







目录
1. AlexNet网络
1.1 AlexNet网络结构 :
2012年AlexNet网络打开了深度学习的大门,掀起深度学习的研究热潮,验证了深度学习的有效性。
AlexNet网络结构相对简单,使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层,具体如下所示。
由于当时GPU内存的限制,原作者使用两个GPU并行操作,实际上下两个部分网络结构是一致的,我们只分析其中一个就行了。
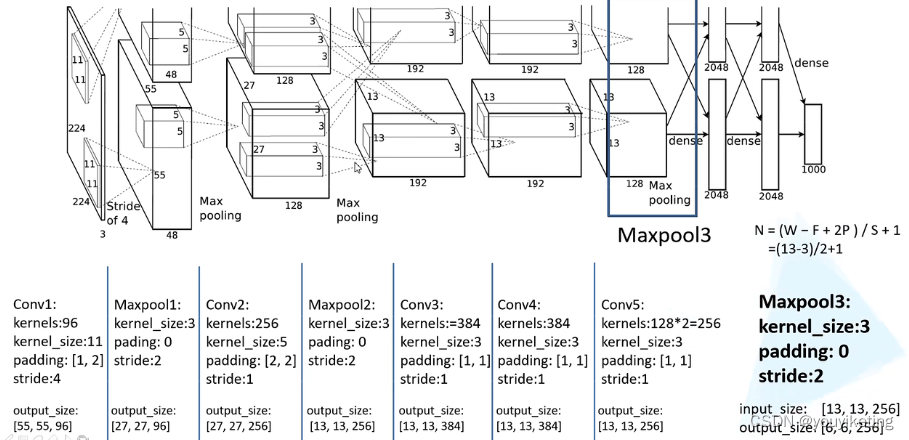

(from B站up主:霹雳吧啦Wz )
1.2 AlexNet 亮点:
(1)GPU加速:首次利用GPU进行网络加速训练;
(2)ReLu激活函数:使用了ReLu激活函数,而不是传统的Sigmoid、Tanh激活函数(神经网络在进行方向误差传播时,各个层都要乘以激活函数的一阶导数,梯度每传递一层就会衰减一层,网络层数较多时,梯度G就会不停衰减直到消失),而由于ReLU函数具有线性、非饱和的特点,采用修正线性单元(ReLU)的深度卷积神经网络训练时间比等价的tanh单元要快几倍,同时ReLU有效防止了过拟合现象的出现;
(3)层叠池化操作:以往池化的大小PoolingSize与步长stride一般是相等的,例如:图像大小为256*256,PoolingSize=2×2,stride=2,这样可以使图像或是FeatureMap大小缩小一倍变为128,此时池化过程没有发生层叠。但是AlexNet采用了层叠池化操作,即PoolingSize > stride。这种操作非常像卷积操作,可以使相邻像素间产生信息交互和保留必要的联系。(作者在论文中证明,此操作可以有效防止过拟合的发生)。
(3)LRN局部响应归一化:使用了LRN局部响应归一化,对局部神经元的活动创建竞争机制,使得其中响应较大的值变得相对更大,并抑制其他较小的神经元,增强了模型的泛化能力.
(4)Dropout操作:在全连接的前两层中使用了Dropout随机失活神经元操作,将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。那些“失活的”神经元不再进行前向传播并且不参与反向传播。这个技术减少了复杂的神经元之间的相互影响。
过拟合:特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美地预测训练集,但对新数据地测试集预测结果差。过度拟合了训练数据,而没有考虑泛化能力。
我们通过使用Dropout的方式在网络正向传播的过程中随机失活一部分神经元(及随机减少网络的部分参数,从而减少过拟合)

卷积后的矩阵尺寸大小计算公式:

