






全栈运行原理
一个网站是怎么来的?
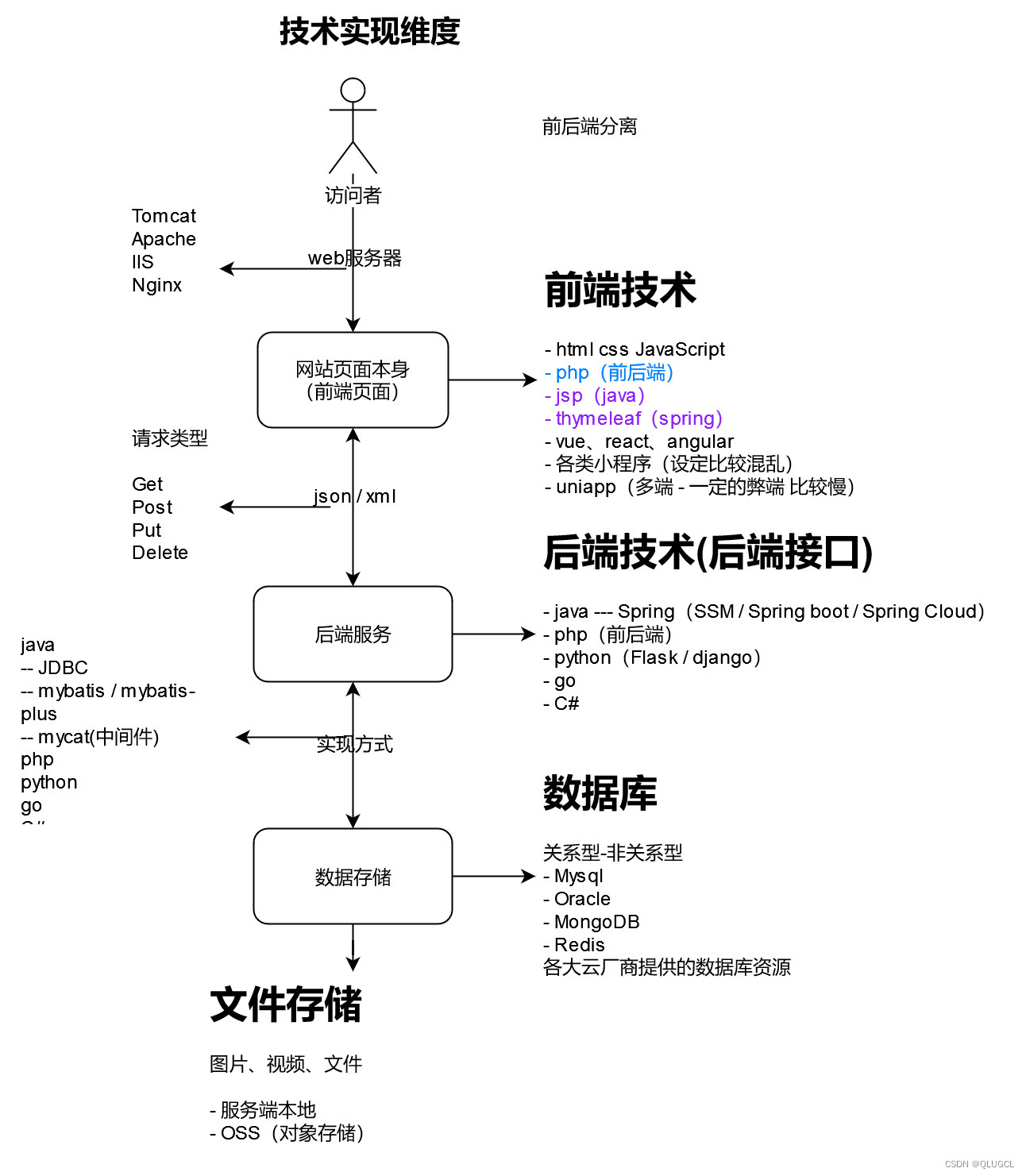
前端规划
优秀的前端工程师不仅要了解主流的前端技术,还要学习后端、网络等,提升知识广度。
而真正的前端专家们一定是长期在某一个细的领域不断深耕,才能创造更多新的技术,因此技术的深度也尤为重要。
最重要的是,要对技术充满热情,持续学习新的技术,把握业内动向,才能引领时代!
基础知识
编程语言总结
什么是计算机语言
计算机就是一台用来计算机的机器,人让计算机干什么计算机就得干什么!
需要通过计算机的语言来控制计算机(编程语言)!
计算机语言其实和人类的语言没有本质的区别,不同点就是交流的主体不同!
计算机语言发展经历了三个阶段:
机器语言
- 机器语言通过二进制编码来编写程序
- 执行效率好,编写起来太麻烦
符号语言(汇编)
- 使用符号来代替机器码
- 编写程序时,不需要使用二进制,而是直接编写符号
- 编写完成后,需要将符号转换为机器码,然后再由计算机执行
符号转换为机器码的过程称为汇编
- 将机器码转换为符号的过程,称为反汇编
- 汇编语言一般只适用于某些硬件,兼容性比较差
高级语言
- 高级语言的语法基本和现在英语语法类似,并且和硬件的关系没有那么紧密了
- 也就是说我们通过高级语言开发程序可以在不同的硬件系统中执行
- 并且高级语言学习起来也更加的容易,现在我们知道的语言基本都是高级语言
- C、C++、C#、Java、JavaScript、Python 。。。
编译型语言和解释型语言
计算机只能识别二进制编码(机器码),所以任何的语言在交由计算机执行时必须要先转换为机器码,
也就是像 print(‘hello’) 必需要转换为类似 1010101 这样的机器码
根据转换时机的不同,语言分成了两大类:
编译型语言
- C语言
- 编译型语言,会在代码执行前将代码编译为机器码,然后将机器码交由计算机执行
- a(源码) --编译--> b(编译后的机器码)
- 特点:
执行速度特别快
跨平台性比较差
解释型语言
- Python JS Java
- 解释型语言,不会在执行前对代码进行编译,而是在执行的同时一边执行一边编译
- a(源码)--解释器--> 解释为机器码执行
- 特点:
执行速度比较慢
跨平台性比较好
编译型语言(C/C++)相比解释型语言(Java/Python等)执行更快,性能更好,适合追求处理速度的功能模块,例如实时算费等。
因为执行时编译型语言的执行文件是机器码可以直接执行,解释型语言是中间码文件需要经过解释器解释为机器码再执行。
同样print(“hello world”)一条语句,编译型语言经过的步骤就多一道,性能差距从一开始就决定了。
Git篇
