









 本文深入探讨了Aho-Corasick算法的原理及其在字符串搜索中的应用,通过具体实例展示了算法的工作流程,并提供了详细的实现代码。此外,还进行了实验评估,验证了算法的有效性和效率。
本文深入探讨了Aho-Corasick算法的原理及其在字符串搜索中的应用,通过具体实例展示了算法的工作流程,并提供了详细的实现代码。此外,还进行了实验评估,验证了算法的有效性和效率。
偷懒是罪过,拖到今天才把测试弄完。
算法实现在了解原理之后并不算难,本文的测试指标比较简单,只使用了一个数据集按照大小和规则书计算时间和速度。
建议:了解以下AC算法的改进方法、测试可以用多种数据集,测试以下内存消耗。
一、算法概述
Aho–Corasick算法是由Alfred V. Aho和Margaret J.Corasick 发明的字符串搜索算法,用于在输入的一串字符串中匹配有限组“字典”中的子串。
该算法主要依靠构造一个有限状态机(类似于在一个trie树中添加失配指针)来实现。这些额外的失配指针允许在查找字符串失败时进行回退(例如设Trie树的单词cat匹配失败,但是在Trie树中存在另一个单词cart,失配指针就会指向前缀ca),转向某前缀的其他分支,免于重复匹配前缀,提高算法效率。
算法主要分为以下三个部分:
- 构造Goto表:成功转移到另一个状态
- 构造Failture指针:如果某状态发生匹配失败,需要跳转到一个特定的节点
- 匹配:匹配成功某一字符串
举例:
模式串{she,his,hers},文本为“ushhis”。算法流程如下图:
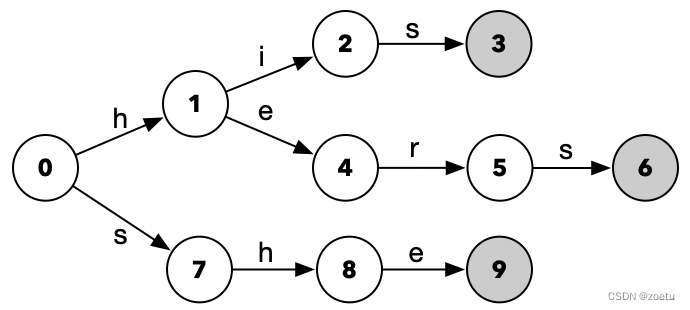
- Goto:根据模式串{she,his,hers}构造出一个Trie树结构,如左图所示。其中,灰色节点代表终点态,节点状态之间的字符为跳转字符。
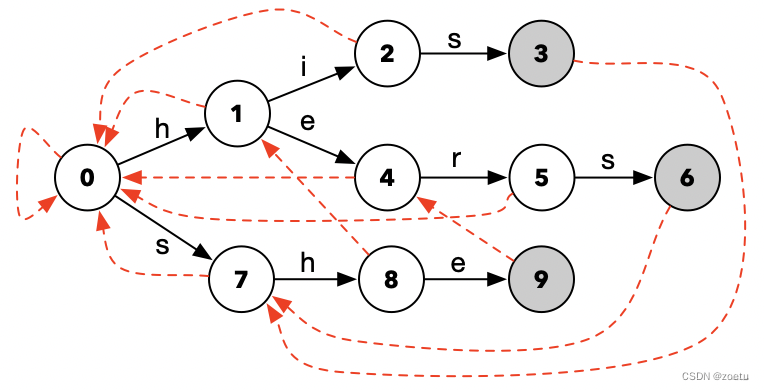
- Failure:
- 根节点:失败节点指向自己。
- 非根节点:对于状态匹配失败的节点a,如果其父节点的失败节点可以根据该节点a的跳转字符成功转移状态到另一节点b,那么就将失败节点a指向该节点b;如果其父节点的失败节点不能根据该节点的跳转字符转移状态到另一节点,那么就将失败节点a将检查其父节点的父节点的失败节点是否满足上述条件;依次递推,如果回溯到根节点还未找到,那就指向将失败节点指向根节点。
- Match:
a. 每轮跳转结束后,所停留在的节点,如果是终点态,则该节点对应的模式串匹配成功;
b. 从停留的节点开始,沿Failure路径递归至根节点,路过的所有的节点,只要是终点态节点,则该节点对应的模式串也就匹配成功。
匹配例子:
状态转换图如上所示,当我们输入文本为ushhis时,跳转步骤如下:
- 当前状态0,输入u,无法正常跳转,进入Failure路径,到达状态0
- 当前状态0,输入s,可以正常跳转,到达状态7
- 当前状态7,输入h,可以正常跳转,到达状态8
- 当前状态8,输入h,无法正常跳转,进入Failure路径,到达状态1
- 当前状态1,输入i,可以正常跳转,到达状态2
- 当前状态2,输入s,可以正常跳转,到达状态3
当我们执行到上面的第八步时,我们发现状态3是一个终点态。所以,我们可以判定,此时我们找到了模式串his。
二、算法实现
下面是算法主要函数:
1. 构建Aho–Corasick自动机
func (ac *AhoCorasick) Build(dictionary []string) {
for i, _ := range dictionary {
ac.Insert(dictionary[i]) //goto
}
ac.Build_fail() //fail
ac.mark = make([]bool, ac.size)
}
func (ac *AhoCorasick) Insert(s string) {
curNode := ac.root
for _, v := range s {
