







快排思想
快排算法是基于分治策略的排序算法,其基本思想是,对于输入的数组a[low, high],按以下三个步骤进行排序。
(1)分解:以a[p]为基准将a[low: high]划分为三段a[low:p-1],a[p]和a[p+1:high],使得a[low:p-1]中任何一个元素小于等于a[p], 而a[p+1: high]中任何一个元素大于等于a[p]。
(2)递归求解:通过递归调用快速排序算法分别对a[low:p-1]和a[p+1:high]进行排序。
(3)合并:由于对a[low:p-1]和a[p+1:high]的排序是就地进行的,所以在a[low:p-1]和a[p+1:high]都已排好序后,不需要执行任何计算,a[low:high]就已经排好序了。
快排基准的选择
快速排序的运行时间与划分是否对称有关。最坏情况下,每次划分过程产生两个区域分别包含n-1个元素和1个元素,其时间复杂度会达到O(n^2)。在最好的情况下,每次划分所取的基准都恰好是中值,即每次划分都产生两个大小为n/2的区域。此时,快排的时间复杂度为O(nlogn)。所以基准的选择对快排而言至关重要。快排中基准的选择方式有以下三种。
(1)固定基准
以下Partition()函数对数组进行划分时,以元素x = a[low]作为划分的基准。
-
template <
class T>
-
int Partition(T a[],
int low,
int high)
-
{
-
int i = low, j = high+
1;
-
T x = a[low];
-
while(
true)
-
{
-
while(a[++i] < x && i < high);
-
while(a[--j] > x);
-
if(i >= j)
break;
-
Swap(a[i], a[j]);
-
}
-
a[low] = a[j];
-
a[j] = x;
-
return j;
-
}
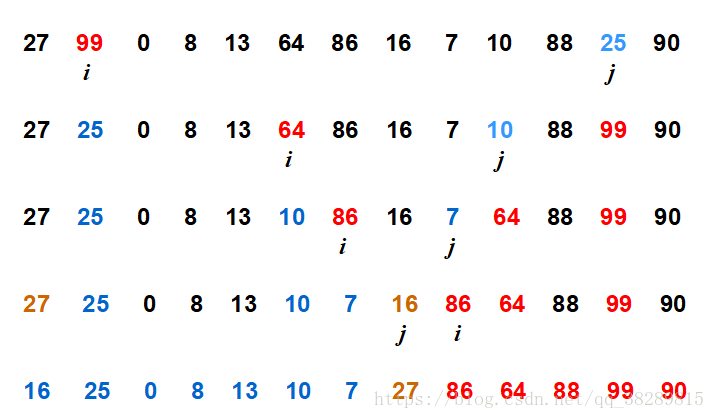
快排过程一趟:
快排动图(网上找的动图,虽然基准选的不一样,但排序过程还是一样的):

如果数组元素是随机的,划分过程不产生极端情况,那么程序的运行时间不会有太大的波动。如果数组元素已经基本有序时,此时的划分就容易产生最坏的情况,即快速排序变成冒泡排序,时间复杂度为O(n^2)。
例如:序列[1][2][3][5][4][6]以固定基准进行快排时。
第一趟:[1][2][3][5][4][6]
第二趟:[1][2][3][5][4][6]
第三趟:[1][2][3][5][4][6]
第四趟:[1][2][3][4][5][6]
程序中要用的函数:(1)C++可以使用以下方法产生随机数,而单纯的使用rand()%M产生的是伪随机数。
-
#define M 100
-
srand(
time(
0));
-
for(
int i =
0; i < M; i++)
-
a[i] =
rand()%(M);
(2)方法一:获得程序片段运行的时间:
-
clock_t start_time = clock();
-
//程序代码片段
-
clock_t end_time = clock();
-
cout<<
"Runing time is:"<<
static_cast<
double>(end_time-start_time)/CLOCKS_PER_SEC*
1000<<
"ms"<<
endl;
方法二:获得程序片段运行的时间:
-
#include<sys/time.h>
-
int gettimeofday(
struct timeval*tv,
struct timezone *tz )
-
struct timeval
-
{
-
long tv_sec;
/*秒*/
-
long tv_usec;
/*微妙*/
-
};
-
struct timezone
-
{
-
int tz_minuteswest;
-
/*和greenwich时间差*/
-
int tz_dsttime;
-
};
例如:
-
int main()
-
{
-
float Time=
0;
-
struct timeval start;
-
struct timeval end;
-
-
gettimeofday(&start,
NULL);
//gettimeofday(&start,&tz);结果一样
-
//程序片段
-
gettimeofday(&end,
NULL);
-
-
Time=(end.tv_sec-start.tv_sec)*
1000000+(end.tv_usec-start.tv_usec);
//微秒
-
cout << Time <<
endl;
-
return
0;
-
}
完整代码如下:
-
#include <iostream>
-
#include <time.h>
-
#include <stdlib.h>
-
#include <cstdlib>
-
#define M 1000000
-
using
namespace
std;
-
-
template <
class T>
-
