







本学习笔记为Datewhale-7月组队学习-动手学数据分析的学习内容,学习链接为:https://github.com/datawhalechina/hands-on-data-analysis
前言
在前一篇博文【动手学数据分析-Task02:数据清洗及特征处理】里,我们一起学习了数据清洗以及数据的特征处理,学会了如何观察及处理缺失值和重复值,理解了分箱处理的概念及操作,还学习了文本的变量转换等特征处理手段,这一部分十分重要,只有数据变得相对干净,我们之后对数据的分析才可以更有力。而在这篇博文中我们将会一起学习数据重构,数据结构旧属于数据理解(准备)的范围,为下一期的学习做一个铺垫。
一、学习知识点概要
Task03:数据重构
知识点:
1.数据拼接(concat、merge、jion和append的使用与区别)
2.数据聚合与运算(GroupBy机制和运算函数使用)
二、学习内容
(一)数据拼接
1. 数据加载
开始之前,导入numpy、pandas包和数据
import numpy as np
import pandas as pd
# 载入所有数据
df_left_up = pd.read_csv("train-left-up.csv")
df_left_down = pd.read_csv("train-left-down.csv")
df_right_up = pd.read_csv("train-right-up.csv")
df_right_down = pd.read_csv("train-right-down.csv")
2. 观察数据的之间的关系
df_left_up.head()

df_left_down.head(10)

df_right_up.head()

df_right_down.head()

3. 合并数据
(1)使用concat方法
将数据train-left-up.csv和train-right-up.csv横向合并为一张表,并保存这张表为result_up
result_up = pd.concat([df_left_up,df_right_up],axis =1)
result_up.head(800)

将train-left-down和train-right-down横向合并为一张表,并保存这张表为result_down。然后将上边的result_up和result_down纵向合并为result。
result_down = pd.concat([df_left_down,df_right_down],axis =1)
result = pd.concat([result_up,result_down],ignore_index=True)#ignore_index=True,可以重新设置序列号
result.head(900)

(2)join方法和append方法
result_up = df_left_up.join(df_right_up)
result_down = df_left_down.join(df_right_down)
result = result_up.append(result_down,ignore_index=True)
result.head(900)

(3)merge方法和append方法
result_up = pd.merge(df_left_up,df_right_up,left_index=True,right_index=True)
result_down = pd.merge(df_left_down,df_right_down,left_index=True,right_index=True)
result = result_up.append(result_down,ignore_index=True)
result.head(900)

思考: 对比merge、join以及concat的方法的不同以及相同。思考一下上述情况下,为什么都要求使用DataFrame的append方法,如何只要求使用merge或者join可不可以完成上述情况呢?
解答:
Pandas提供了concat,merge,join和append四种方法用于dataframe的拼接,其区别如下:
| 函数 | 适用场景 | 调用方法 | 备注 |
|---|---|---|---|
| .concat() | 可用于两个或多个df间行方向(增加行,下同)或列方向(增加列,下同)进行内联或外联拼接操作,默认行拼接,取并集 | result = pd.concat( [df1,df4], axis=1 ) | 提供了参数axis设置行/列拼接的方向;合并的范围小,只支持索引的合并 |
| .merge() | 只可用于两个df间列方向的拼接操作,取交集(即:存在相同主键的df1和df2的列拼接) | result=pd.merge(df1, df2,how=‘left’) | 提供了类似于SQL数据库连接操作的功能,支持左联、右联、内联和外联等全部四种SQL连接操作类型;合并的范围广泛,可以通过索引/列关联 |
| .join() | 只可用于df间列方向的拼接操作,默认左列拼接,how=’left’ | df1.join(df2) | 支持左联、右联、内联和外联四种操作类型 |
| .append() | 可用于df间行方向的拼接操作,默认 | df1.append(df4) | append是series和dataframe的方法, 可用于df间行方向的拼接操作 |
由上表可知,
merge或者join只能进行列连接,所以要使用append进行行连接
(4)完成的数据保存为result.csv
result.to_csv('result.csv')
4. 将数据变为Series类型的数据
观察原来的数据
#原数据
result.head(2)