2. 实战:BelgiumTSC分类
2.1 数据集
下载链接:
BelgiumTS - Belgian Traffic Sign Dataset (ethz.ch)
数据集格式:
BelgiumTSC
├─ Training
| ├─ 00000
| | ├─ XXXXX_YYYYY.ppm
| | ├─ ...
| | └─GT-00000.csv
| ├─00001
| | ├─ XXXXX_YYYYY.ppm
| | ├─ ...
| | └─GT-00001.csv
| ├─ ...
| ├─ 00061
| | ├─ XXXXX_YYYYY.ppm
| | ├─ ...
| | └─GT-00061.csv
| └─train_data.csv
└─Testing
├─ 00000
| ├─ XXXXX_YYYYY.ppm
| ├─ ...
| └─GT-00000.csv
├─ 00001
| ├─ XXXXX_YYYYY.ppm
| ├─ ...
| └─GT-00001.csv
├─ ...
├─ 00061
| ├─ XXXXX_YYYYY.ppm
| ├─ ...
| └─GT-00061.csv
└─test_data.csv
2.2 AlexNet网络搭建
因为数据集的数据较少,且为了加快训练速度,本文的设置参数如下:
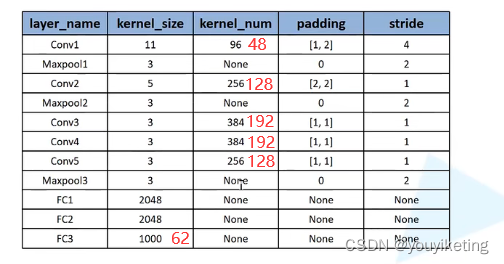
import torch.nn as nn
import torch
from torch.utils.tensorboard import SummaryWriter
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# C1
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
# C2
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
# C3
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
# C4
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
# C5
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
# FC6
nn.Dropout(p=0.5), # 随机失活的比例为:0.5
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
# FC7
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
# FC8
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1) # 将4维张量->展平->1维张量
x = self.classifier(x)
return x
# 权重初始化
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
# 验证模型是否搭建正确:4维张量(64,3,32,32) -> model -> 2维张量(64,10)
if __name__ == '__main__':
myModel = AlexNet()
print(myModel)
input = torch.ones((32, 3, 224, 224))
output = myModel(input)
print("output.shape: ", output.shape)
# 画网络结构图
writer = SummaryWriter("../net_logs")
writer.add_graph(myModel, input)
writer.close()2.3 dataset
import os
import pandas as pd
from torch.utils.data import Dataset
from PIL import Image
class BelgiumTSC(Dataset):
base_folder = 'BelgiumTSC'
# 初始化,为class提供全局变量
def __init__(self, root_dir, train=False, transform=None):
"""
Args:
root_dir (string): Directory containing BelgiumTSC folder.
train (bool): Load training set or test set.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.root_dir = root_dir
self.sub_directory = 'Training' if train else 'Testing'
self.csv_file_name = 'train_data.csv' if train else 'test_data.csv'
csv_file_path = os.path.join(root_dir, self.base_folder, self.sub_directory,
self.csv_file_name)
self.csv_data = pd.read_csv(csv_file_path)
self.transform = transform
# 获取数据及其label值(类别)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.base_folder, self.sub_directory,
self.csv_data.iloc[idx, 0])
img = Image.open(img_path)
classId = self.csv_data.iloc[idx, 1]
if self.transform is not None:
img = self.transform(img)
return img, classId
# 获取数据集长度
def __len__(self):
return len(self.csv_data)
2.4 训练
# import time
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from tqdm import tqdm
import source.dataset_BelgiumTSC as dataset
from source.AlexNet_model import AlexNet
def main():
# 定义训练的设备
print(torch.cuda.is_available())
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 数据集准备
dataset_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))
])
dataset_dir = "../dataset"
train_dataset = dataset.BelgiumTSC(root_dir=dataset_dir, train=True, transform=dataset_transform)
test_dataset = dataset.BelgiumTSC(root_dir=dataset_dir, train=False, transform=dataset_transform)
# 数据集长度
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
print("train_data_size: {}".format(train_data_size))
print("test_data_size: {}".format(test_data_size))
# 加载数据集
BatchSize = 32
train_dataloader = DataLoader(train_dataset, batch_size=BatchSize, shuffle=True, num_workers=0, drop_last=True)
test_dataloader = DataLoader(test_dataset, batch_size=BatchSize, shuffle=False, num_workers=0, drop_last=True)
# 搭建网络模型
myModel = AlexNet(num_classes=62, init_weights=True)
myModel.to(device)
# 损失函数--交叉熵
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 1e-4
optimizer = torch.optim.Adam(myModel.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
epochs = 20 # 训练的轮数
best_acc = 0.95
# 添加tensorboard
writer = SummaryWriter("../train_logs")
for epoch in range(epochs):
print("-----------------第{}轮训练开始--------------------".format(epoch+1))
# train:
myModel.train()
# for train_step, data in enumerate(tqdm(train_dataloader), 0):
for train_step, data in enumerate(train_dataloader, 0):
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = myModel(images)
loss = loss_fn(outputs, labels)
acc_sum = (outputs.argmax(1) == labels).sum()
# 优化器优化模型
optimizer.zero_grad() # 梯度清0
loss.backward() # 调用损失,反向传播
optimizer.step() # 对每一步进行优化
# record statistic
if (train_step+1) % 20 == 0:
print("Epoch [{}][{}/{}]:Loss:{:.3f} acc:{:.3f} "
.format(epoch+1, train_step+1, len(train_dataloader),
loss.item(), acc_sum/BatchSize))
writer.add_scalar("train_loss", loss.item(), epoch*len(train_dataloader)+train_step+1)
writer.add_scalar("train_acc", acc_sum/BatchSize, epoch*len(train_dataloader)+train_step+1)
print()
# print("training time(s): ", time.perf_counter()-epoch_time)
# test
# 每跑完一轮,用测试数据测试模型,以测试数据损失及正确率评估该模型是否训练好
myModel.eval()
total_test_loss = 0
total_acc_sum = 0
with torch.no_grad():
for data in test_dataloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = myModel(images)
loss = loss_fn(outputs, labels)
total_test_loss += loss.item()
acc_sum = (outputs.argmax(1) == labels).sum()
total_acc_sum += acc_sum
# record statistic
print("Validate Loss: {:.3f}".format(total_test_loss/len(test_dataloader)))
print("Validate acc: {:.3f}".format(total_acc_sum/test_data_size))
writer.add_scalar("validate_loss", total_test_loss/len(test_dataloader), epoch+1)
writer.add_scalar("validate_acc", total_acc_sum/test_data_size, epoch+1)
# 保存模型+训练参数
if total_acc_sum/test_data_size >= best_acc:
torch.save(myModel, "../saved_models/myModel_{}.path".format(epoch+1))
print("模型已保存")
print("训练结束")
writer.close()
if __name__ == '__main__':
main()
2.5 验证
import torch
from torchvision import transforms
from PIL import Image
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 准备用于验证的图片
# image_path = "../validate_data/00017_00001.ppm" # 0
image_path = "../validate_data/00252_00000.ppm" # 1
# image_path = "../validate_data/00025_00000.ppm" # 2
image = Image.open(image_path)
print(image)
# 对验证图片进行预处理,满足网络模型输入要求
transform = transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5),
(0.5, 0.5, 0.5))
])
image = transform(image)
image = torch.reshape(image, (1, 3, 224, 224)) # 3维张量[3,32,32] -> reshape -> 4维张量[1,3,32,32]
print(image.shape)
# 加载保存的网络模型+模型参数
model = torch.load("../saved_models/myModel_19.path") # GPU网络模型
print(model)
# validate
model.eval()
with torch.no_grad():
image = image.to(device) # 将输入数据加载为GPU数据类型
output = model(image)
output_target = output.argmax(1).item()
print("scores: ", output)
print("labels: ", output_target)
2.6 结果