隔离项目和原有Git工程联系
如果你想隔离项目并与原有Git工程的联系,删除.git文件是其中的一种方法,但并不是唯一的方法。删除.git文件将删除Git版本控制的历史记录和配置信息,从而断开与原有Git仓库的连接。
以下是一些可能的方法来隔离项目和原有Git工程的联系:
-
删除
.git文件夹:在项目的根目录中,删除.git文件夹或者通过命令行运行rm -rf .git(请注意,这是一个潜在的危险操作,请谨慎使用)。这将删除Git仓库相关的所有信息,包括历史记录、分支和配置。 -
克隆项目:将项目克隆到一个新的目录中。使用
git clone命令来创建一个项目的独立副本,这个副本将与原有Git工程没有任何联系。然后,你可以删除原始项目与Git仓库的连接。 -
创建新的Git仓库:在项目的根目录中初始化一个新的Git仓库。通过运行
git init命令,可以创建一个全新的Git仓库,并在项目中重新开始版本控制。这将与原有Git工程完全分离。
不论你选择哪种方法,删除.git文件或创建一个全新的Git仓库,都会断开项目与原有Git工程的联系,使其成为独立的实体。
Git冲突的原因通常有以下几种:
代码合并时才会发生冲突,合并时以改动代码处为准覆盖原始代码(文件+行=位置),若改动代码处有多个非原始的改动版本(多方)则冲突。
合法代码合并方式:
1、基于原始版本的代码改动。
2、合并时是覆盖改动前原始版本代码而非其他方版本。(先pull再push)
冲突产生的根本原因是:多方改动后的同一个文件的同一块区域的内容不同。
单一账号改动的同一区域内容不会冲突。
同时修改了同一行代码:当两个人同时修改了同一行代码时,Git无法判断哪个修改是正确的,因此会产生冲突。
修改了同一文件的不同部分:当两个人修改了同一文件的不同部分时,Git会尝试合并这些修改,但如果这些修改之间存在冲突(修改同一行),就会产生冲突。
合并分支时:当合并两个分支时,如果这两个分支都修改了同一文件的同一行,就会产生冲突。
当Git发现冲突时,会在冲突的文件中标记出冲突的部分,并在文件中添加特殊的标记,如"<<<<<<<
HEAD"和"=======“和”>>>>>>>",以表示冲突的部分。此时需要手动解决冲突,即选择哪个修改是正确的,然后将特殊标记删除,保存文件并提交修改。
IDEA篇
IDEA常用操作
IDEA常用快捷键
CTR+ALT+L:快速格式化代码。
CTR+左击:类名/方法名则直接进入对应类和方法。

右上角放大镜搜索,可以设定搜索范围。

IDEA查看并修改编解码方式
IDEA文件编码修改
整体项目编码修改方式
IntelliJ IDEA可以在菜单中的File -> Settings -> Editor -> File Encoding下修改项目文件的编码
