







动手学深度学习(基础一)
机器学习中的关键组件
- 用来学习的数据(Data)
- 如何转换数据的模型(Model)
- 一个目标函数(Object Function),用来量化模型的有效性
- 调整模型参数以优化目标函数的方法(Algorithm)
数据(data)
数据是一些模型的基础,在机器学习中,每个数据集由一个个样本(example/sample)组成,大多情况,它们遵循独立同分布(independently and indentically distributed)。样本也叫数据点(data point)或者数据示例(data instance),通常每个样本都是由一组成为特征(features,或协变量(covariates))的属性组成。机器学习模型会根据这些属性进行预测。要预测的是一个特殊的属性,成为标签(lable,或目标(target))。
当每个样本的特征类别数量都是相同的时候,其特征向量是固定长度,这个长度被称为数据的维度(dimensionality)。固定长度的特征向量是一个方便的属性,可以量化学习大量样本。
但不是所有的数据都可以用固定长度的向量表示。如图像,如果全部来自标准的拍摄设备,固定长度是可以的,但是图像数据如果来自互联网,就很难使用固定长度的向量表示。这时,可以考虑将数据裁切成标准尺寸,但是会由丢失信息的风险。另外,文本也不符合固定长度的向量表示。与传统机器学习相比,深度学习的一个主要优势是可以处理不同长度的数据。
一般来讲,数据集越大,深度学习模型的效果会更好。但数据的质量对模型最终的效果依然起着决定的作用
注:
独立同分布: 是概率论与统计学中的概念,指的是一组随机变量中每个变量的概率分布都相同,却这些随机变量相互独立
模型
简单说就是对数据的转换,得到想到得到的结果。
深度学习(deep learning)模型是由神经网络错综复杂的交织在一起,包含层层的数据转换
目标函数
机器学习简单定义为从经验中学习,这里的学习是指的自主提高模型完成某项任务的效能。
在机器学习中,需要定义模型的优劣程度的度量,这个度量大多是可优化的,这被称为目标函数(objective function)。
通常,定义一个目标函数,并希望优化它到最低点。因为越低越好,因此这些函数有时被称为损失函数(loss function,或cost function)。
通常,损失函数是根据模型参数定义的,并取决于数据集。在一个数据集上,可以通过最小总损失来学习模型参数的最佳值。
可用数据集通常分为两部分:
一些为训练而收集的样本,称为训练数据集(training dataset,或者训练集(training set));
在训练数据集上表现良好的模型,不一定在新数据集上有同样的性能,这里的新数据集通常称为测试数据集(test dataset,或称为测试集(test set))
训练数据集用于拟合模型参数,测试数据集用于评估拟合的模型。当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为**过拟合(overfitting)**的
优化算法
当拥有了数据源,模型和一个适合的损失函数,接下来就需要一种算法,能够搜索出最佳的参数,以最小化损失函数,这个算法就被称为优化算法。
大多流行的优化算法,通常基于一个基本方法--------梯度下降(gradient descent)。
梯度下降:在每个步骤中,梯度下降法会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝那个方向移动,然后就可以在减少损失的方向上优化参数。
