







上一章:数据库配置和常用命令
下面学习如何使用Django封装的数据模型操作函数来进行增删改查。内容很多很全,步骤详细欢迎收藏,可随时查看。
码字不易,求个三连!
下面还是博客项目的Author数据模型为例。数据模型如下:
from uuid import uuid4
from django.db import models
class Author(models.Model):
"""用户类型:博客作者"""
GENDER = (
('0', '女'),
('1', '男'),
)
AUTHOR_STATUS = {
('0', '正常'),
('1', '锁定',),
('2', '删除'),
}
# 作者编号
# id = models.AutoField(primary_key=True, verbose_name='作者编号')
id = models.UUIDField(primary_key=True, verbose_name='作者编号', auto_created=True, default=uuid4)
# 登录账号
username = models.CharField(max_length=50, verbose_name='登录账号', db_index=True)
# 登录密码
password = models.CharField(max_length=50, verbose_name='登录密码')
# 真实姓名
realname = models.CharField(max_length=20, verbose_name='作者姓名')
# 年龄
age = models.IntegerField(default=0, verbose_name='作者年龄')
# 性别
gender = models.CharField(max_length=1, choices=GENDER, verbose_name='性别', default='男')
# 邮箱
email = models.EmailField(verbose_name='联系邮箱', null=True)
# 手机
phone = models.CharField(max_length=20, verbose_name='联系电话', null=True)
# 用户状态
status = models.CharField(max_length=5, choices=AUTHOR_STATUS, verbose_name='用户状态', help_text='必须选择其中一个状态'
, default='正常')
# 个人介绍
intro = models.TextField(verbose_name='个人介绍', null=True)
# 备注信息
remark = models.TextField(verbose_name='备注信息', null=True)
class Meta:
# 后台管理系统中的名称
verbose_name_plural = '作者'
def __str__(self):
return self.realname
具体的数据同步和迁移请参考前两章内容,这里不再详细说明。
数据新增
1.save()
>>> from author.models import Author
>>> author = Author(username='test01', password='123456')
>>> author.save()
只有执行save操作,,才会真正执行插入数据库的操作。
2.create()
>>> author = Author.objects.create(username='test02', password='123456')
该方法会直接执行插入的sql。
3.bulk_create
批量插入操作。
>>> authors = [Author(username='test03', password='123456'), Author(username='test04', password='123456')]
>>> Author.objects.bulk_create(authors)
数据修改
1.save()
先查出对象(查询后面会详细介绍),更新对象属性,再save。
>>> author = Author.objects.get(id=1)