将数据变成Series类型
unit_result = result.stack()
unit_result.head(23)

保存为unit_result,csv
unit_result.to_csv('unit_result.csv')
(二)数据聚合与运算
载入result.csv,并查看这个文件
df = pd.read_csv('result.csv')
df.head()

1. GroupBy机制
Hadley Wickham是许多流行R语言软件包的作者,他创造了用于描述组操作的术语拆分-应用-联合(split-apply-combine)。在操作的第一步,数据包含在pandas对象中,可以是Series、DataFrame或其他数据结构,之后根据你提供的一个或多个键分离到各个组中。分离操作是在数据对象的特定轴向上进行的。
分组键可是多种形式的,并且键不一定是完全相同的类型:
- 与需要分组的轴向长度一致的值列表或值数组
- DataFrame的列名的值
- 可以将分组轴向上的值和分组名称相匹配的字典或Series
- 可以在轴索引或索引中的单个标签上调用的函数
2. 数据运用
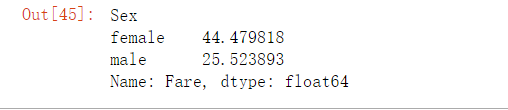
(1)计算男性与女性的平均票价
df_fare = df['Fare'].groupby(df['Sex'])
means = df_fare.mean()
means
(2)统计男女的存活人数
#乘坐泰坦尼克号中男女的人数
df_sex = df['Survived'].groupby(df['Sex']).count()
df_sex.head()


# 男女的存活人数
survived_sex = df['Survived'].groupby(df['Sex']).sum()
survived_sex.head()

(3)统计不同等级客舱的存活人数
#客舱不同等级的乘坐人数
df['Survived'].groupby(df['Pclass']).count()
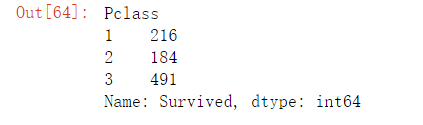
# 不同客舱的存活人数
survived_pclass = df['Survived'].groupby(df['Pclass'])
survived_pclass.sum()

思考: 从数据分析的角度,上面的统计结果可以得出那些结论
思考心得 :
女士的平均票价要高于男士
女士存活比例更高
客舱等级越高存活率越高
思考: 从任务二到任务三中,这些运算可以通过agg()函数来同时计算。并且可以使用rename函数修改列名。你可以按照提示写出这个过程吗?
思考心得:
df.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns=
{'Fare': 'mean_fare', 'Pclass': 'count_pclass'})

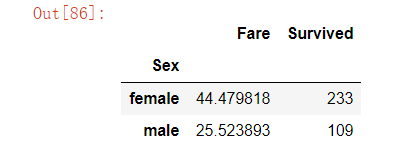
(4)合并任务二和任务三的数据
合并数据
result = pd.merge(means,survived_sex,on='Sex')
result
保存到sex_fare_survived.csv
result.to_csv('sex_fare_survived.csv')
(5)计算在不同等级的票中的不同年龄的船票花费的平均值
df.groupby(['Pclass','Age'])['Fare'].mean().head(10)

(6)计算存活人数最高的年龄段的存活率
根据不同年龄的总的存活人数,然后找出存活人数最高的年龄,最后计算该年龄的存活率(存活人数/总人数)
查看不同年龄的存活人数
survived_age = df['Survived'].groupby(df['Age']).sum()
survived_age.head(100)

找出存活人数最大值的年龄段
survived_age[survived_age.values==survived_age.max()]

计算总人数
_sum = df['Survived'].sum()
print(_sum)

