







前言
近期需要阅读的论文很多,偶然间在微博刷到许多人推荐科研利器ChatPDF和有道速读。使用后的结论是不推荐使用,下面分别给出理由。
使用&评价
网页版,无需安装任何东西,两款都支持中文。
下面太长不看,只看这个表也够。
| ChatPDF | 有道速读 | |
|---|---|---|
| 语言 | 中英文(给指令) | 中英文 |
| 文件导入 | 本地/URL | 本地 |
| 特点 | 1. 看起来很专业,实际可能是瞎话(有可能出现凭空捏造),也可能是有效信息(参考问答效果最后一问题) 2. 提取信息来源有限,集中于首页和最后一页 | 1. 生成速度略慢 2. 翻译全文,涉及数学符号的句子翻译起来很难看 3. 回答冗余,来源比较可靠 |
ChatPDF
ChatPDF支持URL更方便,界面类似于ChatGPT,三段式。跟自己看论文的方式差不多,先看abs然后intro最后一段获取信息,英文不好的小伙伴还不如直接用翻译器。
缺点:
- 看起来很专业,实际是瞎话(有可能出现凭空捏造)
- 提取信息来源有限,集中于首页和最后一页
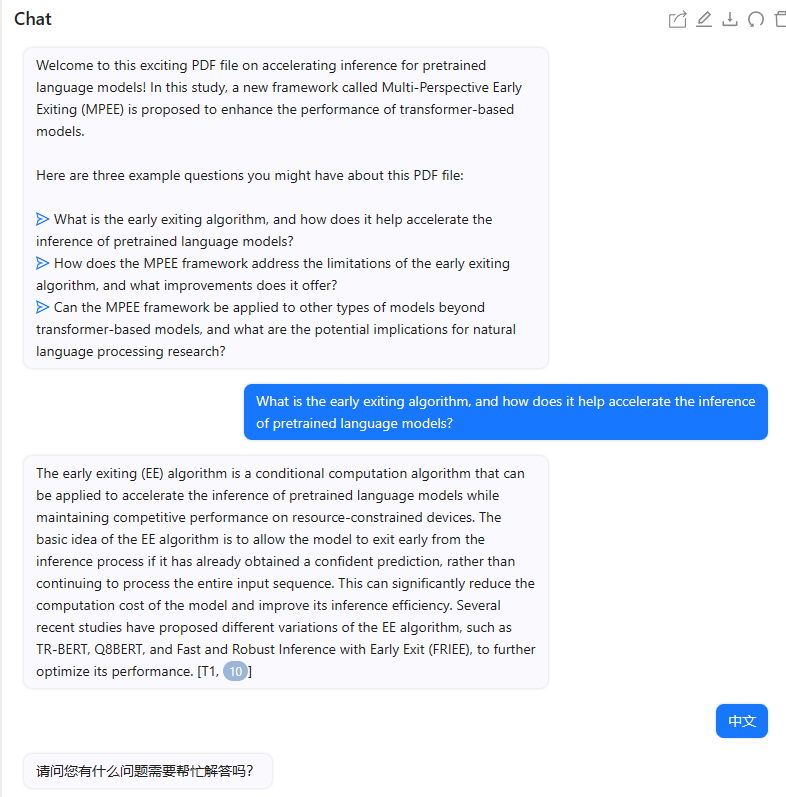
有道速读
缺点:
- 生成速度略慢
- 涉及数学符号的句子翻译起来很难看
- 问答助手的回答比较冗余
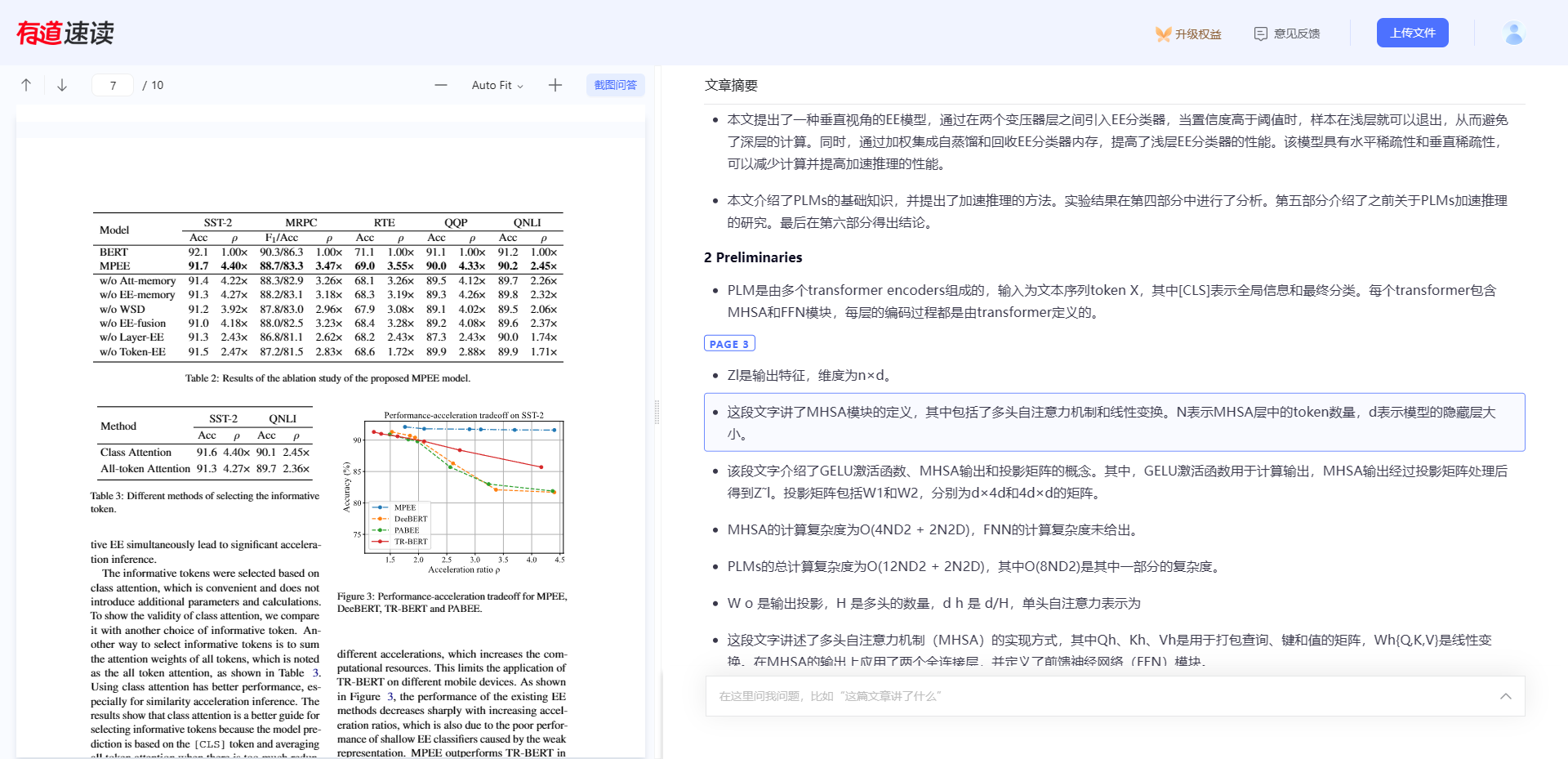
只支持本地导入,本Zotero重度用户不适。界面如下图所示,有道速读更像一个翻译器,直接帮你翻译好了所有的句子,有些断句让人困惑!
