







一、KeyValueTextInputFormat原理简述

KeyValueTextInputFormat使用案例:
1、需求
统计输入文件中每一行的第一个单词相同的行数。
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2)期望结果数据
banzhang 2
xihuan 2
2.需求分析

3.代码实现
(1)、Mapper:
package com.atguigu.mapreduce.keyvalue;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 16:21
*/
public class KVMapper extends Mapper<Text, Text, Text, LongWritable> {
private LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Context context) throws IOException, InterruptedException {
context.write(key,v);
}
}
(2)、Reducer
package com.atguigu.mapreduce.keyvalue;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 16:21
*/
public class KVReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable value : values) {
// 遍历value并相加
sum += value.get();
}
v.set(sum);
// 写出
context.write(key,v);
}
}
(3)、Driver
package com.atguigu.mapreduce.keyvalue;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 16:20
*/
public class KVDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration conf = new Configuration();
// 每个MapReduce任务都被初始化为一个Job,它分为两个阶段,map和reduce阶段
Job job = Job.getInstance(conf);
// 设置切割符
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
// 2 设置jar加载路径
job.setJarByClass(KVDriver.class);
// 3 设置Mapper和Reducer类
job.setMapperClass(KVMapper.class);
job.setReducerClass(KVReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 设置输入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\study\\Linux\\大数据\\input") );
FileOutputFormat.setOutputPath(job,new Path("D:\\study\\Linux\\大数据\\output"));
// 7 提交
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
结果:
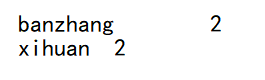
二、NLineInputFormat原理简述

NLineInputFormat使用案例:
1.需求
对每个单词进行个数统计,要求根据每个输入文件的行数来规定输出多少个切片。此案例要求每三行放入一个切片中。
(1)输入数据
hello hadoop
hello yqw
hello zwx
hadoop yqw
wjy wjy
hello
hive
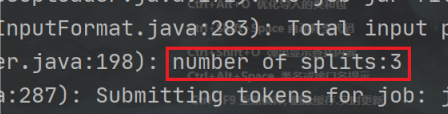
(2)期望输出数据
Number of splits:3
2.需求分析

3.代码实现
(1)、Mapper
package com.atguigu.mapreduce.nline;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 17:02
*/
public class NLineMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
private Text k = new Text();
private LongWritable v =new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 切分数据
String[] words = value.toString().split(" ");
// 遍历words
for (String word : words) {
k.set(word);
// 写出
context.write(k,v);
}
}
}
(2)、Reducer
package com.atguigu.mapreduce.nline;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 17:02
*/
public class NLineReducer extends Reducer<Text, LongWritable, Text,LongWritable> {
private LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
// 累加value
for (LongWritable value : values) {
sum+=value.get();
}
v.set(sum);
// 写出
context.write(key,v);
}
}
(3)、Driver
package com.atguigu.mapreduce.nline;
import com.atguigu.mapreduce.FlowBean;
import com.atguigu.mapreduce.FlowCountMapper;
import com.atguigu.mapreduce.FlowCountReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* @author yqw
* @since 2020-07-30 17:02
*/
public class NLineDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration conf = new Configuration();
// 每个MapReduce任务都被初始化为一个Job,它分为两个阶段,map和reduce阶段
Job job = Job.getInstance(conf);
// 2 设置jar加载路径
job.setJarByClass(NLineDriver.class);
// 3 设置Mapper和Reducer类
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
NLineInputFormat.setNumLinesPerSplit(job, 3);
job.setInputFormatClass(NLineInputFormat.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new
Path("D:\\study\\Linux\\大数据\\input"));
FileOutputFormat.setOutputPath(job, new
Path("D:\\study\\Linux\\大数据\\output"));
// 7 提交
boolean result = job.waitForCompletion(true);
// 退出
System.exit(result ? 0 : 1);
}
}
结果:















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