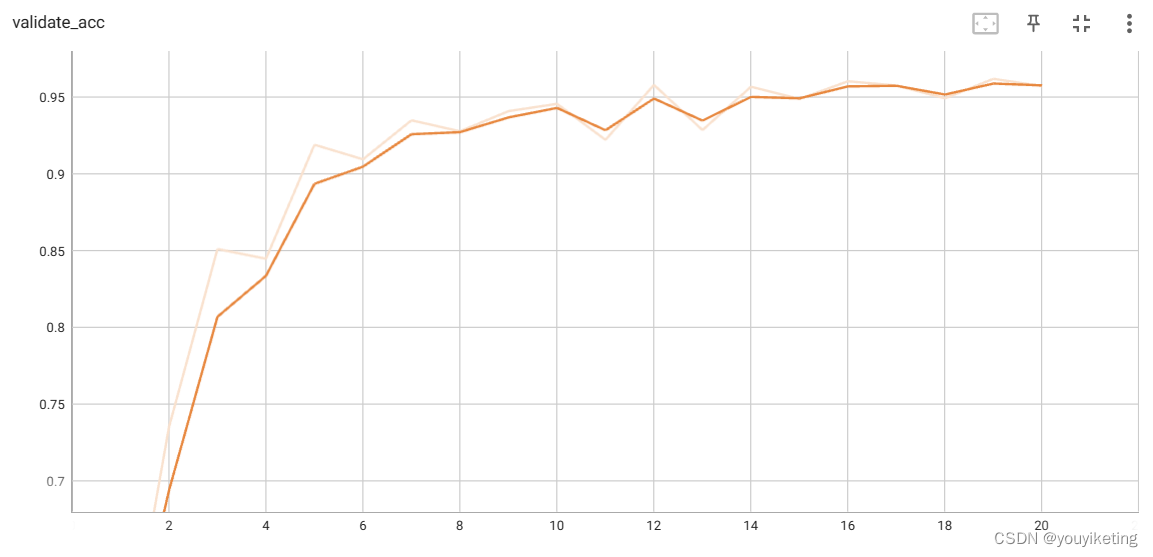
完整代码链接:链接:https://pan.baidu.com/s/1TynlFgzCVvrXZ-x-O5mvtA?pwd=n87o
提取码:n87o
参考:
3.1 AlexNet网络结构详解与花分类数据集下载_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=a2b7029e58d3c675b2d4ea72e64ea4f5(6条消息) AlexNet网络详解_红鲤鱼与绿驴的博客-CSDN博客_科积万9fc296
https://www.bilibili.com/video/BV1p7411T7Pc/?spm_id_from=333.788&vd_source=a2b7029e58d3c675b2d4ea72e64ea4f5(6条消息) AlexNet网络详解_红鲤鱼与绿驴的博客-CSDN博客_科积万9fc296![]() https://blog.csdn.net/weixin_44772440/article/details/122766653?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_utm_term~default-1-122766653-blog-118552085.pc_relevant_3mothn_strategy_recovery&spm=1001.2101.3001.4242.2&utm_relevant_index=4
https://blog.csdn.net/weixin_44772440/article/details/122766653?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_utm_term~default-1-122766653-blog-118552085.pc_relevant_3mothn_strategy_recovery&spm=1001.2101.3001.4242.2&utm_relevant_index=4














 729
729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