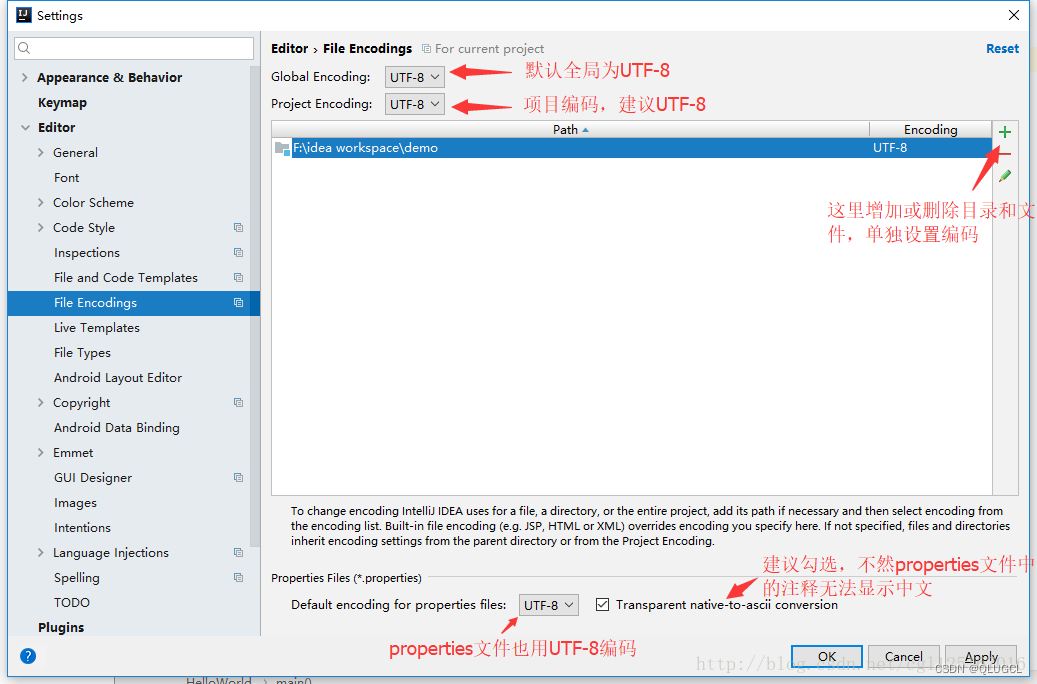
单独文件的编码也可以这样设置
Git可视化操作(提交代码前先pull更新merge最新版本一下再push,保证提交的最终项目是最新)
注意:pull的次数不要太多,防止将别人测试版pull下来,push的时候和正式版产生冲突。
尽量初始化项目pull一次,提交之前pull一次,最后push。
若是产生冲突就需要新开窗口pull下来最新的cv上自己的然后push。
pull后融合,改动的地方以工作区为主,其余地方以远程仓库为主,若本地和远程相差过大则冲突
IDEA的git操作教程
pull下来远程仓库
方法一
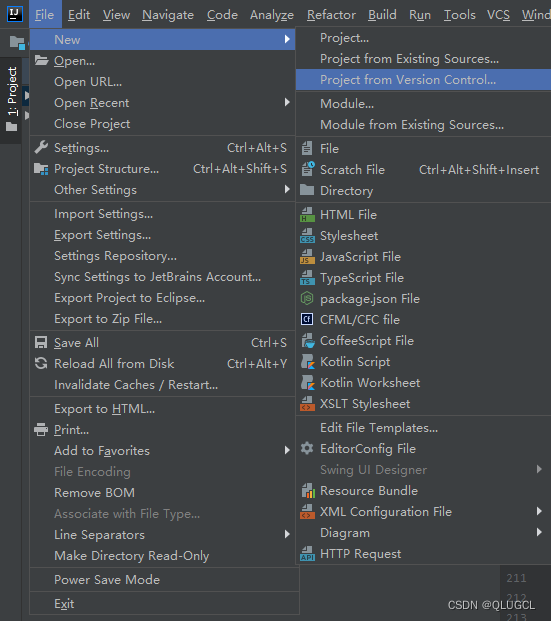
此处若是未配置用户名和密码会弹出输入框

方法二
或者直接用上述办法一直接pull下来对应的远程仓库,这样会直接配置连接上对应的远程仓库。(若未输入用户名密码则会弹出来对应输入框)
配置连接远程数据库
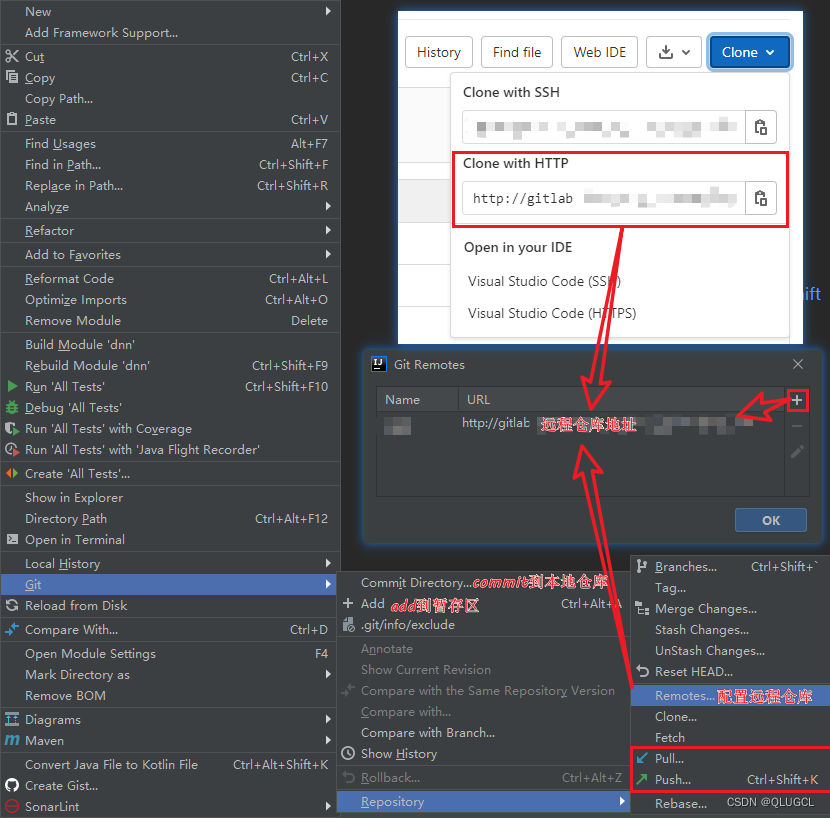
选中项目然后右键
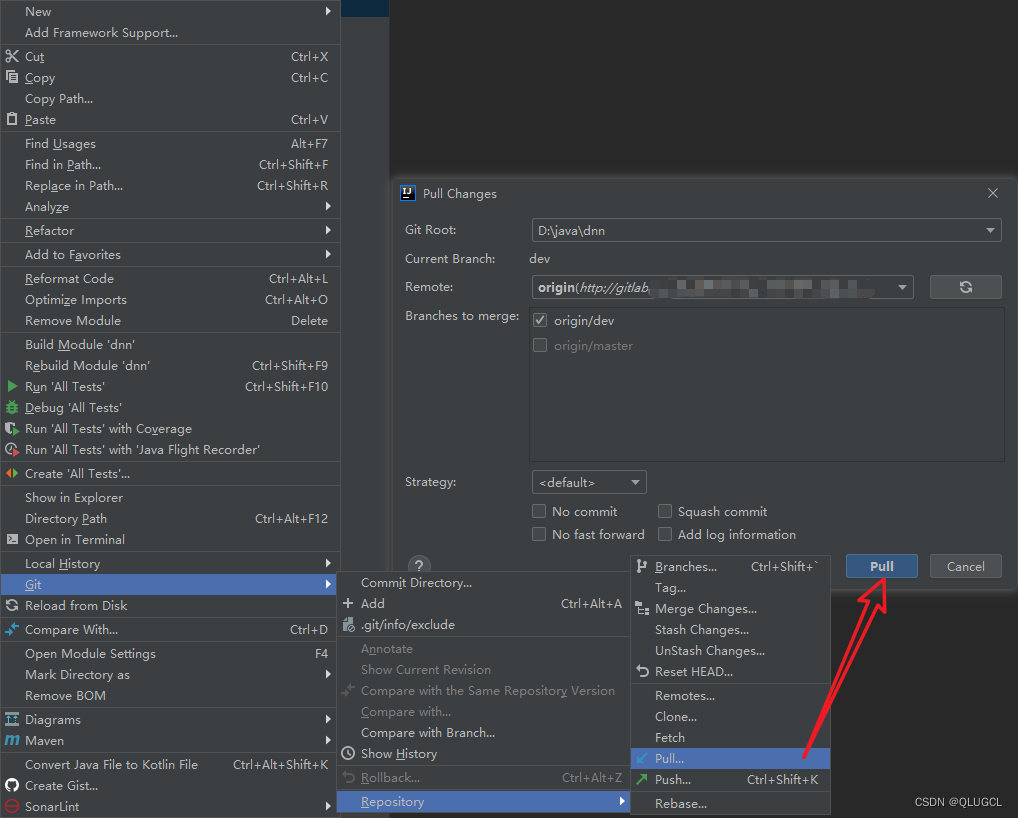
方法三
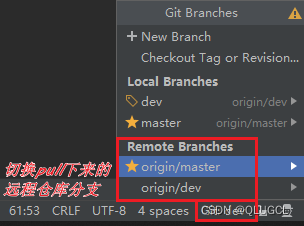
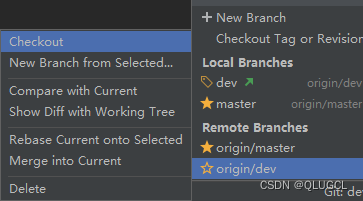
log:分支状态可视化
git log:查看当前(HEAD指向)分支的所有(empty到HEAD)版本

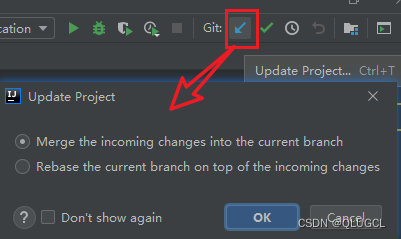
检查一遍
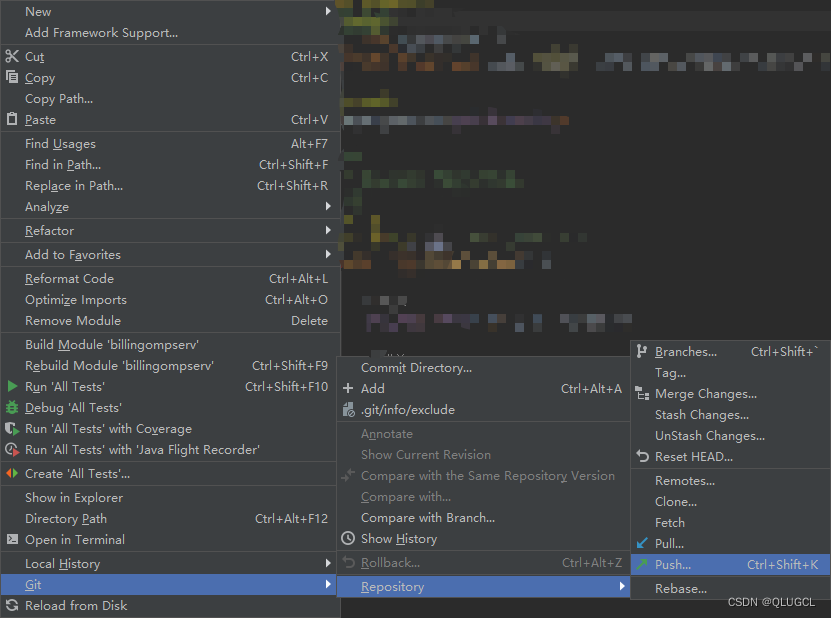
最后push
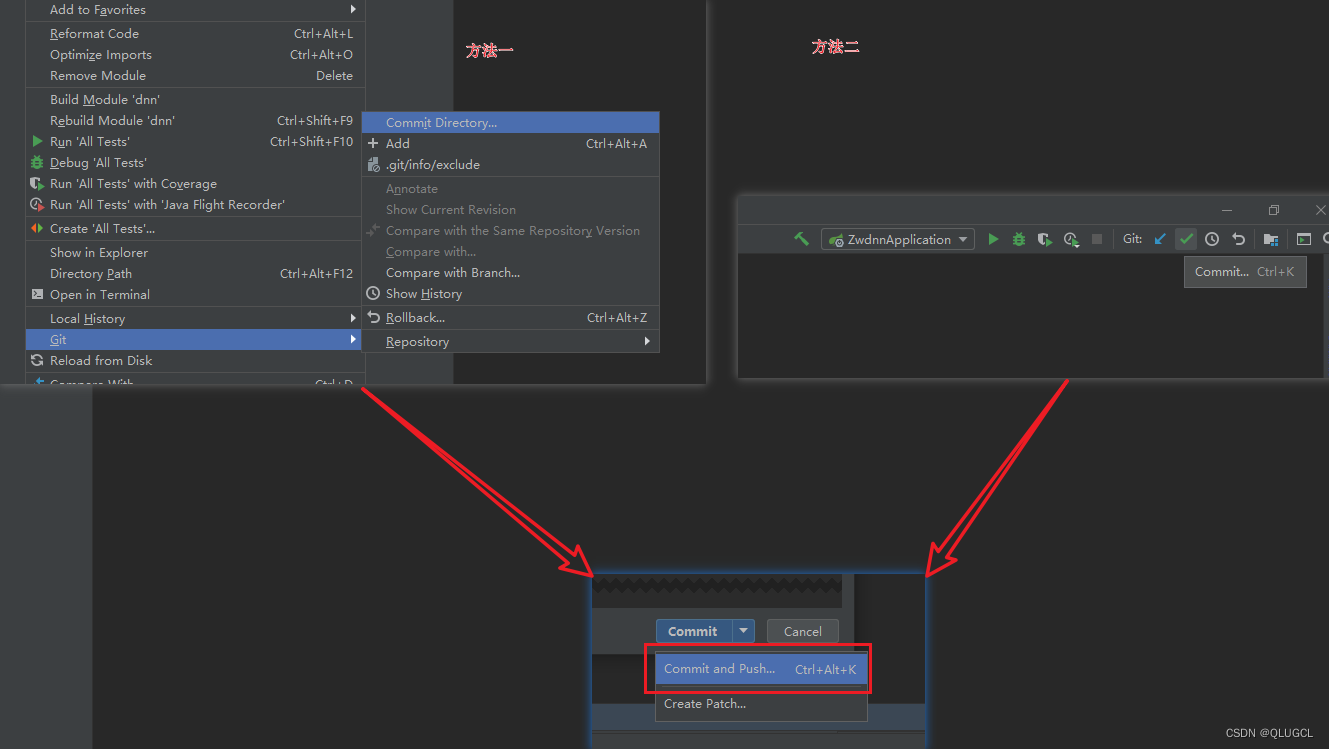
方法三
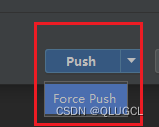
最终若是push出问题直接force push
IDEA中Git冲突的产生及解决方法
IDEA中Git冲突的产生及解决方法
冲突产生的根本原因是:多方改动后的同一个文件的同一块区域的内容不同(行列数定位)。
单一账号改动的同一区域内容不会冲突。
不同账号改动的同一区域同一行会冲突。
Git问题:1.push时候遇到错误,push失败
究其原因是为了保证head指向的代码同步为最新版本。
push失败的情况,是因为我们在push提交代码的时候,远程仓库已经发生变化了(远程head头指针与本地保存的远程head头指针指向不同),换句话说就是在这个期间(上一次拉取代码到本次提交代码),有其他人在我们之前提交了代码到我们想要推送的分支,导致远程仓库代码更新变化了。所以git拒绝了本次push。