有道速读的问答似乎能给出一些有用的回答,看起来不是完全照搬的翻译,应该是几段话生成的。另外,生成速度比ChatPDF略慢。
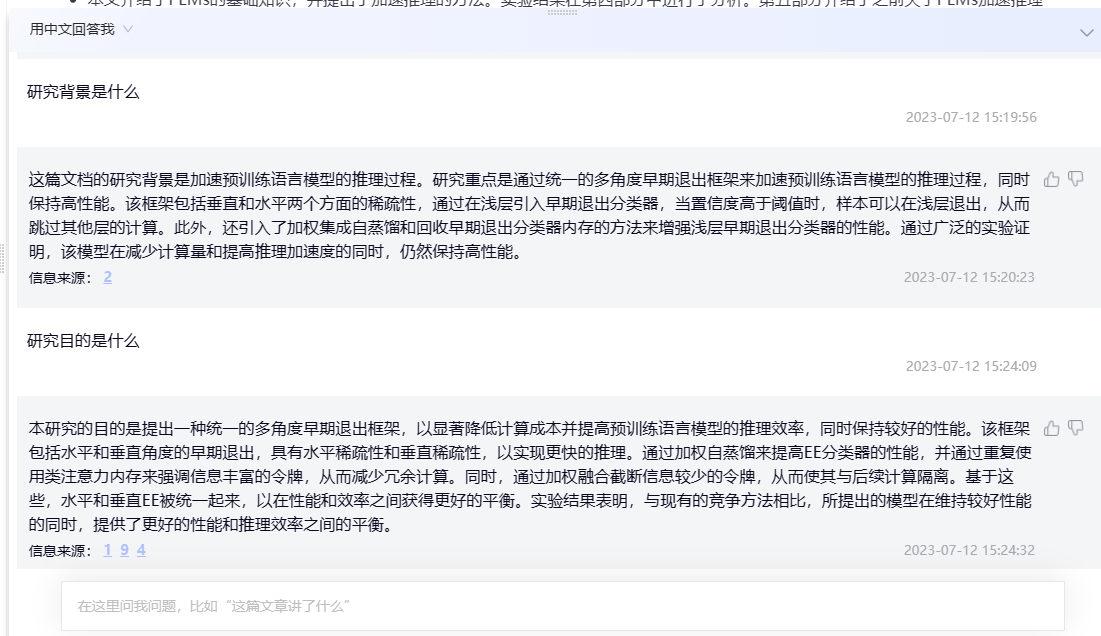
细看问答效果
问两个助手相同的问题:
- 这篇文章的研究背景是什么
- 这篇文章的方法是什么
- 这篇文章的实验结果是什么
- 这篇文章的局限性是什么
回答如下:
| 问题 | ChatPDF | 有道速读 | 简评 |
|---|---|---|---|
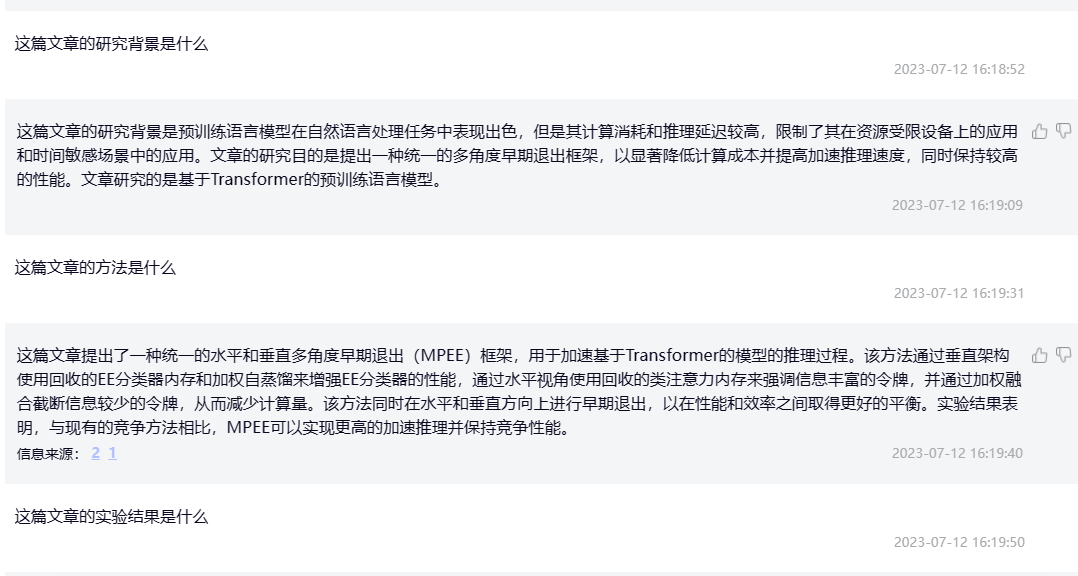
| 这篇文章的研究背景是什么 | 这篇文章的研究背景是针对transformer-based模型的推理加速问题。虽然transformer-based模型在自然语言处理任务中表现出色,但是它们通常需要大量的计算资源和时间来进行推理,这限制了它们在实际应用中的使用。因此,本文提出了一种名为MPEE(多角度早期退出)的框架,旨在通过多角度早期退出算法来加速transformer-based模型的推理过程,从而提高其效率和性能。该框架通过使用水平和垂直两个角度的早期退出算法,以及加权自蒸馏技术和重复利用分类器和注意力机制等技术,实现了更高效的推理加速。 | 这篇文章的研究背景是预训练语言模型在自然语言处理任务中表现出色,但是其计算消耗和推理延迟较高,限制了其在资源受限设备上的应用和时间敏感场景中的应用。文章的研究目的是提出一种统一的多角度早期退出框架,以显著降低计算成本并提高加速推理速度,同时保持较高的性能。文章研究的是基于Transformer的预训练语言模型。 | 有道速读的回答更加简洁,此处更胜一筹,但是都生成了除研究背景之外的信息。 |
