









现在的世界,什么都需要人工智能AI进行处理,那么,对于Java程序猿来说,是不是有些工作是不是就不能胜任呢,答案是显然是不一定的,对于图片识别来说,这个任务就可以使用Java进行开发,虽然效率可能不是最好的,但是,结果是一致的。
下面我就开始出大招了
第一步,添加技能点
如果需要进行图片识别,那么肯定需要识别的插件或者是一个库呀,不然程序怎么清楚是识别那些东西,识别是中文还是英文,对不对,这个时候呢,就出现了“野怪”——ocr,给我们提供支持,从而进行升级添加技能点
什么事OCR,这个大家可以自行百度,其主要作用就是为我们进行识别图片中的文字的一个重要角色,下载方式直接百度tesseract下载就行
下载完成后,需要进行配置环境变量,我这也不进行过多描述,可以自行百度,如果需要,可后续追加一篇配置下载的博客说明
那么野怪位置找到了,我们就需要开始刷怪升级了
第二步,添加词库
需要识别文字,那么武器必不可少,如果没有装备,野怪也是能秒人的,所以,我们需要去下载一些词库,例如中文词库:chi_sim.traineddata,下载方式也可在百度上进行下载下来,下载完成后,在刚刚安装的tesseract下找到tessdata文件夹,将其复制过来就可以了,我的是D盘下,所以位置如下图
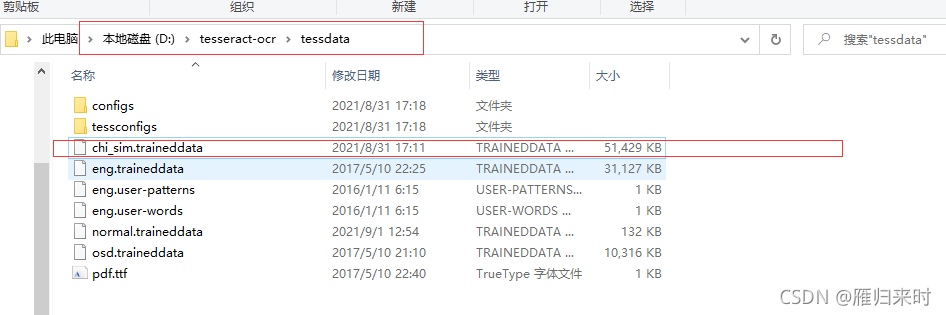
移动过来后,我们就有武器了,开始刷怪
第三步,开大,结束战斗(前方高能)
public static String IdentifyThePicture(){
//识别图片
System.out.println("开始识别");
long starttime = System.currentTimeMillis();
//获取当前程序执行绝对路径。
String text = orcde("normal", "D:\\tesseract-ocr\\tessdata", "D://JT//1.png");
System.out.println("discriminate interval:" + (System.currentTimeMillis() - starttime) + ",ocr text:" + text);
return text;
}
public static String orcde(String lang, String langpath, String imageurl){
// 识别图片的路径(修改为自己的图片路径)
String path = imageurl;
// 语言库位置(修改为跟自己语言库文件夹的路径)
String lagnguagePath = langpath;
File file = new File(path);
ITesseract instance = new Tesseract();
//设置训练库的位置
instance.setDatapath(lagnguagePath);
//chi_sim :简体中文, eng 根据需求选择语言库
instance.setLanguage(lang);
String result = null;
try {
long startTime = System.currentTimeMillis();
result = instance.doOCR(file);
long endTime = System.currentTimeMillis();
System.out.println("Time is:" + (endTime - startTime) + " 毫秒");
} catch (TesseractException e) {
e.printStackTrace();
}
System.out.println("result: ");
System.out.println(result);
return result;
}
运行结果如下:
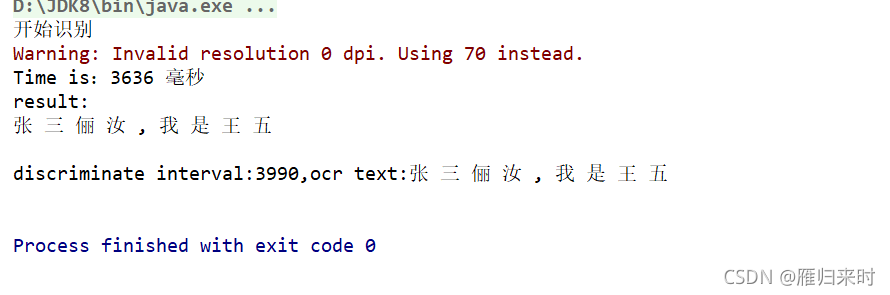
图片中的内容如下:

你是不是发现有两个字不对,这个咱暂时不告诉你,请继续往下看
代码看起来是不是很简单,(你心里觉得是这样想的)因为这是有野怪,如果没有野怪怎么办,或者等级不够怎么办(1级单挑100级?)显然是不可以的,这个时候就需要进行训练了,训练啥,训练词库,怎么训练,如下:
第一步,下载jTessBoxEditor_jb51(找到新手训练营)
jTessBoxEditor_jb51这是啥东西,我告诉你,这个是训练词库必须要用的一个jar包,但是呢,他不是在项目里面使用的,而是独立运行的,怎么使用,待会就来
第二步,生产词条(找到野怪)
怎么生产词条,也就将你需要识别的一些文字,做成一个jpg的图片,怎么做,直接截图呗,然后保存为jpg就行了
是不是说好简单,还没完呢!