void Print(T a[], int n, int m)
-
{
-
for(
int i = n; i < m; i++)
-
{
-
cout <<
"[" << a[i] <<
"]";
-
}
-
cout <<
endl;
-
}
-
-
template <
class T>
-
void Swap(T &a, T &b)
-
{
-
T asd;
-
asd = a;
-
a = b;
-
b = asd;
-
}
-
-
template <
class T>
-
int Partition(T a[], int p, int r)
-
{
-
int i = p, j = r+
1;
-
T x = a[p];
-
while(
true)
-
{
-
while(a[++i] < x && i < r);
-
while(a[--j] > x);
-
if(i >= j)
break;
-
Swap(a[i], a[j]);
-
}
-
a[p] = a[j];
-
a[j] = x;
-
return j;
-
}
-
-
template <
class T>
-
void QuickSort(T a[], int p, int r)
-
{
-
if(p < r)
-
{
-
int q = Partition(a, p, r);
-
QuickSort(a, p, q
-1);
-
QuickSort(a, q+
1, r);
-
}
-
}
-
-
int a[M] = {
0};
-
int main()
-
{
-
srand(time(
0));
-
for(
int i =
0; i < M; i++)
-
//a[i] = i+1; //设置升序数组
-
a[i] = rand()%(M);
//设置随机数组
-
//if(i < M/2-1) //设置重复数组
-
// a[i] = 5;
-
//else
-
// a[i] = 10;
-
//在检验数据的时候可以用Print()函数将其打印出来
-
//Print(a, 0, M);
-
clock_t start_time = clock();
-
QuickSort(a,
0, M
-1);
-
clock_t end_time = clock();
-
cout<<
"Runing time is:"<<
static_cast<
double>(end_time - start_time)/CLOCKS_PER_SEC*
1000<<
"ms"<<
endl;
-
//Print(a, 0, M);
-
return
0;
-
}
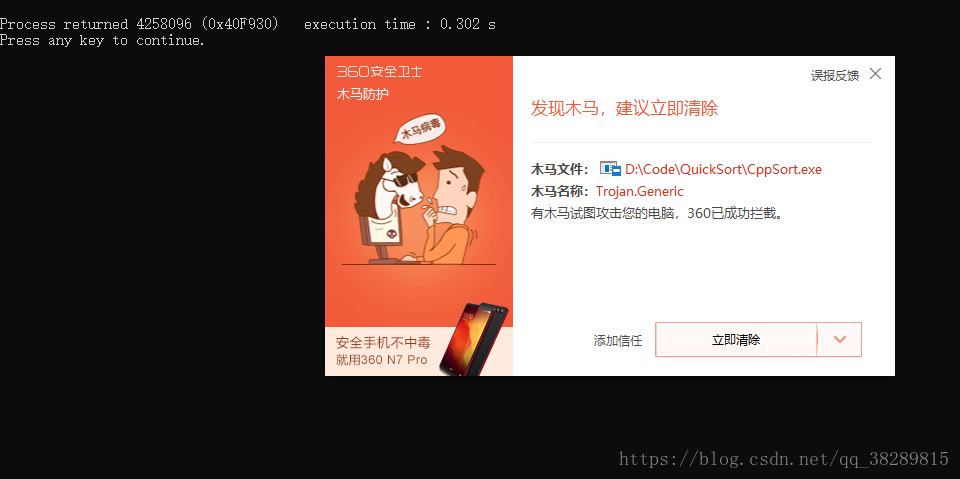
p.s:(1)在Codeblocks下处理升序数组时,元素最好设置少一点。设置的太大可能会出现下图提示:
(2)重复数组中的元素值只有两个。
(3)随机数组(较多重复元素)的设置是:a[i] = rand()%(M/100);。
数据如下:

固定基准对升序数组的分割及其糟糕,排序时间特别长,所以只设置了10万个元素(从上面代码可以看出,设置的是栈数组,如果设置的是堆数组,处理元素的数量可以很大,程序段处理时间也会相应减少)。
(2)随机基准
在待排数组有序或基本有序的情况下,选择使用固定基准影响快排的效率。为了解决数组基本有序的问题,可以采用随机基准的方式来化解这一问题。算法如下:
-
int Random(int a[], int low, int high)//在low和high间随机选择一元素作为划分的基准
-
{
-
srand(time(
0));
-
int pivot = rand()%(high - low) + low;
-
Swap(a[pivot],a[low]);
//把随机基准位置的元素和low位置元素互换
-
return a[low];
-
}
此时,原来Partition()函数里的T x = a[low];相应的改为T x = Random(a, low, high);
虽然使用随机基准能解决待排数组基本有序的情况,但是由于这种随机性的存在,对其他情况的数组也会有影响(若数组元素是随机的,使用固定基准常常优于随机基准)。随机数算法(Sherwood算法)能有效的减少升序数组排序所用的时间,数组元素越多,随机数算法的效果越好。可以试想,上述升序数组中有10万个元素而且各不相同,那么在第一次划分时,基准选的最差的概率就是十万分之一。当然,选择最优基准的概率也是十万分之一,随机数算法随机选择一个元素作为划分基准,算法的平均性能较好,从而避免了最坏情况的多次发生。许多算法书中都有介绍随机数算法,因为算法对程序的优化程度和下面所讲的三数取中方法很接近,所以我只记录了一种方法的运行时间。
(3)三数取中
由于随机基准选取的随机性,使得它并不能很好的适用于所有情况(即使是同一个数组,多次运行的时间也大有不同)。目前,比较好的方法是使用三数取中选取基准。它的思想是:选取数组开头,中间和结尾的元素,通过比较,选择中间的值作为快排的基准。其实可以将这个数字扩展到更大(例如5数取中,7数取中等)。这种方式能很好的解决待排数组基本有序的情况,而且选取的基准没有随机性。