>>> author
<Author: test01>
>>> author.username = 'test0101'
>>> author
<Author: test0101>
2.update
适用于条件查询后更新。
>>> author = Author.objects.filter(id=1).update(username='test01')
>>> author
1
>>>
注意返回的更新成功的条数。
数据删除
1.delete
删除单条
>>> author = Author.objects.get(id=4)
>>> author.delete()
(1, {'author.Author': 1})
按条件删除
>>> Author.objects.filter(id=3).delete()
(1, {'author.Author': 1})
删除全部
Author.objects.all().delete()
数据查询
单条查询
查询单条数据,常见API如下:
- get([condition]):根据条件查询一条数据,如果查不到或者查到多条则抛错。
- count():返回查询到的总条数。
- first():返回查询结果集中第一条数据。
- last():返回查询结果集中最后一条数据。
- exists():测试查询结果集中是否包含数据,是返回True,否则返回False。
多条查询
场景API:
- all():查询指定类型的所有数据。
- filter([condition]):根据条件查询指定类型数据,返回一个结果集。
- exclude([condition]):查询不满足指定条件的所有数据,返回一个结果集。
- order_by([field]):按照指定字段排序,返回一个结果集。
- values():查询bong返回对象的标准JSON格式数据。
条件查询
条件查询可以有多种操作方式:
1.把条件添加到filter函数中
>>> Author.objects.filter(username='test02')
<QuerySet [<Author: test02>]>
2.多条链式查询,filter([condition]).filter([condition]),或filter([condition], [condition])
>>> Author.objects.filter(username='test02').filter(password='123456')
<QuerySet [<Author: test02>]>
>>> Author.objects.filter(username='test02', password='123456')
<QuerySet [<Author: test02>]>
3.模糊查询,filter(condition_contains=value)
>>> Author.objects.filter(username__contains='test')
<QuerySet [<Author: test01>, <Author: test03>, <Author: test02>, <Author: test04>]>
4.是否为空查询,filter(condition__isnull=True/False)
>>> Author.objects.filter(username__isnull=False)
<QuerySet [<Author: test01>, <Author: test03>, <Author: test02>, <Author: test04>]>
5.范围查询,filter(condition__in=[values like list])
>>> Author.objects.filter(username__in=['test01', 'test02'])
<QuerySet [<Author: test01>, <Author: test02>]>
6.关系查询
关系运算支持
- gt:大于
- gte:大于等于
- lt:小于
- lte:小于等于
如,等于为filter(condition__lt=value)
>>> Author.objects.filter(age__lt=12)
