







Upsert Kafka SQL Connector

Upsert Kafka 连接器支持以 upsert 方式从 Kafka topic 中读取数据并将数据写入 Kafka topic。
作为 source,upsert-kafka 连接器生产 changelog 流,其中每条数据记录代表一个更新或删除事件。更准确地说,数据记录中的 value 被解释为同一 key 的最后一个 value 的 UPDATE,如果有这个 key(如果不存在相应的 key,则该更新被视为 INSERT)。用表来类比,changelog 流中的数据记录被解释为 UPSERT,也称为 INSERT/UPDATE,因为任何具有相同 key 的现有行都被覆盖。另外,value 为空的消息将会被视作为 DELETE 消息。
作为 sink,upsert-kafka 连接器可以消费 changelog 流。它会将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,从而保证主键上的消息有序,因此同一主键上的更新/删除消息将落在同一分区中。
Dependencies
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.13.6</version>
</dependency>官网完整示例
CREATE TABLE pageviews_per_region (
user_region STRING,
pv BIGINT,
uv BIGINT,
PRIMARY KEY (user_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = '...',
'key.format' = 'avro',
'value.format' = 'avro'
);
CREATE TABLE pageviews (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP,
user_region STRING,
WATERMARK FOR viewtime AS viewtime - INTERVAL '2' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'pageviews',
'properties.bootstrap.servers' = '...',
'format' = 'json'
);
-- 计算 pv、uv 并插入到 upsert-kafka sink
INSERT INTO pageviews_per_region
SELECT
user_region,
COUNT(*),
COUNT(DISTINCT user_id)
FROM pageviews
GROUP BY user_region;Demo
upsert-kafka和mysql join后sink到mysql
1、创建upsert-kafka
String sourceTableDDL = "CREATE TABLE source_table(" +
"user_id int," +
"salary bigint, " +
"proc as PROCTIME()," +
"PRIMARY KEY (user_id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'upsert-kafka'," +
" 'topic' = 'source'," +
" 'properties.bootstrap.servers' = 'xxx:9092'," +
" 'properties.group.id' = 'user_log', " +
" 'key.json.ignore-parse-errors' = 'true'," +
" 'value.json.fail-on-missing-field' = 'false',"+
" 'key.format' = 'json'," +
" 'value.format' = 'json'" +
")";
tableEnv.executeSql(sourceTableDDL);2、创建mysql维表
String mysqlDDL = "CREATE TABLE dim_mysql (" +
" id int," +
" name string," +
" age int,"+
" PRIMARY KEY (id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://localhost:3306/flink'," +
" 'table-name' = 'dim_mysql'," +
" 'username' = 'root'," +
" 'password' = ''" +
")";
tableEnv.executeSql(mysqlDDL);3、创建mysql sink表
String sinkMysqlDDL = "CREATE TABLE sink_mysql (" +
" id int," +
" name string," +
" age int," +
" salary bigint," +
" PRIMARY KEY (id) NOT ENFORCED" +
") WITH (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://localhost:3306/flink'," +
" 'table-name' = 'result'," +
" 'username' = 'root'," +
" 'password' = ''" +
")";
tableEnv.executeSql(sinkMysqlDDL);4、测试
Table resultTable=tableEnv.from("source_table")
.groupBy($("user_id"))
.aggregate($("salary").sum().as("sum_salary"))
.select($("user_id"), $("sum_salary"));
tableEnv.createTemporaryView("resultTable", resultTable);
String joinSql = "SELECT st.user_id, dm.name, dm.age, rt.sum_salary FROM resultTable rt, source_table AS st " +
"LEFT JOIN dim_mysql FOR SYSTEM_TIME AS OF st.proc AS dm " +
"ON st.user_id = dm.id " +
"WHERE st.user_id=rt.user_id";
Table joinTable = tableEnv.sqlQuery(joinSql);
joinTable.executeInsert("sink_mysql");
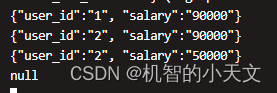
joinTable.execute().print();5、向kafka topic中发送数据
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(kafkaProps);
for(int i=0; i<1; i++){
String key = "{\"user_id\":\"1\"}";
String value = "{\"user_id\":\"1\", \"salary\":\"90000\"}";
//String value = null;
ProducerRecord<String, String> record = new ProducerRecord<>("source",
key,value
);
Future<RecordMetadata> future = kafkaProducer.send(record);
Thread.sleep(5000);
}6、测试结果
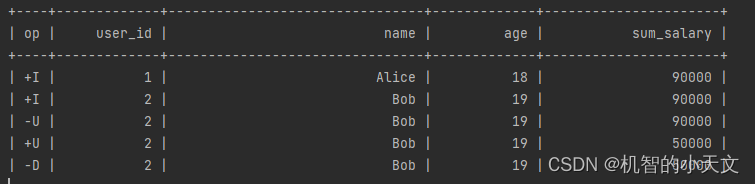















 8673
8673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









