







Zhu T, Li L, Yang J, et al. Multimodal sentiment analysis with image-text interaction network[J]. IEEE Transactions on Multimedia, pages 1–1, 2022(CCF B类)
目录
(1)Cross-modal Alignment Module
(4)Multimodal Sentiment Classification
一、本文贡献
- 提出一种新的针对于多模态情感分析的图像文本交互网络。该方法通过对齐情感图像区域和文本词用于分析图像文本交互。
- 基于跨模态的注意力机制提出了一种跨模态的对齐模块,用来捕获图像区域和文本单词之间的细粒度对应关系;为抑制错位对齐的区域单词对所产生的消极影响,提出一个自适应的跨模态门模块融合多模态特征。
- 大量的实验验证了本文方法的优点。进行消融实验,验证方法的合理性。
二、本文所提出的方法
1.模型框架
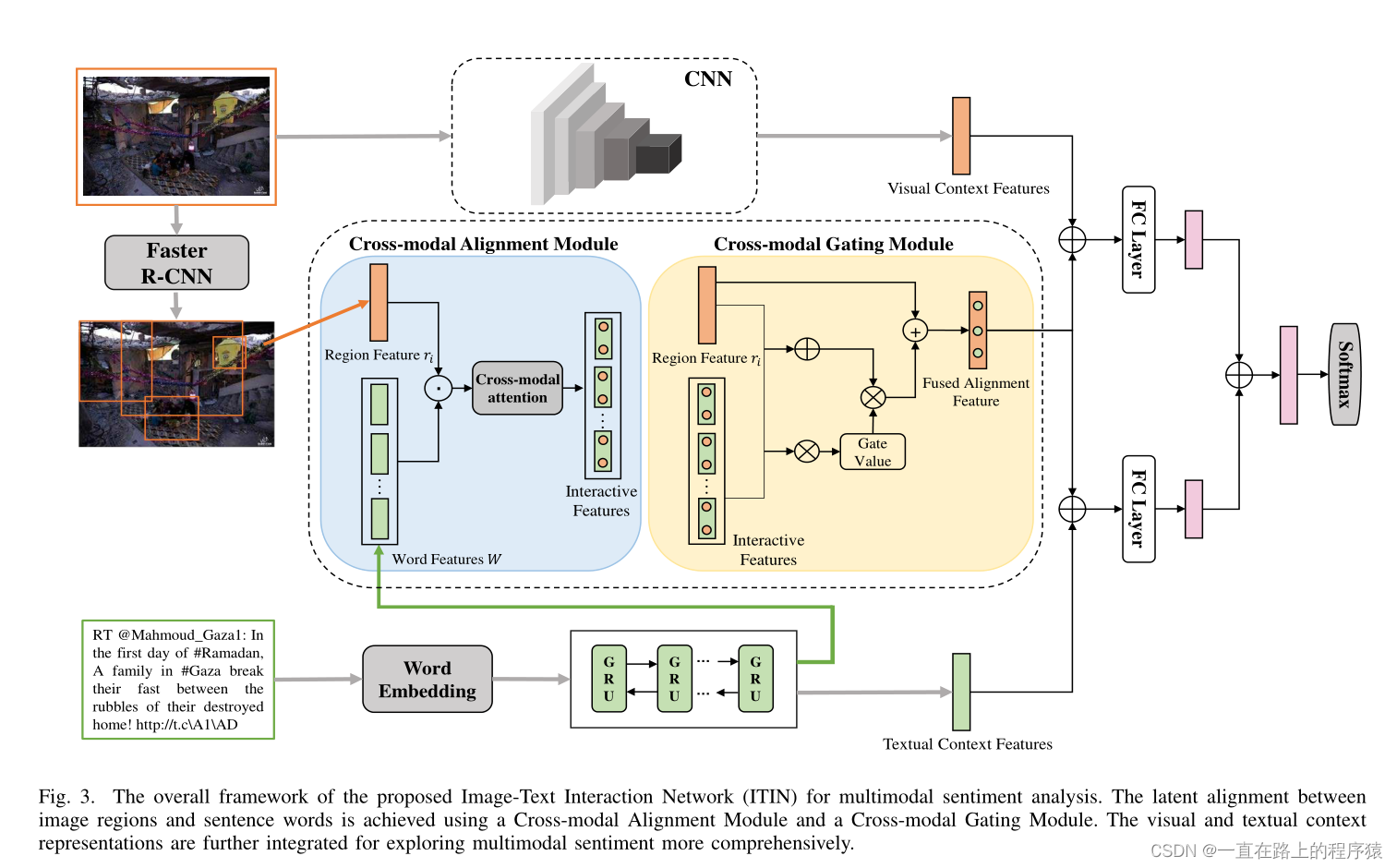
2.图像文本交互
(1)Cross-modal Alignment Module
跨模态对齐模块目的是在嵌入空间中对齐图像区域和句子中的单词。
图像区域特征提取:对于输入的图像I,使用在Visual Genomes数据集上预训练的Faster R-CNN检测图像区域以及相关的表示。取每个图像的前m个区域提示框,每个区域是一个2048维的向量,定义为𝑓𝑖,i=1,2,3…m。通过一个线性映射将𝑓𝑖到维度为d的区域特征𝑟𝑖。