Idea如何查看本地自动保存的代码版本
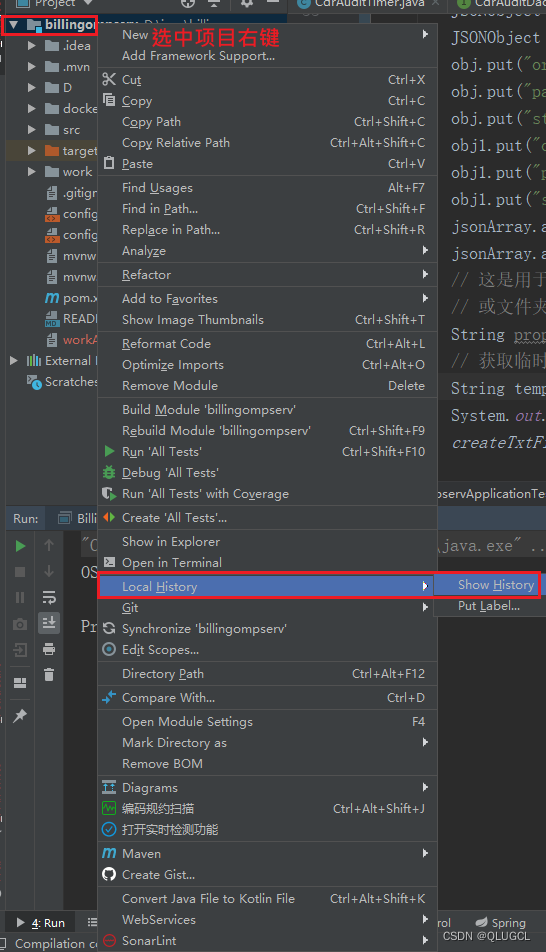
恢复历史数据
VSCode篇
更新远程Git仓库账号信息
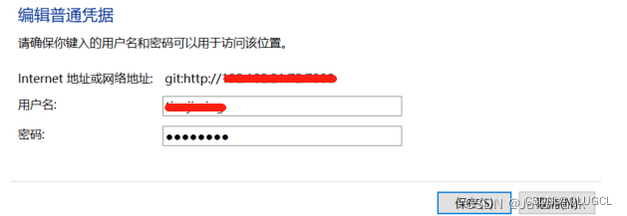
VSCode错误提示:“未能对 git remote 进行身份验证”,请更新git账号信息
注意:
Internet地址或网络地址:远程Git仓库域名或者IP:PORT,不是具体的项目链接。
开发篇
网络资源,信息搜索技巧
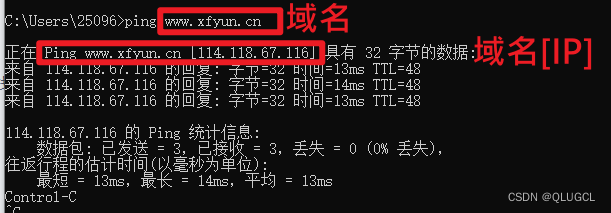
本地查询域名对应IP
CMD看域名的办法:ping 域名
前端原理实战
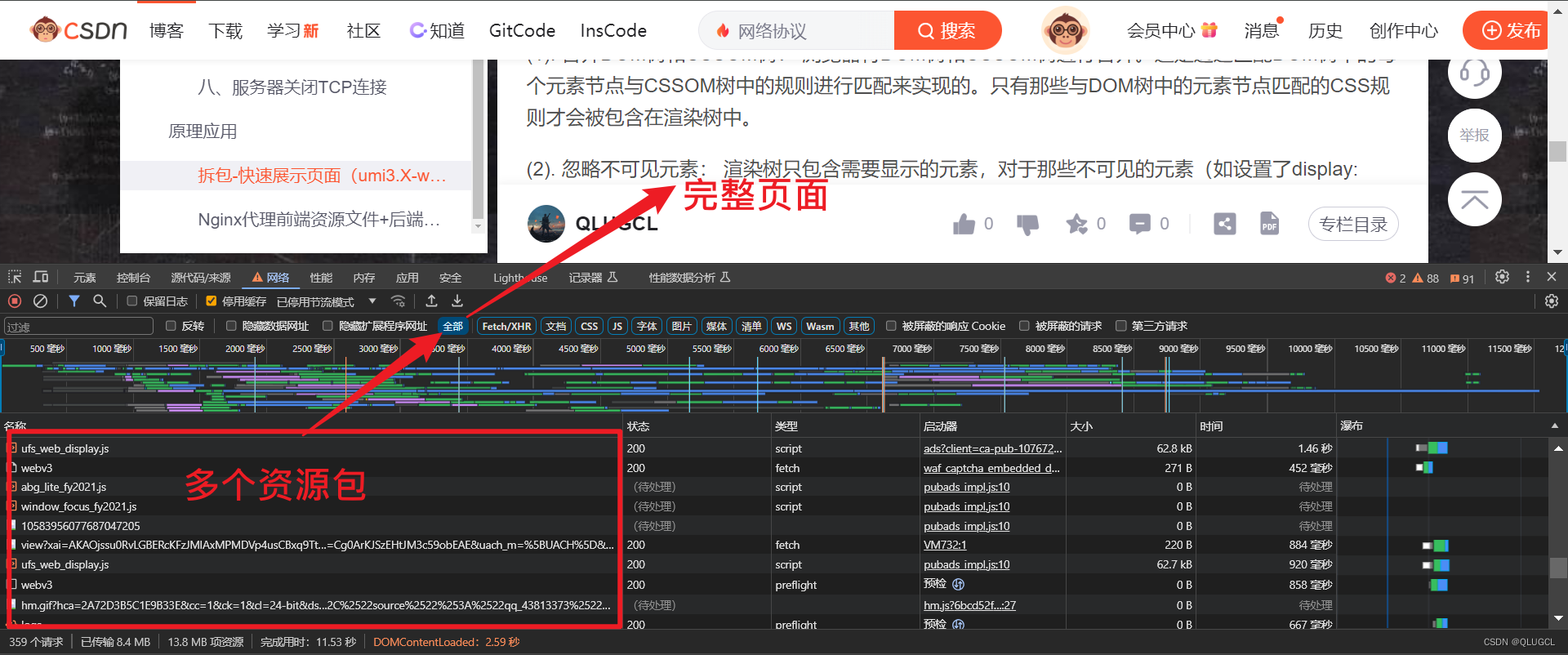
网页请求:静态资源(图片,ccs,js,html等)+(后端)网络url数据请求
F12后台
网络------>全部/所有:(前端服务器)静态资源获取html,jpg,css,js等+(后端服务器)网络url数据请求 。
网络------>Fetch/XHR------>(后端)网络url数据请求。
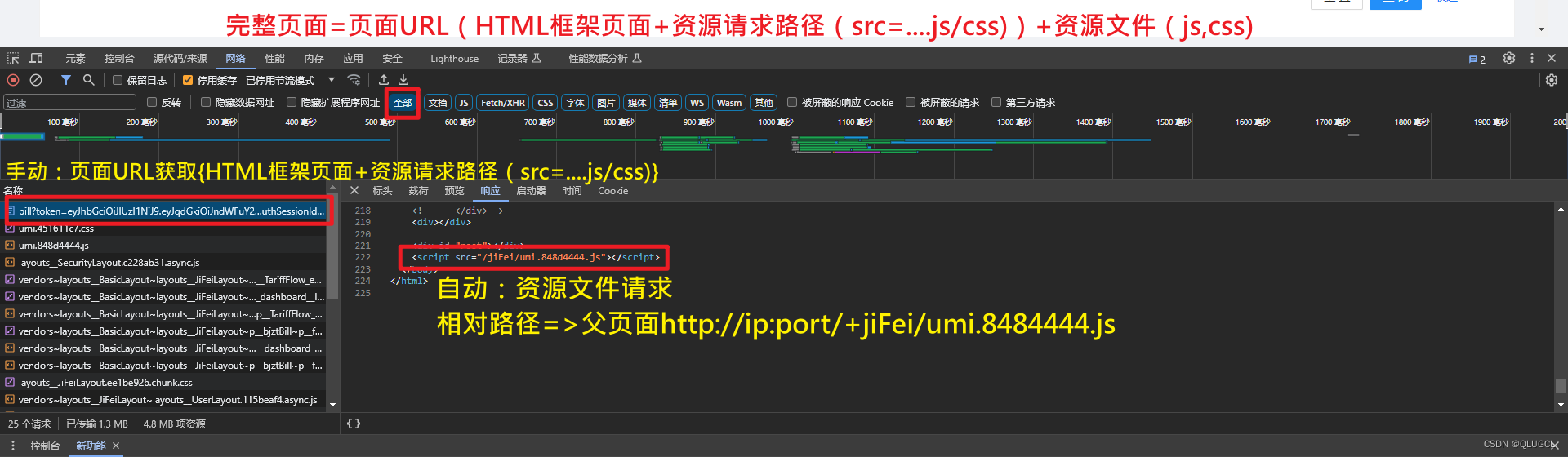
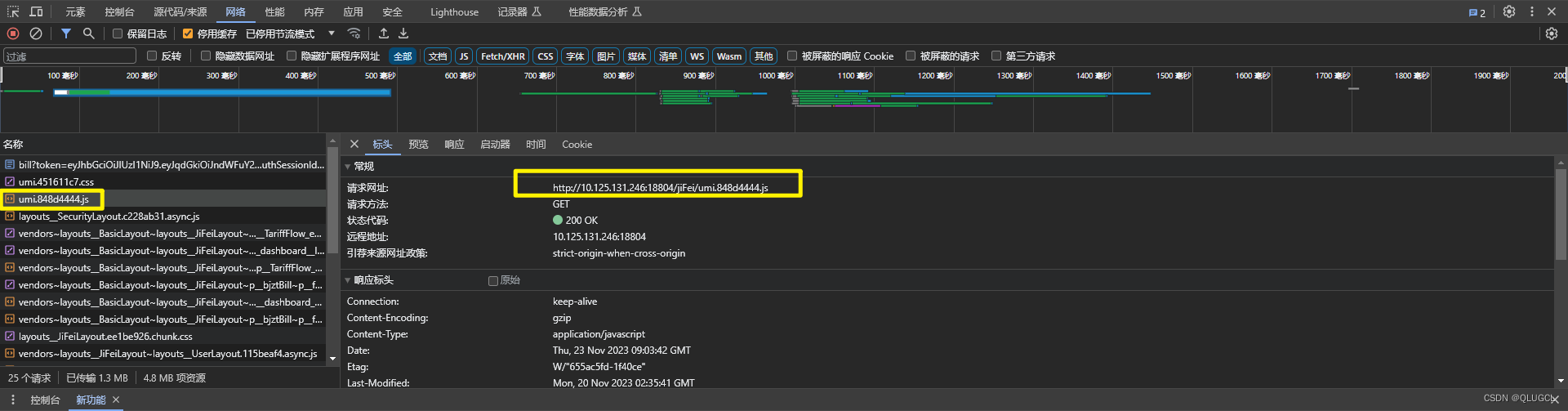
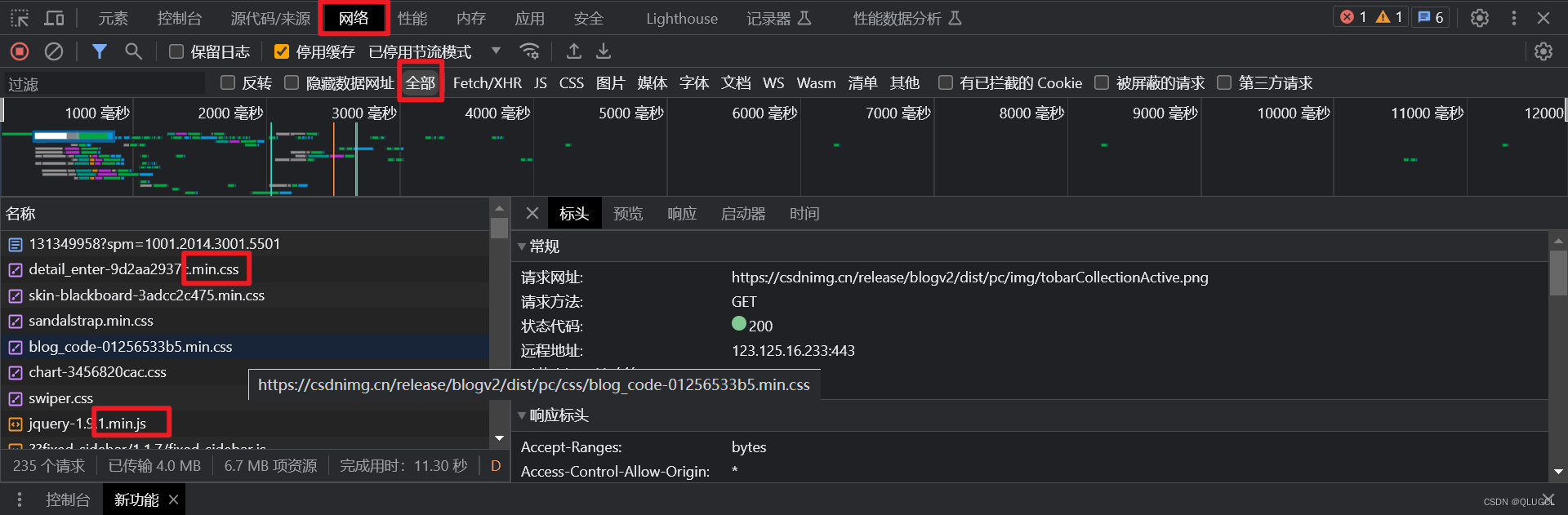
网页前端内容都是从数据包的response的body和源码资源中提取的。
网页的全部信息以及资源都是基于数据包。
数据包中资源如图所示

选中后右键检查元素,直接定位对应源代码。
前端后端交互四要素
- 页面功能名称(中英)。
- request访问url(post、get)和传参(数据格式和个数)。
- response返回结构以及key健含义。
- 后端接口方法名方便前端参考配置请求方法名。
前后端分工-数据处理
前提:
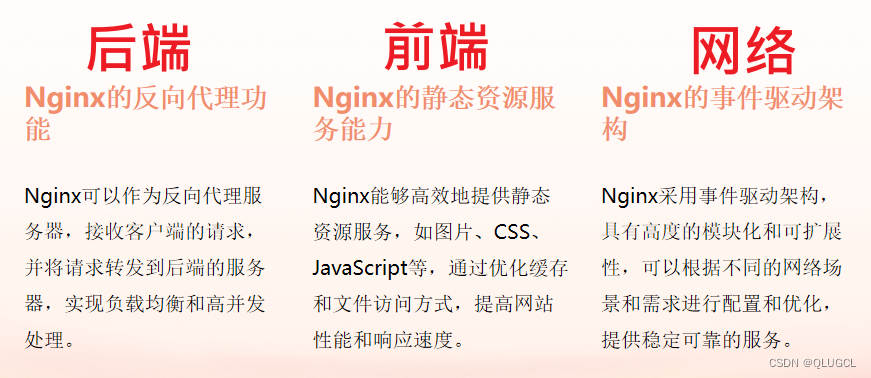
前端容器只跑了一个NG,其余的是静态资源存储在容器内存中,NG代理转发静态资源,最终由用户浏览器加载解析运行页面。
客户体验上,尽可能后端服务器处理数据,前端处理数据最终会导致用户电脑浏览器负载过大,页面加载响应慢,操作交互体验感差。
后端服务器性能肯定优于用户各自电脑浏览器性能,尽可能后端服务器处理数据,减轻用户各自电脑浏览器负载,提升客户体验。
结论:
前端尽量减少数据处理操作,数据处理操作放在后端服务器,加快页面显示,提升客户体验感。
什么是虚拟私有云?什么是VPC?
