







 本文详细介绍了KafkaBroker的工作原理,包括其在Kafka集群中的角色、工作流程,以及Broker的重要参数。重点阐述了Controller的必要性、作用、数据服务和leader选举流程,包括脑裂问题和羊群效应的解决方案。
本文详细介绍了KafkaBroker的工作原理,包括其在Kafka集群中的角色、工作流程,以及Broker的重要参数。重点阐述了Controller的必要性、作用、数据服务和leader选举流程,包括脑裂问题和羊群效应的解决方案。
这里写自定义目录标题
Broker
概述
Kafka服务实例,负责消息的持久化、中转等功能。一个独立的Kafka 服务器被就是一个broker。
broker 是集群的组成部分。每个集群都有一个broker 同时充当了集群控制器Controller的角色。
kafka使用Zookeeper(ZK)进行元数据管理,保存broker注册信息,包括主题(Topic)、分区(Partition)信息等,选择分区leader,在低版本kafka消费者的offset信息也会保存在ZK中。
在每一个Broker在启动时都会像向ZK注册信息,ZK会选取一个最早注册的Broker作为Controller,后面Controller会与ZK进行数据交互获取元数据(即整个Kafka集群的信息,例如有那些Broker,每个Broker中有那些Partition等信息),并负责管理工作,包括将分区分配给broker 和监控broker,其他Broker是与Controller进行交互进而感知到整个集群的所有信息。
Broker总体工作流程
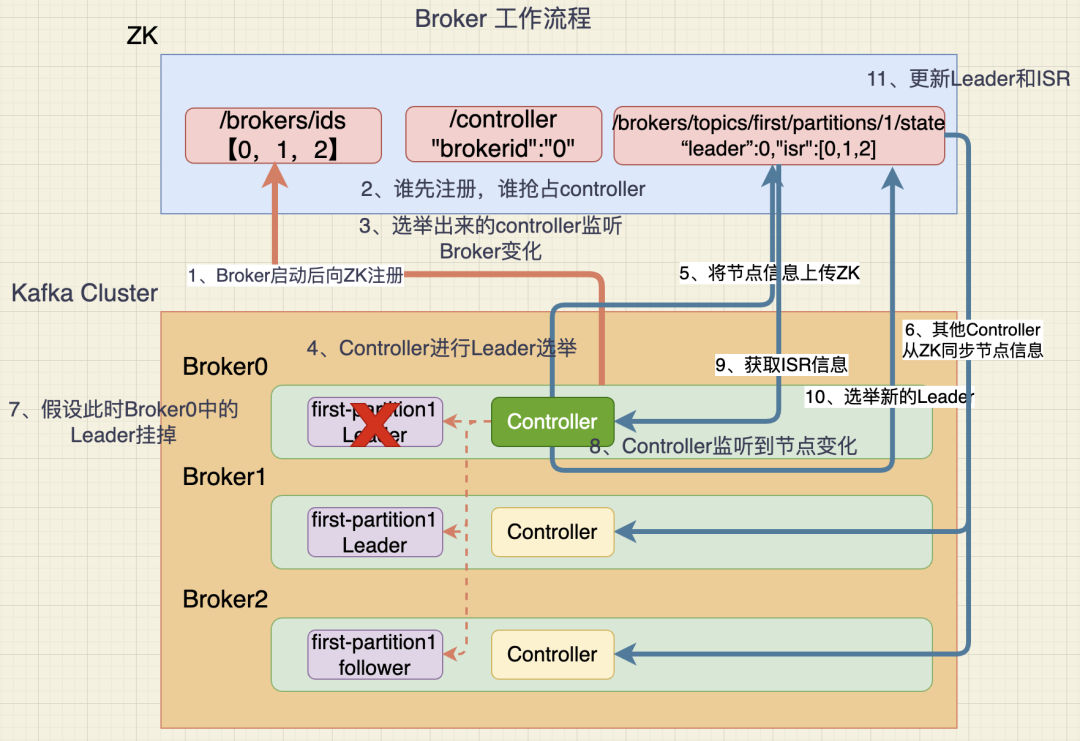
流程如下:
- broker 启动后,向 ZK 集群进行注册
- 各个 broker 的 controller 抢占 ZNode
- 抢占到的 Controller 监听 brokers 节点的变化
- Controller 决定 Leader 的选举:规则:在 isr 中存活的 broker,按照 AR 中排在前面的优先
- Controller 将节点信息上传到 ZK
- 其他 controller 从 ZK 同步相关信息
- 假设此时 broker1 中的 Leader 挂了
- Controller 监听到了节点变化
- 从 ZK 中获取 ISR
- 选举出新的 Leader
- 向 ZK 更新 Leader 和 ISR
Broker重要参数
介绍完 Broker 的工作流程,给大家总结一下,Broker 在工作过程中涉及到的一些参数:
| 参数 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR,默认 30s |
| auto.leader.rebalance.enable | 默认是 true。自动 Leader Partition 平衡 |
| leader.imbalance.per.broker.percentage | 默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,会触发 leader 的平衡 |
| leader.imbalance.check.interval.seconds | 默认值 300 秒。检查 leader 负载是否平衡的间隔时间 |
| log.segment.bytes | Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G |
| log.index.interval.bytes | 默认 4kb,每当写入了 4kb 大小的日志 (.log),然后就往 index 文件里面记录一个索引 |
| log.ret |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