机器学习中的学习问题
首先,监督学习、无监督学习和强化学习都是机器学习中的一种训练方式/学习方式。如图所示
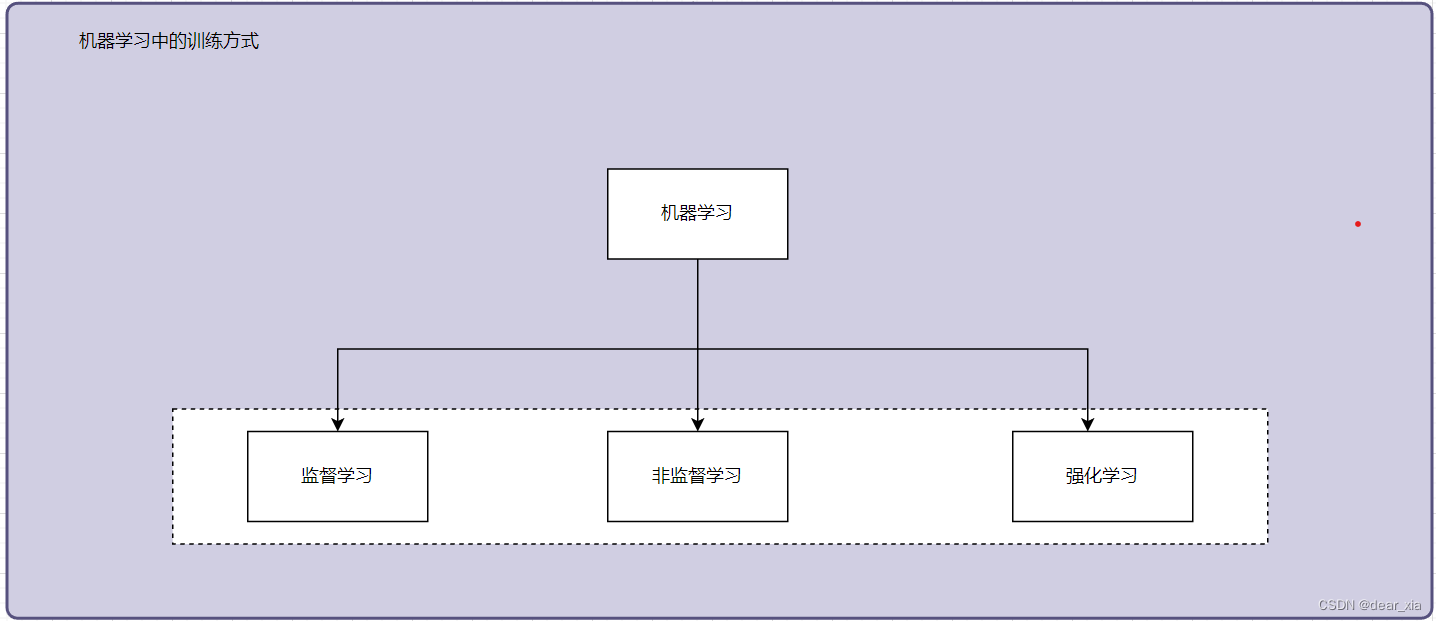
监督学习
**监督学习(supervised learning)**擅长在给定输入特征的情况下预测标签。每一个“特征-标签”对都称为一个样本。我们的目标是生成一个模型,能够将任务输入特征都映射到标签(预测)。
监督学习的学习过程:
1,选择一个适合目标人的数学模型
2,先把一部分已知的“特征–标签”(训练集)给机器学习
3,机器总结出自己的方法论
4,把测试集给机器,让它去解答
 图片参考:https://easyai.tech/ai-definition/supervised-learning/
图片参考:https://easyai.tech/ai-definition/supervised-learning/
监督学习的两个任务–回归、分类
回归
回归(regression)是最简单的监督学习任务。回归主要预测连续的、具体的数值
分类
分类是对各种事物分门别类,用于离散型预测
主流监督学习算法:
| 算法 | 类型 |
|---|---|
| 朴素贝叶斯 | 分类 |
| 决策树 | 分类 |
| SVM | 分类 |
| 逻辑回归 | 回归 |
| 线性回归 | 回归 |
| 回归树 | 回归 |
| K近邻 | 分类+回归 |
| Adaboosting | 分类+回归 |
| 神经网络 | 分类+回归 |
无监督学习
数据中不包含“目标”的机器学习问题被称为无监督学习(unsupervised learning)
简单说,无监督学习本质上是一个统计手段,在没有标签的数据里面可以发现潜在的一些结构的一种训练方式。
无监督学习具备三个特点
1,无监督学习没有明确的目标
2,无监督学习不需要给数据打标签
3,无监督学习无法量化效果
常见的两种无监督学习算法:聚类和降维
聚类:简单说就是一种自动分类的方法,在监督学习中,可以清楚每一个分类是什么,但在聚类中,你无法清楚的知道聚类后的几个分类分别代表什么
降维:看上去很像压缩。这是为了在尽可能保证相关的结构的同时,降低数据的复杂度。
强化学习
如果你对使用机器学习开发与环境交互并采取行动感兴趣,那么最终可能会专注于强化学习(reinforcement learning)。

在强化学习问题中,**智能体(agent)**在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。 请注意,强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
我们可以将任何监督学习问题转换为强化学习问题。强化学习还可以解决许多监督学习无法解决的问题,如:在监督学习中,我们希望输入与正确的标签相关联。但在强化学习中,不假设环境告诉智能体每个观测的最优动作。一般来说,智能体只是得到一些奖励,此外环境甚至可能都不会告诉是哪些行为导致的奖励。
强化学习可能还必须解决部分可观测问题,即当前的观察结果可能无法阐述有关当前状态的所有信息。
在任何时间点上,强化学习智能体可能知道一个好的策略,但可能有许多更好的策略从未尝试过。强化学习智能体必须不断的做出选择:是应该利用当前最好的策略,还是探索新的策略空间。















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