什么是虚拟私有云?什么是VPC?
阿里云架构参考
阿里云VPC下Kubernetes的网络地址段
网络是怎样连接的?
IPV4的数量局限性导致VPC应运而生。(私网IP=假IP)
在创建VPC选择的地址段。只能从10.0.0.0/8,172.16.0.0/12,192.168.0.0/16三者当中选择一个。
网段是VPC下容器的网段。
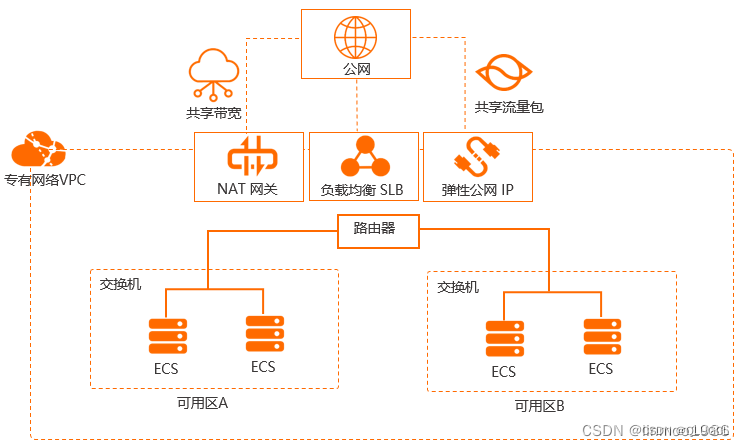
基础知识
简介:
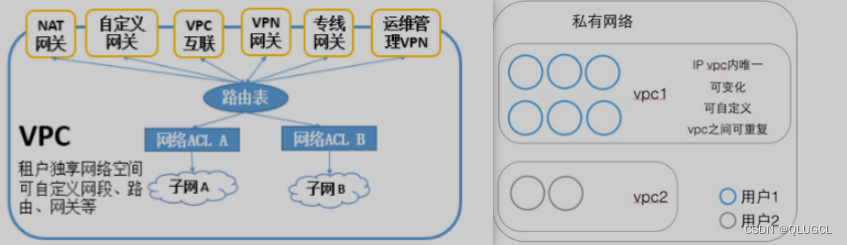
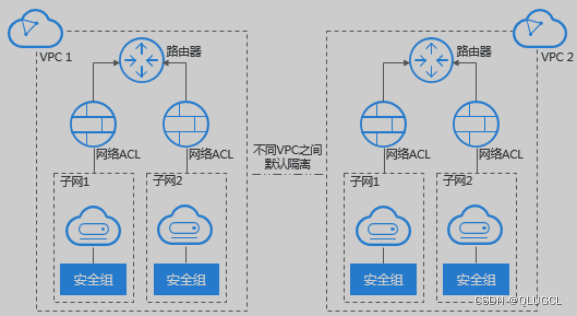
每个虚拟私有云VPC由一个私网网段、路由表和至少一个子网组成。
网络隔离:将大网拆分成一张张VPC小网,VPC小网之间默认是不通信。
网内互通:同一VPC专有网络内的不同交换机之间内网互通
通过隔离来实现测试环境,开发环境,生产环境等业务隔离。
虚拟私有云(Virtual Private Cloud,VPC),为云服务器、云容器、云数据库等云上资源构建隔离、私密的虚拟网络环境。VPC丰富的功能帮助您灵活管理云上网络,包括创建子网、设置安全组和网络ACL、管理路由表、申请弹性公网IP和带宽等。此外,您还可以通过云专线、VPN等服务将VPC与传统的数据中心互联互通,灵活整合资源,构建混合云网络。
产品架构
虚拟私有云VPC产品架构可以分为:VPC的组成、安全、VPC连接。
VPC通过划分网段,交换机再去子集划分很清晰;NAT网关是直接对整个VPC起作用的;
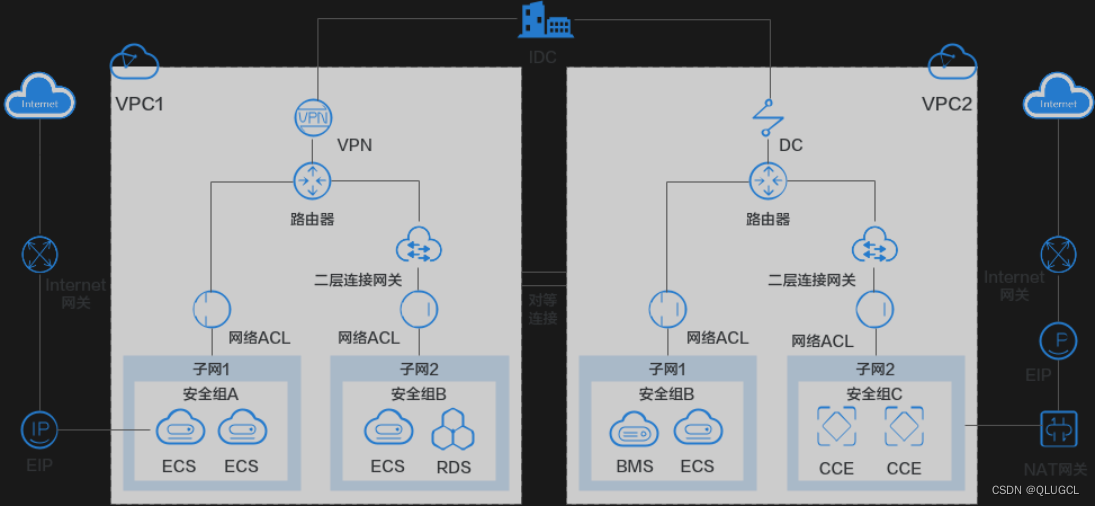

NAT网关(最外层—看门员)
NAT网关是唯一确定公网IP的代理人。
- NAT 网关绑了一个公网 IP。
- NAT 网关就是 VPC 和公网之间的一个转换器。
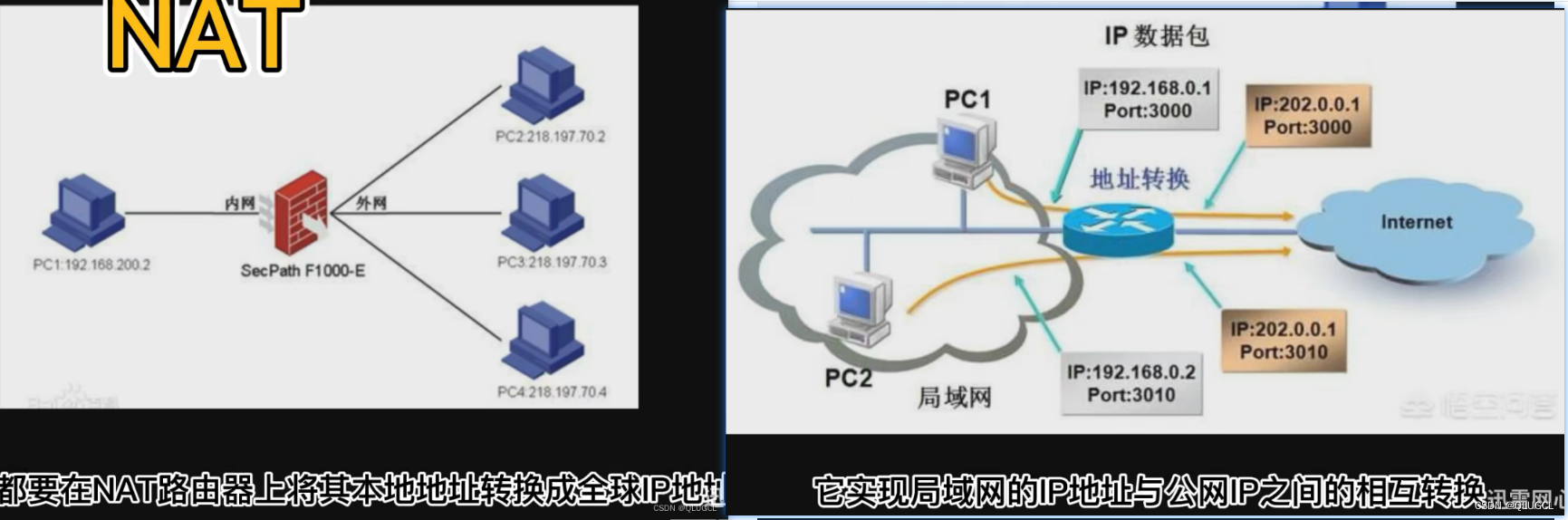
NAT网关位于云网络安全边界(看门员),用于实现云上私有网络(即内部网络)与公网的地址转换,从而允许内部网络中的设备访问公网资源。
NAT网关的工作原理可以便是IP地址转换(私网->公网)。这种地址转换过程需要在NAT网关上进行配置,还需要建立端口映射关系。
NAT网关是物通博联推出的一款物联网设备,它可以将私有网络中的IP地址转换为公共网络中的IP地址,从而实现内部网络与外部网络的通信。它还负责处理各种网络协议,确保数据在不同网络之间的传输能够顺利进行。NAT网关通常被部署在工厂设备上层接口上,以便对内部网络进行地址转换和数据转发。
工厂通常拥有多个局域网络,通过NAT网关可以将这些局域网络与互联网连接起来,实现内部设备与外部网络的通信。同时,NAT网关还可以防止外部网络的攻击,提高企业的网络安全。
每一个小的局域网都会使用一个网段的私网地址,在与外界连接时再通过NAT网关变成公网地址。