例如:序列[1][1][6][5][4][7][7],三个元素分别是[1]、[5]、[7],此时选择[5]作为基准。
第一趟:[1][1][4][5][6][7][7]
三数取中算法如下:
-
int NumberOfThree(int arr[],int low,int high)
-
{
-
int mid = low + ((high - low) >>
1);
//右移相当于除以2
-
-
if (arr[mid] > arr[high])
-
{
-
Swap(arr[mid],arr[high]);
-
}
-
if (arr[low] > arr[high])
-
{
-
Swap(arr[low],arr[high]);
-
}
-
if (arr[mid] > arr[low])
-
{
-
Swap(arr[mid],arr[low]);
-
}
-
//此时,arr[mid] <= arr[low] <= arr[high]
-
return arr[low];
-
}
同理,Partition()函数里的T x = a[low];相应的改为T x = NumberOfThree(a, low, high);
数据如下:

三数取中(随机数算法效果相同)在处理升序数组时有质的飞越,而且处理的还是100万个元素。
快速排序的优化
优化1:序列长度达到一定大小时,使用插入排序
当快排达到一定深度后,划分的区间很小时,再使用快排的效率不高。当待排序列的长度达到一定数值后,可以使用插入排序。由《数据结构与算法分析》(Mark Allen Weiness所著)可知,当待排序列长度为5~20之间,此时使用插入排序能避免一些有害的退化情形。
-
template <
class T>
-
void QSort(T arr[],
int low,
int high)
-
{
-
int pivotPos;
-
if (high - low +
1 <
10)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
if(low < high)
-
{
-
pivotPos = Partition(arr,low,high);
-
QSort(arr,low,pivotPos
-1);
-
QSort(arr,pivotPos+
1,high);
-
}
-
}
完整代码如下:
-
/*
-
次快排代码采用了 三数取中&插入排序
-
*/
-
#include <iostream>
-
#include <time.h>
-
#include <stdlib.h>
-
using
namespace
std;
-
-
#define M 1000000
-
int NumberOfThree(int arr[],int low,int high);
-
-
template <
class T>
-
void Print(T a[], int n)
-
{
-
for(
int i =
0; i < n; i++)
-
{
-
cout <<
"[" << a[i] <<
"]";
-
}
-
cout <<
endl;
-
}
-
-
template <
class T>
-
void Swap(T &a, T &b)
-
{
-
T asd;
-
asd = a;
-
a = b;
-
b = asd;
-
}
-
-
template <
class T>
-
int Partition(T a[], int p, int r)
-
{
-
int i = p, j = r+
1;
-
T x = NumberOfThree(a, p, r);
-
while(
true)
-
{
-
while(a[++i] < x && i < r);
-
while(a[--j] > x);
-
if(i >= j)
break;
-
Swap(a[i], a[j]);
-
}
-
a[p] = a[j];
-
a[j] = x;
-
return j;
-
}
-
-
-
void InsertSort(int arr[], int m, int n)
-
{
-
int i, j;
-
int temp;
// 用来存放临时的变量
-
for(i = m+
1; i <= n; i++)
-
{
-
temp = arr[i];
-
for(j = i
-1; (j >= m)&&(arr[j] > temp); j--)
-
{
-
arr[j +
1] = arr[j];
-
}
-
arr[j +
1] = temp;
-
}
-
}
-
-
int NumberOfThree(int arr[],int low,int high)
-
{
-
int mid = low + ((high - low) >>
1);
-
-
if (arr[mid] > arr[high])
-
{
-
Swap(arr[mid],arr[high]);
-
}
-
if (arr[low] > arr[high])
-
{
-
Swap(arr[low],arr[high]);
-
}
-
if (arr[mid] > arr[low])
-
{
-
