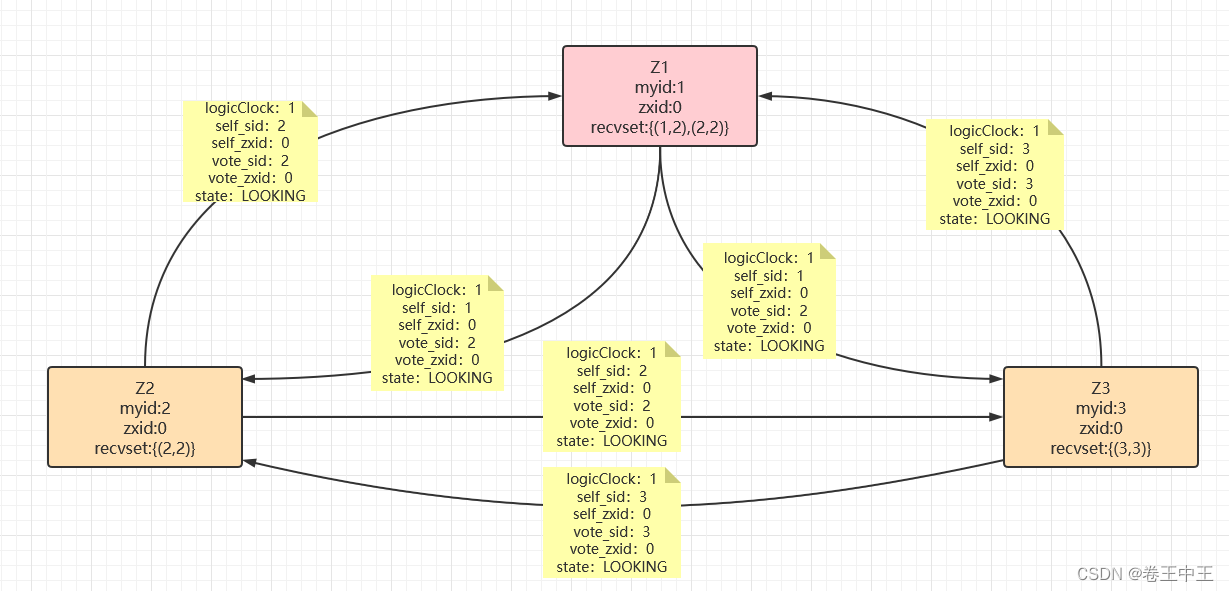
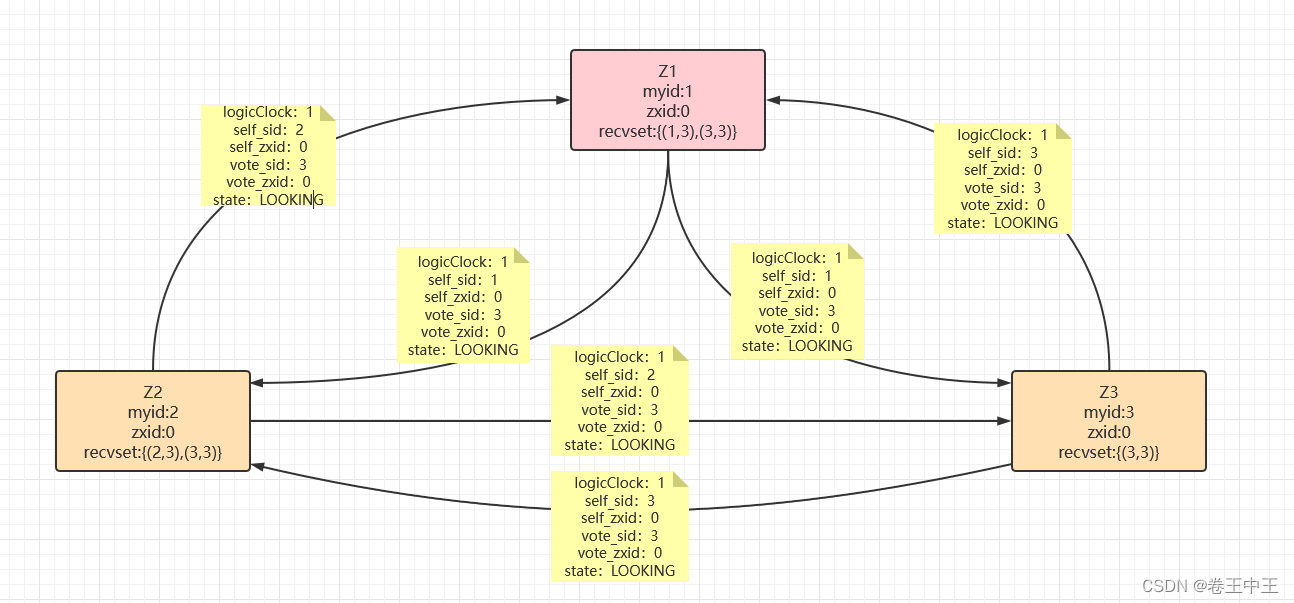
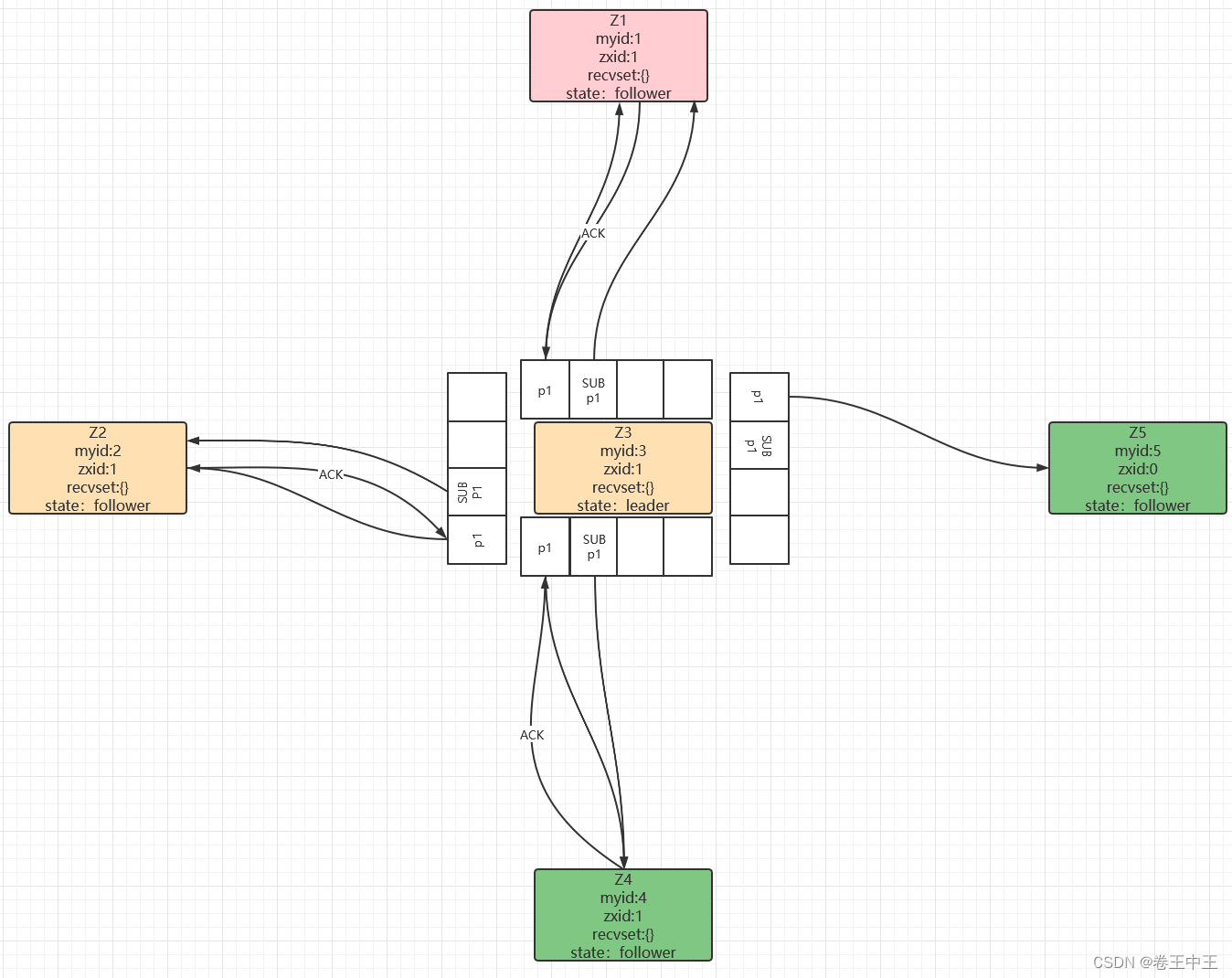
2.1.4 通过统计票数,此时Z1->Z3,Z2->Z3,Z3->Z3。Z3得到3票,已经达到5/2+1=3(半数以上节点投票,5为配置文件中配置的集群的节点个数)票,Z3会获取集群中的最大epoch然后+1,然后向所有支持自己的节点进行同步,由于集群刚刚启动,没有数据进行同步,收到ACK之后,Z3成为leader节点,Z2和Z1节点为follower节点,此时集群可以对外提供服务。
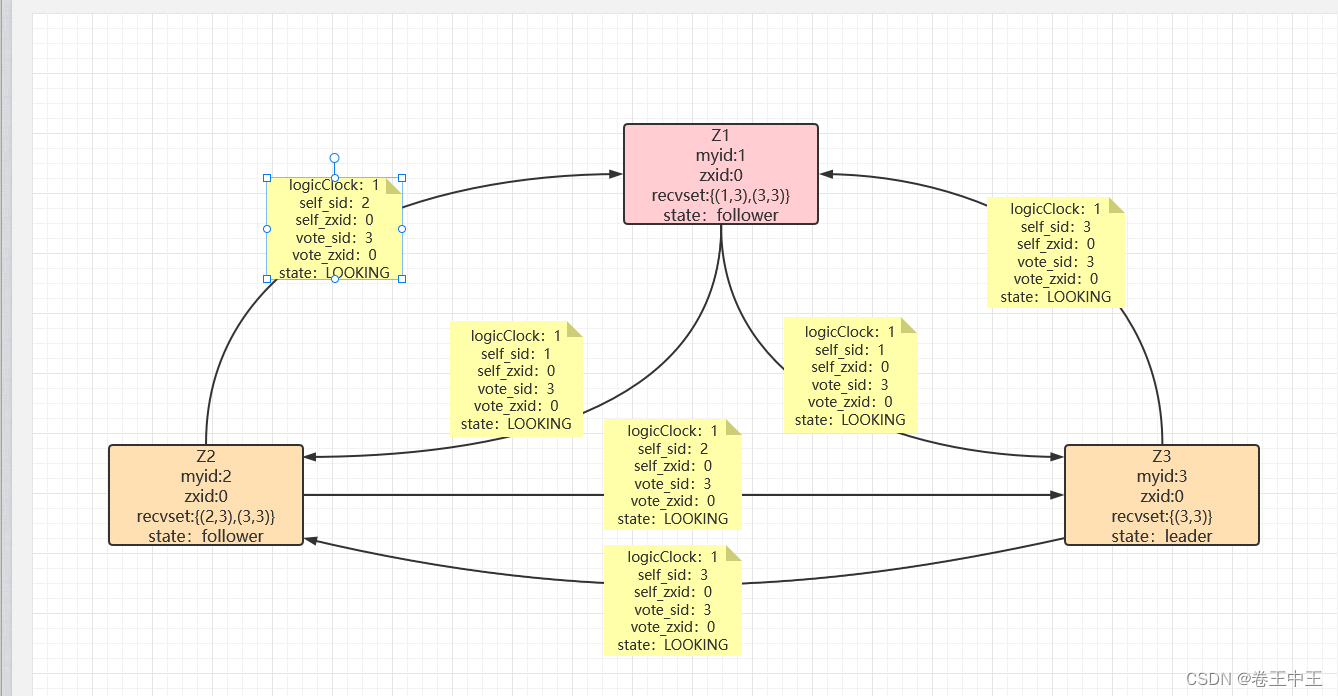