有了jpg图片后,需要对其改变格式,不能手动改变后缀,需要通过格式工厂,或者在线转换插件进行转换,将jpg的图片转换为tif的文件格式,然后启动我们的新手训练营jTessBoxEditor_jb51,(里面有一个启动脚本的了)
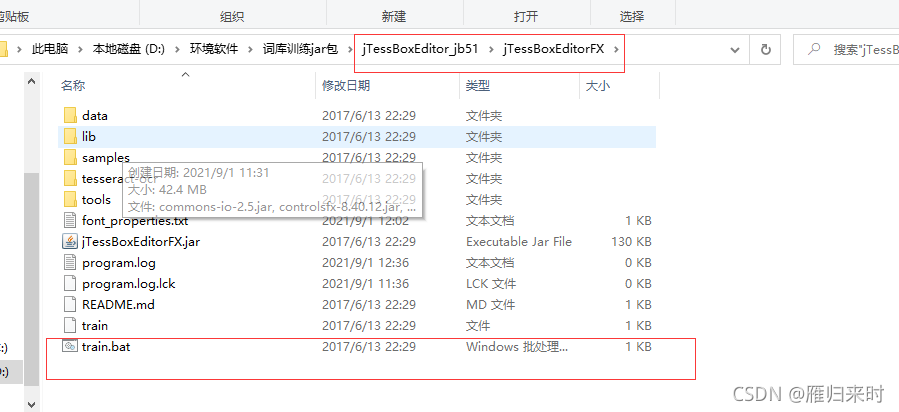
就是上面圈住的这个bat脚本,启动后,会出来一个Java窗口
先过去将刚刚的图片更改图片名字,这个是有要求的
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库myfontlab 字体名normal
那么我们把图片文件重命名 myfontlab.normal.exp0.jpg在转tif。
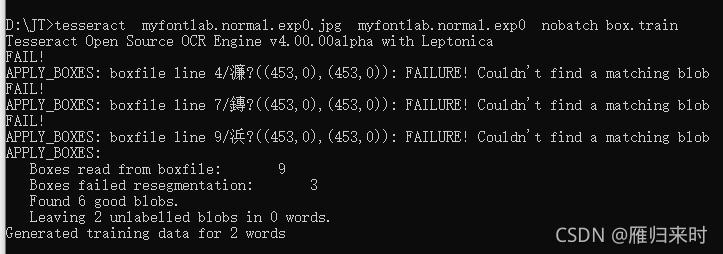
这个时候呢,我们需要打开黑命令框(CMD)输入命令生成box文件
tesseract myfontlab.normal.exp0.jpg myfontlab.normal.exp0 -l chi_sim batch.nochop makebox
运行结果如图