Swap(arr[mid],arr[low]);
-
}
-
//此时,arr[mid] <= arr[low] <= arr[high]
-
return arr[low];
-
}
-
-
template <
class T>
-
void QSort(T arr[],int low,int high)
-
{
-
int pivotPos;
-
if (high - low +
1 <
10)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
if(low < high)
-
{
-
pivotPos = Partition(arr,low,high);
-
QSort(arr,low,pivotPos
-1);
-
QSort(arr,pivotPos+
1,high);
-
}
-
}
-
-
int a[M] = {
0};
-
int main()
-
{
-
srand(time(
0));
-
for(
int i=
0;i<M;i++)
-
//a[i] = i+1; //设置升序数组
-
a[i] = rand()%(M);
//设置随机数组
-
//if(i < M/2-1) //设置重复数组
-
// a[i] = 1;
-
//else
-
// a[i] = 10;
-
//Print(a, M);
-
clock_t start_time = clock();
-
QSort(a,
0, M
-1);
-
clock_t end_time = clock();
-
cout<<
"Runing time is:"<<
static_cast<
double>(end_time - start_time)/CLOCKS_PER_SEC*
1000<<
"ms"<<
endl;
-
//Print(a, M);
-
return
0;
-
}
数据如下:

如上所述,在划分到很小的区间时,里面的元素已经基本有序了,再使用快排,效率就不高了。所以,在结合插入排序后,程序的执行效率有所提高。
优化2:尾递归优化
快排算法和大多数分治排序算法一样,都有两次递归调用。但是快排与归并排序不同,归并的递归则在函数一开始, 快排的递归在函数尾部,这就使得快排代码可以实施尾递归优化。使用尾递归优化后,可以缩减堆栈的深度,由原来的O(n)缩减为O(logn)。
尾递归概念:
如果一个函数中所有递归形式的调用都出现在函数的末尾,当递归调用是整个函数体中最后执行的语句且它的返回值不属于表达式的一部分时,这个递归调用就是尾递归。尾递归函数的特点是在回归过程中不用做任何操作,这个特性很重要,因为大多数现代的编译器会利用这种特点自动生成优化的代码。
尾递归原理:
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。
代码如下:
-
#include <bits/stdc++.h>
-
using
namespace
std;
-
-
int fact(int n) //线性递归
-
{
-
if (n <
0)
-
return
0;
-
else
if(n ==
0 || n ==
1)
-
return
1;
-
else
-
return n * fact(n -
1);
-
}
-
-
int facttail(int n, int a) //尾递归
-
{
-
if (n <
0)
-
return
0;
-
else
if (n ==
0)
-
return
1;
-
else
if (n ==
1)
-
return a;
-
else
-
return facttail(n -
1, n * a);
-
}
-
-
int main()
-
{
-
int a = fact(
5);
-
int b = facttail(
5,
1);
-
cout <<
"A:" << a <<
endl;
-
cout <<
"B:" << b <<
endl;
-
}
示例中的函数是尾递归的,因为对facttail的单次递归调用是函数返回前最后执行的一条语句。在facttail中碰巧最后一条语句也是对facttail的调用,但这并不是必需的。换句话说,在递归调用之后还可以有其他的语句执行,只是它们只能在递归调用没有执行时才可以执行。尾递归是极其重要的,不用尾递归,函数的堆栈耗用难以估量,需要保存很多中间函数的堆栈。比如f(n, sum) = f(n-1) + value(n) + sum; 会保存n个函数调用堆栈,而使用尾递归f(n, sum) = f(n-1, sum+value(n)); 这样则只保留后一个函数堆栈即可,之前的可优化删去。
代码当n=5时,线性递归的递归过程如下:
而尾递归的递归过程如下:
关于尾递归及快排尾递归优化可以看这篇博文:尾递归及快排尾递归优化 ,其中包含了上述阶乘问题、快排尾递归优化和Gdb调试等内容。
在Codeblocks里运行快排代码处理升序数组,一个进行尾递归优化,而另一个不变。没有使用尾递归的代码处理4万个数组元素时,由于超过了栈的深度,程序会异常结束。而使用了尾递归的代码,就算处理10万个数组元素,也不会出现异常(结合三数取中,可以处理100万个数组元素)。