<QuerySet [<Author: test01>, <Author: test03>, <Author: test02>, <Author: test04>]>
7.日期查询
支持的表达式包含year、month、day、week_day、hour、minute、second。
表达式为filter(condition__year=‘2022’)
Q、F对象
Django针对查询条件和查询数据进行的特殊的封装,分为封装成表示查询条件的对象Q和表示查询数据的对象F。
主要用来进行更加复杂的查询。
条件对象Q
Django使用django.db.models.Q类型用于把查询条件封装成对象Q,并使用Q完成查询操作。
基本查询,把查询条件封装成对象Q中,如下:
>>> Author.objects.filter(Q(username='test01'))
<QuerySet [<Author: test01>]>
多个Q之间的“并”查询,可以使用&连接。如下:
>>> Author.objects.filter(Q(username='test01') & Q(gender='男'))
<QuerySet [<Author: test01>]>
多个对象“或”查询,可以使用|连接。如下:
>>> Author.objects.filter(Q(username='test01') | Q(gender='男'))
<QuerySet [<Author: test01>, <Author: test03>, <Author: test02>, <Author: test04>]>
对Q对象取反查询,如下:
>>> Author.objects.filter(~Q(username='test01'))
<QuerySet [<Author: test02>, <Author: test03>, <Author: test04>]>
原始值对象F
有时候,我们需要在已经通过查询得到的数据上进行数据更新,比如更新文章的阅读次数。常规是查询得到文章数据后更新文章的阅读次数,然后存储数据。如下:
>>> article = Article.objects.get(Q(title='文章1'))
>>> article.readed_count += 1
>>> article.save()
上面方式繁琐,通过F对象操作,可以简化步骤,如下:
>>> article = Article.objects.filter(Q(title='文章1')).update(readed_count=F('readed_count') + 1)
关联查询
以我们的博客项目为例,一个作者可以发表多篇文章,一个文章只能属于一个作者,那么Author(作者)类型和Article(文章)类型之间就存在关联。
模型之间的关联关系有以下几种:
- 一对多活多对一关联
- 一对一关联
- 多对多关联
- 自关联
一对多关联
核心API是models.ForeignKey(to, on_delete, **options)。参数含义如下:
- to:要关联的模型,必须指定,可以是具体导入的模型类,也可以是自定义的模型的字符串描述。
- on_delete:关联级别,在删除数据时,被关联的对象如何处理。选项如下:
| 选项 | 描述 |
|---|---|
| models.CASCADE | 删除数据时,同步删除关联数据 |
| models.PROTECT | 在删除数据时,如果存在关联数据,则阻止删除并抛出ProtectedError |
| models.SET_NULL | 在删除数据时,如果关联数据的外键设置了 null=True,则删除当前数据并关联数据的外键字段赋值为Null |
| models.SET_DEFAULT | 在删除数据时,如果设置了default约束,咋删除当前数据之后,关联数据的关键字段赋值为默认值 |
| models.DO_NOTHING | 在删除数据时,对关联数据无操作 |
| models.SET() | 在删除数据时,指定指定函数 |
下面以博客项目为例,更新我们的文章模型Article,关联用户类型。代码如下:
from django.db import models
class Article(models.Model):
"""文章类型"""
ARTICLE_STATUS = (
('0', '正常'),
('1', '删除')