| 这篇文章的方法是什么 | 这篇文章提出了一种名为MPEE(多角度早期退出)的框架,旨在通过多角度早期退出算法来加速transformer-based模型的推理过程,从而提高其效率和性能。该框架通过使用水平和垂直两个角度的早期退出算法,以及加权自蒸馏技术和重复利用分类器和注意力机制等技术,实现了更高效的推理加速。具体来说,垂直角度使用重复利用EE分类器内存和加权自蒸馏技术来增强EE分类器的性能;水平角度使用重复利用类别注意力内存来强调信息丰富的令牌,并通过加权融合截断信息较少的令牌,从而降低计算量。最后,水平和垂直EE被统一起来,以获得更好的性能和效率之间的平衡。 | 这篇文章提出了一种统一的水平和垂直多角度早期退出(MPEE)框架,用于加速基于Transformer的模型的推理过程。该方法通过垂直架构使用回收的EE分类器内存和加权自蒸馏来增强EE分类器的性能,通过水平视角使用回收的类注意力内存来强调信息丰富的令牌,并通过加权融合截断信息较少的令牌,从而减少计算量。该方法同时在水平和垂直方向上进行早期退出,以在性能和效率之间取得更好的平衡。实验结果表明,与现有的竞争方法相比,MPEE可以实现更高的加速推理并保持竞争性能。 | ChatPDF更具体地描述了提出的方法细节,更胜一筹。 |
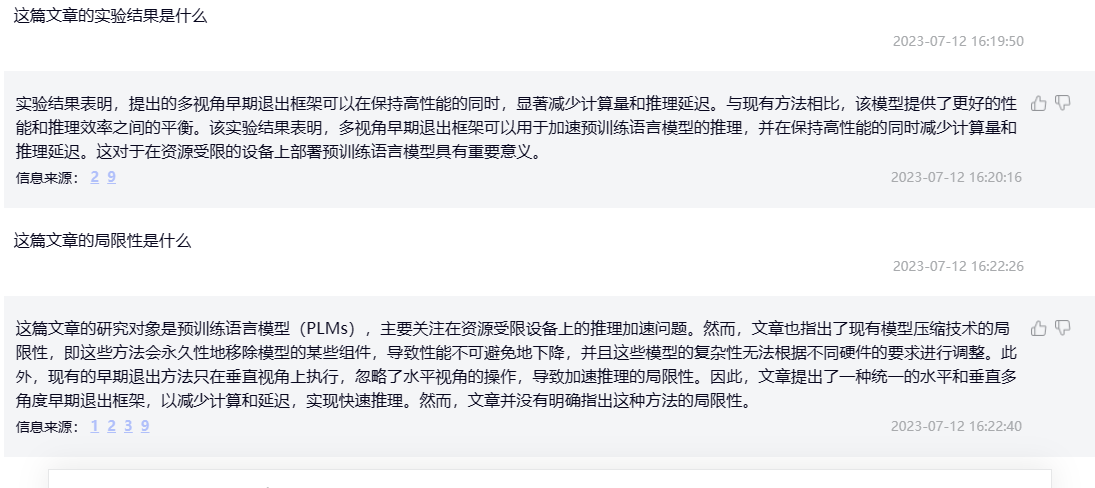