NAT(网络地址转换): 私有网络可以使用网络地址转换(NAT)来映射多个私有 IP 地址到单个公共 IP 地址,以便内部网络中的多个设备可以共享一个公共 IP 地址。
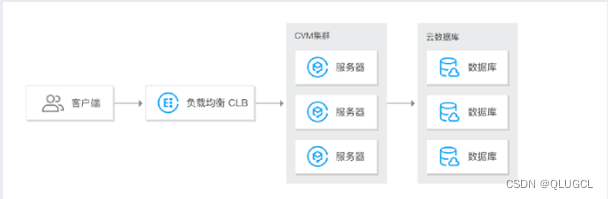
CLB负载均衡
负载均衡(CLB)是对多台云服务器和裸金属服务器进行流量分发的服务。通过流量分发扩展应用系统对外的服务能力,消除单点故障提升应用系统的可用性。
传统型负载均衡CLB(Classic Load Balancer)是将访问流量根据转发策略分发到后端多台云服务器(ECS实例)的流量分发控制服务。CLB扩展了应用的服务能力,增强了应用的可用性。
CLB云负载均衡器(Cloud Load Balance,简称CLB)将来自VPC外部的访问流量自动分发到VPC内的云资源实例,扩展用户应用系统对外的服务能力,实现更高水平的应用容错
CLB负载均衡的IP:PORT可能是NAT的公网IP也可能是代理后的私网假IP。
CLB由以下三个部分组成:
- CLB实例 (Instances)
一个CLB实例是一个运行的负载均衡服务,用来接收流量并将其分配给后端服务器。要使用负载均衡服务,您必须创建一个CLB实例,并至少添加一个监听和两台ECS实例。 - 监听 (Listeners) 监听用来检查客户端请求并将请求转发给后端服务器。监听也会对后端服务器进行健康检查。
- 后端服务器(Backend Servers)
后端服务器是一组接收前端请求的ECS实例。您可以单独添加ECS实例到后端服务器池,也可以通过虚拟服务器组或主备服务器组来批量添加和管理。
打网------不同VPC下如何网络联通
VPC之间的网络联通实践
VPC有多种连接方案,以满足用户不同场景下的诉求。
- 通过VPC对等连接功能,实现同一区域内不同VPC下的私网IP互通。
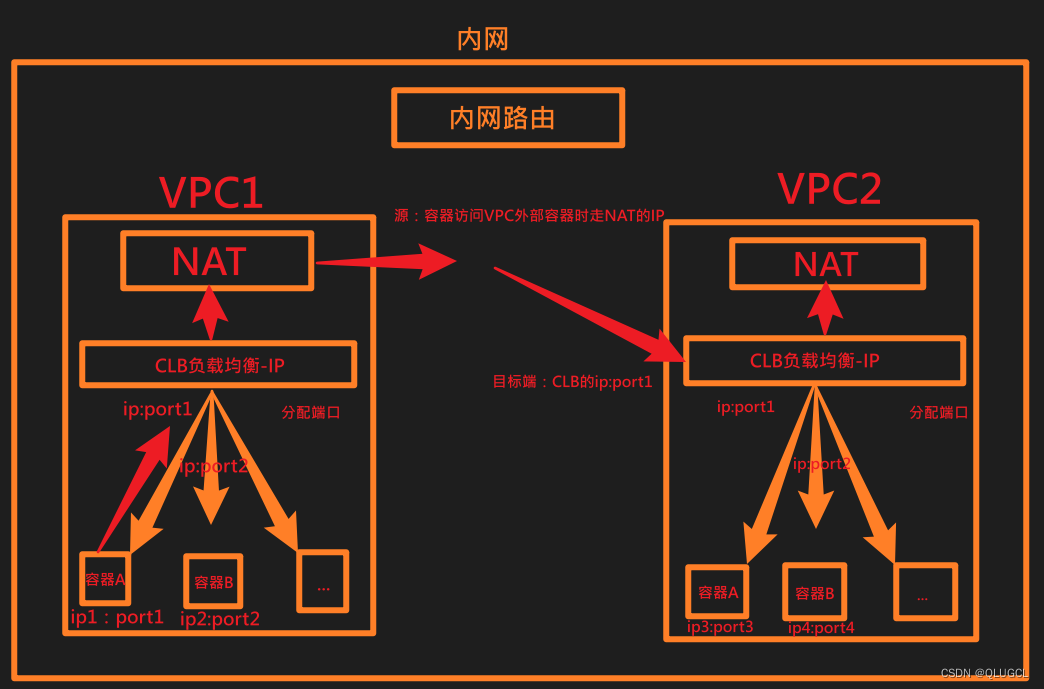
- 通过EIP或NAT网关,使得VPC内的云服务器可以与公网Internet互通。
此种方法只要打通源NAT网关和目标端的网络则NAT网关下的所有容器都可以访问该目标端。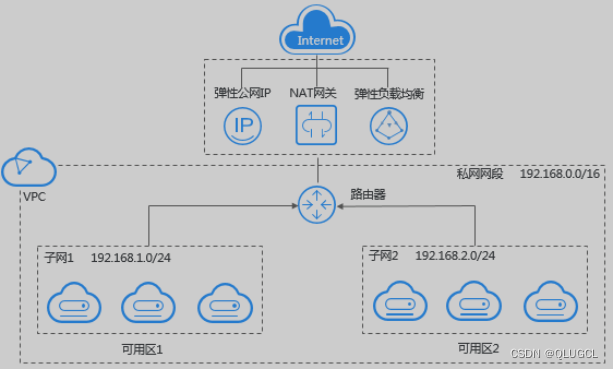
打网信息:
VPC对外暴露NAT的IP(源发请求)和CLB的IP:PORTn(端接请求)
1、源私网NAT网关IP.
2、目标端私网CLB分配给容器IP:PORTn(对外暴露).
打网注意事项:
1、打请求源NAT的IP到响应端CLB的IP:PORTn(对外暴露).
2、打网时只打响应端CLB的IP:PORTn,因此只有请求源NAT的IP单侧发出请求有效(测网也只能从源端测),反之NAT无port无法作为响应端.
3、打通的是源私网的NAT网关IP到目标端CLB分配给私网容器IP:PORTn(对外暴露)的网,所以源NAT网关IP下的容器都可以访问目标端容器.