)
# 编号
id = models.AutoField(verbose_name='文章编号', auto_created=True, primary_key=True)
# 标题
title = models.CharField(verbose_name='文章标题', max_length=200)
# 内容
content = models.TextField(verbose_name='文章内容')
# 发布时间
pub_time = models.DateTimeField(verbose_name='发布时间', auto_now_add=True)
# 阅读次数
readed_count = models.IntegerField(verbose_name='阅读次数', default=0)
# 点赞次数
admired_count = models.IntegerField(verbose_name='点赞次数', default=0)
# 喜欢次数
liked_count = models.IntegerField(verbose_name='喜欢次数', default=0)
# 收藏次数
collected_count = models.IntegerField(verbose_name='收藏次数', default=0)
# 评论次数
commented_count = models.IntegerField(verbose_name='评论次数', default=0)
# 修改时间
up_time = models.DateTimeField(verbose_name='上次修改时间', auto_now=True)
# 操作状态
status = models.CharField(verbose_name='当前状态', choices=ARTICLE_STATUS, default='0', max_length=2)
# 文章作者
author = models.ForeignKey('author.Author', on_delete=models.CASCADE)
class Meta:
# 数据排序
ordering = ['-pub_time', 'id']
def __str__(self):
return "文章标题:{},文章内容:{}".format(self.title, self.content)
上面代码通过ForeignKey完成外键约束,同时删除限定规则为级联删除。
下面来看下如何进行一对多查询。
首先创建两个文章对象,建立和一个作者关联关系。代码如下:
>>> from author.models import Author
>>> from article.models import Article
>>> author = Author.objects.get(id=1)
>>> article = Article(title='文章1', content='文章1内容', author=author)
>>> article.save()
>>> article2 = Article(title='文章2', content='文章2内容', author=author)
>>> article2.save()
下面开始查询:
# 先查询作者
>>> author = Author.objects.get(id=1)
>>> author
<Author: test01>
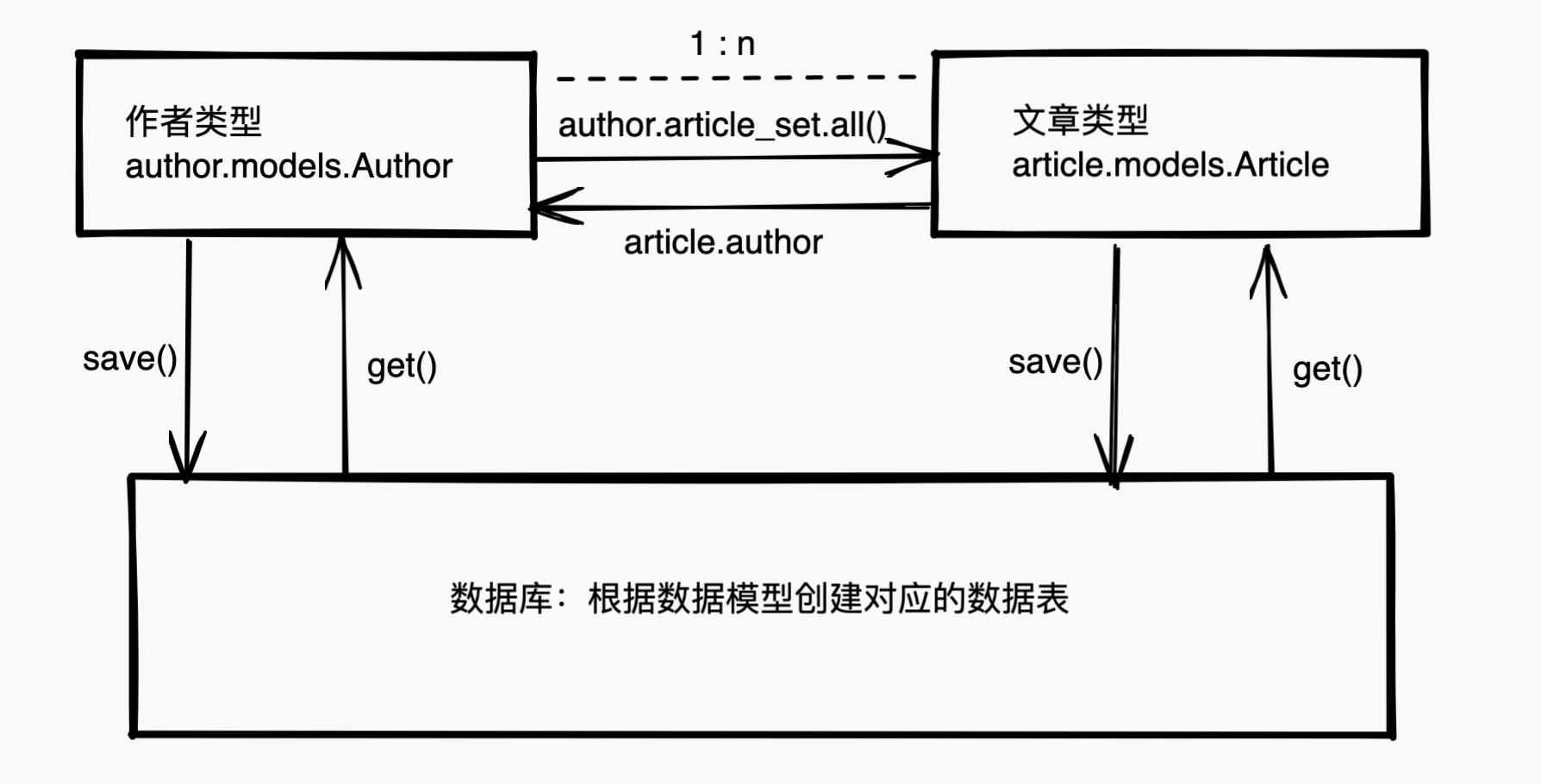
# 一对多,一方查多方:查询作者下面的所有文章
>>> author.article_set.all()
<QuerySet [<Article: 文章标题:文章2,文章内容:文章2内容>, <Article: 文章标题:文章1,文章内容:文章1内容>]>
# 一对多,多方查一方:查询文章对应的作者
>>> article = Article.objects.get(title='文章1')
>>> article.author
<Author: test01>
查询关系如下图:
一对一关联
模型一对一关联只需要在一方添加唯一性约束即可。在Django中,单独封装了models.OneToOneField(to, on_delete)函数来完成模型一对一关联。该函数与ForeignKey含义相同,但是该函数修饰的属性有唯一约束。