2018年10月2日补充:结合我的另一篇博文《内存四区》,对上述问题有更全面的认识。
快排尾递归代码如下:
-
template <
class T>
-
void QSort(T arr[],
int low,
int high)
-
{
-
int pivotPos;
-
if (high - low +
1 <
10)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
while(low < high)
-
{
-
pivotPos = Partition(arr,low,high);
-
QSort(arr,low,pivotPos
-1);
-
low = pivotPos +
1;
-
}
-
}
第一次递归以后,变量low就没有用处了, 也就是说第二次递归可以用迭代控制结构代替。快排尾递归过程如下,纵向是递归,横向是迭代。

数据如下:

对递归的优化,主要是为了减少栈深度。在处理随机数组时,(三数取中+插排+尾递归)的组合并不一定比(三数取中+插排)的效率高。
优化3:聚集元素
聚集元素的思想:在一次分割结束后,将与本次基准相等的元素聚集在一起,再分割时,不再对聚集过的元素进行分割。具体过程有两步,①在划分过程中将与基准值相等的元素放入数组两端,②划分结束后,再将两端的元素移到基准值周围。
普通过程例如:[7][2][7][1][7][4][7][6][3][8] 由三数取中可得基准为[7]
第一趟:[7] [2] [3] [1] [6] [4] [7] [7] [7] [8]
第二趟:[1] [2] [3] [4] [6] [7] [7] [7] [7] [8]
第三趟:[1] [2] [3] [4] [6] [7] [7] [7] [7] [8]
第四趟:[1] [2] [3] [4] [6] [7] [7] [7] [7] [8]
聚集相同元素:
第一步:[7] [7] [7] [1] [2] [4] [3] [6] [7] [8]
第二步:[6] [3] [4] [1] [2] [7] [7] [7] [7] [8]
接下来是对[6] [3] [4] [1] [2] 和 [8]进行快排。(具体过程可以按照以下代码走一遍)
-
template <
class T>
-
void QSort(T arr[],
int low,
int high)
-
{
-
int first = low;
-
int last = high;
-
-
int left = low;
-
int right = high;
-
-
int leftLen =
0;
-
int rightLen =
0;
-
-
if (high - low +
1 <
10)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
-
//一次分割
-
int key = NumberOfThree(arr,low,high);
//使用三数取中选择枢轴
-
-
while(low < high)
-
{
-
while(high > low && arr[high] >= key)
-
{
-
if (arr[high] == key)
//处理相等元素
-
{
-
Swap(arr[right],arr[high]);
-
right--;
-
rightLen++;
-
}
-
high--;
-
}
-
arr[low] = arr[high];
-
while(high > low && arr[low] <= key)
-
{
-
if (arr[low] == key)
-
{
-
Swap(arr[left],arr[low]);
-
left++;
-
leftLen++;
-
}
-
low++;
-
}
-
arr[high] = arr[low];
-
}
-
arr[low] = key;
-
-
//一次快排结束,把与基准相等的元素移到基准周围
-
int i = low -
1;
-
int j = first;
-
while(j < left && arr[i] != key)
-
{
-
Swap(arr[i],arr[j]);
-
i--;
-
j++;
-
}
-
i = low +
1;
-
j = last;
-
while(j > right && arr[i] != key)
-
{
-
Swap(arr[i],arr[j]);
-
i++;
-
j--;
-
}
-
QSort(arr,first,low -
1 - leftLen);
-
QSort(arr,low +
1 + rightLen,last);
-
}
聚集元素第一步:


聚集元素第二步:

下一次就是对[6] [3] [4] [1] [2] 进行快排。当划分区间达到插入排序的要求时,就使用插入排序完成后续工作,所以进入插入排序那一段代码是停止继续递归的标志。
数据如下:

从上表中可以看到,通过对快排聚集元素的优化,在处理数组中的重复元素时有很大的提升。而对于升序数组而言,因为其本身就是有序的,而且没有重复元素,所以结果没有(三数取中+插排)效率高。