![]()
文本特征提取:使用预训练的Bert-Base将具有n个词的句子中的每一个词表示为768维的向量𝑥𝑖,i∈[1,n]。然后使用双向GRU概括句子中的上下文信息。
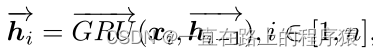
![]()
第一个h𝑖指前向传播的隐藏状态,第二个h𝑖指反向传播的隐藏状态,最终的词向量𝑤𝑖为两个方向的隐藏状态取平均。
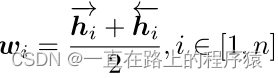
已知区域级别的特征集 R={r1,…,rm} 和单词级别的特征集 W={w1,….,wn} 。使用跨模态注意力机制,模型可以根据每一个图像区域特征关注句子中的单词,从而发现和每一个区域特征最相关的文本信息。
注意力矩阵计算过程:
![]()
通过两个矩阵Wr和Wt,将R和W映射到同一个共享空间中,随后进行矩阵乘法得到注意力分数矩阵A,A∈𝑅𝑚∗𝑛。𝐴𝑖𝑗揭示着第i个区域和第j个单词之间的关系。
对矩阵A在每一行上使用softmax函数,使得矩阵A的行和为1,得到每一个单词与相应图像区域的关联程度。
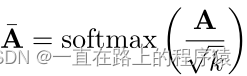
使用规范化的矩阵A,根据每一个图像区域聚集所有的词向量。U的第i行表示与图像第i个区域对应的交互文本向量。
![]()
(2)Cross-modal Gating Module
跨模块对齐模块生成了与每一个区域最相关的词语级别的特征信息。然而不是所有得到的区域文本对可以很好地对齐。该模块通过控制特征融合的强度,消除未对齐的区域文本对的影响,增强跨模态信息的交互。
通过计算gate value评估对齐程度,
![]()
接下来使用gate value控制向后面传递的信息量,若图像区域和相应的单词对齐的很好,那么gate value就大;若图像区域和相应的单词对齐的不好,那么gate value的值就小,小的值可以达到抑制消极信息的目的。
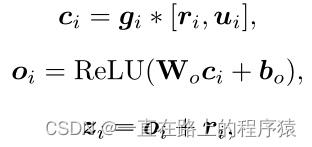
由于图像使用了m个区域,所以最终得到的Z={z1,z2,…,zm},Z的size为(m,d)。Z是一个融合特征,暗含图像区域和词之间的对齐信息。
最后,使用注意力机制聚集特征Z得到整个输入的图像文本对的表示C。
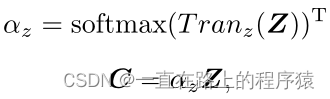
(3)语境信息提取
同一个物体在不同的语境中会表达不同的情感,使用Faster R-CNN提取区域特征并不涉及语境信息的提取。针对图像,使用在ImageNet上预训练的ResNet提取图像的语境信息。
![]()
针对于文本,使用双向GRU的文本特征表示中已经包含了语境信息,所以选择对所用的文本向量执行求和取平均的操作获得文本的语境信息。
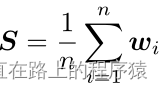
接下来将图像语境信息V和文本语境信息S加入到向量C中。F为最终的跨模态交互向量,F中含有对齐信息和语境信息。

(4)Multimodal Sentiment Classification
将特征向量F送入到softmax层预测最终的情感类别。
![]()
三、实验
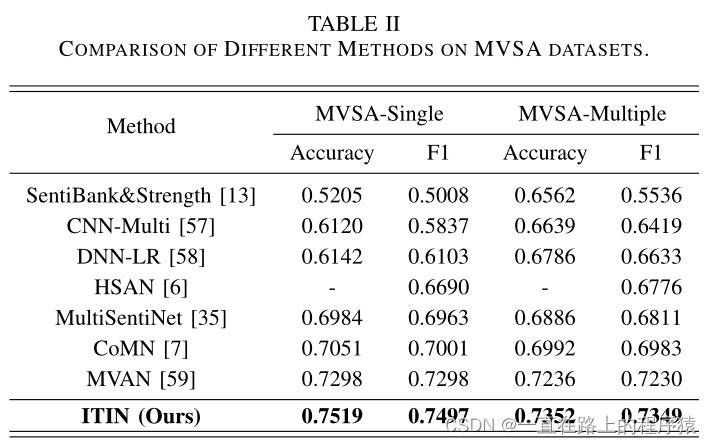
1.在MVSA-S和在MVSA-M上的实验结果
2.消融实验的实验结果
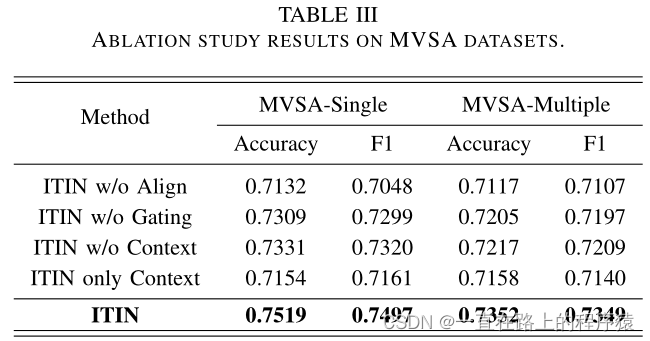
(1)没有对齐层的ITIN效果更差,这证明了对齐图像区域和文本单词的有效性
(2)不使用Gating的ITIN效果差于ITIN,表明门控机制可以进一步增强跨模态交互作用。
(3)不使用Context的ITIN效果差于ITIN,验证了语境信息对情感分类任务的补充作用。
(4)ITIN w/o Context和ITIN only Context的结果比较,表明细粒度的跨模态交互有利于多模态情感分析。
3.案例分析

第一列是输入的image-text pair,第二列是用彩色边框标记的图像区域和对应的不同深浅颜色的文本单词,其中单词的权重越大,颜色也就越深。通过颜色识别图像区域和文本之间的对应关系。第三列是区域文本对的gate value,可以发现对齐的区域文本对的gate value的值大,对不不匹配的则gate value的值就小。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