2.1.5 启动Z4节点,Z4节点首先会初始化logicClock为1,清空自己的投票箱(recvset),然后投票給自己(4,4)。由于在和其他节点通信时,发现集群中已经存在leader节点Z3,然后会和其他节点通信,同步leader信息,修改自己的节点为follower
 2.1.6 启动Z5节点,同理成为follow节点
2.1.6 启动Z5节点,同理成为follow节点

2.2 集群接受写请求
2.2.1 当客户端发起事务操作时,如果请求follower节点,请求会被转发給leader节点处理。当leader节点接收到客户端的事务操作时,首先会把Zxid自增1,然后会把zxid和事务操作放到一个FIFO的队列(每个follower一个队列)里,follower节点从队列获取数据进行同步。
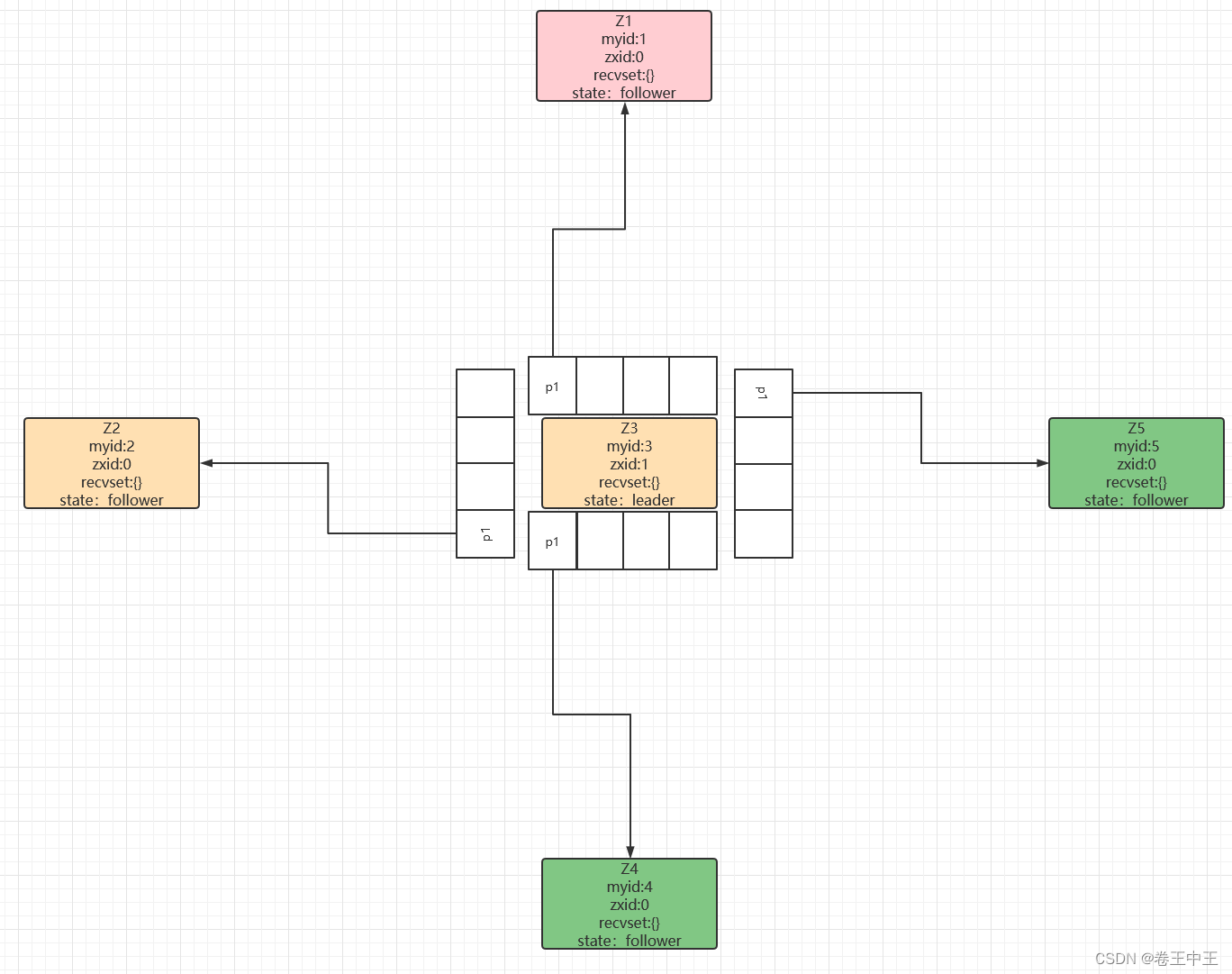
2.2.2 follower节点收到事务操作时,会把事务操作写到自己的事务日志中,然后回复leader节点一个ACK。
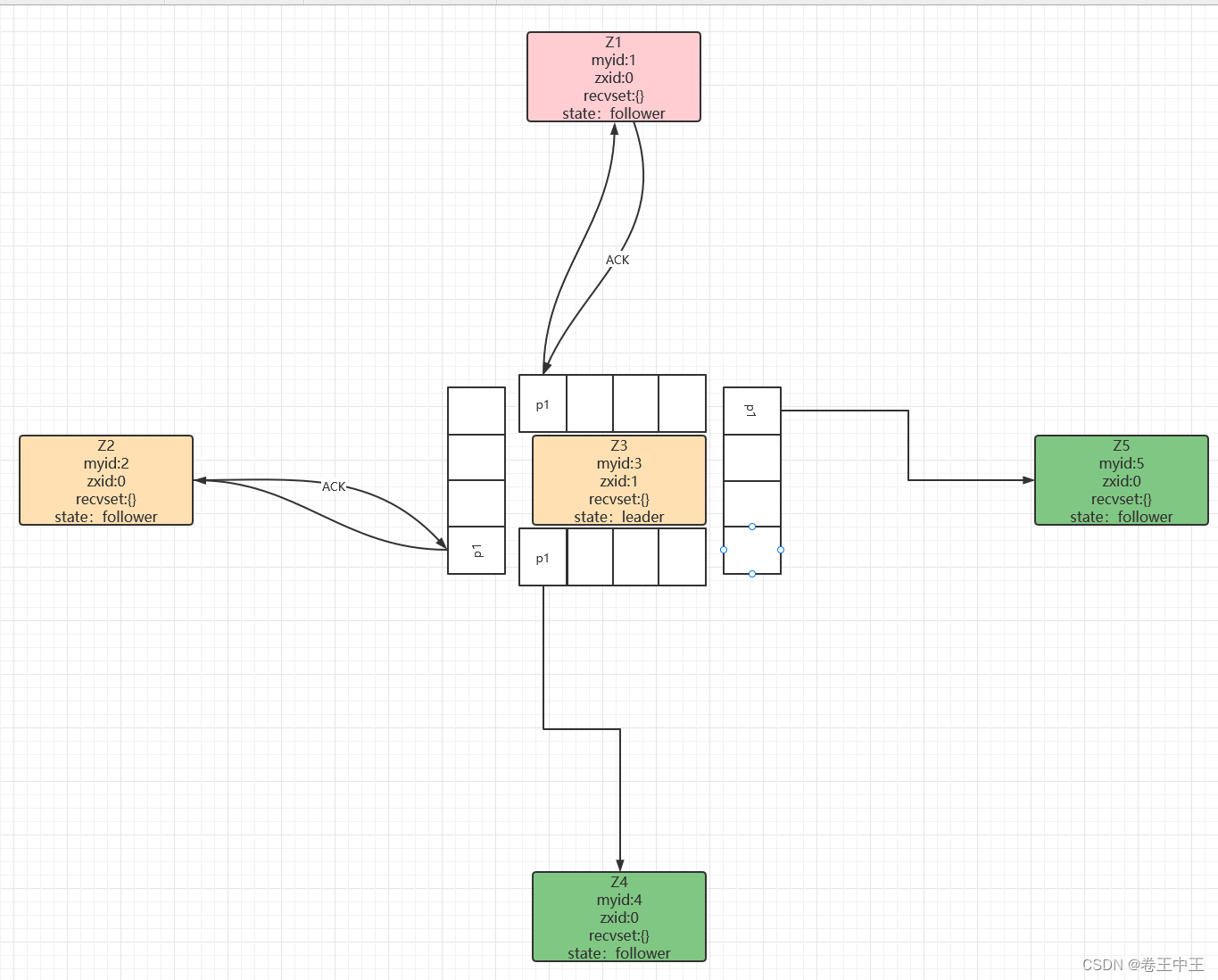 2.2.3 当leader节点收到半数以上的节点的ACK(包含leader本身自己的ACK)后,leader节点会广播一个submit的操作。此时leader对这个事务操作会真正执行,修改zookeeper节点数据。
2.2.3 当leader节点收到半数以上的节点的ACK(包含leader本身自己的ACK)后,leader节点会广播一个submit的操作。此时leader对这个事务操作会真正执行,修改zookeeper节点数据。