if curNode.child[v] == nil {
curNode.child[v] = newTrieNode()
ac.count++
}
curNode = curNode.child[v]
}
curNode.end = len(s)
curNode.index = ac.size
ac.size++
}
func (ac *AhoCorasick) Build_fail() {
ll := list.New()
ll.PushBack(ac.root)
for ll.Len() > 0 {
temp := ll.Remove(ll.Front()).(*trieNode)
var p *trieNode = nil
for i, v := range temp.child {
if temp == ac.root {
v.fail = ac.root
} else {
p = temp.fail
for p != nil {
if p.child[i] != nil {
v.fail = p.child[i]
break
}
p = p.fail
}
if p == nil {
v.fail = ac.root
}
}
ll.PushBack(v)
}
}
}
2. 输出匹配结果
func (ac *AhoCorasick) Match(s string) (ret []int, pos []int) {
curNode := ac.root
ac.resetMark()
var p *trieNode = nil
for key, v := range s {
for curNode.child[v] == nil && curNode != ac.root {
curNode = curNode.fail
}
curNode = curNode.child[v]
if curNode == nil {
curNode = ac.root
}
p = curNode
for p != ac.root && p.end > 0 && !ac.mark[p.index] {
ret = append(ret, p.index)
pos = append(pos, key-p.end+2)
p = p.fail
}
}
return ret, pos
}
三、实验
1. 实验设计
1) 实验环境
- 操作系统: windows
- CPU: Intel® Core™ i5-8250U CPU @ 1.60GHz
2) 实验数据
- 数据集1:url_data.txt
总共100万条数据,占内存39.5MB,平均字符串长度约为49。 - 数据集2:url_2w.txt
总共19956条数据,占内存827KB,平均字符串长度约为53。
AC自动机由数据集2的近2万条规则构造,测试集由数据集1的100万条规则构造。
2. 不同大小文件的匹配时间
将数据集1拆分为不同大小的文件,记录匹配时间及速度。
1) 实验过程
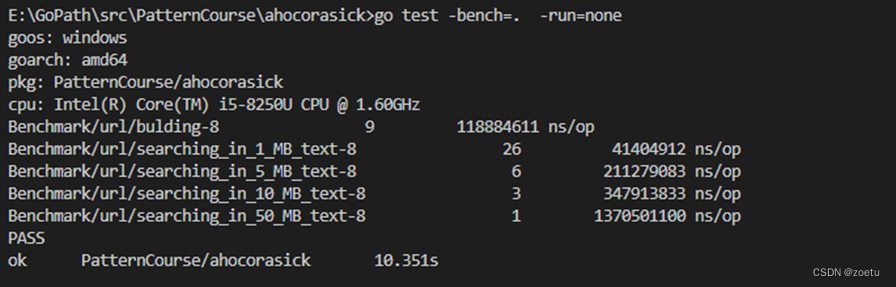
2) 实验结果

实验结果如上表所示,匹配时间随着文件增大而增加,文件大小为39.5MB时,匹配时约为1.37s,匹配速度达到了28MB/s的速度。
3. 不同规则条的搜索时间
将数据集1的100万条规则大小的文件拆分成不同规则数目文件,记录匹配时间及速度。
1) 实验过程
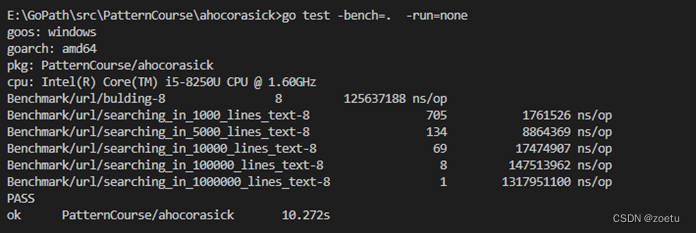
2) 实验结果

实验结果显示规则数增加,匹配时间加长。当规则数量达到100万条时,匹配时间需要1.3s左右。另外,每条规则的匹配时间最好为0.00000131795,最差为0.00000177287s,相差不大。



















 286
286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