计算最大存活率
precetn =survived_age.max()/_sum
print("最大存活率:"+str(precetn))
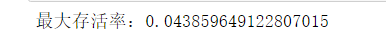
三、学习问题与解答
问题一: 【思考】对比merge、join以及concat的方法的不同以及相同。思考一下上述情况下,为什么都要求使用DataFrame的append方法,如果只要求使用merge或者join可不可以完成上述情况呢?
解答:
Pandas提供了concat,merge,join和append四种方法用于dataframe的拼接,其区别如下:
| 函数 | 适用场景 | 调用方法 | 备注 |
|---|---|---|---|
| .concat() | 可用于两个或多个df间行方向(增加行,下同)或列方向(增加列,下同)进行内联或外联拼接操作,默认行拼接,取并集 | result = pd.concat( [df1,df4], axis=1 ) | 提供了参数axis设置行/列拼接的方向;合并的范围小,只支持索引的合并 |
| .merge() | 只可用于两个df间列方向的拼接操作,取交集(即:存在相同主键的df1和df2的列拼接) | result=pd.merge(df1, df2,how=‘left’) | 提供了类似于SQL数据库连接操作的功能,支持左联、右联、内联和外联等全部四种SQL连接操作类型;合并的范围广泛,可以通过索引/列关联 |
| .join() | 只可用于df间列方向的拼接操作,默认左列拼接,how=’left’ | df1.join(df2) | 支持左联、右联、内联和外联四种操作类型 |
| .append() | 可用于df间行方向的拼接操作,默认 | df1.append(df4) | append是series和dataframe的方法, 可用于df间行方向的拼接操作 |
由上表可知,
merge或者join只能进行列连接,所以要使用append进行行连接
参考链接:
https://blog.csdn.net/weixin_42782150/article/details/89546357
https://blog.csdn.net/zephyr_wang/article/details/110224277
https://blog.csdn.net/weixin_38131197/article/details/101481993
问题二: stack函数的作用?
解答: stack和unstack是python进行层次化索引的重要操作。层次化索引就是对索引进行层次化分类,便于使用,这里的索引可以是行索引,也可以是列索引。
应用stack和unstack只需要记住下面的知识点即可:
stack: 将数据从”表格结构“变成”花括号结构“,即将其列索引变成行索引。
unstack: 数据从”花括号结构“变成”表格结构“,即要将其中一层的行索引变成列索引。如果是多层索引,则以上函数是针对内层索引(这里是store)。利用level可以选择具体哪层索引。
详细参考:https://blog.csdn.net/anshuai_aw1/article/details/82830916
问题三: GroupBy机制?
解答: Hadley Wickham是许多流行R语言软件包的作者,他创造了用于描述组操作的术语拆分-应用-联合(split-apply-combine)。在操作的第一步,数据包含在pandas对象中,可以是Series、DataFrame或其他数据结构,之后根据你提供的一个或多个键分离到各个组中。分离操作是在数据对象的特定轴向上进行的。
详细参考:https://www.shulanxt.com/analytics/python/data-groupby
问题四: pd.read_csv出现Unnamed:0这一列,如何处理?
解答:

第一种解决方式:声明文件第一列为索引
text = pd.read_csv(result,index_col=0)
第二种解决方式:报存result.csv时,不存索引
df.to_csv(path,index=False)
解决后:

问题五: jupyternotebook 撤销删除的操作方法?
解答:
方法一:
先按esc进入命令模式,即左侧线为蓝色(为绿色时是编辑模式),按z键即可恢复(或直接ctrl+z)
方法二:
如果是运行过的代码,直接运行
history
方法三:
功能栏 edit -> undo delete cell
四、学习思考与总结
本次学习,学会了如何进行数据重构。
数据重构包括数据从一种几何形态到另一种几何形态,从一种格式到另一种格式的转换。学习了数据拼接、数据聚合与运算等相关操作和指令,希望通过本次的学习,为后续课程做一个良好的铺垫。
在学习过程中遇到了许多参考答案上没有给出的疑惑,通过自己的查找和理解在上面第三部分学习问题与解答给出了参考。
希望大家可以互相交流、共同学习,如果发现博文中有错的或不解的,欢迎留言或私聊交流~
————————————————
五、参考文章
[1]https://github.com/datawhalechina/hands-on-data-analysis
[2]https://blog.csdn.net/weixin_42782150/article/details/89546357
[3]https://blog.csdn.net/zephyr_wang/article/details/110224277
[4]https://blog.csdn.net/weixin_38131197/article/details/101481993
[5]https://www.shulanxt.com/analytics/python/data-groupby
[6]https://blog.csdn.net/anshuai_aw1/article/details/82830916















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