2.2.4 follower节点收到SUBMIT指令时(不是提交之前的所有事务,而是只提交p1),会把p1事务提交,然后修改自己的ZXID为1,其他follower节点如果由于某种原因同步比较慢时,仍然可以通过执行leader节点的队列数据进行完整数据同步。
2.3 故障恢复
2.3.0 当集群运行一段时间后,leader突然宕机。当其中一个follower节点通过心跳机制发现leader节点已经宕机时,会自增logicClock,首先任然会先把票投给自己,然后广播自己的投票信息。其他follower节点收到投票时会判断leader是否存活,发现leader已经宕机后,会进行新一轮的选主投票。集群如LOOKING状态,zookeeper集群服务不可用
2.3.1 首先follower节点会自增自己的logicClock,清空自己的投票箱(recvset)然后投票给自己,广播自己的投票信息。
此时集群状态:
| 节点 | self_id | self_zxid | vote_id | vote_zxid |
|---|---|---|---|---|
| Z1 | 1 | 8 | 1 | 8 |
| Z2 | 2 | 5 | 2 | 5 |
| Z4 | 4 | 6 | 4 | 6 |
| Z5 | 5 | 8 | 5 | 8 |
2.3.2 follower节点收到其他follower节点的投票信息时,首先会比较Zxid,Zxid越大,表示此节点的数据比较全,如果Zxid相同时,就会比较myid,myid大的作为leader
Z1 节点收到来自Z2,Z4,Z5节点的投票信息,通过比较,发现虽然和Z5节点的Zxid一样大,但是Z5的myid更大,所以最终会把票投给Z5。修改自己的票箱(1,5)(5,5),更改投票信息void_id=5, void_zxid=8.
Z2 节点收到来自Z1,Z4,Z5节点的投票信息,通过比较,发现Z5节点的Zxid最大,所以最终会把票投给Z5。修改自己的票箱(2,5)(5,5),更改投票信息void_id=5, void_zxid=8.
Z4 节点收到来自Z1,Z2,Z5节点的投票信息,通过比较,发现Z5节点的Zxid最大,所以最终会把票投给Z5。修改自己的票箱(4,5)(5,5),更改投票信息void_id=5, void_zxid=8.
Z5 节点收到来自Z1,Z2,Z4节点的投票信息,通过比较,发现虽然和Z1节点的Zxid一样大,但是自身的的myid更大。不改变自己的票箱(5,5),更改投票信息void_id=5, void_zxid=8.