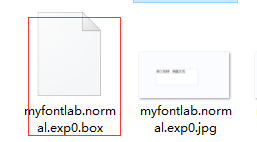
然后就会产生一个新的文件在该文件夹下
这个时候就需要用的我们的jTessBoxEditor_jb51了,点击open,选择刚刚处理过得tif文件图片得到下面结果数据
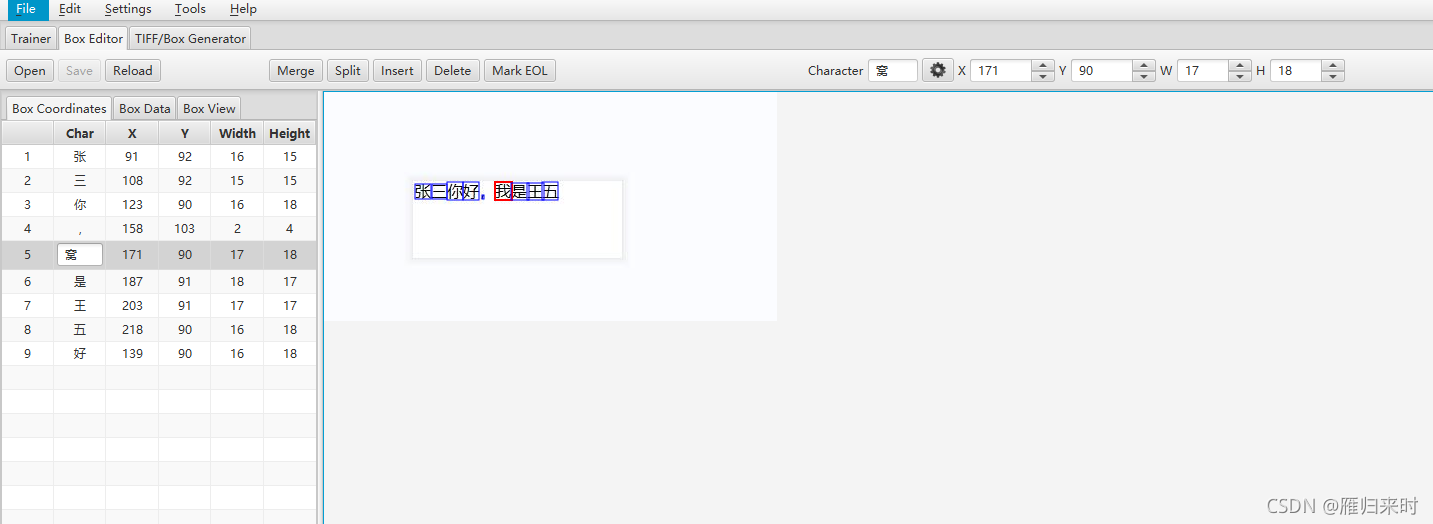
然后开始修改我们不对的字第5行的窝应该是我,所以需要进修改,选择改行,
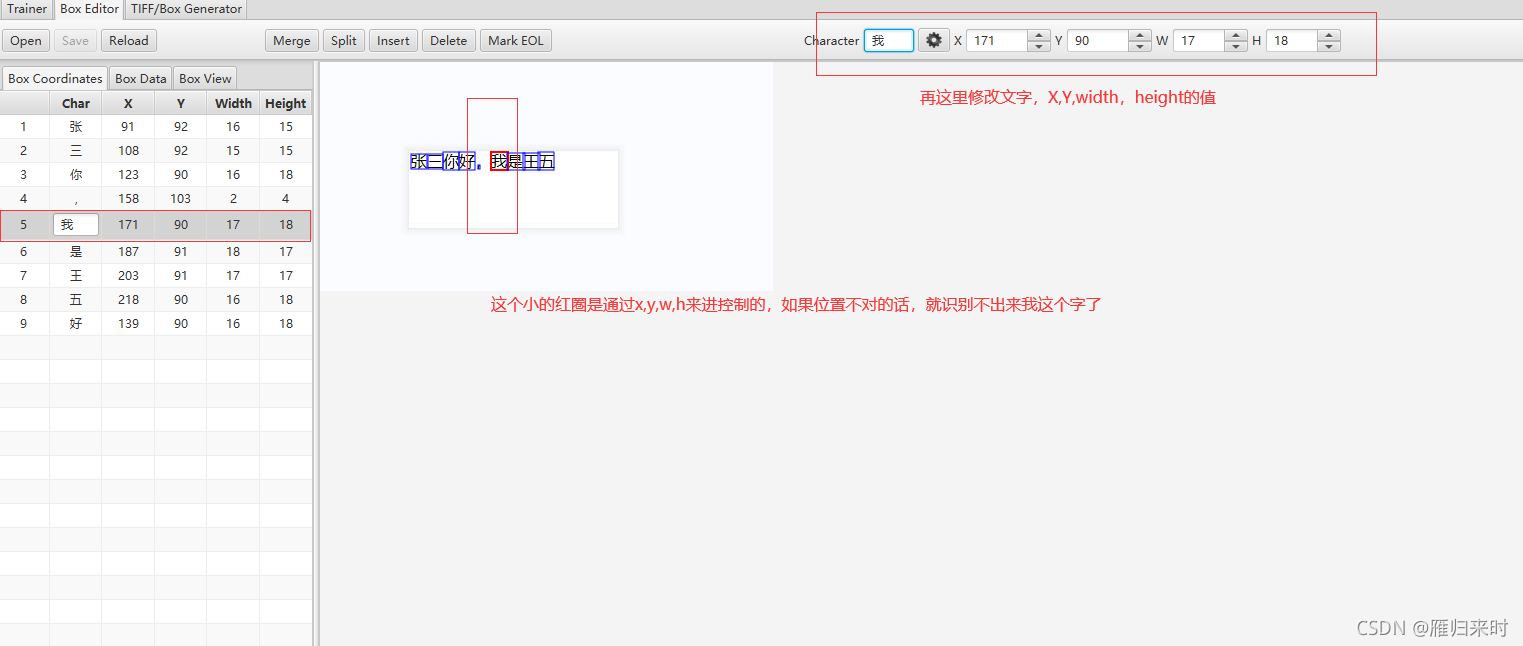
然后点击save进保存,这个时候就词条就生产完毕了需要导入到我们的词库中去
第三步,词条添加到词库中(捡装备了)
cmd中输入命令,生成.tr文件
tesseract myfontlab.normal.exp0.jpg myfontlab.normal.exp0 nobatch box.train

再输入命令,生成unicharset文件
unicharset_extractor myfontlab.normal.exp0.box

新建一个font_properties.txt文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