网络连接的建立:在两台电脑之间建立网络连接时,通常涉及到客户端和服务器的概念。电脑A作为客户端,可能需要知道电脑B的IP地址和端口号来建立连接。而电脑B作为服务器,只需要监听特定的端口,等待客户端的连接请求。在这种情况下,电脑A不需要提供自己的端口号,因为它是主动发起连接的一方。
如图示例:VPC1下容器A发送请求到VPC2下容器A的过程。
容器A(ip1:port1)->CLB负载均衡(ip:port1)->VPC1:NAT(IP)->VPC2:CLB负载均衡(ip:port1)->容器A(ip3:port3)
 - 通过虚拟专用网络VPN、云连接、云专线及VPC二层连接网关功能将VPC和您的数据中心连通
- 通过虚拟专用网络VPN、云连接、云专线及VPC二层连接网关功能将VPC和您的数据中心连通
Nginx部署及应用原理
前端必备的nginx知识点
NG原理:资源访问就靠NG管理、限制等
必须主动触发Nginx监听的端口才能实现Nginx代理
IP:PORT-IP定位Nginx所在容器,PORT触发Nginx监听代理。
URL就是网络资源的地址,只有知道URL才能访问到网络资源,就像知道家庭住址才能找到对应人一样。
地址代理,资源寻址。
底层逻辑:根据最终NG代理的URL地址寻找资源,地址信息(IP:PORT,URL等)。
注意:request请求经过nginx代理则response响应也会经过nginx传输。
例如:添加下载1G的文件功能时需要考虑NG所在容器内存和后端服务器内存以及并发量。
后端服务器生成1G文件—>NG(传输转发1G数据)---->用户浏览器
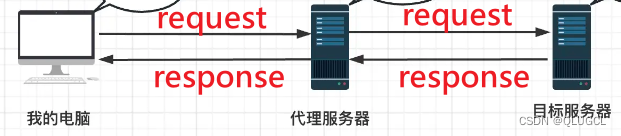
Nginx代理前端页面和后端请求区别
- NG代理前端页面URL,一个页面涉及多个http资源请求(html,js,css等)需要考虑到全部http请求的代理映射。
- NG代理后端请求只有一次http请求只需要代理好IP:PORT即可。
前端页面:
一个页面需要多个http请求获取多个资源包(html,css,js等)整合解析为一个完整的页面。
Nginx配置与触发响应
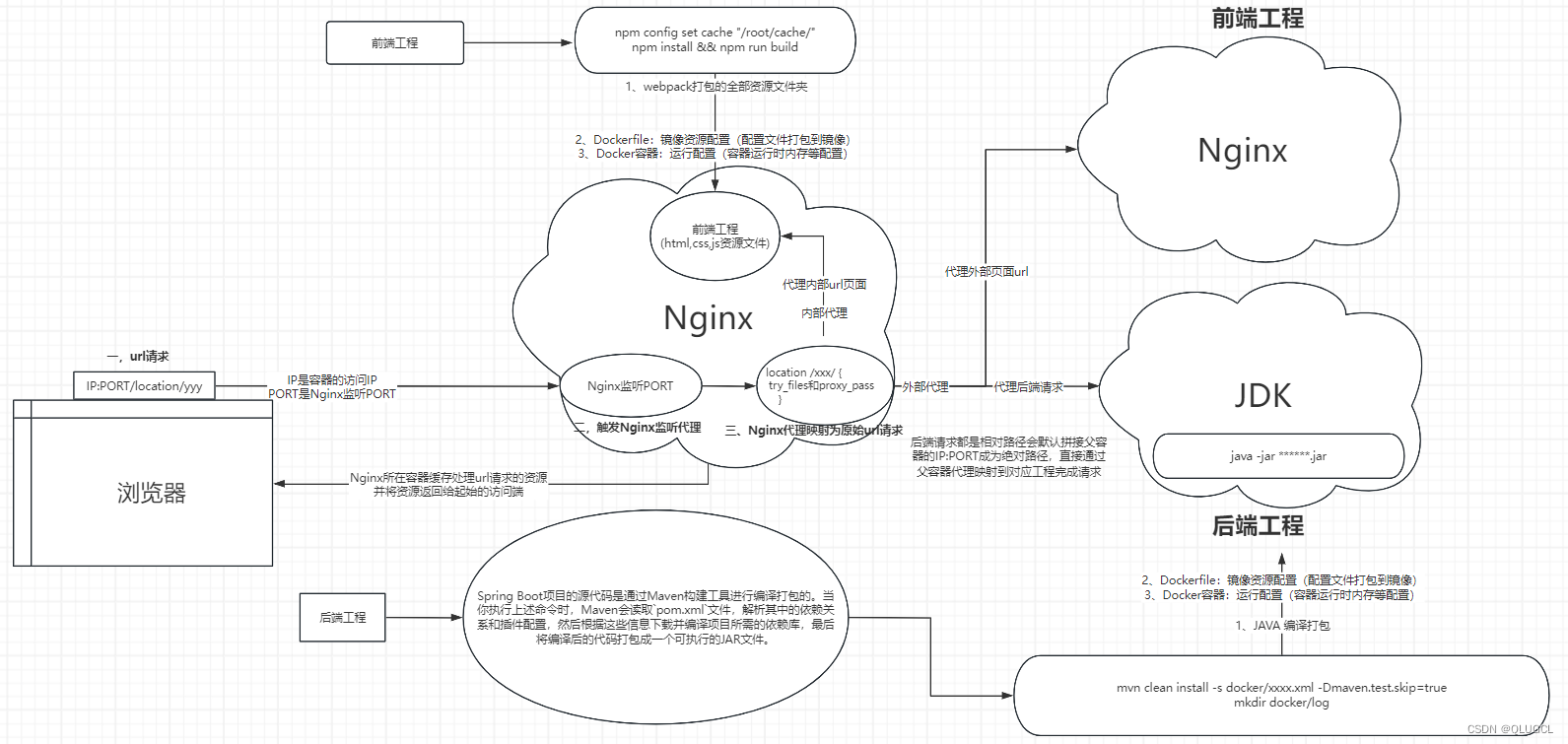
- 容器中的前端工程和Nginx打包部署在一起,内外所有URL请求都是触发后从Nginx代理发出。
- 容器中会将访问端口设置为Nginx的监听端口这样就能实现Nginx代理容器所有请求(自身静态资源页面请求和后端数据请求等)。
- 本地中的前端工程都是部署在Node上面
Nginx代理前端资源文件+后端数据请求路径
底层逻辑:根据最终NG代理的地址寻找资源,地址信息(IP:PORT,URL等)。
外部IP:PORT先根据IP找到容器然后触发Nginx监听的端口后,会进行location映射代理到对应的url路径访问前端资源或后端数据请求。
Nginx的工作原理就是被动被暴露的IP:PORT触发监听端口后代理到对应的URL请求资源(前端或后端)。
容器中会将访问端口设置为Nginx的监听端口这样就能实现Nginx代理容器所有请求(自身静态资源页面请求和后端数据请求等)。
必须主动触发Nginx监听的端口才能实现Nginx代理
IP:PORT-IP定位Nginx所在容器,PORT触发Nginx监听代理。
IP:定位容器
PORT:触发Nginx监听端口
前端运行环境区别
本地都是编译打包跑在Node上,容器是npm run build编译打包资源放到内存由Nginx代理Url请求前端静态资源。
前端容器只跑了一个NG,其余的是静态资源存储在容器内存中,NG代理转发静态资源,最终由用户浏览器加载解析运行页面。
前端工程先npm install下载package.json中依赖和命令脚本(npm start等命令)为node_modules再将其中的依赖和页面等npm run build(webpack)编译打包为资源文件夹.
npm run build=dist包=node_modules依赖+src,config等工程文件=编译打包为一个一个资源文件包(可通过analyze查看每个包的原始路径就能看到有的根路径是node_modules有的是src)
Nginx并不负责编译运行代码只负责代理url请求原生代码页面资源,最终浏览器编译运行原生代码页面,出错会在浏览器控制台console报出来。
浏览器运行打包好的umi.js等资源文件实现路由映射等功能。
user root;
...
http {
...