优化4:多线程处理快排
分治法的基本思想是将一个规模为n的问题分解为k个规模较小的子问题,这些子问题互相独立且与原问题相同。求解这些子问题,然后将各子问题的解合并,从而得到的原问题的解。由此,在处理快排的时候,可以使用多线程提高排序的效率。
要使用的函数:
(1)pthread_create
创建一个线程的函数是pthread_create。其定义如下:
-
#include <pthread.h>
//(Linux下编译需要加 -lpthread)
-
int pthread_create(pthread_t* thread,
const pthread_attr_t* attr, void*
(*start_routine)(void*), void *arg);
第一个参数是一个整数类型,它表示的是资源描述符,实际上,Linux上几乎所有的资源标识符都是一个整型数。第二个attr参数用于设置新线程的属性。给它传递NULL表示使用默认线程属性。start_routine和arg参数分别指定新线程将运行的函数及其参数。
pthread_create()成功时返回0,失败时返回错误码。
(2)pthread_barrier_init
多线程编程时,可以使用这个函数来等待其它线程结束,例如:主线程创建一些线程,这些线程去完成一些工作,而主线程需要去等待这些线程结束(pthread_join也能实现一种屏障)。可以把屏障理解为:为了协同线程之间的工作而使得某一具体线程进入等待状态的一种机制。其原型:
int pthread_barrier_init(pthread_barrier_t *restrict barrier, const pthread_barrierattr_t *restrict attr, unsigned int count);
函数执行成功返回 0,执行失败则返回一个错误号,我们可以通过该错误号获取相关的错误信息。
第一个参数:一个指向pthread_barrier_t 类型的指针,我们必须要指出的是pthread_barrier_init函数不会给指针分配相关内存空间,因此我们传入的指针必须为一个pthread_barrier_t 变量。
第二个参数:用于指定屏障的细节参数,我们这里可以暂且不去管它,如果我们传入NULL,那么系统将按照默认情况处理。
第三个参数:设计屏障等待的最大线程数目。
(3)pthread_barrier_wait
当一个线程需要等待其它多个线程结束时,调用该函数。
原型:
int pthread_barrier_wait(pthread_barrier_t *barrier);
函数执行成功返回 0,执行失败则返回一个错误码,我们可以通过该错误码获取相关的错误信息。
函数参数:指向pthread_barrier_t 变量的指针。
注意:使用barrier这个屏障,无法获取线程的结束状态。若想要获取相关线程结束状态,则需要调用pthread_join函数。
代码如下:
-
#include <cstdio> /*三数取中+插入+聚集元素+多线程组合 && 三数取中+插入+尾递归+多线程组合*/
-
#include <iostream>
-
#include <stdlib.h>
-
#include <sys/time.h>
-
#include <pthread.h>
-
using
namespace
std;
-
-
const
long MAX =
1000000L;
//数组中最大数
-
const
long
long MaxNumber =
1000000L;
//排序数
-
const
int thread =
4;
//线程数
-
const
long NumberOfSort = MaxNumber / thread;
//每个线程排序的个数
-
-
int array_a[MaxNumber];
-
int array_b[MaxNumber];
//合并后,由b数组记录最终序列
-
-
pthread_barrier_t barrier;
-
-
void initial() //数组初始化函数
-
{
-
srand(time(
0));
-
for(
int i =
0; i < MaxNumber; ++i)
-
array_a[i] = rand()%(MAX);
-
//if(i < MaxNumber/2)
-
// array_a[i] = 5;
-
//else
-
// array_a[i] = 10;
-
//array_a[i] = i+1;
-
}
-
-
-
template <
class T>
-
void Print(T a[], int n)
-
{
-
for(
int i =
0; i < n; i++)
-
{
-
cout <<
"[" << a[i] <<
"]";
-
}
-
cout <<
endl;
-
}
-
-
template <
class T>
-
void Swap(T &a, T &b)
-
{
-
T asd;
-
asd = a;
-
a = b;
-
b = asd;
-
}
-
-
void InsertSort(int arr[],int start,int end)