以博客项目为例,为作者添加一个特殊的关联字段:扩展资料,来扩展作者类型的功能。代码如下:
class AuthorProfile(models.Model):
"""用户扩展资料"""
# 资料编号
id = models.AutoField(verbose_name='扩展资料编号', primary_key=True, auto_created=True)
# 粉丝数量
fans_count = models.IntegerField(verbose_name='粉丝数量', default=0)
# 访问数量
visited_count = models.IntegerField(verbose_name='访问次数', default=0)
# 文章字数
words_count = models.IntegerField(verbose_name='文章字数', default=0)
# 文章篇数
article_count = models.IntegerField(verbose_name='文章篇数', default=0)
# 收藏总数量
collected_count = models.IntegerField(verbose_name='收藏总数', default=0)
# 喜欢总数量
liked_count = models.IntegerField(verbose_name='喜欢总数', default=0)
# 点赞总数
admired_count = models.IntegerField(verbose_name='点赞总数', default=0)
# 关联用户
author = models.OneToOneField(Author, on_delete=models.CASCADE)
在上述代码中,添加一个关联属性author,用于AuthorProfile对象和唯一一个Author对象之间关系的定义。在定义好数据模型后,使用makemigrations和migrate命令将新模型同步到数据库。
首先创建需要的数据:
>>> from article.models import Article
>>> from author.models import Author
>>> author = Author.objects.get(username='test02')
>>> from author.models import AuthorProfile
>>> ap1 = AuthorProfile(author=author)
>>> ap2 = AuthorProfile(author=author)
>>> ap1.save()
>>> ap2.save()
pymysql.err.IntegrityError: (1062, "Duplicate entry '5' for key 'author_authorprofile.author_id'")
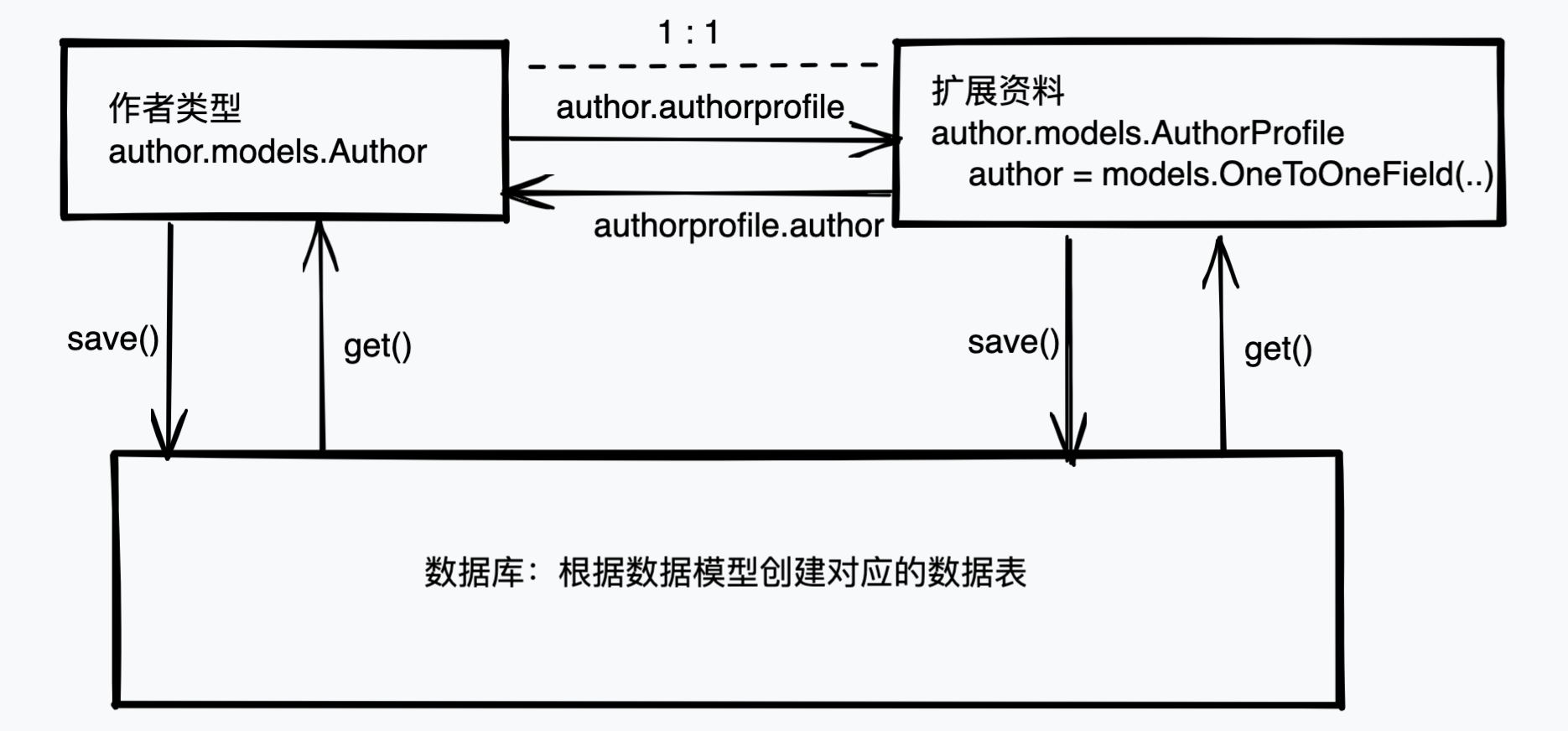
下面就可以进行查询了:
>>> author.authorprofile
<AuthorProfile: AuthorProfile object (None)>
>>> ap1.author
<Author: test02>
模型之间的一对一关联操作和一对多关联操作类似,使用框架提供的内置函数不仅可以完成模型类和数据库的交互,还可以完成模型类和关联模型类之间的操作。如下图:
多对多关联
对于多对多关联,项目中一般是通过中间表的形式建立两个模型之间的关联。Django中通过在模型类中添加多对多关联字段的方式,完成多个模型之间的关联操作。
核心API:models.ManyToManyField(to, related_name),其中参数to用于指定关联模型,related_name用于指定关联名称,该名称在一个类型中是唯一的。
以博客项目为例,一个用户可以收藏、喜欢多篇文章,一篇文章也可以被多个用户收藏、喜欢。
下面修改博客项目中的用户扩展资料模型AuthorProfile,添加收藏多篇文章和喜欢多篇文章的属性字段。代码如下:
class AuthorProfile(models.Model):
"""用户扩展资料"""
... ....
