







执行器(ExecutePlan)
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-10.1 的开源代码和《OpenGauss数据库源码解析》和《PostgresSQL数据库内核分析》一书
概述
在文章【OpenGauss源码学习 —— 执行器(execMain)】中,我们深入探究了执行器在数据库中的核心功能和逻辑。这篇文章详细介绍了执行器的主要组成部分,如查询执行的初始化与结束、主执行循环、以及行处理逻辑等。通过这篇文章,读者可以了解到执行器是如何在数据库系统中处理用户的查询请求,包括如何遍历执行树、执行计划节点,以及如何对数据进行操作和传递。
另一方面,文章【PostgreSQL内核学习(二十一)—— 执行器(InitPlan)】则专注于介绍了 InitPlan 函数在 PostgreSQL 数据库中的作用。这篇文章详细阐述了 InitPlan 如何初始化查询计划,设置执行状态,以及如何准备查询执行所需的各种资源和环境。读者可以通过这篇文章深入理解 InitPlan 在查询执行过程中的重要性,以及它是如何为高效执行查询提供支持的。
本文将深入了解 ExecutePlan 的原理和实现细节,从而更好地理解数据库查询的执行机制。具体学习的模块如下图红色框体所示:
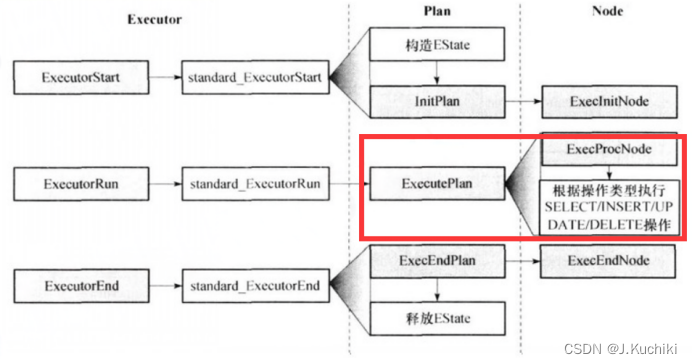
ExecutePlan 函数
ExecutePlan 函数是数据库查询执行过程中的核心部分,负责按照给定的方向处理查询计划,并从中检索指定数量的元组。函数首先初始化一些本地变量,包括当前处理的元组数量和执行方向。它还处理查询计划的并行执行模式,根据执行条件启用或禁用并行模式。
函数的主体是一个无限循环,它反复执行查询计划的节点,直到满足某个退出条件。在每次循环中,它首先重置表达式上下文,然后执行计划节点来获取一个元组。如果获取的元组为空,表示没有更多数据要处理,因此它将结束循环。此外,如果存在垃圾过滤器,函数将对元组进行处理以移除不需要的数据。
如果设置为发送元组,函数将尝试将元组发送到指定的目的地。如果发送失败(可能因为目的地已关闭),循环也会结束。对于 SELECT 操作,函数还会统计处理的元组数量。如果达到了指定的元组数量(numberTuples),或者如果没有指定数量(numberTuples 为 0),表示处理全部元组,循环也将结束。
总之,ExecutePlan 函数的主要作用是根据查询计划执行数据库查询,处理和发送检索到的数据,同时在满足特定条件时结束处理。这个函数是数据库查询执行过程中的关键环节,确保了查询按照预定的方式进行,且能够有效地处理和返回所需数据。函数源码如下所示:(路径:src\backend\executor\execMain.c)
/* ----------------------------------------------------------------
* ExecutePlan
*
* 根据指定的方向处理查询计划,直到检索到 'numberTuples' 个元组。
*
* 如果 numberTuples 为 0,则运行到完成。
*
* 注意:ctid 属性是一个“垃圾”属性,在用户看到之前会被移除。
* ----------------------------------------------------------------
*/
static void
ExecutePlan(EState *estate, // 执行状态对象,包含执行过程中需要的状态信息
PlanState *planstate, // 查询计划状态对象,包含当前执行节点的状态
bool use_parallel_mode, // 是否使用并行模式执行
CmdType operation, // 操作类型(如SELECT, UPDATE等)
bool sendTuples, // 是否发送结果元组
uint64 numberTuples, // 需要处理的元组数量,0表示不限制
ScanDirection direction, // 扫描方向
DestReceiver *dest, // 结果接收器,定义了结果的去向
bool execute_once) // 是否只执行一次
{
TupleTableSlot *slot; // 声明一个元组槽,用于存储当前处理的元组
uint64 current_tuple_count; // 当前已处理元组的计数
/* 初始化局部变量 */
current_tuple_count = 0;
/* 设置执行方向 */
estate->es_direction = direction;
/*
* 如果计划可能会被多次执行,必须禁用并行模式,因为我们
* 可能会提前退出。另外,在写入关系(如更新表格)时也禁用并行模式,
* 因为在并行模式下不允许数据库更改。
*/
if (!execute_once || dest->mydest == DestIntoRel)
use_parallel_mode = false;
estate->es_use_parallel_mode = use_parallel_mode; // 设置是否使用并行模式
if (use_parallel_mode)
EnterParallelMode(); // 如果使用并行模式,则进入并行模式
/* 循环执行计划,直到处理了指定数量的元组 */
for (;;)
{
/* 重置每个输出元组的表达式上下文 */
ResetPerTupleExprContext(estate);
/* 执行计划并获取一个元组 */
slot = ExecProcNode(planstate);
/* 如果元组为空,假定没有更多内容要处理,结束循环 */
if (TupIsNull(slot))
{
/* 允许节点释放或关闭资源 */
(void) ExecShutdownNode(planstate);
break;
}
/* 如果有垃圾过滤器,那么生成一个新元组,并移除垃圾 */
if (estate->es_junkFilter != NULL)
slot = ExecFilterJunk(estate->es_junkFilter, slot);
/* 如果需要将元组发送到某处,则进行发送 */
if (sendTuples)
{
/* 如果无法发送元组,假定目的地已关闭,无法发送更多元组,结束循环 */