运行命令
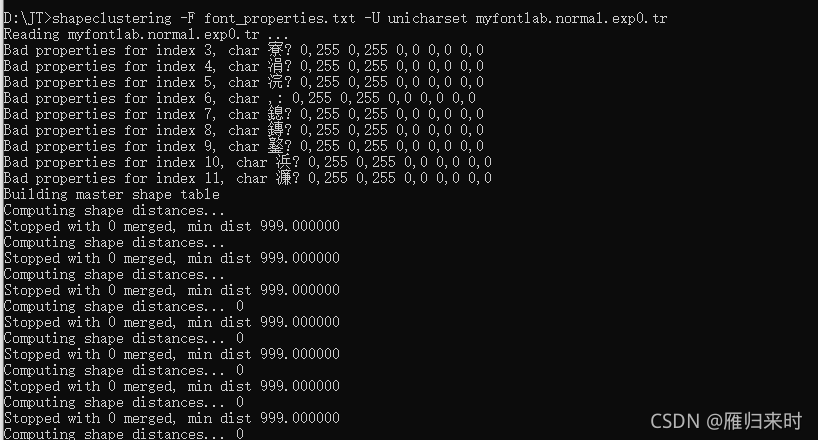
shapeclustering -F font_properties.txt -U unicharset myfontlab.normal.exp0.tr
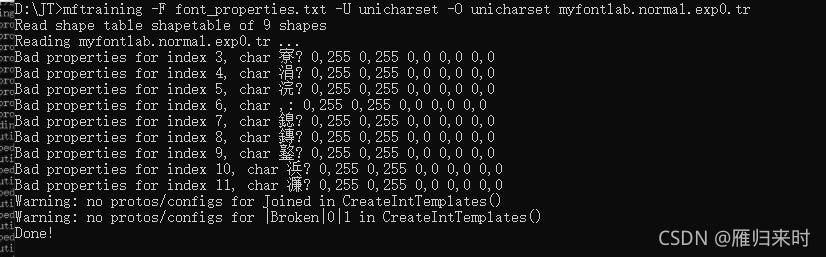
mftraining -F font_properties.txt -U unicharset -O unicharset myfontlab.normal.exp0.tr
cntraining myfontlab.normal.exp0.tr
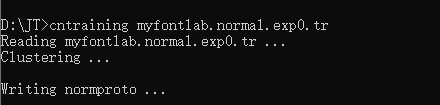
目录下会生成对应下列五个文件,在这五个文件前加上normal.进行重命名
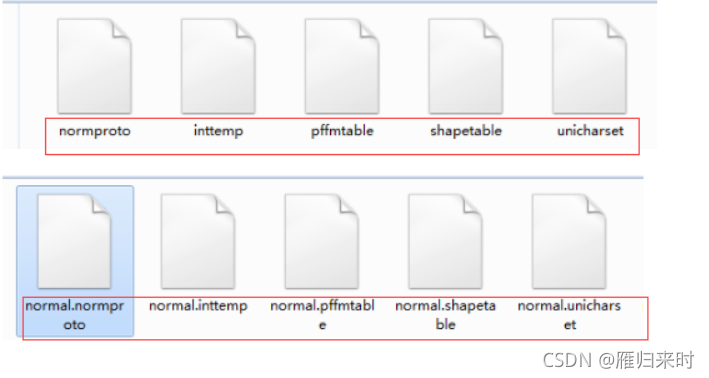
合并五个文件,此时目录下的normal.traineddata 就是训练好的字库文件
执行 命令
combine_tessdata normal.