# 喜欢的文章
articles_liked = models.ManyToManyField('article.Article', related_name='articleliked')
# 收藏的文章
articles_collected = models.ManyToManyField('article.Article', related_name='articlecollected')
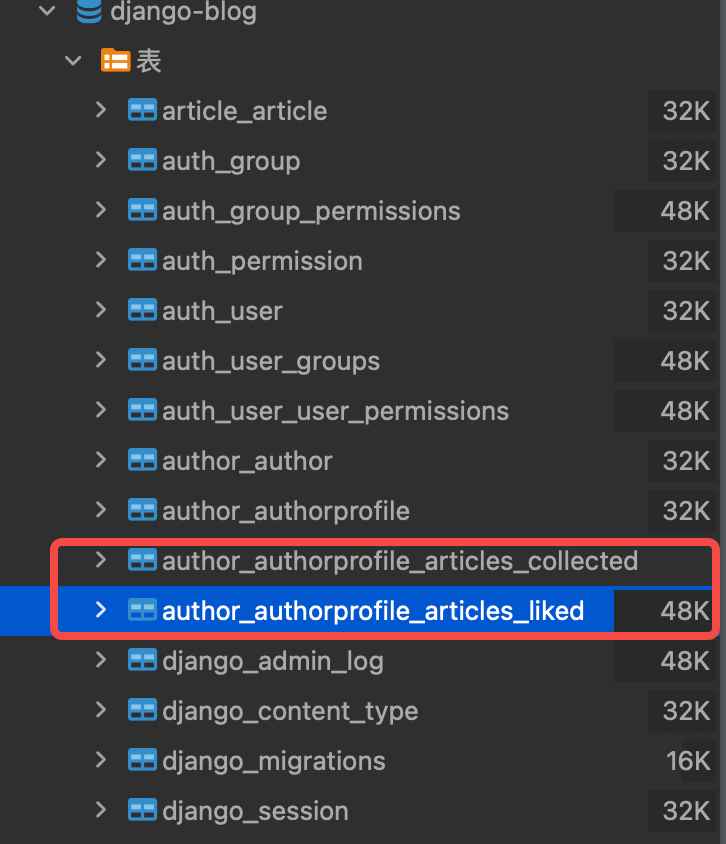
多对多关联,在关联的两个模型中,在任意一方定义关联字段都可以完成关联。
接下来通过makemigrations和migrate完成数据迁移。可以看到数据库自动创建的中间关联关系表。如下:
下面来看下如何完成多对多的查询。
# 新增一个用户
>>> >>> author = Author(username='test05', password='123456')
>>> author.save()
# 添加用户扩展资料
>>> ap = AuthorProfile()
>>> ap.author = author
>>> ap.save()
# 查询所有文章
>>> article = Article.objects.all()
>>> article
<QuerySet [<Article: 文章标题:文章2,文章内容:文章2内容>, <Article: 文章标题:文章1,文章内容:文章1内容>]>
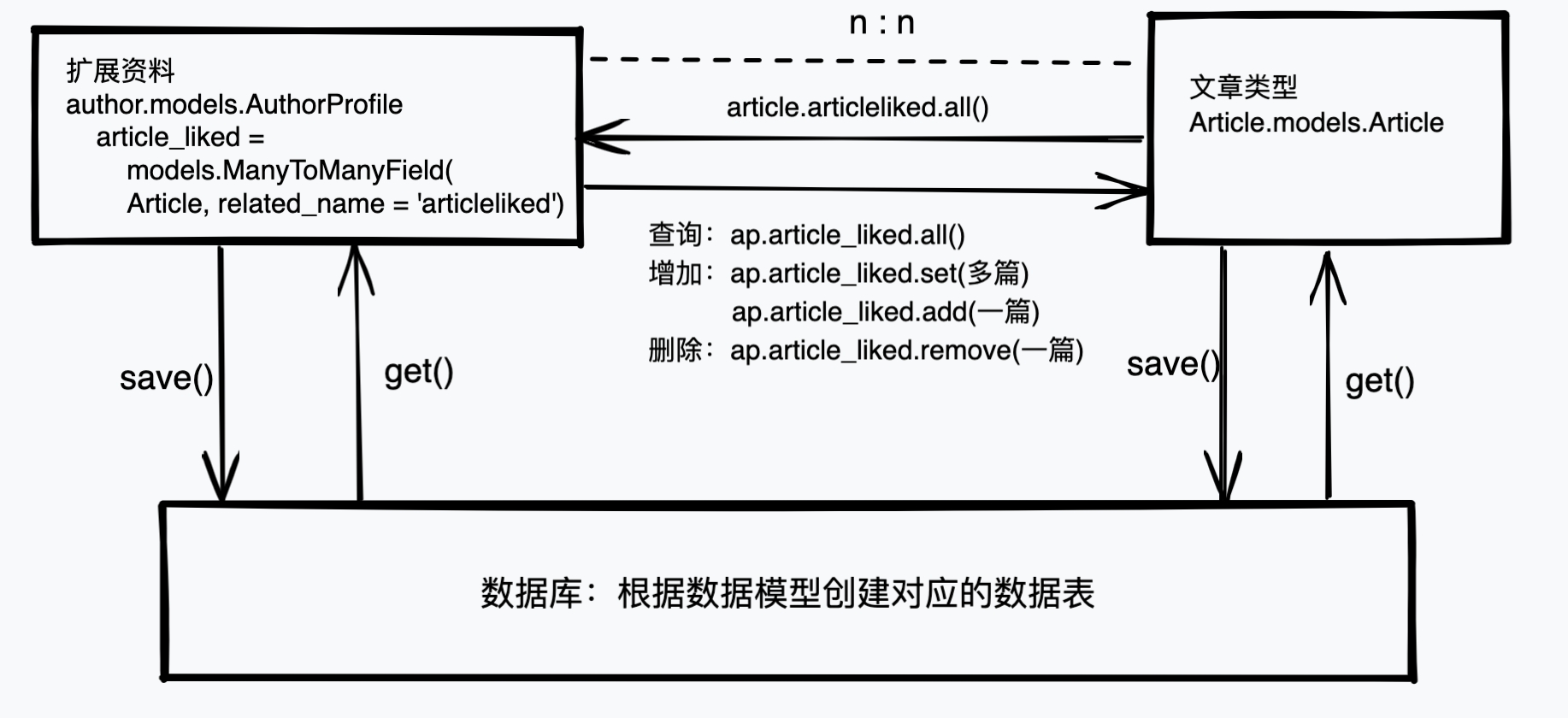
在扩展资料添加多篇喜欢的文章,使用set:
>>> ap.articles_liked.set(article)
>>> ap.save()
查询一个作者喜欢的所有文章:
>>> author = Author.objects.get(username='test05')
>>> author.authorprofile.articles_liked.all()
<QuerySet [<Article: 文章标题:文章2,文章内容:文章2内容>, <Article: 文章标题:文章1,文章内容:文章1内容>]>
查询一篇文章被那些人喜欢:
>>> article = Article.objects.get(title='文章1')
>>> aps = article.articleliked.all()
添加一个关联关系,使用add:
# 给作者增加一个喜欢的文章
>>> article = Article.objects.get(title='文章2')
>>> author.authorprofile.articles_liked.add(article)
>>> author.authorprofile.save()
删除一个关联关系,使用remove:
>>> article2 = Article.objects.get(title='文章2')
>>> author.authorprofile.articles_liked.remove(article2)
查询关系图如下:
自关联
有一种特殊的关联,是在一对多/一对一/多对多的基础上,关联的双方都是当前模型类,这样的关联就是自关联。
以博客项目为例,一个作者可以关注多个作者,同样也可以被多个作者关注。
下面修改博客项目的作者模型Author,代码如下:
class Author(models.Model):
...