| 这篇文章的实验结果是什么 | 该文章的实验结果表明,相比于现有的竞争方法,MPEE可以在保持相当的性能的同时,实现更高的推理加速。作者在三个数据集上进行了实验,包括GLUE、SQuAD和WMT14 EN-DE。在GLUE数据集上,MPEE相比于BERT-base模型,可以将推理时间缩短了1.4倍,同时性能下降不到1%。在SQuAD数据集上,MPEE相比于BERT-base模型,可以将推理时间缩短了1.5倍,同时性能下降不到0.5%。在WMT14 EN-DE数据集上,MPEE相比于Transformer-base模型,可以将推理时间缩短了1.3倍,同时性能下降不到0.5%。这些结果表明,MPEE可以在不显著降低性能的情况下,显著提高transformer-based模型的推理效率。 | 实验结果表明,提出的多视角早期退出框架可以在保持高性能的同时,显著减少计算量和推理延迟。与现有方法相比,该模型提供了更好的性能和推理效率之间的平衡。该实验结果表明,多视角早期退出框架可以用于加速预训练语言模型的推理,并在保持高性能的同时减少计算量和推理延迟。这对于在资源受限的设备上部署预训练语言模型具有重要意义。 | 1. ChatPDF给出的实验数据更加细节,但是是凭空虚构,文章中并未使用SQuAD和WMT14 EN-DE数据集; 2. 有道速读更加笼统,但是有来源。 |
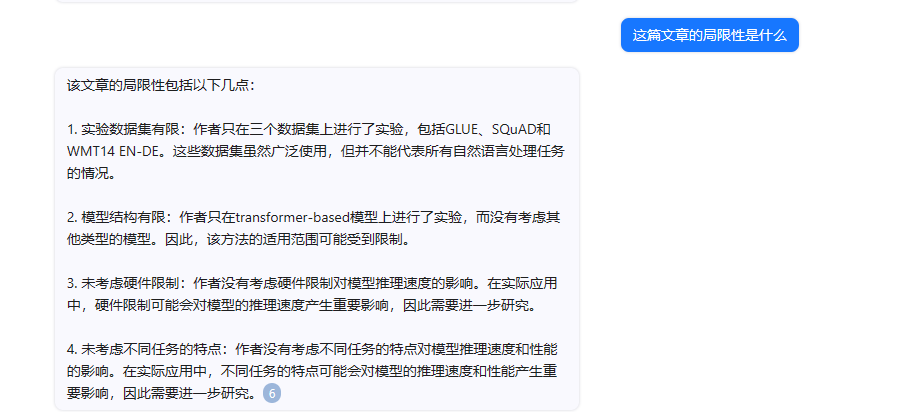