server {
listen 80 default_server; # 默认在80端口启动nginx服务
listen [::]:80 default_server;
server_name _; # 绑定的域名
root /usr/share/nginx/html; # 根目录,会加载这个目录下的html文件
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf; # 可以引入其他配置文件
location / { # 访问服务器跟路径代理文件。
}
error_page 404 /404.html; # 访问的时候路径404
location = /40x.html { # 404时访问的html
}
error_page 500 502 503 504 /50x.html; # 服务器内部错误
location = /50x.html { # 5xx时访问的html
}
}
}
Nginx转发流程(监听端口和启动端口)
项目访问Nginx工程的IP:PORT/path才会实现路径/path/映射
IP是Nginx搭载的工程IP,PORT是Nginx监听端口。
映射路径的编写方法:
proxy_pass :末尾带/不拼location,不带/拼location
假设下面四种情况分别用 http://47.168.10.1:8001/proxy/test.html 进行访问
location /proxy/ {
proxy_pass http://127.0.0.1:8001/;
}
代理到URL:http://127.0.0.1:8001/test.html
location /proxy/ {
proxy_pass http://127.0.0.1:8001;
}
代理到URL:http://127.0.0.1:8001/proxy/test.html
location /proxy/ {
proxy_pass http://127.0.0.1:8001/aaa/;
}
代理到URL:http://127.0.0.1:8001/aaa/test.html
location /proxy/ {
proxy_pass http://127.0.0.1:8001/aaa;
}
代理到URL:http://127.0.0.1:8001/aaatest.html
———————————————— 版权声明:本文为CSDN博主「白小白的小白」的原创文章,遵循CC 4.0
BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42874635/article/details/115702184
Nginx跨域配置
在 Nginx 中实现跨域配置可以通过设置HTTP头部来实现。以下是一种常见的配置方式,可以允许所有域名的访问,适用于开发环境和测试环境。生产环境中应根据实际情况进行更严格的配置。
假设你的应用运行在 http://example.com,而 API 服务运行在 http://api.example.com,并且你希望应用可以通过 AJAX 调用 API,可以按照以下步骤进行配置。
-
在 Nginx 的配置文件中找到相关的
server块,一般位于/etc/nginx/nginx.conf或/etc/nginx/conf.d/default.conf。 -
在
server块中添加以下配置,启用跨域支持:
server {
listen 80;
server_name example.com;
location / {
# 允许所有来源的请求
add_header 'Access-Control-Allow-Origin' '*';
# 允许的请求方法
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE';
# 允许的请求头
add_header 'Access-Control-Allow-Headers' 'Origin, X-Requested-With, Content-Type, Accept, Authorization';
# 允许携带身份验证信息
add_header 'Access-Control-Allow-Credentials' 'true';
# 如果是 OPTIONS 请求(预检请求),直接返回 200
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE';
add_header 'Access-Control-Allow-Headers' 'Origin, X-Requested-With, Content-Type, Accept, Authorization';
add_header 'Access-Control-Allow-Credentials' 'true';
return 200;
}
# ... 其他处理请求的配置
}
# ... 其他配置
}
- 保存配置文件并重启 Nginx 服务,使配置生效:
sudo service nginx restart
完成以上配置后,你的应用就可以通过 AJAX 调用 http://api.example.com 上的 API 服务了,并且可以允许来自任何来源的请求。请注意,这是一种简单的开发环境配置,生产环境中应根据实际需求做出更严格的配置,比如只允许特定的域名访问。
Nginx匹配规则
在Nginx中,location块的匹配优先级是按照以下规则进行的:
-
首先,Nginx会优先匹配最具体的
location块。具体意味着其定义更具体的匹配条件,通常是使用正则表达式或前缀路径更长的块。如果一个请求URI同时匹配多个location块,Nginx将选择最具体的块进行处理。 -
如果多个
location块具有相同的具体性,那么匹配顺序将由配置文件中出现的顺序决定。配置文件中出现得越早的location块将具有更高的优先级,将会被优先匹配并执行。
重合度越高的location块并不一定会执行,实际执行的是最具体的、首先匹配的location块。因此,虽然某些请求可能同时匹配多个location块,但只会执行最具体且最先匹配的那个块。
举例说明:
假设有以下两个location块的Nginx配置:
location / {
root /usr/share/nginx/html/;
try_files $uri $uri/ /index.html;
}
location ~ .*\.(gif|jpg|jpeg|png|js|css)$ {
alias /usr/share/nginx/static/;
}
对于请求http://example.com/image.jpg,它同时匹配到两个location块,但是由于第二个块更具体(使用正则表达式匹配特定文件后缀),Nginx会选择执行第二个块的配置,而不会执行第一个块的配置。因为在这个例子中,第二个块更具体,所以它优先匹配并执行。
nginx配置https操作指引
HTTPS 的加密过程及其工作原理
nginx–HTTPS服务

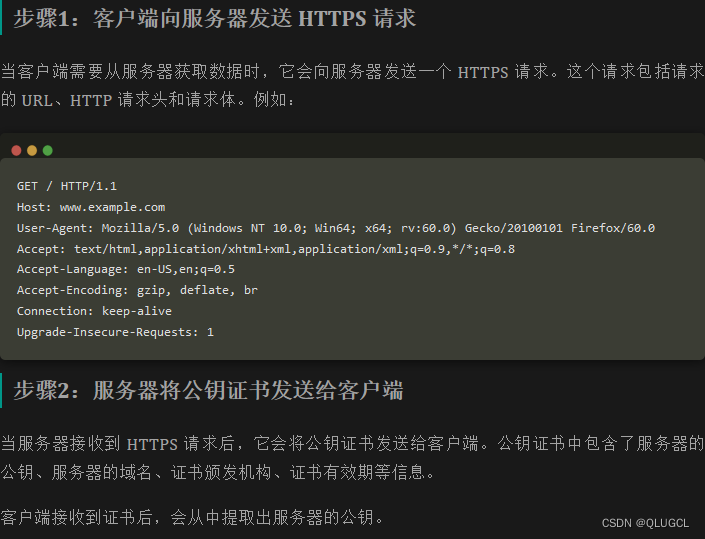
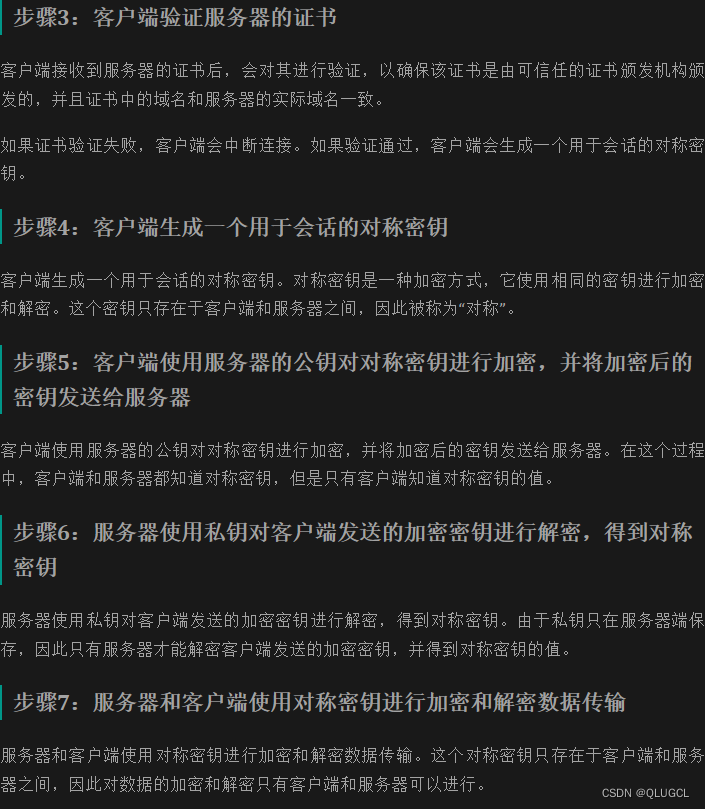
HTTPS 的加密过程可以分为以下步骤:
- 浏览器客户端向服务器发送 HTTPS 请求。
- 服务器将公钥证书发送给客户端。
- 客户端验证服务器的证书。
- 如果验证通过,客户端生成一个用于会话的对称密钥。
- 客户端使用服务器的公钥对对称密钥进行加密,并将加密后的密钥发送给服务器。
- 服务器使用私钥对客户端发送的加密密钥进行解密,得到对称密钥。
- 服务器和客户端使用对称密钥进行加密和解密数据传输。
https简介: https 默认443 ssl证书
超文本传输安全协议,HTTP使用80端口通讯,而HTTPS占用443端口巡讯。但利用SSL/TLS来加密数据包。
HTTPS开发的主要目的,是提供对网络服务器的身份认证,保护交换数据的隐私与完整性。这个协议由网景公司(Netscape)在1994年首次提出,随后扩展到互联网上。
HTTPS 加密的过程中,客户端和服务器之间建立了一个安全的通信通道。在这个通道中,数据被加密传输,确保了数据在传输过程中的机密性、完整性和真实性。
注意:监听https://ip:port/url需要证书,但是监听http代理转发为https://ip:port/url不需要证书
- Nginx监听http协议请求并反向代理转发为https无需证书,可以直接代理。
location /xxx/ {
proxy_pass https://IP:PORT/;
proxy_http_version 1.1;
}
- Nginx默认只监听http协议请求并反向代理,如果需要监听https请求则需要配置证书。
HTTPS代理配置
server {
listen 443 ssl; # 监听443端口,启用SSL
ssl_certificate /path/to/your/certificate.crt; # 你的SSL证书路径
ssl_certificate_key /path/to/your/private.key; # 你的SSL私钥路径
location /xxx/ {
proxy_pass https://IP:PORT/;
proxy_http_version 1.1;
}
}
Docker容器
容器网络测试
容器中curl模拟发出请求可以直接在容器测试目标端对应请求的路径和资源,查看网络是否有问题。
容器的域名映射
- Ng代理域名时需要在容器或host文件配置域名对应的IP映射,否则无法使用域名。
- 只有在docker容器中配上域名和IP的映射关系才能在代码中使用域名来实现功能(ng代理域名或者后端域名跳转发请求)
容器间信息交互
所有容器,前后端,组件等信息交互都是网络传输数据实现。
网络知识很重要。
Spring全家桶
SpringBoot单例模式与前端异步请求
前端Ajax异步或多并发请求,后端多线程响应。
单例模式和多例模式最大的逻辑区别就是对于变量的是否共享、相互干涉问题,单例模式但是多线程处理。
Spring Boot 的单例模式可以同时处理多个 URL 请求。在 Spring Boot 中,控制器(Controller)是单例模式的,但是可以同时处理多个请求。这是因为 Spring Boot 使用多线程处理请求,每个请求都会创建一个新的线程。这些线程是相互独立的,它们可以同时运行不同的控制器方法,从而处理多个请求。
在处理多个 URL 请求时,控制器中的方法应该是线程安全的,不应该共用类成员变量或共享状态。如果需要使用共享状态,可以使用线程安全的方式来实现,例如使用 Java 并发包中的锁或原子变量。
由于单例模式确保了共享实例,这有助于减少线程安全的问题,并提供了更高效的资源利用。
总之,Spring Boot 的单例模式可以同时处理多个 URL 请求,但需要注意线程安全和并发访问的问题。
在Spring框架中,依赖注入(Dependency Injection, DI)默认情况下是采用单例(Singleton)模式的。这意味着在Spring容器中,每个Bean实例只会创建一个,并且这个实例会被所有注入该Bean的地方共享。
Spring容器管理Bean的生命周期,并确保每次请求时都返回同一个实例,除非你明确指定了其他的行为。例如,你可以通过设置Bean的scope属性为prototype来表示每个请求都应该创建一个新的实例,这就是原型(Prototype)模式。
在Spring的典型应用中,大多数业务层(Service)和数据访问层(DAO)的Bean都是单例模式,因为它们通常不依赖于用户会话或其他上下文,而且创建它们的成本相对较高。在Spring Boot框架中,默认情况下,Controller层的Bean也是采用单例(Singleton)模式的。这意味着Spring Boot容器中每个Controller实例只会创建一个,并且这个实例会被所有注入该Controller的地方共享。
总结一下,Spring框架的依赖注入默认是单例模式,但可以通过配置来改变特定Bean的行为,使其成为原型模式或其他模式。
















 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