# 关注的作者
authors_liked = models.ManyToManyField('self', related_name='author')
# 特别关注的作者
author_liked = models.OneToOneField('self', on_delete=models.SET_NULL, null=True, blank=True)
下面开始查询:
>>> from author.models import Author
>>> author = Author(username = 'test06', password='123456')
>>> author.save()
>>> author2 = Author.objects.get(username='test02')
>>> author3 = Author.objects.get(username='test03')
# 添加关注作者
>>> author.authors_liked.add(author2)
>>> author.authors_liked.add(author3)
>>> author.save()
# 查看关注的所有作者
>>> author.authors_liked.all()
<QuerySet [<Author: test03>, <Author: test02>]>
# 添加特别关注作者
>>> author.author_liked = author2
>>> author.save()
# 查看特别关注作者
>>> author.author_liked
<Author: test02>
# 查看自己被谁特别关注了
>>> author2.authors_liked.all()
<QuerySet [<Author: test06>]>
# 查询自己被谁特别关注了
>>> author2.author
<Author: test06>
注意:查询关注的作者和被谁关注,代码一样,结果也是混在一起的。
数据库事务
Django中的默认事务管理采用自动提交模式,除非主动设置需要独立管理。PEP 294(Python数据库API规范v2.0)中要求程序和数据之间的交互,关闭事务自动管理并提交。Django中的规范覆盖了PEP 294规范,默认启用了自动提交,保证ORM中多条语句执行后的数据完整性。
当日,Django也提供了定制化事务管理方式,开放底层的API。可以通过配置文件设置AUTOCOMMIT=False关闭事务管理,但是官方不推荐。
如果要实现特有的事务管理,下面是步骤:
1.关闭事务管理自动配置
在配置文件添加:
AUTOCOMMIT = False
2.事务提交的回调函数
执行事务成功后,可能还需要一些资源管理或回收操作,可以通过回调函数执行。Django提供了专门的回调函数,如下:
from django.db import transaction
def do_something():
# 事务提交后执行的回调函数,如发邮件、请缓存、执行异步任务等。
pass
# 添加事务管理
transaction.on_commit(do_something)
3.事务保存点设置
对事务的管理行为都是基于数据保存点设置的。django提供了atomic()函数专门用于进行事务保存点的处理操作,结合with语句使用,如下:
# 开启一个事务,with语句块中的代码执行完成自动提交里出现异常则回滚
with transaction.atomic():
# 事务中执行的代码
...
# 事务执行完成后,执行回调函数foo
transaction.on_commit(foo)
# 开启另一个事务,同样设置保存点,根据结果执行提交或回滚
with transaction.atomic():
# 事务中执行的代码
...
# 事务执行完成后,执行回调函数bar
transaction.on_commit(bar)
atomic应是封装好的操作,如果想要更底层的处理,Django也有提供API。如下:
savepoint(using=None):创建保存点。using参数指定要连接的数据库,如果没有指定,使用配置的里default数据库。savepoint_commit(sid, using=None):提交保存点sid的数据。savepoint_rollback(sid, using=None):回滚保存点sid的数据。clean_savepoint(using=None):重置/清空保存点。
如下:
from django.db import transaction
# 开启一个事务,管理注解的函数
@transaction.atomic
def viewfunc(request):
# 在事务管理中执行save函数
a.save()
# 创建一个事务保存点
sid = transaction.savepoint()
# 在事务中同时管理a.save和b.save
b.save()
if want_to_keep_b:
# 这里提交事务保存点,事务中同时有a.save和b.save操作
transaction.savepoint_commit(sid)
else:
# 此时在事务管理中,由于回滚,只包含了对a.save的事务管理
transaction.savepoint_rollback(sid)
在常规Django项目中,并不推荐自行处理。
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