| 这篇文章的局限性是什么 | 该文章的局限性包括以下几点: 1. 实验数据集有限:作者只在三个数据集上进行了实验,包括GLUE、SQuAD和WMT14 EN-DE。这些数据集虽然广泛使用,但并不能代表所有自然语言处理任务的情况。 2. 模型结构有限:作者只在transformer-based模型上进行了实验,而没有考虑其他类型的模型。因此,该方法的适用范围可能受到限制。 3. 未考虑硬件限制:作者没有考虑硬件限制对模型推理速度的影响。在实际应用中,硬件限制可能会对模型的推理速度产生重要影响,因此需要进一步研究。 4. 未考虑不同任务的特点:作者没有考虑不同任务的特点对模型推理速度和性能的影响。在实际应用中,不同任务的特点可能会对模型的推理速度和性能产生重要影响,因此需要进一步研究。 | 这篇文章的研究对象是预训练语言模型(PLMs),主要关注在资源受限设备上的推理加速问题。然而,文章也指出了现有模型压缩技术的局限性,即这些方法会永久性地移除模型的某些组件,导致性能不可避免地下降,并且这些模型的复杂性无法根据不同硬件的要求进行调整。此外,现有的早期退出方法只在垂直视角上执行,忽略了水平视角的操作,导致加速推理的局限性。因此,文章提出了一种统一的水平和垂直多角度早期退出框架,以减少计算和延迟,实现快速推理。然而,文章并没有明确指出这种方法的局限性。 | 1. ChatPDF自我发挥,但是有参考价值; 2. 有道速读答不出来 |
参考运行图:
- ChatPDF
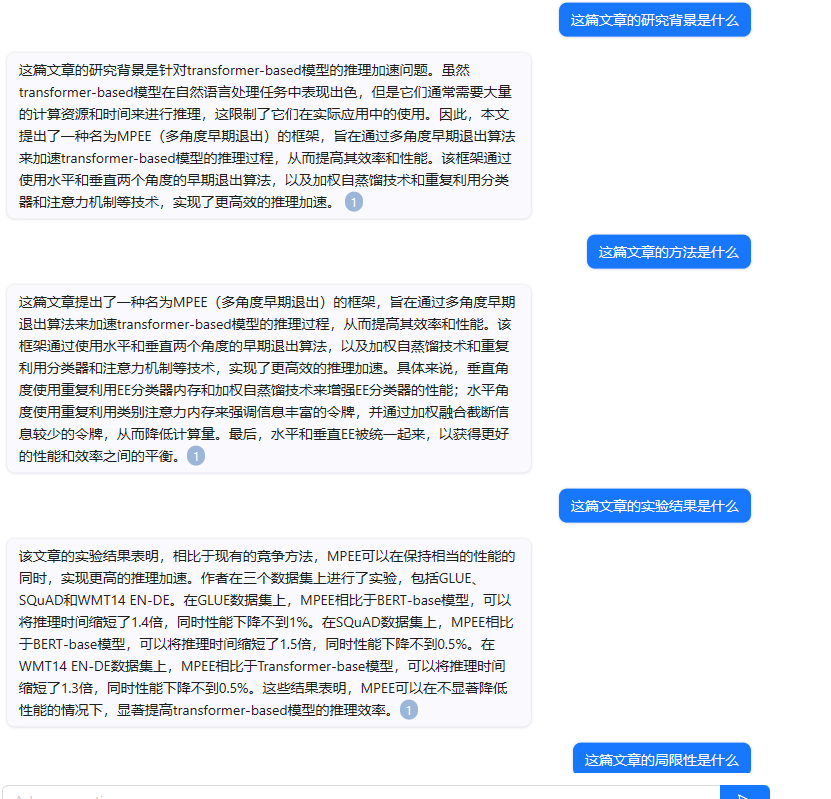
- 有道速读



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