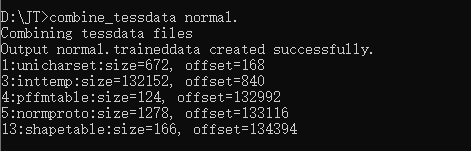
最后就产生了一个新的文件,这就是刚刚训练出来的词库
最后将新的词库放人的OCR中就行了,怎么放,教你
把normal.traineddata 复制到Tesseract-OCRt程序目录下的“tessdata”目录,
在Tesseract-OCRt程序目录下执行
tesseract.exe myfontlab.normal.exp0.jpg out –l normal

这个时候,词库就好了,再运行一下试试
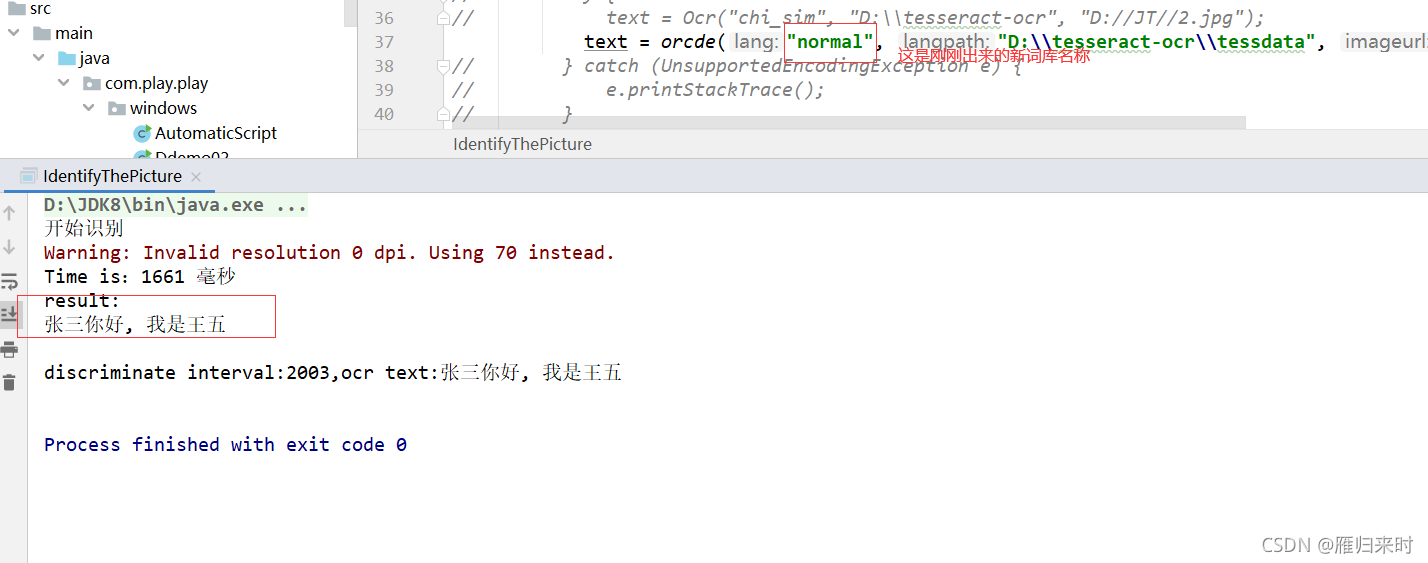
完美,图文识别成功
疯狂打架去吧,再也不用担心打不过了 ^_^
以上内容可能有不正确的地方,望大佬指正,如果需要下载配置介绍,欢迎评论去留言哦
附上pom文件依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.play</groupId>
<artifactId>play</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>play</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--tesseract-platform里面包含了所有tesseract所需要的jar-->
<dependency>
<groupId>org.bytedeco.javacpp-presets</groupId>
<artifactId>tesseract-platform</artifactId>
<version>3.04.01-1.3</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.4.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>














 5501
5501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