-
{
-
int low,high,median,tmp;
-
for(
int i = start+
1;i<= end;i++)
-
{
-
low = start;
-
high = i
-1;
-
-
while(low <= high)
-
{
-
median = (low + high) /
2;
-
if(arr[i] < arr[median])
-
{
-
high = median
-1;
-
}
else
-
{
-
low = median +
1;
-
}
-
}
-
-
tmp = arr[i];
-
-
for(
int j = i
-1;j>high;j--)
-
{
-
arr[j+
1] = arr[j];
-
}
-
arr[high+
1] = tmp;
-
}
-
}
-
-
int NumberOfThree(int arr[],int low,int high)
-
{
-
int mid = low + ((high - low) >>
1);
-
if (arr[mid] > arr[high])
-
{
-
Swap(arr[mid],arr[high]);
-
}
-
if (arr[low] > arr[high])
-
{
-
Swap(arr[low],arr[high]);
-
}
-
if (arr[mid] > arr[low])
-
{
-
Swap(arr[mid],arr[low]);
-
}
-
return arr[low];
-
}
-
-
template <
class T>
-
int Partition(T a[], int p, int r)
-
{
-
int i = p, j = r+
1;
-
T x = NumberOfThree(a, p, r);
-
while(
true)
-
{
-
while(a[++i] < x && i < r);
-
while(a[--j] > x);
-
if(i >= j)
break;
-
Swap(a[i], a[j]);
-
}
-
a[p] = a[j];
-
a[j] = x;
-
return j;
-
}
-
-
#if 1 //有聚集元素的快排
-
template <
class T>
-
void QSort(T arr[],int low,int high)
-
{
-
int first = low;
-
int last = high;
-
int left = low;
-
int right = high;
-
int leftLen =
0;
-
int rightLen =
0;
-
-
if (high - low +
1 <
6)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
-
//一次分割
-
int key = NumberOfThree(arr,low,high);
//使用三数取中法选择枢轴
-
-
while(low < high)
-
{
-
while(high > low && arr[high] >= key)
-
{
-
if (arr[high] == key)
//处理相等元素
-
{
-
Swap(arr[right],arr[high]);
-
right--;
-
rightLen++;
-
}
-
high--;
-
}
-
arr[low] = arr[high];
-
while(high > low && arr[low] <= key)
-
{
-
if (arr[low] == key)
-
{
-
Swap(arr[left],arr[low]);
-
left++;
-
leftLen++;
-
}
-
low++;
-
}
-
arr[high] = arr[low];
-
}
-
arr[low] = key;
-
-
//一次快排结束
-
//把与枢轴key相同的元素移到枢轴最终位置周围
-
int i = low -
1;
-
int j = first;
-
while(j < left && arr[i] != key)
-
{
-
Swap(arr[i],arr[j]);
-
i--;
-
j++;
-
}
-
i = low +
1;
-
j = last;
-
while(j > right && arr[i] != key)
-
{
-
Swap(arr[i],arr[j]);
-
i++;
-
j--;
-
}
-
QSort(arr,first,low -
1 - leftLen);
-
QSort(arr,low +
1 + rightLen,last);
-
}
-
#endif
-
-
#if 0 //没有聚集元素的快排
-
template <
class T>
-
void QSort(T arr[],int low,int high)
-
{
-
int pivotPos;
-
if (high - low +
1 <
10)
-
{
-
InsertSort(arr,low,high);
-
return;
-
}
-
-
while(low < high)
