









目录
版本信息:
RocketMQ-5.1.3
写在前面:
首先,笔者先吐槽一下RocketMQ的官方,源码中啥注释都没有,虽然文档给的多,但是很多都是版本过时不及时更新,阅读者只能靠自己的强硬的技术去理解~
回归正题,如今互联网的技术离不开微服务、分布式的体系,所以在分布式的体系中如何创建一个全局唯一的ID是大家所面对的问题。现大厂都提出了解决方案:Twitter的雪花算法(Snowflake)、美团的Leaf算法、以及Mysql、Redis 这种自带原子性操作的中间件。
当然RocketMQ为分布式而生的消息队列中间件肯定也需要有他的分布式ID解决方案(虽然笔者不知道该如何称呼,源码中也没有给出)~
源码剖析:
createUniqID 方法是本文章所论述的点,此方法在生产者往Broker 发送消息时,给发送的消息创建一个唯一KEY时调用。
public static void setUniqID(final Message msg) {
// 如果用户自定义了唯一key,RocketMQ就不提供默认实现
// 否则RocketMQ调用createUniqID 方法提供默认的实现
if (msg.getProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX) == null) {
msg.putProperty(MessageConst.PROPERTY_UNIQ_CLIENT_MESSAGE_ID_KEYIDX, createUniqID());
}
}在看createUniqID之前,我们先需要看一些变量的初始化作为看createUniqID 方法的铺垫~
org.apache.rocketmq.common.message MessageClientIDSetter类中。
public class MessageClientIDSetter {
private static final int LEN; // 原有长度
private static final char[] FIX_STRING; // 变化后的char字符数组(其实就是字符串)
private static final AtomicInteger COUNTER; // 原子变量
private static long startTime; // 记录开始时间
private static long nextStartTime; // 记录最后时间(用于更新)
static {
byte[] ip;
try {
// 获取到本机的IP地址。
// 一共占用4个字节。
ip = UtilAll.getIP();
} catch (Exception e) {
ip = createFakeIP();
}
// 4(ip) + 2(pid进程id) + 4(类加载器的HashCode) + 4(时间差值) + 2(自增位)
LEN = ip.length + 2 + 4 + 4 + 2;
// 拼接处理分布式体系的10字节
// 处理 本机IP + JVM进程PID + HashCode
ByteBuffer tempBuffer = ByteBuffer.allocate(ip.length + 2 + 4);
tempBuffer.put(ip);
tempBuffer.putShort((short) UtilAll.getPid());
tempBuffer.putInt(MessageClientIDSetter.class.getClassLoader().hashCode());
// 把10字节中的内容 作为索引值 转换成16进制的字符串表示
// 简单来说,这一步就是编码,因为ID不可能用负数或者二进制01表示。
FIX_STRING = UtilAll.bytes2string(tempBuffer.array()).toCharArray();
// 设置当前启动的时间(用来4字节的计算时间差值)
// 并且设置末尾时间,末尾时间用来更新时间
// 如果有小伙伴看过雪花算法,就明白,雪花算法的时间差值是41位,限制只能用多少年,而这里做了优化,动态更新时间。
// 这里的起始时间是本月的1号。