if (!((*dest->receiveSlot) (slot, dest)))
break;
}
/* 如果是 SELECT 操作,计算处理的元组数。(对于其他操作类型,ModifyTable 计划节点必须计算相应的事件。)*/
if (operation == CMD_SELECT)
(estate->es_processed)++;
/* 检查处理的元组数量。如果达到了指定数量,则退出;如果 numberTuples 为零,则表示没有限制 */
current_tuple_count++;
if (numberTuples && numberTuples == current_tuple_count)
{
/* 允许节点释放或关闭资源 */
(void) ExecShutdownNode(planstate);
break;
}
}
/* 如果使用了并行模式,退出并行模式 */
if (use_parallel_mode)
ExitParallelMode();
}
ExecProcNode 函数
ExecProcNode 函数是数据库查询执行过程中的一个关键部分,用于执行给定的计划节点(PlanState)并返回一个元组(TupleTableSlot)。
ExecProcNode 函数的作用是执行查询计划树中的一个特定节点,并从这个节点获取一个元组。这个函数是数据库查询执行的核心组成部分,因为它直接涉及到从计划节点获取数据的过程。
- 检查节点参数变化:函数首先检查
node->chgParam,这是一个标志,表明节点的参数是否发生了变化。如果这个标志不为空,意味着节点的一些执行参数已经改变,需要重新扫描(re-scan)。这通常发生在查询执行过程中,某些外部条件或者上游节点的输出发生变化时。- 重新扫描:如果检测到参数变化,函数将调用
ExecReScan来重新设置节点的状态,以便正确反映新的参数或环境。- 执行节点并获取元组:最后,函数调用节点自身的
ExecProcNode方法来执行该节点的逻辑,并获取下一个可用的元组。不同类型的节点(如扫描节点、连接节点等)将有其特定的ExecProcNode实现,以执行相应的数据检索或处理逻辑。
总结来说,ExecProcNode 是数据库查询执行流程中的核心函数之一,负责直接从查询计划的特定节点获取数据。这个函数通过动态执行计划节点的特定逻辑,使得整个查询过程可以根据计划逐步进行,同时能够适应查询执行过程中可能出现的变化,确保数据的正确检索和处理。函数源码如下所示:(路径:src\include\executor\executor.h)
/* ----------------------------------------------------------------
* ExecProcNode
*
* 执行给定的节点以返回一个(或另一个)元组。
* ----------------------------------------------------------------
*/
#ifndef FRONTEND
static inline TupleTableSlot *
ExecProcNode(PlanState *node)
{
/* 如果节点的参数有所改变 */
if (node->chgParam != NULL) /* 发生了一些变化? */
ExecReScan(node); /* 让 ReScan 函数处理这种情况 */
/* 执行节点的 ExecProcNode 方法并返回一个元组 */
return node->ExecProcNode(node);
}
#endif
注: ExecProcNode 函数用于执行给定的计划节点,并返回一个元组(TupleTableSlot),它是该节点执行的结果。计划节点可以包括顶层查询计划节点,也可以包括子查询的计划节点,每个节点都有一个相应的 ExecProcNode 函数来执行它。这里,代码node->ExecProcNode(node);是在 InitPlan 时,根据所执行算子的具体类型来进行赋值的。例如以 ExecInitResult 函数为例,如下代码段所示:
/*
* create state structure
*/
resstate = makeNode(ResultState);
resstate->ps.plan = (Plan *) node;
resstate->ps.state = estate;
resstate->ps.ExecProcNode = ExecResult;
所以,“给定的计划节点” 意味着你想要执行的特定查询计划中的某个节点。当你调用 ExecProcNode 并传递一个计划节点作为参数时,它将执行该节点描述的操作,并返回结果元组。这是数据库查询执行中的关键部分,它使查询计划得以实际执行并生成结果。
总结
“ExecutePlan” 函数负责执行查询计划中的各个节点,将它们的执行结果组合成最终的查询结果,并返回给调用者。这是数据库查询执行的核心部分,它确保了查询计划的实际执行和结果的生成。注意,具体实现和细节可能会因数据库管理系统而异。
- 输入参数:通常,“ExecutePlan” 函数将接受一个查询计划作为输入参数。这个查询计划通常是一个包含了多个执行计划节点(PlanState)的树状结构,每个节点描述了执行查询的不同操作。
- 执行计划节点: “ExecutePlan” 函数将遍历查询计划中的每个执行计划节点,并逐一执行它们。这些节点可以包括扫描表、连接表、过滤数据、聚合操作等等,每个节点都有一个相应的执行方法。
- 节点执行: “ExecutePlan” 函数将调用每个节点的执行方法(通常是
ExecProcNode函数)来执行节点描述的操作。这些执行方法通常会访问数据库表、处理数据,或者进行其他计算操作,最终生成一个或多个结果元组。- 结果处理: “ExecutePlan” 函数通常会收集每个节点的执行结果,并根据查询的需求进行合并、过滤或其他操作。最终的结果可以是一个或多个元组,这些元组表示了查询的输出。
- 返回结果: “ExecutePlan” 函数通常将最终的查询结果返回给调用者,以供后续处理或返回给客户端应用程序。
总之,
















 1071
1071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