2.3.3 通过进行票数统计,发现Z5节点得到了半数以上的节点的投票。此时节点Z5为leader,Z1,Z2,Z4为follower,下一步会进行数据同步。
2.4 数据同步阶段
2.4.1 通过2.3的选举Z5节点被选为leader节点。leader节点会向所有的follower节点发送选举epoch的请求。所有的follower节点会收到请求后,会发送自己的learnerInfo数据,里面包含了当前节点的最大事务id(Zxid),从Zxid中的高32位中可以获取到每个节点的最大epoch。
2.4.2 当leader节点收到超过半数节点的learnerInfo时,从半数以上的节点中获取最大的epoch,然后进行epoch+1。
2.4.3 leader节点会发送统一epoch的请求,把自增后的epoch发送給所有的follower节点。当follower节点收到新的epoch时,会修改自己的epoch数据,然后回复leader一个ACKEpoch的请求。
2.4.4 当leader节点收到半数以上的ACKEpoch回复时,leader节点会接受所有的follower节点的连接,为每一个follower节点开启一个新的线程进行数据同步
数据同步名词解释:
peerLastZxid:表示follower上最大的zxid
lastProcessedZxid:表示Leader上最大的zxid
maxCommittedLog:表示CommittedLog队列中最大的CommittedLog
minCommittedLog:表示CommittedLog队列中最小的CommittedLog
2.5 数据同步的四种方式
1. 直接差异化同步(DIFF同步)
2. 先回滚再差异化同步(TRUNC+DIFF同步)
3. 仅回滚同步(TRUNC同步)
4. 全量同步(SNAP同步)
2.5.1 直接差异化同步(DIFF同步)
场景描述:条件minCommittedLog <= peerLastZxid <= maxCommittedLog
比如Z5为leader,提议缓存队列的minCommittedLog = 0x500000001,maxCommittedLog = 0x500000005
Z1节点为follower,peerLastZxid=0x500000003
Z5节点会把和Z1节点的差异按照顺序进行发送同步指令,每个事务包含两个数据包分别为PROPOSAL和COMMIT。
Z1收到的数据包顺序如下
| 顺序 | 操作类型 | Zxid |
|---|---|---|
| 1 | PROPOSAL | 0x500000004 |
| 2 | COMMIT | 0x500000004 |
| 3 | PROPOSAL | 0x500000005 |
| 4 | COMMIT | 0x500000005 |
| 5 | NEWLEADER |
2.5.2 仅回滚同步(TRUNC同步)
场景描述:条件peerLastZxid > maxCommittedLog
如果:Z3为原来的leader节点,peerLastZxid = 0x500000006
Z3宕机,此时0x500000006还没有COMMIT到其他节点。
Z5为新选举的leader,此时Z5的maxCommittedLog=0x500000005
Z3再次加入到集群时,会向Z5进行数据同步,此时 需要回退数据
数据包如下:
| 顺序 | 操作类型 | Zxid |
|---|---|---|
| 1 | TRUNC | 0x500000005 |
| 2 | NEWLEADER |
2.5.2 先回滚再差异化同步(TRUNC+DIFF同步)
场景描述:peerLastZxid 存在不属于minCommittedLog maxCommittedLog范围内的数据,但是部分属于这个区间
比如:Z3节点为原leader节点,peerLastZxid = 0x500000006
Z3宕机,此时0x500000006还没有COMMIT到其他节点。
然后Z5为新选举的leader节点,然后集群运行一段时间接收了信息请求 0x600000001,0x600000002
此时Z5的事务队列为…0x500000004,0x500000005,0x600000001,0x600000002
Z3向Z5同步时,需要先回滚数据到0x500000005,然后同步新数据。
接收的数据顺序如下:
| 顺序 | 操作类型 | Zxid |
|---|---|---|
| 1 | TRUNC | 0x500000005 |
| 2 | PROPOSAL | 0x600000001 |
| 3 | COMMIT | 0x600000001 |
| 4 | PROPOSAL | 0x600000002 |
| 5 | COMMIT | 0x600000002 |
| 6 | NEWLEADER |
2.5.2 全量同步(SNAP同步)
场景描述:条件peerLastZxid < minCommittedLog
如果Z2节点,之前作为follower节点,后来宕机下线一段时间重新上线后,由于和集群leader:Z5差异数据比较大,Z5节点的提议缓存队列的minCommittedLog 都比Z2节点的最大事务大,此时Z5节点会把全量数据发送给Z2节点,进行全量数据同步。2、leader上没有提议缓存队列,peerLastZxid不等于lastProcessedZxid(leader服务器数据恢复后得到的最大ZXID)
2.6 数据同步结束
2.6.1 leader向每个follower节点发送同步数据的最后都会发送一个NEWLEADER的请求。当follower节点同步到这个数据时,表示当前节点已经和leader完成了数据同步,然后follower会发送一个ACK的回复。
2.6.2 当leader收到半数以上节点的ACK NEWLEADER回复时,会向所有已经完成数据同步的follower节点发送一个UPTODATE指令,用来通知follower集群已经完成了数据同步,可以对外服务了。
2.6.3 至此数据故障恢复完成















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