// 末尾时间是下月的1号。
setStartTime(System.currentTimeMillis());
// 原子性自增,用于最后2位的自增位。
COUNTER = new AtomicInteger(0);
}
}这里是核心所在,所以在提供的源码中笔者有非常详细的注释,并且这里做一个总结:
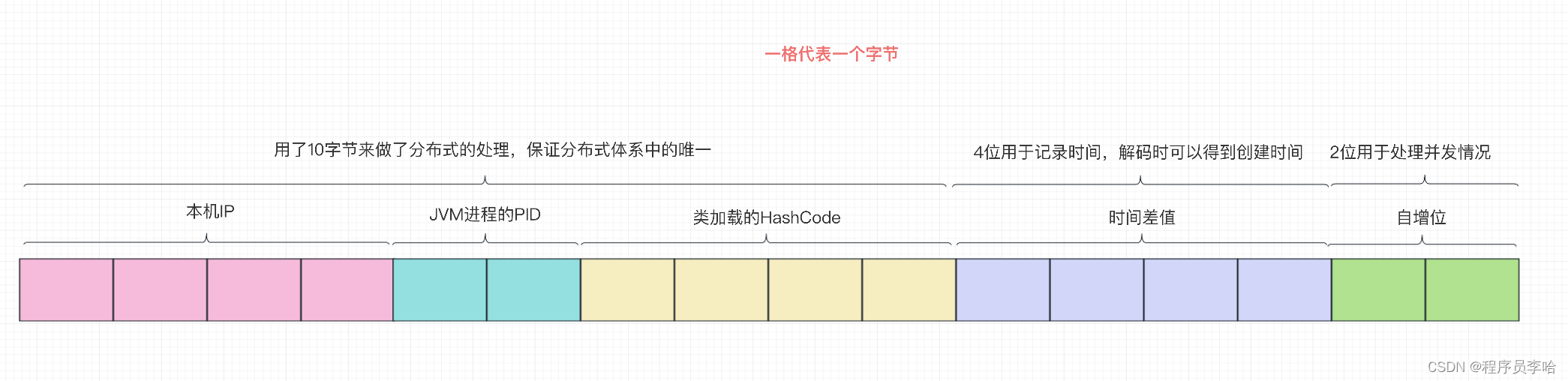
- RocketMQ的分布式ID算法核心就在这里,用了16字节表示:4(本机IP) + 2(进程的PID) + 4(类加载器的HashCode) + 4(时间差值) + 2(自增位)
- 本机IP + 进程PID + 类加载器HashCode 解决了分布式环境下集群的重复可能性
- 最后2位的自增位,用于处理本机RocketMQ的并发重复可能性
- 时间差值用于解码时获得创建的时间
看到这里,有读者会问,那源码中FIX_STRING 变量是干啥的,这很简单,如上图所示总共16字节,因为byte用10进制可能会有负数,作为分布式ID总不能是一串负数或者二进制01表示把。所以RocketMQ用16字节的Byte数组转换成 16进制的字符串表示,存储在FIX_STRING中。
这里需要注意,在上文的初始化代码中,只对 本机IP + JVM进程PID + HashCode做了处理,后续的时间差值和自增位在createUniqID方法中做处理。
以上的铺垫已做完,直接看到org.apache.rocketmq.common.message MessageClientIDSetter类中createUniqID方法
public static String createUniqID() {
// 在Java中byte占用一个字节,char占用2个字节
// 所以这里需要创建LEN * 2 的char数组来存放完 16字节的数据。
char[] sb = new char[LEN * 2];
// 在上文的初始化中把 IP + PID + HashCode 16进制字符串放入到FIX_STRING
// 这里把FIX_STRING拷贝到sb中。
System.arraycopy(FIX_STRING, 0, sb, 0, FIX_STRING.length);
long current = System.currentTimeMillis();
// 是否需要更新时间。
if (current >= nextStartTime) {
setStartTime(current);
}
// 计算出运行时间差值。
int diff = (int)(current - startTime);
if (diff < 0 && diff > -1000_000) {
diff = 0;
}
// 获取到长度,这个长度作为索引。
int pos = FIX_STRING.length;
// 这里填充了4字节的时间差值
UtilAll.writeInt(sb, pos, diff);
pos += 8;
// 这里填充了2字节的自增位。
UtilAll.writeShort(sb, pos, COUNTER.getAndIncrement());
// char数组转换成字符串。
return new String(sb);
}- 获取到初始化中初始的FIX_STRING字段,此字段已经处理了本机IP + JVM进程PID + HashCode,后续的时间差值 和 自增位还没做处理,下文会对其做处理
- 获取到当前时间,判断是否需要更新时间(没个月月初更新)
- 得到时间差值赋值给diff变量,并且转换成16进制的字符表示
- 获取到自增值,并且转换成16进制的字符表示
- 最终把16进制的 char数组转换成String对象
- 整个分布式的ID 创建过程完毕。
总计:
只需要记住三部分
- 第一部分用于处理分布式的重复可能性(IP + PID + HashCode)
- 第二部分用于记录创建时间
- 第三部分用于处理机器的并发创建ID的重复可能性(原子变量解决)
















 3564
3564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