-
{
-
pivotPos = Partition(arr,low,high);
-
QSort(arr,low,pivotPos
-1);
-
low = pivotPos +
1;
-
}
-
}
-
#endif // 1
-
-
void* work(void *arg) //线程排序函数
-
{
-
long length = (
long)arg;
-
QSort(array_a, length, length + NumberOfSort -
1);
-
pthread_barrier_wait(&barrier);
-
pthread_exit(
NULL);
-
}
-
-
void meger() //最终合并函数
-
{
-
long index[thread];
-
for (
int i =
0; i < thread; ++i)
-
{
-
index[i] = i * NumberOfSort;
-
}
-
-
for(
long i =
0; i < MaxNumber; ++i)
-
{
-
long min_index;
-
long min_num = MAX;
-
for(
int j =
0; j < thread; ++j)
-
{
-
if((index[j] < (j +
1) * NumberOfSort)&& (array_a[index[j]] < min_num))
-
{
-
min_index = j;
-
min_num = array_a[index[j]];
-
}
-
}
-
array_b[i] = array_a[index[min_index]];
-
index[min_index]++;
-
}
-
}
-
-
-
int main(int argc, char const *argv[])
-
{
-
initial();
-
//Print(array_a,MaxNumber);
-
struct timeval start, end;
-
pthread_t ptid;
-
gettimeofday(&start,
NULL);
-
-
pthread_barrier_init(&barrier,
NULL, thread +
1);
-
for(
int i =
0; i < thread; ++i)
-
pthread_create(&ptid,
NULL, work, (
void *)(i * NumberOfSort));
-
-
pthread_barrier_wait(&barrier);
-
meger();
-
-
gettimeofday(&end,
NULL);
-
long
long s_usec = start.tv_sec *
1000000 + start.tv_usec;
-
long
long e_usec = end.tv_sec *
1000000 + end.tv_usec;
-
-
double Time = (
double)(e_usec - s_usec) /
1000.0;
-
printf(
"sort use %.4f ms\n", Time);
-
//Print(array_b, MaxNumber);
-
return
0;
-
}
-
-
上传完这段代码,同学告诉我说,这段代码在Linux和Codeblocks里运行的时间不一样(本篇博文的数据都是在Codeblocks上测得的)。然后我立马就测试了一下,发现这之间存在误差,初步猜测是由于编译器引起的。由于我不是双系统,是在虚拟机上运行的Linux系统,这可能是造成误差原因之一(个人认为可以忽略误差,虽然每组数据在不同环境下平均运行时间有差距,但其整体优化的方向是不变的)。
数据如下:
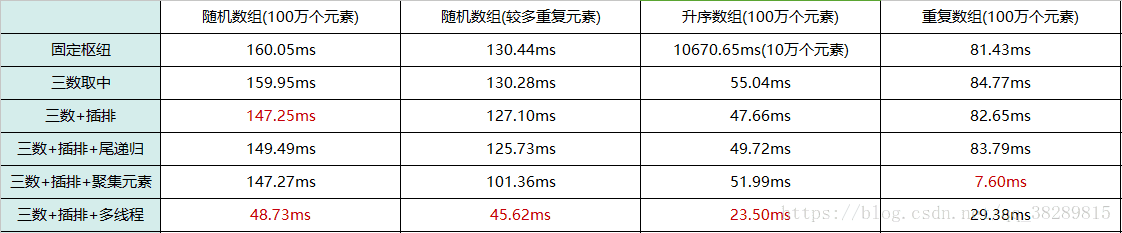
从上表可以看出,结合了多线程的快排(三数+插排+多线程)在处理前三种数组时都有明显的提升。重复数组处理时间增加的原因是:聚集元素在处理重复数组时的表现已经很好了,因为在多线程的组合中,各个线程排完序后要合并,所以增加了(三数+插排+多线程)这一组合的排序时间。因为时间原因,以上的数据,是运行相应代码10次所取得平均值。如果想要得到更精确的数据,需要大量的运行上述代码(即使存在一些不稳定的数据,也不会影响到代码优化的方向)。PS.以上程序运行时间还与个人所使用的电脑配置有关。
参考:
http://blog.csdn.net/zuiaituantuan/article/details/5978009
https://blog.csdn.net/hacker00011000/article/details/52176100
https://baike.baidu.com/item/%E5%B0%BE%E9%80%92%E5%BD%92/554682
https://blog.csdn.net/qq_25425023/article/details/72705285














 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









